
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub |
Ten samouczek zawiera przykłady wykorzystania danych CSV z TensorFlow.
Są na to dwie główne części:
- Ładowanie danych z dysku
- Wstępne przetworzenie go do postaci odpowiedniej do treningu.
Ten samouczek koncentruje się na ładowaniu i podaje kilka szybkich przykładów przetwarzania wstępnego. Samouczek, który koncentruje się na aspekcie wstępnego przetwarzania, można znaleźć w przewodniku po warstwach wstępnego przetwarzania i samouczku .
Ustawiać
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
W danych pamięci
W przypadku każdego małego zestawu danych CSV najprostszym sposobem wytrenowania na nim modelu TensorFlow jest załadowanie go do pamięci jako pandas Dataframe lub tablicy NumPy.
Stosunkowo prostym przykładem jest zbiór danych abalone .
- Zbiór danych jest mały.
- Wszystkie funkcje wejściowe są wartościami zmiennoprzecinkowymi o ograniczonym zakresie.
Oto jak pobrać dane do Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
Zbiór danych zawiera zestaw pomiarów słuchotek , rodzaju ślimaka morskiego.

„Muszla Abalone” (autor Nicki Dugan Pogue , CC BY-SA 2.0)
Zadaniem nominalnym dla tego zbioru danych jest przewidzenie wieku na podstawie innych pomiarów, więc oddziel cechy i etykiety dla treningu:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
W przypadku tego zbioru danych wszystkie funkcje będą traktowane identycznie. Spakuj funkcje w jedną tablicę NumPy.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
Następnie wykonaj model regresji przewidujący wiek. Ponieważ istnieje tylko jeden tensor wejściowy, model keras.Sequential jest tutaj wystarczający.
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
Aby wytrenować ten model, przekaż funkcje i etykiety do Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
Właśnie poznałeś najbardziej podstawowy sposób trenowania modelu przy użyciu danych CSV. Następnie dowiesz się, jak zastosować przetwarzanie wstępne do normalizacji kolumn liczbowych.
Podstawowe przetwarzanie wstępne
Dobrą praktyką jest normalizacja danych wejściowych do modelu. Warstwy przetwarzania wstępnego Keras zapewniają wygodny sposób wbudowania tej normalizacji w model.
Warstwa wstępnie obliczy średnią i wariancję każdej kolumny i użyje ich do normalizacji danych.
Najpierw tworzysz warstwę:
normalize = layers.Normalization()
Następnie używasz metody Normalization.adapt() , aby dostosować warstwę normalizacji do swoich danych.
normalize.adapt(abalone_features)
Następnie użyj warstwy normalizacyjnej w swoim modelu:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
Mieszane typy danych
Zbiór danych „Titanic” zawiera informacje o pasażerach Titanica. Nominalnym zadaniem tego zbioru danych jest przewidzenie, kto przeżył.

Obraz z Wikimedia
{kind=link}
Surowe dane można łatwo załadować jako Pandas DataFrame , ale nie można ich od razu użyć jako danych wejściowych do modelu TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
Ze względu na różne typy i zakresy danych nie można po prostu ułożyć funkcji w tablicy NumPy i przekazać jej do modelu keras.Sequential . Każda kolumna musi być traktowana indywidualnie.
Jedną z opcji jest wstępne przetworzenie danych w trybie offline (za pomocą dowolnego narzędzia), aby przekonwertować kolumny kategorii na kolumny liczbowe, a następnie przekazać przetworzone dane wyjściowe do modelu TensorFlow. Wadą tego podejścia jest to, że jeśli zapiszesz i wyeksportujesz model, przetwarzanie wstępne nie zostanie z nim zapisane. Warstwy przetwarzania wstępnego Keras unikają tego problemu, ponieważ są częścią modelu.
W tym przykładzie zbudujesz model, który implementuje logikę przetwarzania wstępnego za pomocą funkcjonalnego API Keras . Możesz to również zrobić przez tworzenie podklas .
Funkcjonalne API działa na "symbolicznych" tensorach. Normalne „chętne” tensory mają wartość. W przeciwieństwie do tych "symbolicznych" tensorów nie. Zamiast tego śledzą, które operacje są na nich wykonywane, i budują reprezentację obliczeń, którą można uruchomić później. Oto krótki przykład:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
Aby zbudować model przetwarzania wstępnego, zacznij od zbudowania zestawu symbolicznych obiektów keras.Input , pasujących do nazw i typów danych kolumn CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
Pierwszym krokiem w logice przetwarzania wstępnego jest połączenie ze sobą danych liczbowych i przeprowadzenie ich przez warstwę normalizacji:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
Zbierz wszystkie symboliczne wyniki przetwarzania wstępnego, aby później je połączyć.
preprocessed_inputs = [all_numeric_inputs]
W przypadku ciągów wejściowych użyj funkcji tf.keras.layers.StringLookup , aby odwzorować ciągi na indeksy liczb całkowitych w słowniku. Następnie użyj tf.keras.layers.CategoryEncoding , aby przekonwertować indeksy na dane float32 odpowiednie dla modelu.
