
| | |  GitHub এ দেখুন GitHub এ দেখুন | | |
YAMNet হল একটি প্রাক-প্রশিক্ষিত গভীর নিউরাল নেটওয়ার্ক যা 521টি ক্লাস থেকে অডিও ইভেন্টের পূর্বাভাস দিতে পারে, যেমন হাসি, ঘেউ ঘেউ বা সাইরেন।
এই টিউটোরিয়ালে আপনি শিখবেন কিভাবে:
- অনুমানের জন্য YAMNet মডেল লোড করুন এবং ব্যবহার করুন।
- বিড়াল এবং কুকুরের শব্দ শ্রেণীবদ্ধ করতে YAMNet এম্বেডিং ব্যবহার করে একটি নতুন মডেল তৈরি করুন।
- আপনার মডেল মূল্যায়ন এবং রপ্তানি.
TensorFlow এবং অন্যান্য লাইব্রেরি আমদানি করুন
TensorFlow I/O ইনস্টল করে শুরু করুন, যা আপনার জন্য ডিস্ক থেকে অডিও ফাইল লোড করা সহজ করে তুলবে।
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
YAMNet সম্পর্কে
YAMNet হল একটি প্রাক-প্রশিক্ষিত নিউরাল নেটওয়ার্ক যা MobileNetV1 গভীরভাবে-বিভাজ্য কনভোলিউশন আর্কিটেকচার নিযুক্ত করে। এটি ইনপুট হিসাবে একটি অডিও তরঙ্গরূপ ব্যবহার করতে পারে এবং অডিওসেট কর্পাস থেকে 521টি অডিও ইভেন্টের প্রতিটির জন্য স্বাধীন ভবিষ্যদ্বাণী করতে পারে।
অভ্যন্তরীণভাবে, মডেলটি অডিও সিগন্যাল থেকে "ফ্রেম" বের করে এবং এই ফ্রেমের ব্যাচগুলিকে প্রক্রিয়া করে। মডেলটির এই সংস্করণটি 0.96 সেকেন্ড দীর্ঘ ফ্রেম ব্যবহার করে এবং প্রতি 0.48 সেকেন্ডে একটি ফ্রেম বের করে।
মডেলটি একটি 1-D ফ্লোট 32 টেনসর বা NumPy অ্যারে গ্রহণ করে যাতে নির্বিচারে দৈর্ঘ্যের একটি তরঙ্গরূপ থাকে, যা [-1.0, +1.0] পরিসরে একক-চ্যানেল (মনো) 16 kHz নমুনা হিসাবে উপস্থাপিত হয়। এই টিউটোরিয়ালটিতে আপনাকে WAV ফাইলগুলিকে সমর্থিত বিন্যাসে রূপান্তর করতে সহায়তা করার জন্য কোড রয়েছে৷
মডেলটি 3টি আউটপুট প্রদান করে, যার মধ্যে ক্লাস স্কোর, এম্বেডিং (যা আপনি ট্রান্সফার শেখার জন্য ব্যবহার করবেন), এবং লগ মেল স্পেকট্রোগ্রাম । আপনি এখানে আরো বিস্তারিত জানতে পারেন.
