
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questo tutorial mostra come implementare il metodo Actor-Critic usando TensorFlow per addestrare un agente nell'ambiente Open AI Gym CartPole-V0. Si presume che il lettore abbia una certa familiarità con i metodi del gradiente di policy di apprendimento per rinforzo.
Metodi attore-critico
I metodi attore-critico sono metodi di apprendimento delle differenze temporali (TD) che rappresentano la funzione politica indipendente dalla funzione valore.
Una funzione politica (o politica) restituisce una distribuzione di probabilità sulle azioni che l'agente può intraprendere in base allo stato specificato. Una funzione di valore determina il rendimento atteso per un agente che inizia in un determinato stato e agisce in base a una particolare politica per sempre.
Nel metodo attore-critico, la politica è indicata come l' attore che propone un insieme di azioni possibili dato uno stato e la funzione del valore stimato è indicata come critico , che valuta le azioni intraprese dall'attore in base alla politica data .
In questo tutorial, sia l' attore che il critico verranno rappresentati utilizzando una rete neurale con due output.
CartPole-v0
Nell'ambiente CartPole-v0 , un palo è attaccato a un carrello che si muove lungo un binario senza attrito. Il palo parte in posizione verticale e l'obiettivo dell'agente è impedirne la caduta applicando una forza di -1 o +1 al carrello. Viene data una ricompensa di +1 per ogni passo che il palo rimane in piedi. Un episodio termina quando (1) il palo si trova a più di 15 gradi dalla verticale o (2) il carrello si sposta a più di 2,4 unità dal centro.
Il problema è considerato "risolto" quando la ricompensa totale media per l'episodio raggiunge 195 su 100 prove consecutive.
Impostare
Importa i pacchetti necessari e configura le impostazioni globali.
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
Modello
L' attore e il critico verranno modellati utilizzando una rete neurale che genera rispettivamente le probabilità di azione e il valore critico. Questo tutorial usa la sottoclasse del modello per definire il modello.
Durante il passaggio in avanti, il modello prenderà lo stato come input e produrrà sia le probabilità di azione che il valore critico \(V\), che modella la funzione del valore dipendente dallo stato. L'obiettivo è formare un modello che scelga le azioni in base a una policy \(\pi\) che massimizzi il rendimento atteso.
Per Cartpole-v0, ci sono quattro valori che rappresentano lo stato: posizione del carrello, velocità del carrello, angolo del polo e velocità del polo rispettivamente. L'agente può eseguire due azioni per spingere il carrello rispettivamente a sinistra (0) ea destra (1).
Fare riferimento alla pagina wiki CartPole-v0 di OpenAI Gym per ulteriori informazioni.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
Formazione
Per formare l'agente, segui questi passaggi:
- Esegui l'agente nell'ambiente per raccogliere i dati di addestramento per episodio.
- Calcola il rendimento atteso in ogni fase.
- Calcola la perdita per il modello combinato attore-critico.
- Calcola gradienti e aggiorna i parametri di rete.
- Ripetere 1-4 fino al raggiungimento del criterio di successo o del numero massimo di episodi.
1. Raccolta dei dati di allenamento
Come nell'apprendimento supervisionato, per addestrare il modello attore-critico, è necessario disporre di dati di addestramento. Tuttavia, per raccogliere tali dati, il modello dovrebbe essere "eseguito" nell'ambiente.
I dati di allenamento vengono raccolti per ogni episodio. Quindi ad ogni passo temporale, il passaggio in avanti del modello verrà eseguito sullo stato dell'ambiente al fine di generare le probabilità di azione e il valore critico in base alla politica corrente parametrizzata dai pesi del modello.
L'azione successiva verrà campionata dalle probabilità di azione generate dal modello, che verrebbero quindi applicate all'ambiente, generando lo stato successivo e la ricompensa.
Questo processo è implementato nella funzione run_episode , che utilizza le operazioni TensorFlow in modo che possa essere successivamente compilato in un grafico TensorFlow per un training più rapido. Si noti che tf.TensorArray s sono stati utilizzati per supportare l'iterazione Tensor su array di lunghezza variabile.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. Calcolo dei rendimenti attesi
La sequenza di premi per ogni timestep \(t\), \(\{r_{t}\}^{T}_{t=1}\) raccolti durante un episodio viene convertita in una sequenza di rendimenti attesi \(\{G_{t}\}^{T}_{t=1}\) in cui la somma dei premi viene presa dal timestep corrente \(t\) a \(T\) e ciascuno la ricompensa viene moltiplicata per un fattore di sconto in diminuzione esponenzialmente \(\gamma\):
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
Dal momento \(\gamma\in(0,1)\), alle ricompense più lontane dal timestep corrente viene dato meno peso.
