
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questo tutorial mostra la classificazione del testo a partire da file di testo normale archiviati su disco. Addestrerai un classificatore binario per eseguire l'analisi del sentiment su un set di dati IMDB. Alla fine del quaderno, c'è un esercizio da provare, in cui addestrerai un classificatore multiclasse per prevedere il tag per una domanda di programmazione su Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
Analisi del sentimento
Questo taccuino addestra un modello di analisi del sentimento per classificare le recensioni di film come positive o negative , in base al testo della recensione. Questo è un esempio di classificazione binaria o a due classi, un tipo di problema di apprendimento automatico importante e ampiamente applicabile.
Utilizzerai il set di dati di recensioni di film di grandi dimensioni che contiene il testo di 50.000 recensioni di film da Internet Movie Database . Questi sono suddivisi in 25.000 revisioni per la formazione e 25.000 revisioni per i test. I set di formazione e test sono bilanciati , il che significa che contengono un numero uguale di recensioni positive e negative.
Scarica ed esplora il set di dati IMDB
Scarichiamo ed estraiamo il set di dati, quindi esploriamo la struttura delle directory.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
Le aclImdb/train/pos e aclImdb/train/neg contengono molti file di testo, ognuno dei quali è una singola recensione di un film. Diamo un'occhiata a uno di loro.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
Carica il set di dati
Successivamente, caricherai i dati dal disco e li preparerai in un formato adatto per l'allenamento. Per fare ciò, utilizzerai l'utile utility text_dataset_from_directory , che prevede una struttura di directory come segue.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
Per preparare un set di dati per la classificazione binaria, avrai bisogno di due cartelle su disco, corrispondenti a class_a e class_b . Queste saranno le recensioni positive e negative dei film, che possono essere trovate in aclImdb/train/pos e aclImdb/train/neg . Poiché il set di dati IMDB contiene cartelle aggiuntive, le rimuoverai prima di utilizzare questa utilità.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Successivamente, utilizzerai l'utilità text_dataset_from_directory per creare un tf.data.Dataset etichettato. tf.data è una potente raccolta di strumenti per lavorare con i dati.
Quando si esegue un esperimento di machine learning, è consigliabile dividere il set di dati in tre suddivisioni: train , validation e test .
Il set di dati IMDB è già stato suddiviso in treno e test, ma manca di un set di convalida. Creiamo un set di convalida utilizzando una divisione 80:20 dei dati di addestramento utilizzando l'argomento validation_split di seguito.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
Come puoi vedere sopra, ci sono 25.000 esempi nella cartella di formazione, di cui utilizzerai l'80% (o 20.000) per la formazione. Come vedrai tra poco, puoi addestrare un modello passando un set di dati direttamente a model.fit . Se non tf.data , puoi anche scorrere il set di dati e stampare alcuni esempi come segue.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
Nota che le recensioni contengono testo grezzo (con punteggiatura e tag HTML occasionali come <br/> ). Mostrerai come gestirli nella sezione seguente.
Le etichette sono 0 o 1. Per vedere quale di queste corrisponde a recensioni di film positive e negative, puoi controllare la proprietà class_names sul set di dati.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
Successivamente, creerai un set di dati di convalida e test. Utilizzerai le restanti 5.000 revisioni del set di formazione per la convalida.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
Preparare il set di dati per l'addestramento
Successivamente, standardizzerai, tokenizzerai e vettorizzerai i dati utilizzando l'utile livello tf.keras.layers.TextVectorization .
La standardizzazione si riferisce alla preelaborazione del testo, in genere per rimuovere la punteggiatura o elementi HTML per semplificare il set di dati. La tokenizzazione si riferisce alla divisione di stringhe in token (ad esempio, suddividendo una frase in singole parole, suddividendo su uno spazio bianco). La vettorizzazione si riferisce alla conversione di token in numeri in modo che possano essere inseriti in una rete neurale. Tutte queste attività possono essere eseguite con questo livello.
Come hai visto sopra, le recensioni contengono vari tag HTML come <br /> . Questi tag non verranno rimossi dallo standardizzatore predefinito nel livello TextVectorization (che converte il testo in minuscolo ed elimina la punteggiatura per impostazione predefinita, ma non elimina l'HTML). Scriverai una funzione di standardizzazione personalizzata per rimuovere l'HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
Successivamente, creerai un livello TextVectorization . Utilizzerai questo livello per standardizzare, tokenizzare e vettorizzare i nostri dati. Imposta output_mode su int per creare indici interi univoci per ogni token.
Tieni presente che stai utilizzando la funzione di divisione predefinita e la funzione di standardizzazione personalizzata che hai definito sopra. Definirai anche alcune costanti per il modello, come un esplicito sequence_length massimo , che farà sì che il livello riempia o tronchi le sequenze esattamente ai valori di sequence_length .