YAMNet-এর একটি নির্দিষ্ট ব্যবহার হল একটি উচ্চ-স্তরের বৈশিষ্ট্য এক্সট্র্যাক্টর - 1,024-মাত্রিক এমবেডিং আউটপুট। আপনি বেস (YAMNet) মডেলের ইনপুট বৈশিষ্ট্যগুলি ব্যবহার করবেন এবং একটি লুকানো tf.keras.layers.Dense স্তর সমন্বিত আপনার অগভীর মডেলে সেগুলিকে খাওয়াবেন৷ তারপরে, আপনি অনেক লেবেলযুক্ত ডেটার প্রয়োজন ছাড়াই অডিও শ্রেণীবিভাগের জন্য অল্প পরিমাণ ডেটার উপর নেটওয়ার্ককে প্রশিক্ষণ দেবেন এবং শেষ থেকে শেষ পর্যন্ত প্রশিক্ষণ দেবেন। (এটি আরও তথ্যের জন্য টেনসরফ্লো হাবের সাথে ইমেজ শ্রেণীবিভাগের জন্য ট্রান্সফার লার্নিংয়ের অনুরূপ।)
প্রথমে, আপনি মডেলটি পরীক্ষা করবেন এবং অডিও শ্রেণীবদ্ধ করার ফলাফল দেখতে পাবেন। তারপরে আপনি ডেটা প্রাক-প্রসেসিং পাইপলাইন তৈরি করবেন।
TensorFlow হাব থেকে YAMNet লোড হচ্ছে
আপনি সাউন্ড ফাইল থেকে এমবেডিংগুলি বের করতে টেনসরফ্লো হাব থেকে একটি প্রাক-প্রশিক্ষিত YAMNet ব্যবহার করতে যাচ্ছেন।
TensorFlow Hub থেকে একটি মডেল লোড করা সহজ: মডেলটি চয়ন করুন, এর URL অনুলিপি করুন এবং load ফাংশনটি ব্যবহার করুন৷
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
মডেল লোড হওয়ার সাথে সাথে, আপনি YAMNet মৌলিক ব্যবহারের টিউটোরিয়াল অনুসরণ করতে পারেন এবং অনুমান চালানোর জন্য একটি নমুনা WAV ফাইল ডাউনলোড করতে পারেন।
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
অডিও ফাইল লোড করার জন্য আপনার একটি ফাংশনের প্রয়োজন হবে, যা পরবর্তীতে প্রশিক্ষণের ডেটা নিয়ে কাজ করার সময়ও ব্যবহার করা হবে। ( সাধারণ অডিও স্বীকৃতিতে অডিও ফাইল এবং তাদের লেবেল পড়ার বিষয়ে আরও জানুন।
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

ক্লাস ম্যাপিং লোড করুন
YAMNet চিনতে সক্ষম এমন ক্লাসের নামগুলি লোড করা গুরুত্বপূর্ণ৷ ম্যাপিং ফাইলটি CSV ফরম্যাটে yamnet_model.class_map_path() এ উপস্থিত রয়েছে।
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
অনুমান চালান
YAMNet ফ্রেম-স্তরের ক্লাস-স্কোর প্রদান করে (যেমন, প্রতিটি ফ্রেমের জন্য 521 স্কোর)। ক্লিপ-স্তরের ভবিষ্যদ্বাণী নির্ধারণ করার জন্য, স্কোরগুলি ফ্রেম জুড়ে প্রতি-শ্রেণীতে একত্রিত করা যেতে পারে (যেমন, গড় বা সর্বাধিক সমষ্টি ব্যবহার করে)। এটি নিচে scores_np.mean(axis=0) দ্বারা করা হয়েছে। অবশেষে, ক্লিপ-লেভেলে সর্বোচ্চ স্কোর করা ক্লাস খুঁজে পেতে, আপনি সর্বাধিক 521টি সমষ্টিগত স্কোর নিন।
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
ESC-50 ডেটাসেট
ESC-50 ডেটাসেট ( Piczak, 2015 ) হল 2,000 পাঁচ-সেকেন্ড দীর্ঘ পরিবেশগত অডিও রেকর্ডিংয়ের একটি লেবেলযুক্ত সংগ্রহ৷ ডেটাসেট 50টি ক্লাস নিয়ে গঠিত, প্রতি ক্লাসে 40টি উদাহরণ সহ।
ডেটাসেট ডাউনলোড করুন এবং এক্সট্রাক্ট করুন।
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
তথ্য অন্বেষণ