Intuitivamente, il rendimento atteso implica semplicemente che le ricompense ora sono migliori delle ricompense successive. In senso matematico, serve a far convergere la somma delle ricompense.
Per stabilizzare l'allenamento, viene standardizzata anche la sequenza risultante dei rendimenti (cioè avere media zero e deviazione standard unitaria).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. La perdita dell'attore-critico
Poiché viene utilizzato un modello ibrido attore-critico, la funzione di perdita scelta è una combinazione di attori e perdite critiche per la formazione, come mostrato di seguito:
\[L = L_{actor} + L_{critic}\]
Perdita dell'attore
La perdita dell'attore si basa su gradienti politici con il critico come linea di base dipendente dallo stato e calcolata con stime a campione singolo (per episodio).
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
dove:
- \(T\): il numero di passaggi temporali per episodio, che può variare per episodio
- \(s_{t}\): lo stato al timestep \(t\)
- \(a_{t}\): azione scelta al timestep \(t\) dato lo stato \(s\)
- \(\pi_{\theta}\): è la polizza (attore) parametrizzata da \(\theta\)
- \(V^{\pi}_{\theta}\): è la funzione valore (critica) parametrizzata anche da \(\theta\)
- \(G = G_{t}\): il rendimento atteso per un dato stato, coppia di azioni al timestep \(t\)
Alla somma viene aggiunto un termine negativo poiché l'idea è quella di massimizzare le probabilità che le azioni producano ricompense più elevate riducendo al minimo la perdita combinata.
Vantaggio
Il termine \(G - V\) nella nostra formulazione \(L_{actor}\) è chiamato vantaggio , che indica quanto meglio viene data un'azione a un particolare stato rispetto a un'azione casuale selezionata secondo la policy \(\pi\) per quello stato.
Sebbene sia possibile escludere una linea di base, ciò può comportare una varianza elevata durante l'allenamento. E il bello della scelta del critico \(V\) come linea di base è che si è formato per essere il più vicino possibile a \(G\), portando a una varianza inferiore.
Inoltre, senza il critico, l'algoritmo proverebbe ad aumentare le probabilità per le azioni intraprese su un particolare stato in base al rendimento atteso, il che potrebbe non fare molta differenza se le probabilità relative tra le azioni rimangono le stesse.
Ad esempio, supponiamo che due azioni per un dato stato producano lo stesso rendimento atteso. Senza il critico, l'algoritmo cercherebbe di aumentare la probabilità di queste azioni in base all'obiettivo \(J\). Con il critico, potrebbe risultare che non c'è alcun vantaggio (\(G - V = 0\)) e quindi nessun beneficio ottenuto nell'aumentare le probabilità delle azioni e l'algoritmo imposterebbe i gradienti a zero.
Perdita critica
L'addestramento \(V\) per essere il più vicino possibile a \(G\) può essere impostato come un problema di regressione con la seguente funzione di perdita:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
dove \(L_{\delta}\) è la perdita di Huber , che è meno sensibile agli outlier nei dati rispetto alla perdita di errore quadrato.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. Definizione della fase di addestramento per l'aggiornamento dei parametri
Tutti i passaggi precedenti sono combinati in un passaggio di formazione che viene eseguito in ogni episodio. Tutti i passaggi che portano alla funzione di perdita vengono eseguiti con il contesto tf.GradientTape per abilitare la differenziazione automatica.
Questo tutorial utilizza l'ottimizzatore Adam per applicare i gradienti ai parametri del modello.
In questo passaggio viene calcolata anche la somma dei premi non scontati, episode_reward . Questo valore verrà utilizzato in seguito per valutare se il criterio di successo è soddisfatto.
Il contesto tf.function viene applicato alla funzione train_step in modo che possa essere compilato in un grafico TensorFlow richiamabile, che può portare a una velocità 10 volte superiore durante l'allenamento.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. Eseguire il ciclo di formazione
La formazione viene eseguita eseguendo la fase di formazione fino al raggiungimento del criterio di successo o del numero massimo di episodi.
Una registrazione continua delle ricompense degli episodi viene tenuta in coda. Una volta raggiunte 100 prove, la ricompensa più vecchia viene rimossa all'estremità sinistra (coda) della coda e quella più recente viene aggiunta in testa (a destra). Viene inoltre mantenuta una somma parziale delle ricompense per l'efficienza computazionale.
