
Hướng dẫn này trình bày cách sử dụng các công cụ có sẵn với TensorFlow Profiler để theo dõi hiệu suất của các mô hình TensorFlow của bạn. Bạn sẽ tìm hiểu cách hiểu cách mô hình của bạn hoạt động trên máy chủ (CPU), thiết bị (GPU) hoặc trên sự kết hợp của cả máy chủ và (các) thiết bị.
Việc lập hồ sơ giúp hiểu mức tiêu thụ tài nguyên phần cứng (thời gian và bộ nhớ) của các hoạt động TensorFlow (ops) khác nhau trong mô hình của bạn, đồng thời giải quyết các tắc nghẽn về hiệu suất và cuối cùng là làm cho mô hình thực thi nhanh hơn.
Hướng dẫn này sẽ hướng dẫn bạn cách cài đặt Profiler, các công cụ khác nhau có sẵn, các chế độ khác nhau về cách Profiler thu thập dữ liệu hiệu suất và một số phương pháp hay nhất được đề xuất để tối ưu hóa hiệu suất mô hình.
Nếu bạn muốn lập hồ sơ hiệu suất mô hình của mình trên Cloud TPU, hãy tham khảo hướng dẫn Cloud TPU .
Cài đặt các điều kiện tiên quyết của Profiler và GPU
Cài đặt plugin Profiler cho TensorBoard bằng pip. Lưu ý rằng Profiler yêu cầu phiên bản mới nhất của TensorFlow và TensorBoard (>=2.2).
pip install -U tensorboard_plugin_profile
Để cấu hình trên GPU, bạn phải:
- Đáp ứng các yêu cầu về trình điều khiển GPU NVIDIA® và Bộ công cụ CUDA® được liệt kê trong các yêu cầu phần mềm hỗ trợ GPU TensorFlow .
Đảm bảo Giao diện công cụ cấu hình NVIDIA® CUDA® (CUPTI) tồn tại trên đường dẫn:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Nếu bạn không có CUPTI trên đường dẫn, hãy thêm thư mục cài đặt của nó vào biến môi trường $LD_LIBRARY_PATH bằng cách chạy:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Sau đó, chạy lại lệnh ldconfig ở trên để xác minh rằng thư viện CUPTI đã được tìm thấy.
Giải quyết vấn đề đặc quyền
Khi chạy lập hồ sơ bằng Bộ công cụ CUDA® trong môi trường Docker hoặc trên Linux, bạn có thể gặp phải sự cố liên quan đến việc không đủ đặc quyền CUPTI ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). Đi tới Tài liệu dành cho nhà phát triển NVIDIA để tìm hiểu thêm về cách bạn có thể giải quyết những vấn đề này trên Linux.
Để giải quyết các vấn đề về đặc quyền CUPTI trong môi trường Docker, hãy chạy
docker run option '--privileged=true'
Công cụ hồ sơ
Truy cập Profiler từ tab Profile trong TensorBoard, tab này chỉ xuất hiện sau khi bạn đã thu thập được một số dữ liệu mô hình.
Profiler có một số công cụ giúp phân tích hiệu suất:
- Trang tổng quan
- Máy phân tích đường ống đầu vào
- Thống kê TensorFlow
- Trình xem dấu vết
- Thống kê hạt nhân GPU
- Công cụ hồ sơ bộ nhớ
- Trình xem nhóm
Trang tổng quan
Trang tổng quan cung cấp chế độ xem cấp cao nhất về cách mô hình của bạn hoạt động trong quá trình chạy hồ sơ. Trang này hiển thị cho bạn trang tổng quan tổng hợp về máy chủ và tất cả thiết bị của bạn cũng như một số đề xuất để cải thiện hiệu suất đào tạo mô hình của bạn. Bạn cũng có thể chọn từng máy chủ trong danh sách Máy chủ thả xuống.
