
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি তিনটি উদাহরণ সহ অটোএনকোডারের সাথে পরিচয় করিয়ে দেয়: বেসিক, ইমেজ ডিনোইসিং এবং অসঙ্গতি সনাক্তকরণ।
একটি অটোএনকোডার হল একটি বিশেষ ধরনের নিউরাল নেটওয়ার্ক যা তার ইনপুটকে তার আউটপুটে অনুলিপি করার জন্য প্রশিক্ষিত। উদাহরণস্বরূপ, একটি হস্তলিখিত অঙ্কের একটি চিত্র দেওয়া হলে, একটি অটোএনকোডার প্রথমে চিত্রটিকে একটি নিম্ন মাত্রিক সুপ্ত প্রতিনিধিত্বে এনকোড করে, তারপরে সুপ্ত উপস্থাপনাটিকে একটি চিত্রে ডিকোড করে। একটি অটোএনকোডার পুনর্গঠন ত্রুটি কমিয়ে ডেটা সংকুচিত করতে শেখে।
অটোএনকোডার সম্পর্কে আরও জানতে, অনুগ্রহ করে ইয়ান গুডফেলো, ইয়োশুয়া বেঙ্গিও এবং অ্যারন কোরভিলের ডিপ লার্নিং থেকে অধ্যায় 14 পড়ার কথা বিবেচনা করুন।
TensorFlow এবং অন্যান্য লাইব্রেরি আমদানি করুন
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
from tensorflow.keras import layers, losses
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Model
ডেটাসেট লোড করুন
শুরু করতে, আপনি ফ্যাশন MNIST ডেটাসেট ব্যবহার করে মৌলিক অটোএনকোডারকে প্রশিক্ষণ দেবেন। এই ডেটাসেটের প্রতিটি চিত্র 28x28 পিক্সেল।
(x_train, _), (x_test, _) = fashion_mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
print (x_train.shape)
print (x_test.shape)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step (60000, 28, 28) (10000, 28, 28)
প্রথম উদাহরণ: মৌলিক অটোএনকোডার

দুটি ঘন স্তর সহ একটি অটোএনকোডারকে সংজ্ঞায়িত করুন: একটি encoder , যা চিত্রগুলিকে একটি 64 মাত্রিক সুপ্ত ভেক্টরে সংকুচিত করে এবং একটি decoder , যা সুপ্ত স্থান থেকে আসল চিত্রটিকে পুনর্গঠন করে৷
আপনার মডেল সংজ্ঞায়িত করতে, কেরাস মডেল সাবক্লাসিং API ব্যবহার করুন।
latent_dim = 64
class Autoencoder(Model):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential([
layers.Flatten(),
layers.Dense(latent_dim, activation='relu'),
])
self.decoder = tf.keras.Sequential([
layers.Dense(784, activation='sigmoid'),
layers.Reshape((28, 28))
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = Autoencoder(latent_dim)
autoencoder.compile(optimizer='adam', loss=losses.MeanSquaredError())
ইনপুট এবং লক্ষ্য উভয় হিসাবে x_train ব্যবহার করে মডেলকে প্রশিক্ষণ দিন। encoder 784 মাত্রা থেকে সুপ্ত স্থান থেকে ডেটাসেটকে সংকুচিত করতে শিখবে এবং decoder আসল চিত্রগুলিকে পুনর্গঠন করতে শিখবে। .