A seconda del tempo di esecuzione, l'allenamento può terminare in meno di un minuto.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
Visualizzazione
Dopo l'allenamento, sarebbe utile visualizzare come si comporta il modello nell'ambiente. Puoi eseguire le celle sottostanti per generare un'animazione GIF di un episodio eseguito del modello. Tieni presente che è necessario installare pacchetti aggiuntivi per OpenAI Gym per eseguire correttamente il rendering delle immagini dell'ambiente in Colab.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
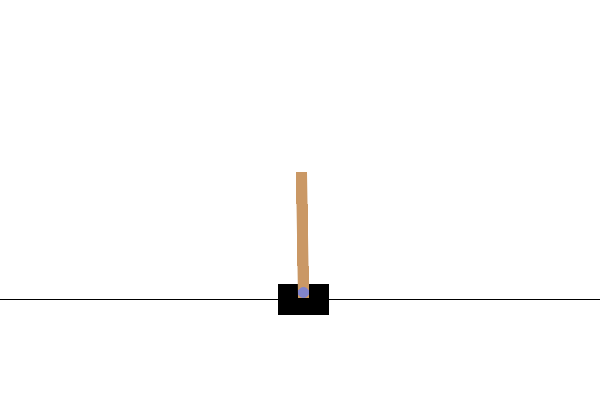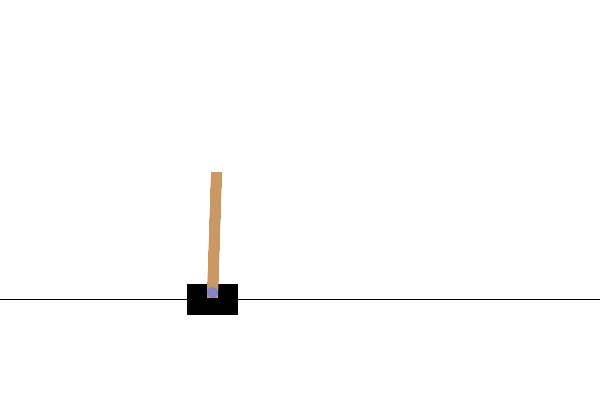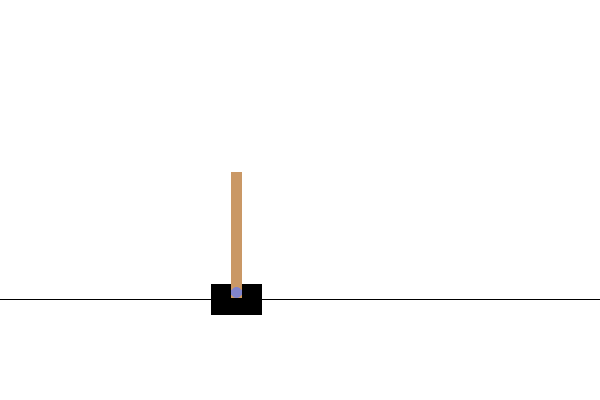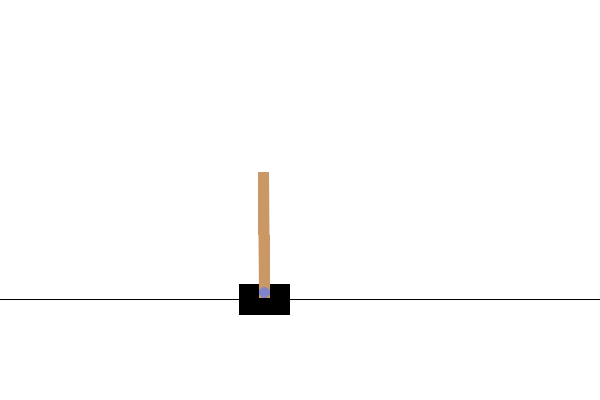
Prossimi passi
Questo tutorial ha dimostrato come implementare il metodo attore critico usando Tensorflow.
Come passaggio successivo, potresti provare ad allenare un modello in un ambiente diverso in OpenAI Gym.
Per ulteriori informazioni sui metodi attore-critici e sul problema Cartpole-v0, puoi fare riferimento alle seguenti risorse:
- Metodo critico dell'attore
- Lezione critica dell'attore (CAL)
- Problema di controllo dell'apprendimento del cartpolo [Barto, et al. 1983]
Per ulteriori esempi di apprendimento per rinforzo in TensorFlow, puoi controllare le seguenti risorse: