
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا البرنامج التعليمي كيفية بناء وتدريب شبكة خصومة توليدية شرطية (cGAN) تسمى pix2pix والتي تتعلم التعيين من الصور المدخلة إلى الصور المخرجة ، كما هو موضح في الترجمة من صورة إلى صورة مع شبكات الخصومة الشرطية بواسطة Isola et al. (2017). pix2pix ليس تطبيقًا محددًا - يمكن تطبيقه على مجموعة كبيرة من المهام ، بما في ذلك توليف الصور من خرائط الملصقات ، وإنشاء صور ملونة من الصور بالأبيض والأسود ، وتحويل صور خرائط Google إلى صور جوية ، وحتى تحويل الرسومات التخطيطية إلى صور.
في هذا المثال ، ستنشئ شبكتك صورًا لواجهات المباني باستخدام قاعدة بيانات واجهة CMP التي يوفرها مركز تصور الآلة في الجامعة التقنية التشيكية في براغ . لإبقائها قصيرة ، ستستخدم نسخة مُعالجة مسبقًا من مجموعة البيانات هذه التي أنشأها مؤلفو pix2pix.
في pix2pix cGAN ، تقوم بشرط إدخال الصور وإنشاء صور الإخراج المقابلة. تم اقتراح شبكات cGAN لأول مرة في شبكات الخصومة التوليدية الشرطية (Mirza and Osindero ، 2014)
ستحتوي بنية شبكتك على:
- مولد بهندسة معمارية تعتمد على U-Net .
- مُميِّز يتم تمثيله بواسطة مصنف PatchGAN تلافيفي (مقترح في ورقة pix2pix ).
لاحظ أن كل فترة يمكن أن تستغرق حوالي 15 ثانية على وحدة معالجة رسومات واحدة V100.
فيما يلي بعض الأمثلة على المخرجات التي تم إنشاؤها بواسطة pix2pix cGAN بعد التدريب لمدة 200 عصر على مجموعة بيانات الواجهات (80 كيلو خطوة).


استيراد TensorFlow ومكتبات أخرى
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
قم بتحميل مجموعة البيانات
قم بتنزيل بيانات CMP Facade Database (30 ميجابايت). تتوفر مجموعات بيانات إضافية بنفس التنسيق هنا . في Colab ، يمكنك تحديد مجموعات بيانات أخرى من القائمة المنسدلة. لاحظ أن بعض مجموعات البيانات الأخرى أكبر بكثير ( edges2handbags 8 جيجابايت).
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
كل صورة أصلية بحجم 256 x 512 تحتوي على صورتين 256 x 256 :
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
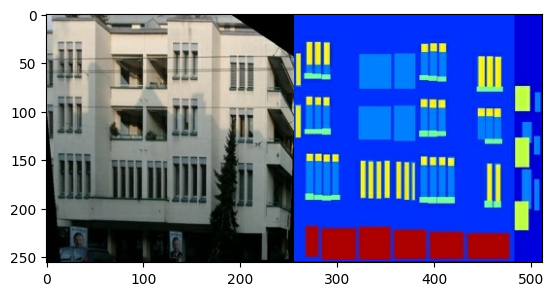
أنت بحاجة إلى فصل صور واجهة المبنى الحقيقية عن صور ملصقات العمارة - وكلها ستكون بحجم 256 x 256 .
حدد وظيفة تقوم بتحميل ملفات الصور وإخراج موترين للصور:
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
ارسم عينة من المدخلات (صورة ملصق العمارة) والحقيقية (صورة واجهة المبنى):
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
كما هو موضح في ورقة pix2pix ، فأنت بحاجة إلى تطبيق الارتعاش العشوائي والانعكاس للمعالجة المسبقة لمجموعة التدريب.
حدد العديد من الوظائف التي:
- قم بتغيير حجم كل صورة
256 x 256إلى ارتفاع وعرض أكبر -286 x 286. - قم بقصها بشكل عشوائي إلى
256 x 256. - اقلب الصورة بشكل أفقي ، أي من اليسار إلى اليمين (انعكاس عشوائي).
- تطبيع الصور إلى النطاق
[-1, 1].
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
يمكنك فحص بعض المخرجات المعالجة مسبقًا:
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
بعد التحقق من عمل التحميل والمعالجة المسبقة ، دعنا نحدد وظيفتين مساعدتين تقومان بتحميل مجموعات التدريب والاختبار ومعالجتها مسبقًا:
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
بناء خط أنابيب الإدخال مع tf.data
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
بناء المولد
منشئ pix2pix cGAN هو U-Net معدل. يتكون U-Net من جهاز تشفير (جهاز اختزال العينة) ومفكك تشفير (مكثف). (يمكنك معرفة المزيد عنها في البرنامج التعليمي لتجزئة الصور وعلى موقع مشروع U-Net .)