Domyślne ustawienia warstwy tf.keras.layers.CategoryEncoding tworzą jeden gorący wektor dla każdego wejścia. A layers.Embedding również zadziała. Więcej informacji na ten temat można znaleźć w przewodniku i samouczku dotyczącym wstępnego przetwarzania warstw .
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
Dzięki kolekcji danych inputs i processed_inputs można połączyć wszystkie wstępnie przetworzone dane wejściowe i zbudować model obsługujący przetwarzanie wstępne:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
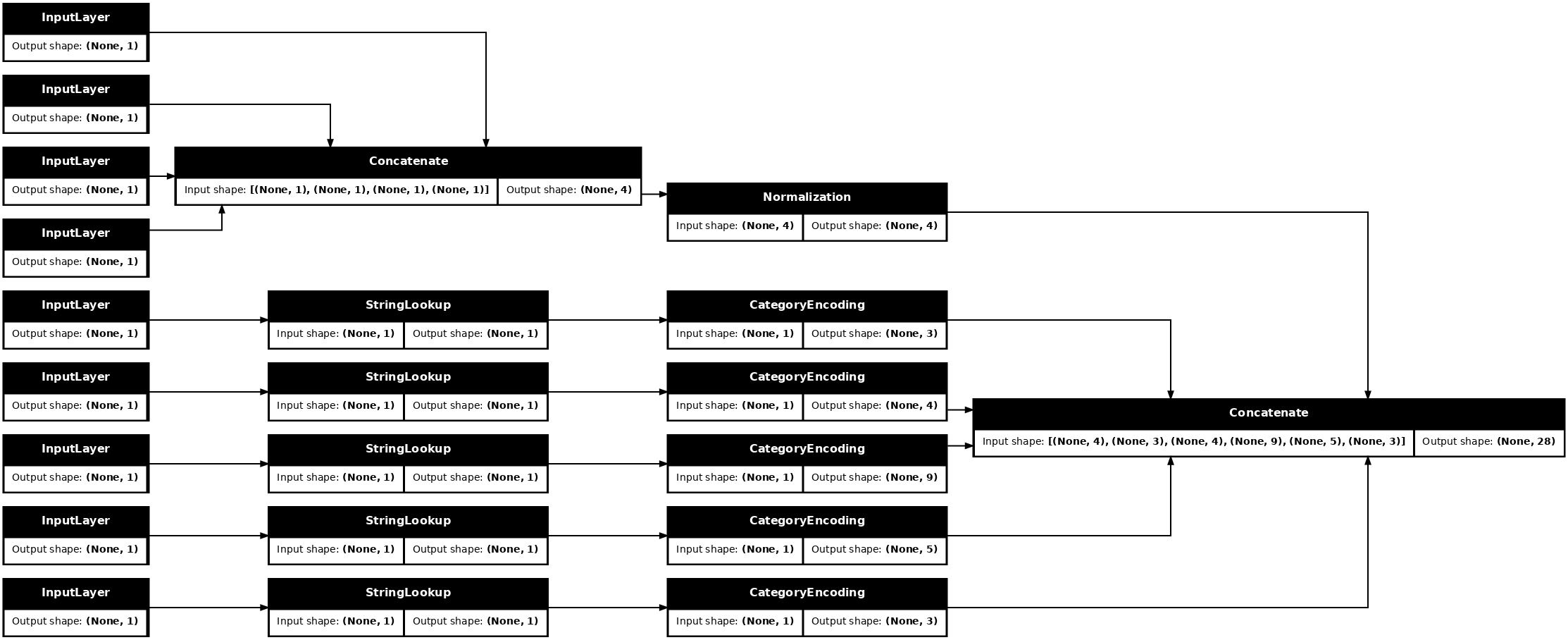
Ten model zawiera tylko wstępne przetwarzanie danych wejściowych. Możesz go uruchomić, aby zobaczyć, co robi z Twoimi danymi. Modele Keras nie konwertują automatycznie Pandas DataFrames , ponieważ nie jest jasne, czy powinny one zostać przekonwertowane na jeden tensor, czy na słownik tensorów. Więc przekształć to w słownik tensorów:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
Wytnij pierwszy przykład szkoleniowy i przekaż go do tego modelu przetwarzania wstępnego, zobaczysz połączone ze sobą funkcje liczbowe i ciąg jeden-gorący:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Teraz zbuduj model na tym:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
Kiedy trenujesz model, przekaż słownik funkcji jako x , a etykietę jako y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
Ponieważ przetwarzanie wstępne jest częścią modelu, możesz zapisać model i załadować go w innym miejscu, aby uzyskać identyczne wyniki:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
Korzystanie z tf.data
W poprzedniej sekcji polegałeś na wbudowanym tasowaniu danych i grupowaniu danych podczas uczenia modelu.