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
Successivamente, chiamerai adapt per adattare lo stato del livello di preelaborazione al set di dati. Ciò farà sì che il modello crei un indice di stringhe in numeri interi.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
Creiamo una funzione per vedere il risultato dell'utilizzo di questo livello per preelaborare alcuni dati.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
Come puoi vedere sopra, ogni token è stato sostituito da un numero intero. Puoi cercare il token (stringa) a cui corrisponde ogni intero chiamando .get_vocabulary() sul livello.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
Sei quasi pronto per addestrare il tuo modello. Come passaggio finale di preelaborazione, applicherai il livello TextVectorization creato in precedenza al set di dati di training, validazione e test.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
Configura il set di dati per le prestazioni
Questi sono due metodi importanti che dovresti usare durante il caricamento dei dati per assicurarti che l'I/O non si blocchi.
.cache() mantiene i dati in memoria dopo che sono stati caricati dal disco. Ciò garantirà che il set di dati non diventi un collo di bottiglia durante l'addestramento del modello. Se il tuo set di dati è troppo grande per essere contenuto nella memoria, puoi anche utilizzare questo metodo per creare una cache su disco performante, che è più efficiente da leggere rispetto a molti file di piccole dimensioni.
.prefetch() si sovrappone alla preelaborazione dei dati e all'esecuzione del modello durante l'addestramento.
Puoi saperne di più su entrambi i metodi e su come memorizzare nella cache i dati su disco nella guida alle prestazioni dei dati .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Crea il modello
È ora di creare la tua rete neurale:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
I livelli sono impilati in sequenza per costruire il classificatore:
- Il primo livello è un livello di
Embedding. Questo livello prende le recensioni con codifica intera e cerca un vettore di incorporamento per ogni indice di parola. Questi vettori vengono appresi come treni modello. I vettori aggiungono una dimensione all'array di output. Le dimensioni risultanti sono:(batch, sequence, embedding). Per ulteriori informazioni sugli incorporamenti, vedere l' esercitazione sull'incorporamento di parole . - Successivamente, un livello
GlobalAveragePooling1Drestituisce un vettore di output a lunghezza fissa per ogni esempio calcolando la media sulla dimensione della sequenza. Ciò consente al modello di gestire input di lunghezza variabile, nel modo più semplice possibile. - Questo vettore di output a lunghezza fissa viene convogliato attraverso uno strato completamente connesso (
Dense) con 16 unità nascoste. - L'ultimo strato è densamente connesso con un singolo nodo di output.
Funzione di perdita e ottimizzatore
Un modello ha bisogno di una funzione di perdita e di un ottimizzatore per l'allenamento. Poiché si tratta di un problema di classificazione binaria e il modello emette una probabilità (uno strato di unità singola con un'attivazione sigmoidea), utilizzerai la funzione di perdita di losses.BinaryCrossentropy .
Ora, configura il modello per utilizzare un ottimizzatore e una funzione di perdita:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
Allena il modello
Addestrerai il modello passando l'oggetto del dataset di dati al metodo fit.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
Valuta il modello
Vediamo come si comporta il modello. Verranno restituiti due valori. Perdita (un numero che rappresenta il nostro errore, valori più bassi sono migliori) e precisione.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
Questo approccio abbastanza ingenuo raggiunge una precisione di circa l'86%.
Crea una trama di precisione e perdita nel tempo
model.fit() restituisce un oggetto History che contiene un dizionario con tutto ciò che è accaduto durante l'allenamento:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
Sono disponibili quattro voci: una per ogni metrica monitorata durante l'addestramento e la convalida. Puoi usarli per tracciare la perdita di formazione e convalida per il confronto, nonché l'accuratezza di formazione e convalida:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
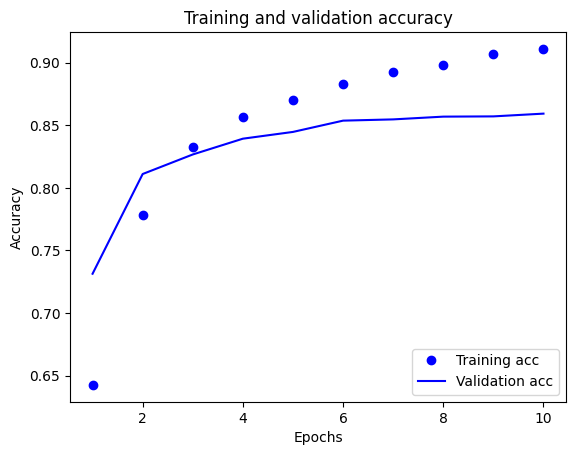
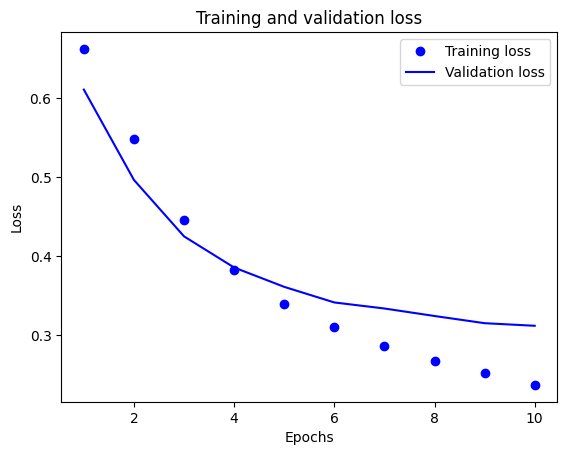
In questo grafico, i punti rappresentano la perdita e l'accuratezza dell'allenamento e le linee continue rappresentano la perdita e l'accuratezza della convalida.