autoencoder.fit(x_train, x_train,
epochs=10,
shuffle=True,
validation_data=(x_test, x_test))
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.0243 - val_loss: 0.0140 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0116 - val_loss: 0.0106 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0100 - val_loss: 0.0098 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0094 - val_loss: 0.0094 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0092 - val_loss: 0.0092 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0090 - val_loss: 0.0091 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0090 - val_loss: 0.0090 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0089 - val_loss: 0.0090 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0088 - val_loss: 0.0089 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0088 - val_loss: 0.0089 <keras.callbacks.History at 0x7ff1d35df550>
এখন যেহেতু মডেলটি প্রশিক্ষিত হয়েছে, আসুন পরীক্ষা সেট থেকে ছবিগুলিকে এনকোডিং এবং ডিকোডিং করে পরীক্ষা করি৷
encoded_imgs = autoencoder.encoder(x_test).numpy()
decoded_imgs = autoencoder.decoder(encoded_imgs).numpy()
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i])
plt.title("original")
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i])
plt.title("reconstructed")
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

দ্বিতীয় উদাহরণ: ইমেজ denoising

একটি অটোএনকোডারকে ছবি থেকে শব্দ অপসারণ করতেও প্রশিক্ষণ দেওয়া যেতে পারে। নিম্নলিখিত বিভাগে, আপনি প্রতিটি ছবিতে এলোমেলো শব্দ প্রয়োগ করে ফ্যাশন MNIST ডেটাসেটের একটি কোলাহলপূর্ণ সংস্করণ তৈরি করবেন। তারপরে আপনি একটি স্বয়ংক্রিয় এনকোডারকে ইনপুট হিসাবে শোরগোল ইমেজ ব্যবহার করে এবং আসল চিত্রটিকে লক্ষ্য হিসাবে প্রশিক্ষণ দেবেন।
আগে করা পরিবর্তনগুলি বাদ দিতে ডেটাসেটটি পুনরায় আমদানি করা যাক।
(x_train, _), (x_test, _) = fashion_mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
print(x_train.shape)
(60000, 28, 28, 1)
ইমেজ এলোমেলো শব্দ যোগ করা
noise_factor = 0.2
x_train_noisy = x_train + noise_factor * tf.random.normal(shape=x_train.shape)
x_test_noisy = x_test + noise_factor * tf.random.normal(shape=x_test.shape)
x_train_noisy = tf.clip_by_value(x_train_noisy, clip_value_min=0., clip_value_max=1.)
x_test_noisy = tf.clip_by_value(x_test_noisy, clip_value_min=0., clip_value_max=1.)
শোরগোল ইমেজ প্লট.
n = 10
plt.figure(figsize=(20, 2))
for i in range(n):
ax = plt.subplot(1, n, i + 1)
plt.title("original + noise")
plt.imshow(tf.squeeze(x_test_noisy[i]))
plt.gray()
plt.show()

একটি কনভোলিউশনাল অটোএনকোডার সংজ্ঞায়িত করুন
এই উদাহরণে, আপনি encoder Conv2D স্তরগুলি এবং decoder Conv2DT ট্রান্সপোজ স্তরগুলি ব্যবহার করে একটি রূপান্তরমূলক অটোএনকোডারকে প্রশিক্ষণ দেবেন৷
class Denoise(Model):
def __init__(self):
super(Denoise, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Input(shape=(28, 28, 1)),
layers.Conv2D(16, (3, 3), activation='relu', padding='same', strides=2),
layers.Conv2D(8, (3, 3), activation='relu', padding='same', strides=2)])