Jeśli potrzebujesz większej kontroli nad wejściowym potokiem danych lub potrzebujesz danych, które nie mieszczą się łatwo w pamięci: użyj tf.data .
Więcej przykładów można znaleźć w przewodniku tf.data .
Wł. dane w pamięci
Jako pierwszy przykład zastosowania tf.data do danych CSV rozważ poniższy kod, aby ręcznie podzielić słownik funkcji z poprzedniej sekcji. Dla każdego indeksu przyjmuje ten indeks dla każdej funkcji:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Uruchom to i wydrukuj pierwszy przykład:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
Najbardziej podstawowym tf.data.Dataset w programie ładującym dane pamięci jest konstruktor Dataset.from_tensor_slices . Zwraca to tf.data.Dataset , który implementuje uogólnioną wersję powyższej funkcji slices w TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
Możesz iterować po tf.data.Dataset jak każdy inny iterowalny python:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
Funkcja from_tensor_slices może obsługiwać dowolną strukturę zagnieżdżonych słowników lub krotek. Poniższy kod tworzy zestaw danych z par (features_dict, labels) :
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
Aby wytrenować model przy użyciu tego Dataset , musisz przynajmniej shuffle i batch dane.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
Zamiast przekazywać features i labels do Model.fit , przekazujesz zestaw danych:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
Z jednego pliku
Jak dotąd ten samouczek działał z danymi w pamięci. tf.data to wysoce skalowalny zestaw narzędzi do budowania potoków danych i zapewnia kilka funkcji do obsługi ładowania plików CSV.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
Teraz odczytaj dane CSV z pliku i utwórz tf.data.Dataset .
(Aby uzyskać pełną dokumentację, zobacz tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
Ta funkcja zawiera wiele wygodnych funkcji, dzięki czemu praca z danymi jest łatwa. To zawiera:
- Używanie nagłówków kolumn jako kluczy słownikowych.
- Automatyczne określanie typu każdej kolumny.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
Może również dekompresować dane w locie. Oto spakowany gzipem plik CSV zawierający zbiór danych o ruchu międzystanowym w metro

Obraz z Wikimedia
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
Ustaw argument compression_type na odczyt bezpośrednio ze skompresowanego pliku:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
Buforowanie
Przetwarzanie danych csv wiąże się z pewnym obciążeniem. W przypadku małych modeli może to być wąskie gardło w treningu.
W zależności od przypadku użycia dobrym pomysłem może być użycie Dataset.cache lub data.experimental.snapshot , aby dane csv były analizowane tylko w pierwszej epoce.
Główna różnica między metodami cache i snapshot polega na tym, że pliki cache mogą być używane tylko przez proces TensorFlow, który je utworzył, ale pliki snapshot mogą być odczytywane przez inne procesy.
Na przykład 20-krotne wykonanie iteracji przez traffic_volume_csv_gz_ds zajmuje ~15 sekund bez buforowania lub ~2s z buforowaniem.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
Jeśli ładowanie danych jest spowolnione przez wczytywanie plików CSV, a cache i snapshot są niewystarczające dla danego przypadku użycia, rozważ ponowne zakodowanie danych w bardziej uproszczonym formacie.
Wiele plików
Wszystkie dotychczasowe przykłady w tej sekcji można było łatwo wykonać bez tf.data . Jednym z miejsc, w którym tf.data może naprawdę uprościć rzeczy, jest zajmowanie się kolekcjami plików.
Na przykład zestaw danych obrazów czcionek znaków jest dystrybuowany jako kolekcja plików csv, po jednym na czcionkę.

Obraz David Mark z Pixabay
Pobierz zbiór danych i spójrz na znajdujące się w nim pliki:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
Kiedy masz do czynienia z wieloma plikami, możesz przekazać wzorzec pliku w stylu file_pattern do funkcji experimental.make_csv_dataset . Kolejność plików jest tasowana w każdej iteracji.