প্রতিটি ফাইলের জন্য মেটাডেটা ./datasets/ESC-50-master/meta/esc50.csv এ csv ফাইলে নির্দিষ্ট করা আছে
এবং সমস্ত অডিও ফাইল ./datasets/ESC-50-master/audio/ এ রয়েছে
আপনি ম্যাপিং সহ একটি DataFrame তৈরি করবেন এবং ডেটার পরিষ্কার দৃশ্যের জন্য এটি ব্যবহার করবেন।
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
ডেটা ফিল্টার করুন
এখন ডেটা DataFrame ডেটা সংরক্ষণ করা হয়েছে, কিছু রূপান্তর প্রয়োগ করুন:
- সারিগুলি ফিল্টার করুন এবং শুধুমাত্র নির্বাচিত ক্লাসগুলি ব্যবহার করুন -
dogএবংcat৷ আপনি যদি অন্য কোনো ক্লাস ব্যবহার করতে চান তবে এখানেই আপনি সেগুলি বেছে নিতে পারেন। - সম্পূর্ণ পথ পেতে ফাইলের নাম সংশোধন করুন। এটি পরে লোড করা সহজ করে তুলবে।
- একটি নির্দিষ্ট পরিসরের মধ্যে হতে লক্ষ্য পরিবর্তন করুন। এই উদাহরণে,
dog0এ থাকবে, কিন্তুcat5এর আসল মানের পরিবর্তে1হয়ে যাবে।
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
অডিও ফাইল লোড করুন এবং এম্বেডিং পুনরুদ্ধার করুন
এখানে আপনি load_wav_16k_mono প্রয়োগ করবেন এবং মডেলের জন্য WAV ডেটা প্রস্তুত করবেন।
WAV ডেটা থেকে এমবেডিং বের করার সময়, আপনি একটি অ্যারে অফ আকৃতি পাবেন (N, 1024) যেখানে N হল YAMNet পাওয়া ফ্রেমের সংখ্যা (প্রতি 0.48 সেকেন্ডের অডিওর জন্য একটি)।
আপনার মডেল প্রতিটি ফ্রেমকে একটি ইনপুট হিসাবে ব্যবহার করবে। অতএব, আপনাকে একটি নতুন কলাম তৈরি করতে হবে যাতে প্রতি সারিতে একটি ফ্রেম থাকে। এই নতুন সারিগুলিকে সঠিকভাবে প্রতিফলিত করতে আপনাকে লেবেল এবং fold কলাম প্রসারিত করতে হবে।
প্রসারিত fold কলাম মূল মান রাখে। আপনি ফ্রেমগুলিকে মিশ্রিত করতে পারবেন না কারণ, স্প্লিটগুলি সম্পাদন করার সময়, আপনার কাছে একই অডিওর অংশগুলি বিভিন্ন স্প্লিটে থাকতে পারে, যা আপনার বৈধতা এবং পরীক্ষার পদক্ষেপগুলিকে কম কার্যকর করে তুলবে৷
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
ডেটা বিভক্ত করুন
আপনি fold কলাম ব্যবহার করে ডেটাসেটকে ট্রেন, বৈধতা এবং পরীক্ষা সেটে বিভক্ত করবেন।
ESC-50 পাঁচটি অভিন্ন আকারের ক্রস-ভ্যালিডেশন fold s-এ সাজানো হয়েছে, যাতে একই মূল উৎস থেকে ক্লিপগুলি সবসময় একই fold থাকে - ESC: পরিবেশগত শব্দ শ্রেণীবিভাগের জন্য ডেটাসেট পেপারে আরও জানুন।
শেষ ধাপ হল ডেটাসেট থেকে fold কলামটি সরিয়ে ফেলা যেহেতু আপনি প্রশিক্ষণের সময় এটি ব্যবহার করতে যাচ্ছেন না।
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
আপনার মডেল তৈরি করুন
আপনি বেশিরভাগ কাজ করেছেন! এর পরে, শব্দ থেকে বিড়াল এবং কুকুর চিনতে একটি লুকানো স্তর এবং দুটি আউটপুট সহ একটি খুব সাধারণ অনুক্রমিক মডেল সংজ্ঞায়িত করুন।
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
পরীক্ষার ডেটাতে evaluate পদ্ধতিটি চালানো যাক শুধুমাত্র নিশ্চিত হওয়ার জন্য যে কোনও অতিরিক্ত ফিটিং নেই।
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
তুমি এটি করেছিলে!