self.decoder = tf.keras.Sequential([
layers.Conv2DTranspose(8, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2D(1, kernel_size=(3, 3), activation='sigmoid', padding='same')])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = Denoise()
autoencoder.compile(optimizer='adam', loss=losses.MeanSquaredError())
autoencoder.fit(x_train_noisy, x_train,
epochs=10,
shuffle=True,
validation_data=(x_test_noisy, x_test))
Epoch 1/10 1875/1875 [==============================] - 8s 3ms/step - loss: 0.0169 - val_loss: 0.0107 Epoch 2/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0095 - val_loss: 0.0086 Epoch 3/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0082 - val_loss: 0.0080 Epoch 4/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0078 - val_loss: 0.0077 Epoch 5/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0076 - val_loss: 0.0075 Epoch 6/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0074 - val_loss: 0.0074 Epoch 7/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0073 - val_loss: 0.0073 Epoch 8/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0072 - val_loss: 0.0072 Epoch 9/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0071 - val_loss: 0.0071 Epoch 10/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0070 - val_loss: 0.0071 <keras.callbacks.History at 0x7ff1c45a31d0>
আসুন এনকোডারের একটি সারাংশ দেখে নেওয়া যাক। লক্ষ্য করুন কিভাবে 28x28 থেকে 7x7 পর্যন্ত চিত্রগুলি ডাউনস্যাম্প করা হয়েছে।
autoencoder.encoder.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 14, 14, 16) 160
conv2d_1 (Conv2D) (None, 7, 7, 8) 1160
=================================================================
Total params: 1,320
Trainable params: 1,320
Non-trainable params: 0
_________________________________________________________________
ডিকোডারটি 7x7 থেকে 28x28 পর্যন্ত চিত্রগুলির নমুনা দেয়৷
autoencoder.decoder.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_transpose (Conv2DTra (None, 14, 14, 8) 584
nspose)
conv2d_transpose_1 (Conv2DT (None, 28, 28, 16) 1168
ranspose)
conv2d_2 (Conv2D) (None, 28, 28, 1) 145
=================================================================
Total params: 1,897
Trainable params: 1,897
Non-trainable params: 0
_________________________________________________________________
অটোএনকোডার দ্বারা উত্পাদিত কোলাহলপূর্ণ চিত্র এবং অস্বীকৃত চিত্র উভয়ই প্লট করা।
encoded_imgs = autoencoder.encoder(x_test).numpy()
decoded_imgs = autoencoder.decoder(encoded_imgs).numpy()
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# display original + noise
ax = plt.subplot(2, n, i + 1)
plt.title("original + noise")
plt.imshow(tf.squeeze(x_test_noisy[i]))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
bx = plt.subplot(2, n, i + n + 1)
plt.title("reconstructed")
plt.imshow(tf.squeeze(decoded_imgs[i]))
plt.gray()
bx.get_xaxis().set_visible(False)
bx.get_yaxis().set_visible(False)
plt.show()