Si noti che la perdita di allenamento diminuisce ad ogni epoca e l'accuratezza dell'allenamento aumenta ad ogni epoca. Ciò è previsto quando si utilizza un'ottimizzazione della discesa del gradiente: dovrebbe ridurre al minimo la quantità desiderata ad ogni iterazione.
Questo non è il caso della perdita e dell'accuratezza della convalida: sembrano raggiungere il picco prima dell'accuratezza dell'allenamento. Questo è un esempio di overfitting: il modello ha prestazioni migliori sui dati di addestramento rispetto a dati che non ha mai visto prima. Dopo questo punto, il modello ottimizza eccessivamente e apprende le rappresentazioni specifiche dei dati di addestramento che non si generalizzano ai dati di test.
Per questo caso particolare, è possibile prevenire l'overfitting semplicemente interrompendo l'addestramento quando l'accuratezza della convalida non aumenta più. Un modo per farlo è utilizzare il callback tf.keras.callbacks.EarlyStopping .
Esporta il modello
Nel codice precedente, hai applicato il livello TextVectorization al set di dati prima di inserire il testo nel modello. Se vuoi rendere il tuo modello in grado di elaborare stringhe grezze (ad esempio, per semplificarne la distribuzione), puoi includere il livello TextVectorization all'interno del tuo modello. Per farlo, puoi creare un nuovo modello usando i pesi che hai appena allenato.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
Inferenza su nuovi dati
Per ottenere previsioni per nuovi esempi, puoi semplicemente chiamare model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
L'inclusione della logica di preelaborazione del testo all'interno del modello consente di esportare un modello per la produzione che semplifica la distribuzione e riduce il potenziale di distorsione del treno/test .
C'è una differenza di prestazioni da tenere a mente quando si sceglie dove applicare il livello di TextVectorization. L'utilizzo al di fuori del modello consente di eseguire l'elaborazione asincrona della CPU e il buffering dei dati durante l'allenamento su GPU. Quindi, se stai addestrando il tuo modello sulla GPU, probabilmente vorrai utilizzare questa opzione per ottenere le migliori prestazioni durante lo sviluppo del tuo modello, quindi passare all'inclusione del livello TextVectorization all'interno del tuo modello quando sei pronto per prepararti per la distribuzione .
Visita questo tutorial per saperne di più sul salvataggio dei modelli.
Esercizio: classificazione multiclasse su domande Stack Overflow
Questo tutorial ha mostrato come addestrare un classificatore binario da zero sul set di dati IMDB. Come esercizio, puoi modificare questo blocco appunti per addestrare un classificatore multiclasse a prevedere il tag di una domanda di programmazione in Stack Overflow .
È stato preparato un set di dati da utilizzare contenente il corpo di diverse migliaia di domande di programmazione (ad esempio, "Come posso ordinare un dizionario per valore in Python?") pubblicate in Stack Overflow. Ognuno di questi è etichettato esattamente con un tag (o Python, CSharp, JavaScript o Java). Il tuo compito è prendere una domanda come input e prevedere il tag appropriato, in questo caso Python.
Il set di dati con cui lavorerai contiene diverse migliaia di domande estratte dal set di dati Stack Overflow pubblico molto più ampio su BigQuery , che contiene oltre 17 milioni di post.
Dopo aver scaricato il set di dati, scoprirai che ha una struttura di directory simile al set di dati IMDB con cui hai lavorato in precedenza:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
Per completare questo esercizio, è necessario modificare questo blocco appunti in modo che funzioni con il set di dati Stack Overflow apportando le seguenti modifiche:
Nella parte superiore del blocco appunti, aggiorna il codice che scarica il set di dati IMDB con il codice per scaricare il set di dati Stack Overflow che è già stato preparato. Poiché il set di dati Stack Overflow ha una struttura di directory simile, non sarà necessario apportare molte modifiche.
Modifica l'ultimo livello del tuo modello su
Dense(4), poiché ora ci sono quattro classi di output.Durante la compilazione del modello, modificare la perdita in
tf.keras.losses.SparseCategoricalCrossentropy. Questa è la funzione di perdita corretta da utilizzare per un problema di classificazione multiclasse, quando le etichette per ciascuna classe sono interi (in questo caso, possono essere 0, 1 , 2 o 3 ). Inoltre, modifica le metriche inmetrics=['accuracy'], poiché si tratta di un problema di classificazione multiclasse (tf.metrics.BinaryAccuracyviene utilizzato solo per classificatori binari).Quando si traccia l'accuratezza nel tempo, modificare
binary_accuracyeval_binary_accuracyinaccuracyeval_accuracy.Una volta completate queste modifiche, sarai in grado di addestrare un classificatore multiclasse.
Imparare di più
Questo tutorial ha introdotto la classificazione del testo da zero. Per ulteriori informazioni sul flusso di lavoro di classificazione del testo in generale, consulta la Guida alla classificazione del testo di Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.