
| | |  Visualizza su GitHub Visualizza su GitHub | | |
YAMNet è una rete neurale profonda pre-addestrata in grado di prevedere eventi audio da 521 classi , come risate, abbaiati o una sirena.
In questo tutorial imparerai come:
- Carica e usa il modello YAMNet per l'inferenza.
- Costruisci un nuovo modello utilizzando gli incorporamenti di YAMNet per classificare i suoni di cani e gatti.
- Valuta ed esporta il tuo modello.
Importa TensorFlow e altre librerie
Inizia installando TensorFlow I/O , che ti semplificherà il caricamento di file audio dal disco.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
A proposito di YAMNet
YAMNet è una rete neurale pre-addestrata che utilizza l'architettura di convoluzione separabile in profondità MobileNetV1 . Può utilizzare una forma d'onda audio come input e fare previsioni indipendenti per ciascuno dei 521 eventi audio dal corpus AudioSet .
Internamente, il modello estrae i "frame" dal segnale audio ed elabora i batch di questi frame. Questa versione del modello utilizza frame lunghi 0,96 secondi ed estrae un frame ogni 0,48 secondi.
Il modello accetta un array 1-D float32 Tensor o NumPy contenente una forma d'onda di lunghezza arbitraria, rappresentata come campioni a canale singolo (mono) a 16 kHz nell'intervallo [-1.0, +1.0] . Questo tutorial contiene codice per aiutarti a convertire i file WAV nel formato supportato.
Il modello restituisce 3 output, inclusi i punteggi della classe, gli incorporamenti (che utilizzerai per trasferire l'apprendimento) e lo spettrogramma log mel . Puoi trovare maggiori dettagli qui .
Un uso specifico di YAMNet è come estrattore di funzionalità di alto livello: l'output di incorporamento a 1.024 dimensioni. Utilizzerai le funzionalità di input del modello di base (YAMNet) e le inserirai nel tuo modello meno profondo costituito da uno strato nascosto tf.keras.layers.Dense . Quindi, addestrerai la rete su una piccola quantità di dati per la classificazione audio senza richiedere molti dati etichettati e formazione end-to-end. (Questo è simile al trasferimento dell'apprendimento per la classificazione delle immagini con TensorFlow Hub per ulteriori informazioni.)
Innanzitutto, testerai il modello e vedrai i risultati della classificazione dell'audio. Quindi costruirai la pipeline di pre-elaborazione dei dati.
Caricamento di YAMNet da TensorFlow Hub
Utilizzerai uno YAMNet pre-addestrato da Tensorflow Hub per estrarre gli incorporamenti dai file audio.
Il caricamento di un modello da TensorFlow Hub è semplice: scegli il modello, copia il suo URL e utilizza la funzione di load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Con il modello caricato, puoi seguire il tutorial sull'utilizzo di base di YAMNet e scaricare un file WAV di esempio per eseguire l'inferenza.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Avrai bisogno di una funzione per caricare i file audio, che verrà utilizzata anche in seguito quando si lavora con i dati di allenamento. (Ulteriori informazioni sulla lettura dei file audio e delle relative etichette in Riconoscimento audio semplice .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Carica la mappatura della classe
È importante caricare i nomi delle classi che YAMNet è in grado di riconoscere. Il file di mappatura è presente in yamnet_model.class_map_path() nel formato CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
Esegui l'inferenza
YAMNet fornisce punteggi di classe a livello di frame (ovvero 521 punteggi per ogni frame). Al fine di determinare le previsioni a livello di clip, i punteggi possono essere aggregati per classe tra i fotogrammi (ad esempio, utilizzando l'aggregazione media o massima). Questo viene fatto di seguito da scores_np.mean(axis=0) . Infine, per trovare la classe con il punteggio più alto a livello di clip, prendi il massimo dei 521 punteggi aggregati.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
Set di dati ESC-50
Il set di dati ESC-50 ( Piczak, 2015 ) è una raccolta etichettata di 2.000 registrazioni audio ambientali lunghe cinque secondi. Il set di dati è composto da 50 classi, con 40 esempi per classe.