- كل كتلة في المشفر هي: Convolution -> Batch Naturalization -> Leaky ReLU
- كل كتلة في وحدة فك التشفير هي: تحويل التفافي -> تطبيع دفعة -> تسرب (مطبق على الكتل الثلاثة الأولى) -> ReLU
- توجد اتصالات تخطي بين وحدة التشفير ووحدة فك التشفير (كما في U-Net).
حدد الاختزال (المشفر):
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
تحديد مكثف (وحدة فك الترميز):
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
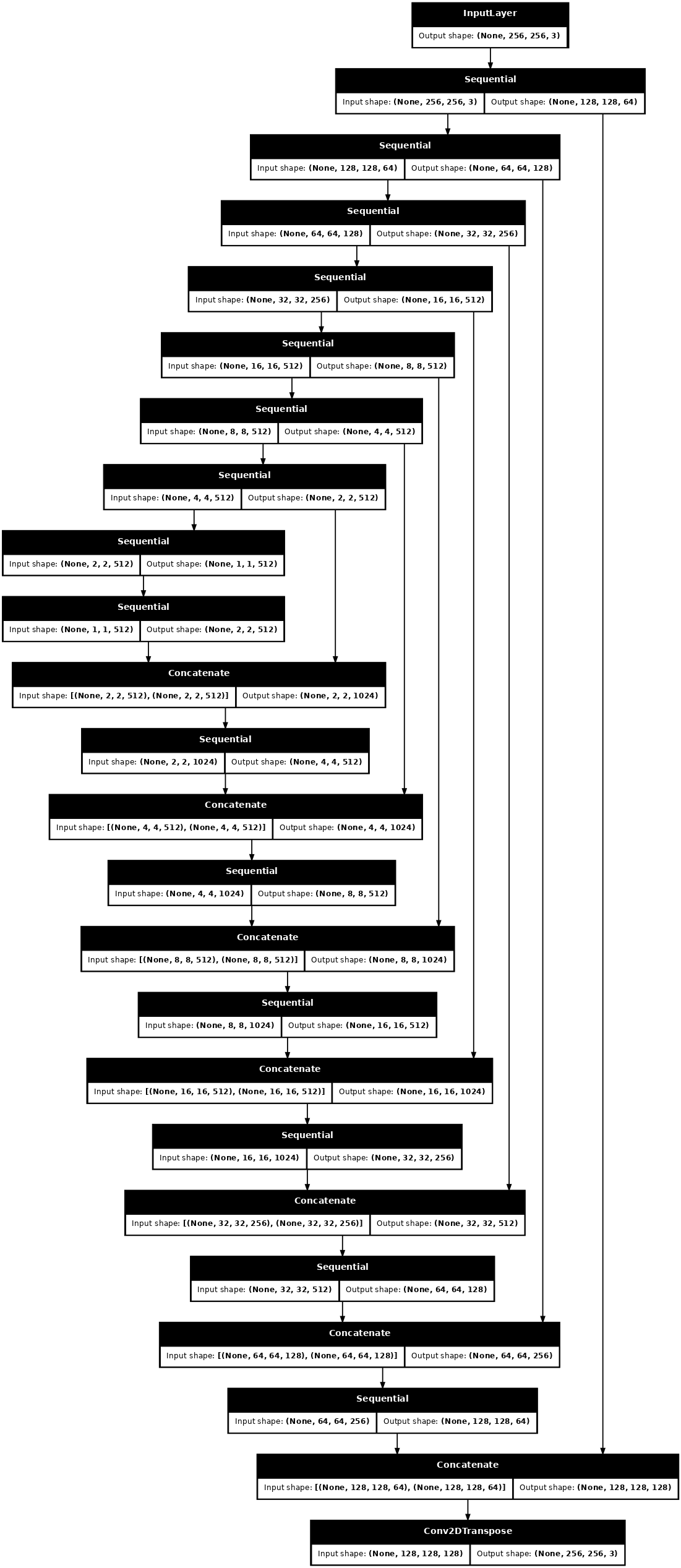
حدد المولد مع الاختزال والمضاعف:
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
تصور بنية نموذج المولد:
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
اختبر المولد:
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
حدد خسارة المولد
تتعلم GANs خسارة تتكيف مع البيانات ، بينما تتعلم cGANs خسارة منظمة تعاقب بنية محتملة تختلف عن إخراج الشبكة والصورة المستهدفة ، كما هو موضح في ورقة pix2pix .
- خسارة المولد عبارة عن فقدان إنتروبيا سيني للصور المولدة ومجموعة من الصور.
- تذكر ورقة pix2pix أيضًا خسارة L1 ، وهي MAE (يعني الخطأ المطلق) بين الصورة التي تم إنشاؤها والصورة الهدف.