তৃতীয় উদাহরণ: অসঙ্গতি সনাক্তকরণ
ওভারভিউ
এই উদাহরণে, আপনি ECG5000 ডেটাসেটে অসঙ্গতি সনাক্ত করতে একটি অটোএনকোডারকে প্রশিক্ষণ দেবেন। এই ডেটাসেটে 5,000টি ইলেক্ট্রোকার্ডিওগ্রাম রয়েছে, প্রতিটিতে 140টি ডেটা পয়েন্ট রয়েছে৷ আপনি ডেটাসেটের একটি সরলীকৃত সংস্করণ ব্যবহার করবেন, যেখানে প্রতিটি উদাহরণকে 0 (একটি অস্বাভাবিক ছন্দের সাথে সম্পর্কিত), বা 1 (একটি স্বাভাবিক ছন্দের সাথে সম্পর্কিত) লেবেল করা হয়েছে। আপনি অস্বাভাবিক ছন্দ সনাক্ত করতে আগ্রহী.
কিভাবে আপনি একটি অটোএনকোডার ব্যবহার করে অসঙ্গতি সনাক্ত করবেন? মনে রাখবেন যে একটি অটোএনকোডার পুনর্গঠনের ত্রুটি কমানোর জন্য প্রশিক্ষিত। আপনি শুধুমাত্র স্বাভাবিক ছন্দে একটি অটোএনকোডার প্রশিক্ষণ দেবেন, তারপর সমস্ত ডেটা পুনর্গঠন করতে এটি ব্যবহার করুন। আমাদের অনুমান হল যে অস্বাভাবিক ছন্দে উচ্চতর পুনর্গঠন ত্রুটি থাকবে। তারপরে আপনি একটি ছন্দকে একটি অসঙ্গতি হিসাবে শ্রেণীবদ্ধ করবেন যদি পুনর্গঠনের ত্রুটি একটি নির্দিষ্ট থ্রেশহোল্ডকে অতিক্রম করে।
ইসিজি ডেটা লোড করুন
আপনি যে ডেটাসেটটি ব্যবহার করবেন তা timeseriesclassification.com থেকে একটির উপর ভিত্তি করে।
# Download the dataset
dataframe = pd.read_csv('http://storage.googleapis.com/download.tensorflow.org/data/ecg.csv', header=None)
raw_data = dataframe.values
dataframe.head()
# The last element contains the labels
labels = raw_data[:, -1]
# The other data points are the electrocadriogram data
data = raw_data[:, 0:-1]
train_data, test_data, train_labels, test_labels = train_test_split(
data, labels, test_size=0.2, random_state=21
)
ডেটাকে [0,1] তে স্বাভাবিক করুন।
min_val = tf.reduce_min(train_data)
max_val = tf.reduce_max(train_data)
train_data = (train_data - min_val) / (max_val - min_val)
test_data = (test_data - min_val) / (max_val - min_val)
train_data = tf.cast(train_data, tf.float32)
test_data = tf.cast(test_data, tf.float32)
আপনি শুধুমাত্র স্বাভাবিক ছন্দ ব্যবহার করে অটোএনকোডারকে প্রশিক্ষণ দেবেন, যা এই ডেটাসেটে 1 হিসাবে লেবেল করা হয়েছে। স্বাভাবিক ছন্দগুলিকে অস্বাভাবিক ছন্দ থেকে আলাদা করুন।
train_labels = train_labels.astype(bool)
test_labels = test_labels.astype(bool)
normal_train_data = train_data[train_labels]
normal_test_data = test_data[test_labels]
anomalous_train_data = train_data[~train_labels]
anomalous_test_data = test_data[~test_labels]
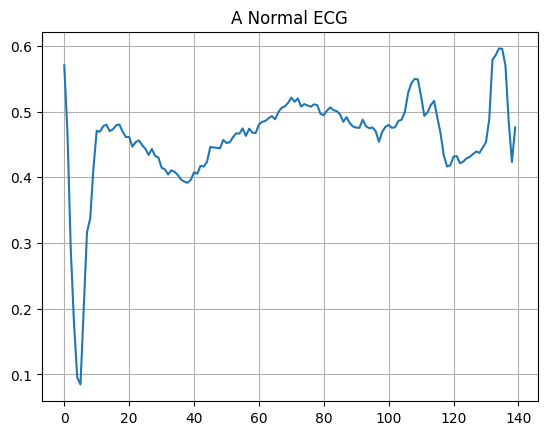
একটি সাধারণ ইসিজি প্লট করুন।
plt.grid()
plt.plot(np.arange(140), normal_train_data[0])
plt.title("A Normal ECG")
plt.show()
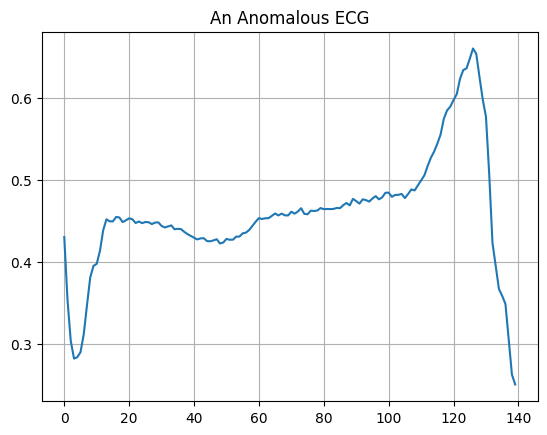
একটি অস্বাভাবিক ইসিজি প্লট করুন।
plt.grid()
plt.plot(np.arange(140), anomalous_train_data[0])
plt.title("An Anomalous ECG")
plt.show()
মডেল তৈরি করুন
class AnomalyDetector(Model):
def __init__(self):
super(AnomalyDetector, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Dense(32, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(8, activation="relu")])
self.decoder = tf.keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(32, activation="relu"),
layers.Dense(140, activation="sigmoid")])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = AnomalyDetector()