Scarica il set di dati ed estrailo.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Esplora i dati
I metadati per ogni file sono specificati nel file CSV in ./datasets/ESC-50-master/meta/esc50.csv
e tutti i file audio sono in ./datasets/ESC-50-master/audio/
Creerai un DataFrame panda con la mappatura e la utilizzerai per avere una visione più chiara dei dati.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Filtra i dati
Ora che i dati sono archiviati in DataFrame , applica alcune trasformazioni:
- Filtra le righe e usa solo le classi selezionate:
dogecat. Se vuoi usare altre classi, qui puoi sceglierle. - Modifica il nome del file per avere il percorso completo. Questo faciliterà il caricamento in seguito.
- Modifica gli obiettivi in modo che rientrino in un intervallo specifico. In questo esempio,
dogrimarrà a0, macatdiventerà1invece del suo valore originale di5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Carica i file audio e recupera gli incorporamenti
Qui applicherai load_wav_16k_mono e preparerai i dati WAV per il modello.
Quando si estraggono gli incorporamenti dai dati WAV, si ottiene un array di forma (N, 1024) dove N è il numero di fotogrammi trovati da YAMNet (uno ogni 0,48 secondi di audio).
Il tuo modello utilizzerà ogni frame come un input. Pertanto, è necessario creare una nuova colonna con un frame per riga. Devi anche espandere le etichette e la colonna fold per riflettere correttamente queste nuove righe.
La colonna di fold espansa mantiene i valori originali. Non puoi mischiare i fotogrammi perché, quando esegui le divisioni, potresti finire per avere parti dello stesso audio su divisioni diverse, il che renderebbe meno efficaci le tue fasi di convalida e test.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
Dividi i dati
Utilizzerai la colonna fold per suddividere il set di dati in set di treni, convalida e test.
L'ESC-50 è organizzato in cinque fold di convalida incrociata di dimensioni uniformi, in modo tale che le clip della stessa fonte originale siano sempre nella stessa fold - scopri di più nell'ESC: Dataset for Environmental Sound Classification paper.
L'ultimo passaggio consiste nel rimuovere la colonna fold dal set di dati poiché non la utilizzerai durante l'allenamento.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Crea il tuo modello
Hai fatto la maggior parte del lavoro! Quindi, definisci un modello sequenziale molto semplice con un livello nascosto e due uscite per riconoscere cani e gatti dai suoni.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Eseguiamo il metodo di evaluate sui dati del test solo per essere sicuri che non ci sia overfitting.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
Ce l'hai fatta!
Metti alla prova il tuo modello
Quindi, prova il tuo modello sull'incorporamento del test precedente utilizzando solo YAMNet.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Salva un modello che può prendere direttamente un file WAV come input
Il tuo modello funziona quando gli dai gli incorporamenti come input.
In uno scenario reale, ti consigliamo di utilizzare i dati audio come input diretto.
Per fare ciò, combinerai YAMNet con il tuo modello in un unico modello che puoi esportare per altre applicazioni.
Per semplificare l'utilizzo del risultato del modello, il livello finale sarà un'operazione reduce_mean . Quando usi questo modello per servire (che imparerai più avanti nel tutorial), avrai bisogno del nome del livello finale. Se non ne definisci uno, TensorFlow ne definirà automaticamente uno incrementale che rende difficile il test, poiché continuerà a cambiare ogni volta che si addestra il modello. Quando si utilizza un'operazione TensorFlow grezza, non è possibile assegnarle un nome. Per risolvere questo problema, creerai un livello personalizzato che applica reduce_mean e lo chiamerai 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
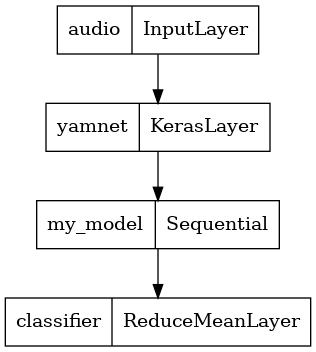
Carica il tuo modello salvato per verificare che funzioni come previsto.
reloaded_model = tf.saved_model.load(saved_model_path)
E per il test finale: dati alcuni dati sonori, il tuo modello restituisce il risultato corretto?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Se vuoi provare il tuo nuovo modello su una configurazione di servizio, puoi utilizzare la firma 'serving_default'.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(Facoltativo) Altri test
Il modello è pronto.
Confrontiamolo con YAMNet sul set di dati di test.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Prossimi passi
Hai creato un modello in grado di classificare i suoni di cani o gatti. Con la stessa idea e un set di dati diverso puoi provare, ad esempio, a costruire un identificatore acustico degli uccelli basato sul loro canto.
Condividi il tuo progetto con il team di TensorFlow sui social media!