
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questo tutorial mostra l'addestramento di una semplice rete neurale convoluzionale (CNN) per classificare le immagini CIFAR . Poiché questo tutorial utilizza l' API Keras Sequential , la creazione e il training del modello richiederanno solo poche righe di codice.
Importa TensorFlow
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
Scarica e prepara il set di dati CIFAR10
Il set di dati CIFAR10 contiene 60.000 immagini a colori in 10 classi, con 6.000 immagini in ciascuna classe. Il set di dati è suddiviso in 50.000 immagini di addestramento e 10.000 immagini di test. Le classi si escludono a vicenda e non vi è alcuna sovrapposizione tra di loro.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
Verifica i dati
Per verificare che il set di dati sia corretto, tracciamo le prime 25 immagini del set di addestramento e visualizziamo il nome della classe sotto ogni immagine:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

Crea la base convoluzionale
Le 6 righe di codice seguenti definiscono la base convoluzionale utilizzando un modello comune: uno stack di livelli Conv2D e MaxPooling2D .
Come input, una CNN prende i tensori di forma (image_height, image_width, color_channels), ignorando la dimensione del batch. Se non conosci queste dimensioni, color_channels si riferisce a (R,G,B). In questo esempio, configurerai la tua CNN per elaborare input di forma (32, 32, 3), che è il formato delle immagini CIFAR. Puoi farlo passando l'argomento input_shape al tuo primo livello.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
Mostriamo l'architettura del tuo modello finora:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
Sopra, puoi vedere che l'output di ogni livello Conv2D e MaxPooling2D è un tensore di forma 3D (altezza, larghezza, canali). Le dimensioni di larghezza e altezza tendono a ridursi man mano che ci si addentra nella rete. Il numero di canali di output per ogni livello Conv2D è controllato dal primo argomento (ad esempio, 32 o 64). In genere, poiché la larghezza e l'altezza si riducono, puoi permetterti (dal punto di vista computazionale) di aggiungere più canali di output in ogni livello Conv2D.
Aggiungi strati densi in cima
Per completare il modello, alimenterai l'ultimo tensore di uscita dalla base convoluzionale (di forma (4, 4, 64)) in uno o più strati densi per eseguire la classificazione. I livelli densi prendono i vettori come input (che sono 1D), mentre l'output corrente è un tensore 3D. Innanzitutto, appiattirai (o srotolerai) l'output 3D in 1D, quindi aggiungerai uno o più livelli Dense in cima. CIFAR ha 10 classi di output, quindi usi un livello Dense finale con 10 output.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
Ecco l'architettura completa del tuo modello:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
Il riepilogo della rete mostra che (4, 4, 64) le uscite sono state appiattite in vettori di forma (1024) prima di passare attraverso due strati densi.
Compila e addestra il modello
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
Valuta il modello
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
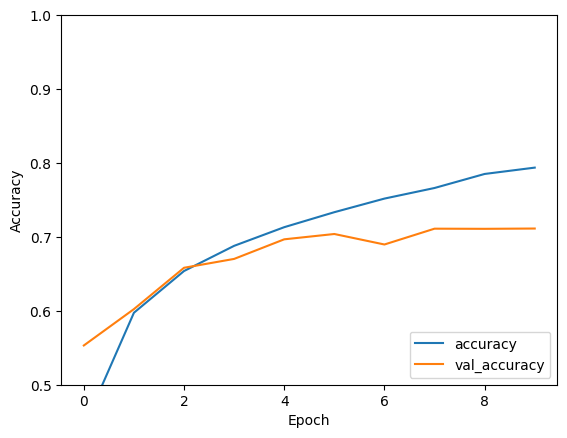
print(test_acc)
0.7192000150680542
La tua semplice CNN ha raggiunto un'accuratezza del test di oltre il 70%. Non male per poche righe di codice! Per un altro stile CNN, consulta l'esempio di avvio rapido di TensorFlow 2 per esperti che utilizza l'API di sottoclasse Keras e tf.GradientTape .