
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questo tutorial crea un esempio contraddittorio utilizzando l'attacco Fast Gradient Signed Method (FGSM) come descritto in Spiegazione e utilizzo di esempi contraddittori di Goodfellow et al . Questo è stato uno dei primi e più popolari attacchi per ingannare una rete neurale.
Che cos'è un esempio contraddittorio?
Gli esempi contraddittori sono input specializzati creati con lo scopo di confondere una rete neurale, con conseguente errata classificazione di un determinato input. Questi famigerati input sono indistinguibili dall'occhio umano, ma fanno sì che la rete non riesca a identificare i contenuti dell'immagine. Esistono diversi tipi di attacchi di questo tipo, tuttavia, qui l'attenzione è concentrata sull'attacco del metodo del segno del gradiente veloce, che è un attacco a scatola bianca il cui obiettivo è garantire un'errata classificazione. Un attacco con scatola bianca è il punto in cui l'attaccante ha accesso completo al modello che viene attaccato. Uno degli esempi più famosi di un'immagine contraddittoria mostrata di seguito è tratto dal suddetto articolo.

Qui, a partire dall'immagine di un panda, l'attaccante aggiunge piccole perturbazioni (distorsioni) all'immagine originale, il che si traduce nel modello che etichetta questa immagine come un gibbone, con grande sicurezza. Il processo di aggiunta di queste perturbazioni è spiegato di seguito.
Metodo del segno di gradiente veloce
Il metodo del segno del gradiente veloce funziona utilizzando i gradienti della rete neurale per creare un esempio contraddittorio. Per un'immagine di input, il metodo utilizza i gradienti della perdita rispetto all'immagine di input per creare una nuova immagine che massimizza la perdita. Questa nuova immagine è chiamata immagine contraddittoria. Questo può essere riassunto usando la seguente espressione:
\[adv\_x = x + \epsilon*\text{sign}(\nabla_xJ(\theta, x, y))\]
dove
- adv_x : Immagine contraddittoria.
- x : immagine di input originale.
- y : Etichetta di input originale.
- \(\epsilon\) : Moltiplicatore per garantire che le perturbazioni siano piccole.
- \(\theta\) : parametri del modello.
- \(J\) : Perdita.
Una proprietà interessante qui è il fatto che i gradienti sono presi rispetto all'immagine di input. Questo viene fatto perché l'obiettivo è creare un'immagine che massimizzi la perdita. Un metodo per ottenere ciò è trovare quanto ogni pixel nell'immagine contribuisce al valore della perdita e aggiungere una perturbazione di conseguenza. Funziona abbastanza velocemente perché è facile scoprire come ogni pixel di input contribuisce alla perdita usando la regola della catena e trovando i gradienti richiesti. Quindi, i gradienti vengono presi rispetto all'immagine. Inoltre, poiché il modello non viene più addestrato (quindi il gradiente non viene preso rispetto alle variabili addestrabili, ovvero i parametri del modello), e quindi i parametri del modello rimangono costanti. L'unico obiettivo è ingannare un modello già addestrato.
Quindi proviamo a ingannare un modello preaddestrato. In questo tutorial, il modello è MobileNetV2 , preaddestrato su ImageNet .
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
Carichiamo il modello MobileNetV2 preaddestrato ei nomi delle classi ImageNet.
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224.h5 14540800/14536120 [==============================] - 0s 0us/step 14548992/14536120 [==============================] - 0s 0us/step
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
Immagine originale
Usiamo un'immagine di esempio di un Labrador Retriever di Mirko CC-BY-SA 3.0 da Wikimedia Common e creiamo da essa esempi contraddittori. Il primo passaggio consiste nel preelaborarlo in modo che possa essere alimentato come input per il modello MobileNetV2.
{kind=link}
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg 90112/83281 [================================] - 0s 0us/step 98304/83281 [===================================] - 0s 0us/step
Diamo un'occhiata all'immagine.
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step 49152/35363 [=========================================] - 0s 0us/step