autoencoder.compile(optimizer='adam', loss='mae')
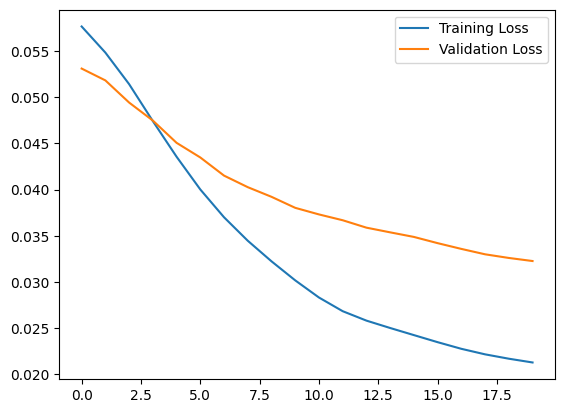
লক্ষ্য করুন যে অটোএনকোডারকে শুধুমাত্র সাধারণ ইসিজি ব্যবহার করে প্রশিক্ষিত করা হয়, তবে সম্পূর্ণ পরীক্ষার সেট ব্যবহার করে মূল্যায়ন করা হয়।
history = autoencoder.fit(normal_train_data, normal_train_data,
epochs=20,
batch_size=512,
validation_data=(test_data, test_data),
shuffle=True)
Epoch 1/20 5/5 [==============================] - 1s 33ms/step - loss: 0.0576 - val_loss: 0.0531 Epoch 2/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0552 - val_loss: 0.0514 Epoch 3/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0519 - val_loss: 0.0499 Epoch 4/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0483 - val_loss: 0.0475 Epoch 5/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0445 - val_loss: 0.0451 Epoch 6/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0409 - val_loss: 0.0432 Epoch 7/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0377 - val_loss: 0.0415 Epoch 8/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0348 - val_loss: 0.0401 Epoch 9/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0319 - val_loss: 0.0388 Epoch 10/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0293 - val_loss: 0.0378 Epoch 11/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0273 - val_loss: 0.0369 Epoch 12/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0259 - val_loss: 0.0361 Epoch 13/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0249 - val_loss: 0.0354 Epoch 14/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0239 - val_loss: 0.0346 Epoch 15/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0230 - val_loss: 0.0340 Epoch 16/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0222 - val_loss: 0.0335 Epoch 17/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0215 - val_loss: 0.0331 Epoch 18/20 5/5 [==============================] - 0s 9ms/step - loss: 0.0211 - val_loss: 0.0331 Epoch 19/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0208 - val_loss: 0.0329 Epoch 20/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0206 - val_loss: 0.0327
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.legend()
<matplotlib.legend.Legend at 0x7ff1d339b790>
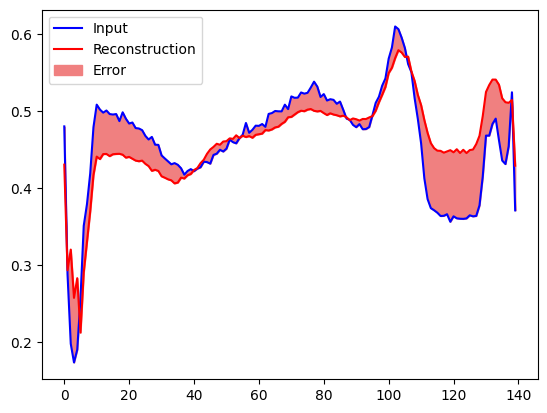
আপনি শীঘ্রই একটি ECG কে অস্বাভাবিক হিসাবে শ্রেণীবদ্ধ করবেন যদি পুনর্গঠনের ত্রুটি স্বাভাবিক প্রশিক্ষণের উদাহরণ থেকে একটি আদর্শ বিচ্যুতির চেয়ে বেশি হয়। প্রথমে, আসুন ট্রেনিং সেট থেকে একটি সাধারণ ইসিজি, অটোএনকোডার দ্বারা এনকোড এবং ডিকোড করার পরে পুনর্গঠন এবং পুনর্গঠন ত্রুটির প্লট করা যাক।
encoded_data = autoencoder.encoder(normal_test_data).numpy()
decoded_data = autoencoder.decoder(encoded_data).numpy()
plt.plot(normal_test_data[0], 'b')
plt.plot(decoded_data[0], 'r')
plt.fill_between(np.arange(140), decoded_data[0], normal_test_data[0], color='lightcoral')
plt.legend(labels=["Input", "Reconstruction", "Error"])
plt.show()