- يتيح ذلك للصورة التي تم إنشاؤها أن تصبح مشابهة هيكليًا للصورة المستهدفة.
- صيغة حساب الخسارة الإجمالية للمولد هي
gan_loss + LAMBDA * l1_loss، حيثLAMBDA = 100. تم تحديد هذه القيمة من قبل مؤلفي الورقة.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
إجراءات التدريب للمولد هي كما يلي:

بناء المُميِّز
المُميِّز في pix2pix cGAN هو مُصنِّف تلافيفي PatchGAN - يحاول تصنيف ما إذا كانت كل صورة تصحيح حقيقية أم غير حقيقية ، كما هو موصوف في ورقة pix2pix .
- كل كتلة في أداة التمييز هي: التفاف -> تطبيع دفعة -> Leaky ReLU.
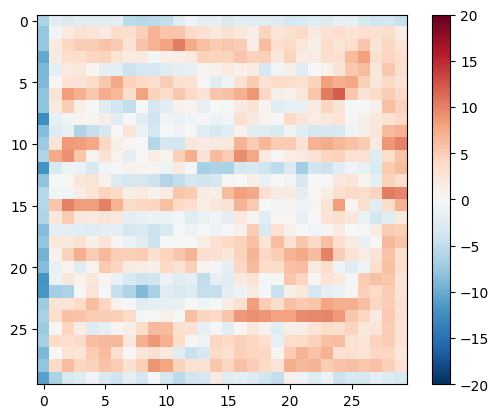
- شكل الناتج بعد الطبقة الأخيرة هو
(batch_size, 30, 30, 1). - كل تصحيح صورة
30 x 30من الناتج يصنف70 x 70جزء من صورة الإدخال. - يتلقى المُميِّز مُدخَلين:
- الصورة المدخلة والصورة المستهدفة والتي يجب تصنيفها على أنها حقيقية.
- الصورة المدخلة والصورة المولدة (خرج المولد) والتي يجب أن تصنف على أنها مزيفة.
- استخدم
tf.concat([inp, tar], axis=-1)معًا.
دعنا نحدد المميز:
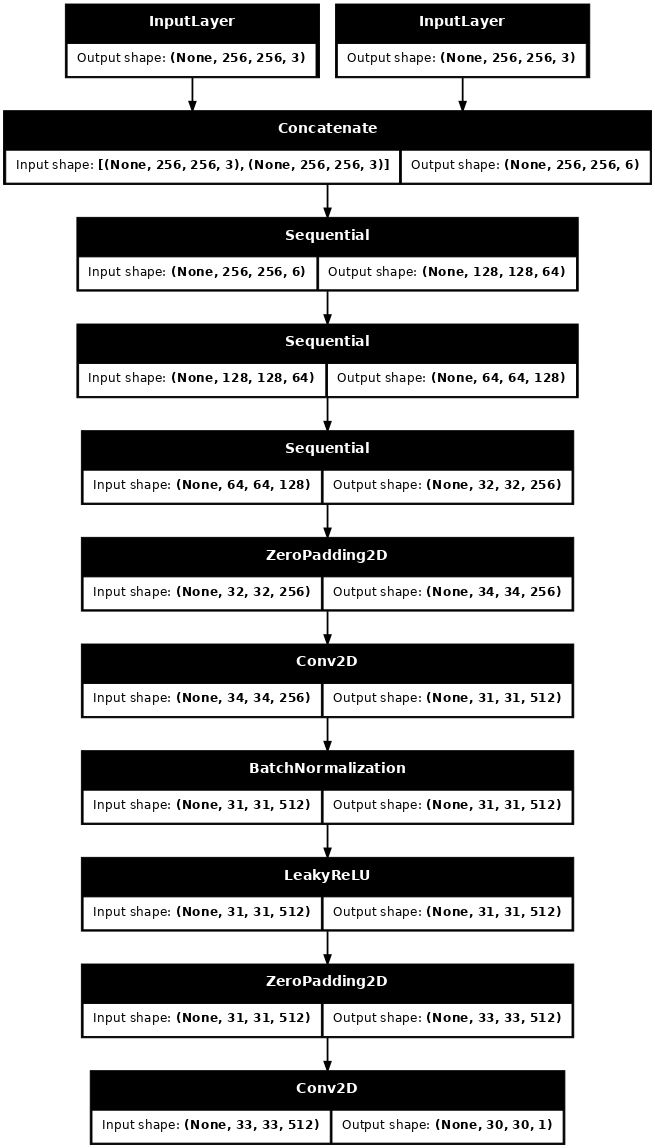
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
تصور بنية نموذج المميز:
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
اختبار أداة التمييز:
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>
تحديد خسارة أداة التمييز
- تأخذ وظيفة
discriminator_lossمدخلين: صور حقيقية وصور مُنشأة . -
real_lossهي خسارة عبر إنتروبيا سينية للصور الحقيقية ومجموعة من الصور (لأن هذه هي الصور الحقيقية) . - created_loss عبارة عن فقدان إنتروبيا سيني للصور التي تم إنشاؤها
generated_lossمن الأصفار (نظرًا لأن هذه هي الصور المزيفة) . -
total_lossهو مجموعreal_lossالتي تمgenerated_loss.