Crea l'immagine del contraddittorio
Implementazione del metodo del segno di gradiente veloce
Il primo passo è creare perturbazioni che verranno utilizzate per distorcere l'immagine originale risultando in un'immagine contraddittoria. Come accennato, per questo compito, i gradienti vengono presi rispetto all'immagine.
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
Le perturbazioni risultanti possono anche essere visualizzate.
# Get the input label of the image.
labrador_retriever_index = 208
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]
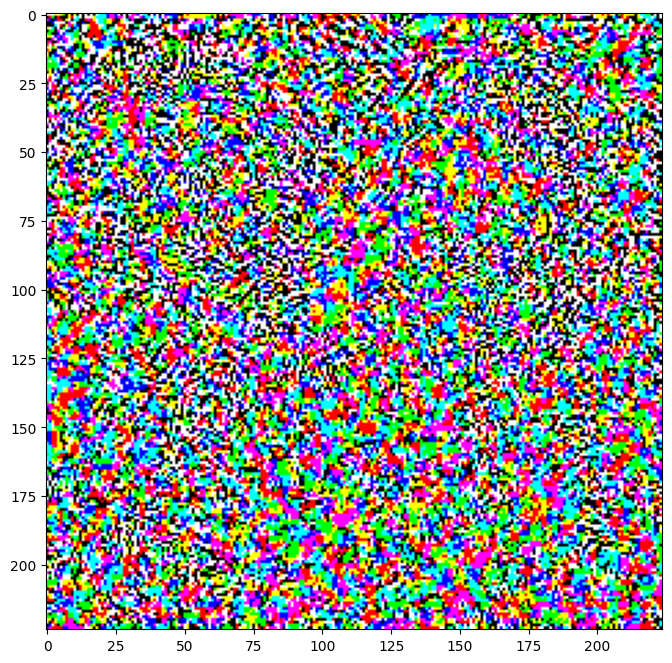
Proviamo questo per diversi valori di epsilon e osserviamo l'immagine risultante. Noterai che all'aumentare del valore di epsilon, diventa più facile ingannare la rete. Tuttavia, questo si presenta come un compromesso che fa sì che le perturbazioni diventino più identificabili.
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])



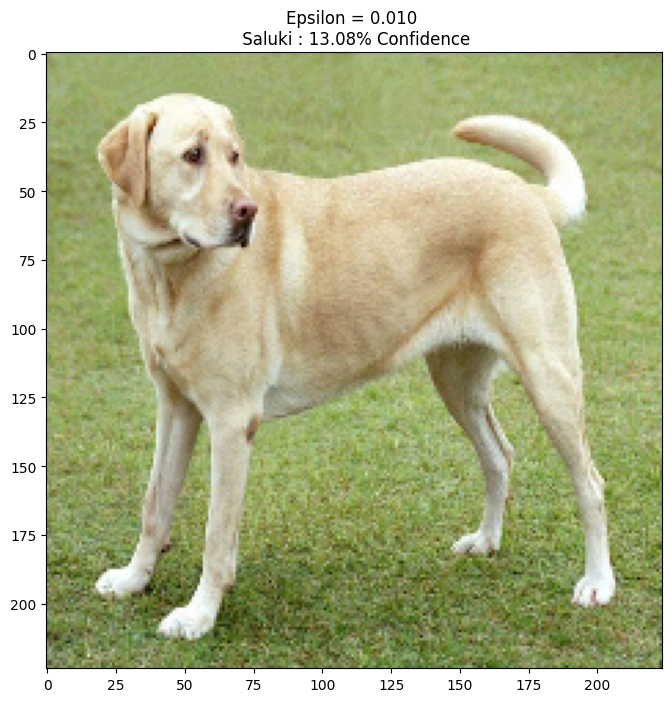
Prossimi passi
Ora che conosci gli attacchi avversari, provalo su diversi set di dati e architetture diverse. Puoi anche creare e addestrare il tuo modello, quindi tentare di ingannarlo usando lo stesso metodo. Puoi anche provare a vedere come varia la fiducia nelle previsioni quando cambi epsilon.
Sebbene potente, l'attacco mostrato in questo tutorial è stato solo l'inizio della ricerca sugli attacchi del contraddittorio e da allora ci sono stati più documenti che hanno creato attacchi più potenti. Oltre agli attacchi contraddittori, la ricerca ha portato anche alla creazione di difese, che mira a creare solidi modelli di machine learning. Puoi rivedere questo documento di indagine per un elenco completo di attacchi e difese contraddittori.
Per molte altre implementazioni di attacchi e difese contraddittorio, potresti voler vedere la libreria di esempi contraddittoria CleverHans .