Użyj argumentu num_parallel_reads , aby ustawić liczbę plików odczytywanych równolegle i przeplatanych razem.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
Te pliki csv mają obrazy spłaszczone w jednym wierszu. Nazwy kolumn są sformatowane r{row}c{column} . Oto pierwsza partia:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
Opcjonalnie: pola do pakowania
Prawdopodobnie nie chcesz pracować z każdym pikselem w osobnych kolumnach, takich jak ta. Zanim spróbujesz użyć tego zbioru danych, upewnij się, że spakujesz piksele w tensorze obrazu.
Oto kod, który analizuje nazwy kolumn, aby zbudować obrazy dla każdego przykładu:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Zastosuj tę funkcję do każdej partii w zbiorze danych:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Narysuj powstałe obrazy:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

Funkcje niższego poziomu
Jak dotąd ten samouczek koncentrował się na narzędziach najwyższego poziomu do odczytu danych csv. Istnieją inne dwa interfejsy API, które mogą być przydatne dla zaawansowanych użytkowników, jeśli przypadek użycia nie pasuje do podstawowych wzorców.
-
tf.io.decode_csv- funkcja do parsowania wierszy tekstu na listę tensorów kolumn CSV. -
tf.data.experimental.CsvDataset— konstruktor zestawu danych csv niższego poziomu.
Ta sekcja odtwarza funkcjonalność dostarczoną przez make_csv_dataset , aby zademonstrować, jak można użyć tej funkcjonalności niższego poziomu.
tf.io.decode_csv
Ta funkcja dekoduje ciąg lub listę ciągów na listę kolumn.
W przeciwieństwie do make_csv_dataset ta funkcja nie próbuje odgadnąć typów danych kolumn. Typy kolumn określa się, dostarczając listę record_defaults zawierającą wartość prawidłowego typu dla każdej kolumny.
Aby odczytać dane Titanica jako ciągi za pomocą decode_csv , powiedziałbyś:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
Aby przeanalizować je z ich rzeczywistymi typami, utwórz listę record_defaults odpowiednich typów:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
Klasa tf.data.experimental.CsvDataset zapewnia minimalny interfejs Dataset CSV bez wygodnych funkcji funkcji make_csv_dataset : parsowanie nagłówków kolumn, wnioskowanie o typie kolumn, automatyczne tasowanie, przeplatanie plików.
Ten konstruktor wykorzystuje record_defaults w taki sam sposób jak io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Powyższy kod jest w zasadzie odpowiednikiem:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Wiele plików
Aby przeanalizować zestaw danych czcionek przy użyciu experimental.CsvDataset , musisz najpierw określić typy kolumn dla parametru record_defaults . Zacznij od sprawdzenia pierwszego wiersza jednego pliku:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Tylko pierwsze dwa pola to ciągi, pozostałe to liczby typu int lub float, a łączną liczbę cech można uzyskać, licząc przecinki:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
Konstruktor CsvDatasaet może pobierać listę plików wejściowych, ale odczytuje je sekwencyjnie. Pierwszym plikiem na liście plików CSV jest AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
Więc kiedy przekazujesz listę plików do CsvDataaset , najpierw odczytywane są rekordy z AGENCY.csv :
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
Aby przeplatać wiele plików, użyj Dataset.interleave .
Oto początkowy zbiór danych, który zawiera nazwy plików csv:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
Tasuje nazwy plików w każdej epoce:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
Metoda interleave przyjmuje funkcję map_func , która tworzy element podrzędny Dataset dla każdego elementu elementu nadrzędnego Dataset .
Tutaj chcesz utworzyć CsvDataset z każdego elementu zestawu danych plików:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Zestaw Dataset zwrócony przez przeplatanie zwraca elementy przez cykliczne przechodzenie przez szereg podrzędnych Dataset . Zwróć uwagę poniżej, jak zbiór danych cyklicznie przekracza cycle_length=3 trzy pliki czcionek:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
Wydajność
Wcześniej zauważono, że io.decode_csv jest bardziej wydajny, gdy jest uruchamiany na partii ciągów.
Można wykorzystać ten fakt, używając dużych rozmiarów partii, aby poprawić wydajność ładowania CSV (ale najpierw spróbuj buforowania ).
Dzięki wbudowanej ładowarce 20, 2048-przykładowych partii zajmuje około 17s.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
Przekazywanie partii wierszy tekstu do decode_csv przebiega szybciej, w około 5 sekund:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
Aby zapoznać się z innym przykładem zwiększenia wydajności csv przy użyciu dużych partii, zobacz samouczek dotyczący przesunięć i niedopasowań .
Takie podejście może działać, ale rozważ inne opcje, takie jak cache i snapshot lub ponowne kodowanie danych w bardziej uproszczonym formacie.