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
يتم عرض إجراءات التدريب للمميز أدناه.
لمعرفة المزيد حول الهندسة المعمارية والمعلمات التشعبية ، يمكنك الرجوع إلى ورقة pix2pix .

تحديد المحسّنين ونقاط التفتيش
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
توليد الصور
اكتب وظيفة لرسم بعض الصور أثناء التدريب.
- قم بتمرير الصور من مجموعة الاختبار إلى المولد.
- سيقوم المولد بعد ذلك بترجمة صورة الإدخال إلى الإخراج.
- الخطوة الأخيرة هي رسم التنبؤات وفويلا !
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
اختبر الوظيفة:
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

تمرين
- لكل مثال المدخلات يولد مخرجات.
- يستقبل
input_imageالمتولدة كإدخال أول. المدخل الثاني هوinput_imageوtarget_image. - بعد ذلك ، احسب المولد وخسارة المُميِّز.
- بعد ذلك ، احسب تدرجات الخسارة فيما يتعلق بكل من متغيرات المولد والمميز (المدخلات) وقم بتطبيقها على المحسن.
- أخيرًا ، سجل الخسائر في TensorBoard.
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
حلقة التدريب الفعلية. نظرًا لأن هذا البرنامج التعليمي يمكن تشغيله لأكثر من مجموعة بيانات واحدة ، وتختلف مجموعات البيانات اختلافًا كبيرًا في الحجم ، يتم إعداد حلقة التدريب للعمل في خطوات بدلاً من العصور.
- يتكرر على عدد الخطوات.
- كل 10 خطوات تطبع نقطة (
.). - كل 1 كيلو خطوة: امسح العرض وقم بتشغيل
generate_imagesلإظهار التقدم. - كل 5 كيلو خطوة: احفظ نقطة تفتيش.
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
تقوم حلقة التدريب هذه بحفظ السجلات التي يمكنك عرضها في TensorBoard لمراقبة تقدم التدريب.
إذا كنت تعمل على جهاز محلي ، فستبدأ عملية منفصلة لـ TensorBoard. عند العمل في جهاز كمبيوتر محمول ، قم بتشغيل العارض قبل بدء التدريب للمراقبة باستخدام TensorBoard.
لبدء تشغيل العارض ، الصق ما يلي في خلية التعليمات البرمجية:
%load_ext tensorboard
%tensorboard --logdir {log_dir}
أخيرًا ، قم بتشغيل حلقة التدريب:
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
إذا كنت ترغب في مشاركة نتائج TensorBoard بشكل عام ، فيمكنك تحميل السجلات إلى TensorBoard.dev عن طريق نسخ ما يلي في خلية تعليمات برمجية.
tensorboard dev upload --logdir {log_dir}
يمكنك عرض نتائج التشغيل السابق لدفتر الملاحظات هذا على TensorBboard.dev .
TensorBoard.dev هي تجربة مُدارة لاستضافة وتتبع ومشاركة تجارب ML مع الجميع.
يمكن أيضًا تضمينه بشكل مضمن باستخدام <iframe> :
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
يكون تفسير السجلات أكثر دقة عند تدريب GAN (أو cGAN مثل pix2pix) مقارنة بتصنيف بسيط أو نموذج انحدار. أشياء يجب البحث عنها:
- تحقق من عدم "فوز" المولد ولا نموذج التمييز. إذا كان إما
gen_gan_lossأوdisc_lossمنخفضًا جدًا ، فهذا مؤشر على أن هذا النموذج يسيطر على الآخر ، وأنك لا تدرب النموذج المدمج بنجاح. - تعد قيمة
log(2) = 0.69نقطة مرجعية جيدة لهذه الخسائر ، لأنها تشير إلى ارتباك قدره 2 - فالمميز ، في المتوسط ، غير مؤكد بنفس القدر بشأن الخيارين. - بالنسبة
disc_loss، تعني القيمة الأقل من0.69أن أداة التمييز تعمل بشكل أفضل من العشوائية في المجموعة المدمجة من الصور الحقيقية والمولدة. - بالنسبة إلى
gen_gan_loss، تعني القيمة الأقل من0.69أن المولد يعمل بشكل أفضل من العشوائي في خداع أداة التمييز. - مع تقدم التدريب ، يجب أن
gen_l1_loss.
قم باستعادة أحدث نقطة تفتيش واختبر الشبكة
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.index
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
قم بإنشاء بعض الصور باستخدام مجموعة الاختبار
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