আপনার মডেল পরীক্ষা করুন
এর পরে, শুধুমাত্র YAMNet ব্যবহার করে পূর্ববর্তী পরীক্ষা থেকে এমবেডিংয়ে আপনার মডেলটি চেষ্টা করুন।
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
একটি মডেল সংরক্ষণ করুন যা সরাসরি ইনপুট হিসাবে একটি WAV ফাইল নিতে পারে
আপনার মডেল কাজ করে যখন আপনি এটিকে ইনপুট হিসাবে এমবেডিং দেন।
একটি বাস্তব-বিশ্বের পরিস্থিতিতে, আপনি সরাসরি ইনপুট হিসাবে অডিও ডেটা ব্যবহার করতে চাইবেন।
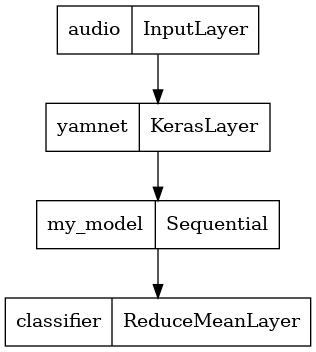
এটি করতে, আপনি আপনার মডেলের সাথে YAMNet কে একটি একক মডেলে একত্রিত করবেন যা আপনি অন্যান্য অ্যাপ্লিকেশনের জন্য রপ্তানি করতে পারেন৷
মডেলের ফলাফল ব্যবহার করা সহজ করার জন্য, চূড়ান্ত স্তর হবে একটি reduce_mean অপারেশন। পরিবেশনের জন্য এই মডেলটি ব্যবহার করার সময় (যা সম্পর্কে আপনি পরে টিউটোরিয়ালটিতে শিখবেন), আপনার চূড়ান্ত স্তরটির নাম প্রয়োজন হবে। আপনি যদি একটি সংজ্ঞায়িত না করেন, TensorFlow একটি ক্রমবর্ধমান স্বয়ংক্রিয়ভাবে সংজ্ঞায়িত করবে যা পরীক্ষা করা কঠিন করে তোলে, কারণ আপনি যখনই মডেলকে প্রশিক্ষণ দেবেন তখন এটি পরিবর্তন হতে থাকবে। একটি কাঁচা TensorFlow অপারেশন ব্যবহার করার সময়, আপনি এটিতে একটি নাম বরাদ্দ করতে পারবেন না। এই সমস্যাটির সমাধান করার জন্য, আপনি একটি কাস্টম স্তর তৈরি করবেন যা প্রযোজ্য হবে reduce_mean এবং এটিকে 'classifier' বলুন।
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
এটি প্রত্যাশিত হিসাবে কাজ করে তা যাচাই করতে আপনার সংরক্ষিত মডেল লোড করুন৷
reloaded_model = tf.saved_model.load(saved_model_path)
এবং চূড়ান্ত পরীক্ষার জন্য: কিছু শব্দ তথ্য দেওয়া, আপনার মডেল সঠিক ফলাফল ফিরিয়ে দেয়?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
আপনি যদি একটি পরিবেশন সেটআপে আপনার নতুন মডেল চেষ্টা করতে চান, আপনি 'serving_default' স্বাক্ষর ব্যবহার করতে পারেন।
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(ঐচ্ছিক) আরও কিছু পরীক্ষা
মডেল প্রস্তুত.
পরীক্ষা ডেটাসেটে YAMNet এর সাথে এর তুলনা করা যাক।
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
পরবর্তী পদক্ষেপ
আপনি একটি মডেল তৈরি করেছেন যা কুকুর বা বিড়াল থেকে শব্দ শ্রেণীবদ্ধ করতে পারে। একই ধারণা এবং একটি ভিন্ন ডেটাসেট দিয়ে আপনি চেষ্টা করতে পারেন, উদাহরণস্বরূপ, পাখিদের গানের উপর ভিত্তি করে একটি অ্যাকোস্টিক শনাক্তকারী তৈরি করা।
সোশ্যাল মিডিয়াতে TensorFlow টিমের সাথে আপনার প্রোজেক্ট শেয়ার করুন!