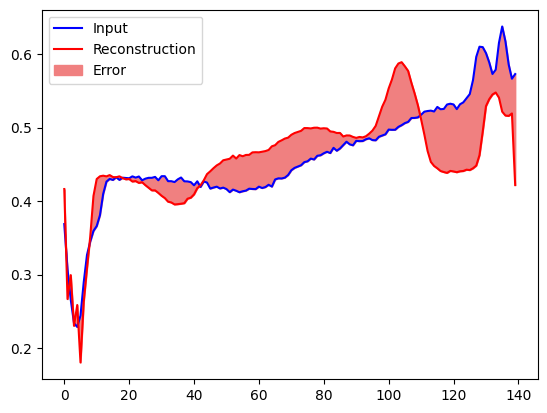
একটি অনুরূপ প্লট তৈরি করুন, এই সময় একটি অস্বাভাবিক পরীক্ষার উদাহরণের জন্য।
encoded_data = autoencoder.encoder(anomalous_test_data).numpy()
decoded_data = autoencoder.decoder(encoded_data).numpy()
plt.plot(anomalous_test_data[0], 'b')
plt.plot(decoded_data[0], 'r')
plt.fill_between(np.arange(140), decoded_data[0], anomalous_test_data[0], color='lightcoral')
plt.legend(labels=["Input", "Reconstruction", "Error"])
plt.show()
অসঙ্গতিগুলি সনাক্ত করুন
পুনর্গঠনের ক্ষতি একটি নির্দিষ্ট থ্রেশহোল্ডের চেয়ে বেশি কিনা তা গণনা করে অসঙ্গতিগুলি সনাক্ত করুন৷ এই টিউটোরিয়ালে, আপনি প্রশিক্ষণ সেট থেকে সাধারণ উদাহরণের গড় গড় ত্রুটি গণনা করবেন, তারপর ভবিষ্যতের উদাহরণগুলিকে অস্বাভাবিক হিসাবে শ্রেণীবদ্ধ করবেন যদি পুনর্গঠনের ত্রুটিটি প্রশিক্ষণ সেট থেকে একটি আদর্শ বিচ্যুতির চেয়ে বেশি হয়।
প্রশিক্ষণ সেট থেকে স্বাভাবিক ইসিজিতে পুনর্গঠনের ত্রুটি প্লট করুন
reconstructions = autoencoder.predict(normal_train_data)
train_loss = tf.keras.losses.mae(reconstructions, normal_train_data)
plt.hist(train_loss[None,:], bins=50)
plt.xlabel("Train loss")
plt.ylabel("No of examples")
plt.show()

একটি থ্রেশহোল্ড মান চয়ন করুন যা গড় থেকে উপরে একটি আদর্শ বিচ্যুতি।
threshold = np.mean(train_loss) + np.std(train_loss)
print("Threshold: ", threshold)
Threshold: 0.03241627
আপনি যদি পরীক্ষার সেটে অস্বাভাবিক উদাহরণগুলির জন্য পুনর্গঠন ত্রুটি পরীক্ষা করেন, আপনি লক্ষ্য করবেন যে অধিকাংশের থ্রেশহোল্ডের চেয়ে বেশি পুনর্গঠন ত্রুটি রয়েছে। থ্রেশহোল্ড পরিবর্তন করে, আপনি আপনার শ্রেণীবদ্ধকারীর নির্ভুলতা এবং প্রত্যাহার সমন্বয় করতে পারেন।
reconstructions = autoencoder.predict(anomalous_test_data)
test_loss = tf.keras.losses.mae(reconstructions, anomalous_test_data)
plt.hist(test_loss[None, :], bins=50)
plt.xlabel("Test loss")
plt.ylabel("No of examples")
plt.show()

পুনর্গঠন ত্রুটি থ্রেশহোল্ডের চেয়ে বেশি হলে একটি অসঙ্গতি হিসাবে একটি ECG শ্রেণীবদ্ধ করুন।
def predict(model, data, threshold):
reconstructions = model(data)
loss = tf.keras.losses.mae(reconstructions, data)
return tf.math.less(loss, threshold)
def print_stats(predictions, labels):
print("Accuracy = {}".format(accuracy_score(labels, predictions)))
print("Precision = {}".format(precision_score(labels, predictions)))
print("Recall = {}".format(recall_score(labels, predictions)))
preds = predict(autoencoder, test_data, threshold)
print_stats(preds, test_labels)
Accuracy = 0.944 Precision = 0.9921875 Recall = 0.9071428571428571
পরবর্তী পদক্ষেপ
অটোএনকোডারগুলির সাথে অসঙ্গতি সনাক্তকরণ সম্পর্কে আরও জানতে, ভিক্টর ডিবিয়ার TensorFlow.js এর সাথে নির্মিত এই দুর্দান্ত ইন্টারেক্টিভ উদাহরণটি দেখুন। বাস্তব-বিশ্ব ব্যবহারের ক্ষেত্রে, আপনি শিখতে পারেন যে কীভাবে এয়ারবাস টেনসরফ্লো ব্যবহার করে আইএসএস টেলিমেট্রি ডেটাতে অসঙ্গতি সনাক্ত করে। বেসিক সম্পর্কে আরও জানতে, ফ্রাঁসোয়া চোলেটের এই ব্লগ পোস্টটি পড়ার কথা বিবেচনা করুন। আরও বিশদ বিবরণের জন্য, ইয়ান গুডফেলো, ইয়োশুয়া বেঙ্গিও এবং অ্যারন কোরভিলের ডিপ লার্নিং থেকে অধ্যায় 14 দেখুন।