Trang tổng quan hiển thị dữ liệu như sau:
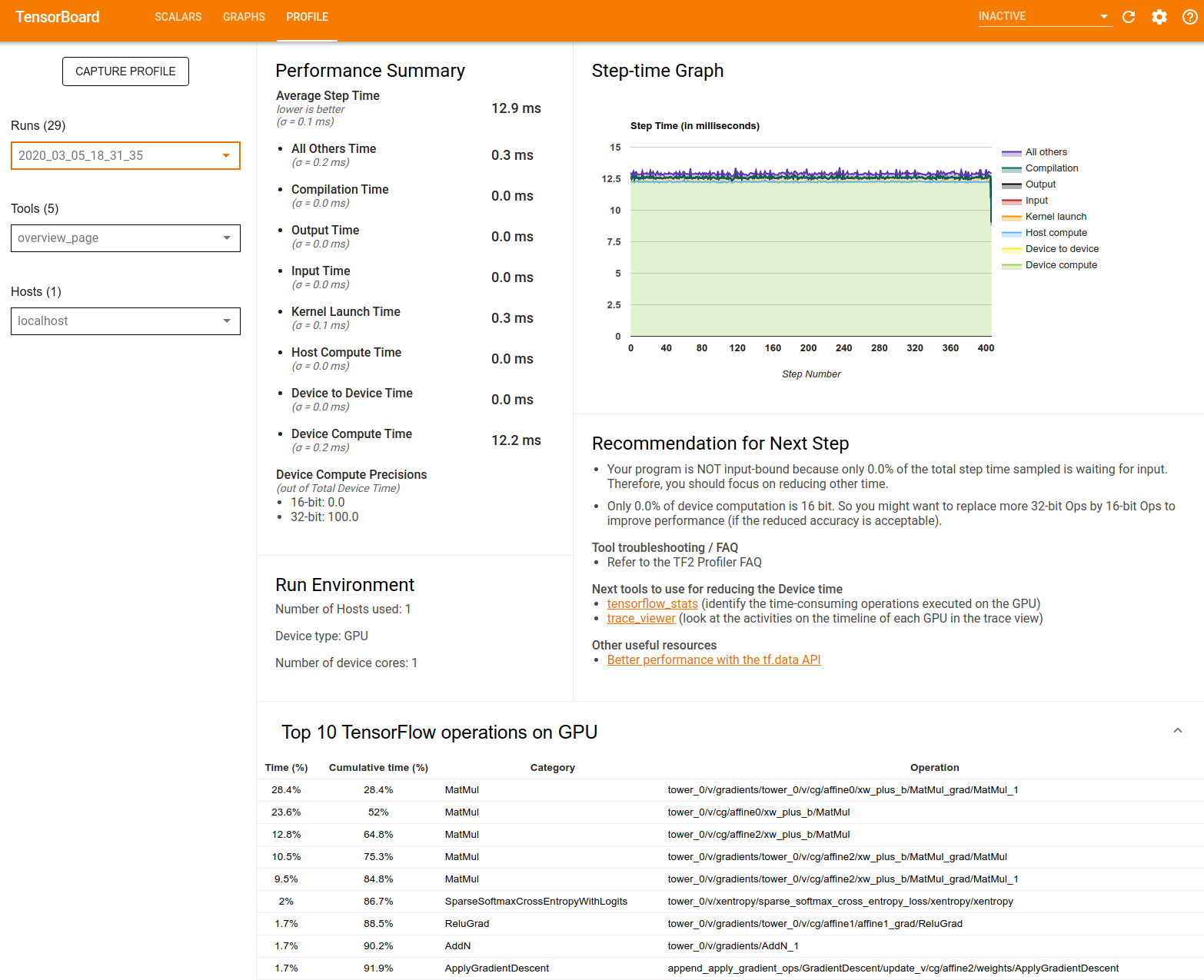
Tóm tắt Hiệu suất : Hiển thị bản tóm tắt cấp cao về hiệu suất mô hình của bạn. Bản tóm tắt hiệu suất có hai phần:
Phân tích từng bước thời gian: Chia thời gian bước trung bình thành nhiều loại thời gian được sử dụng:
- Biên dịch: Thời gian dành cho việc biên dịch hạt nhân.
- Đầu vào: Thời gian dành cho việc đọc dữ liệu đầu vào.
- Đầu ra: Thời gian dành cho việc đọc dữ liệu đầu ra.
- Khởi chạy hạt nhân: Thời gian máy chủ dành để khởi chạy hạt nhân
- Thời gian tính toán của máy chủ..
- Thời gian giao tiếp giữa thiết bị với thiết bị.
- Thời gian tính toán trên thiết bị.
- Tất cả những thứ khác, bao gồm cả chi phí Python.
Độ chính xác tính toán của thiết bị - Báo cáo phần trăm thời gian tính toán của thiết bị sử dụng phép tính 16 và 32 bit.
Biểu đồ thời gian từng bước : Hiển thị biểu đồ thời gian bước của thiết bị (tính bằng mili giây) trên tất cả các bước được lấy mẫu. Mỗi bước được chia thành nhiều danh mục (với các màu sắc khác nhau) về thời gian sử dụng. Vùng màu đỏ tương ứng với phần thời gian của bước mà thiết bị ở chế độ chờ chờ dữ liệu đầu vào từ máy chủ. Vùng màu xanh lá cây hiển thị thời gian thiết bị thực sự hoạt động.
10 hoạt động TensorFlow hàng đầu trên thiết bị (ví dụ: GPU) : Hiển thị các hoạt động trên thiết bị chạy lâu nhất.
Mỗi hàng hiển thị thời gian riêng của một hoạt động (dưới dạng phần trăm thời gian được thực hiện bởi tất cả các hoạt động), thời gian tích lũy, danh mục và tên.
Môi trường chạy : Hiển thị bản tóm tắt cấp cao về môi trường chạy mô hình bao gồm:
- Số lượng máy chủ được sử dụng
- Loại thiết bị (GPU/TPU).
- Số lượng lõi thiết bị.
Đề xuất cho Bước tiếp theo : Báo cáo khi một mô hình bị giới hạn đầu vào và đề xuất các công cụ bạn có thể sử dụng để xác định và giải quyết các tắc nghẽn về hiệu suất của mô hình.
Máy phân tích đường ống đầu vào
Khi chương trình TensorFlow đọc dữ liệu từ một tệp, nó sẽ bắt đầu ở đầu biểu đồ TensorFlow theo cách thức liên kết. Quá trình đọc được chia thành nhiều giai đoạn xử lý dữ liệu được kết nối nối tiếp, trong đó đầu ra của một giai đoạn là đầu vào của giai đoạn tiếp theo. Hệ thống đọc dữ liệu này được gọi là đường dẫn đầu vào .
Một quy trình điển hình để đọc bản ghi từ tệp có các giai đoạn sau:
- Đọc tập tin.
- Tiền xử lý tệp (tùy chọn).
- Truyền tập tin từ máy chủ sang thiết bị.
Đường dẫn đầu vào không hiệu quả có thể làm chậm ứng dụng của bạn một cách nghiêm trọng. Một ứng dụng được coi là giới hạn đầu vào khi nó dành một phần đáng kể thời gian trong quy trình đầu vào. Sử dụng thông tin chi tiết thu được từ bộ phân tích quy trình đầu vào để hiểu quy trình đầu vào hoạt động kém hiệu quả ở đâu.
Trình phân tích đường dẫn đầu vào sẽ cho bạn biết ngay lập tức liệu chương trình của bạn có bị giới hạn đầu vào hay không và hướng dẫn bạn thực hiện phân tích phía thiết bị và máy chủ để gỡ lỗi tắc nghẽn hiệu suất ở bất kỳ giai đoạn nào trong đường dẫn đầu vào.
Hãy xem hướng dẫn về hiệu suất của quy trình đầu vào để biết các phương pháp hay nhất được đề xuất nhằm tối ưu hóa quy trình đầu vào dữ liệu của bạn.
Bảng thông tin đường dẫn đầu vào
Để mở bộ phân tích đường dẫn đầu vào, hãy chọn Hồ sơ , sau đó chọn input_pipeline_analyzer từ menu thả xuống Công cụ .
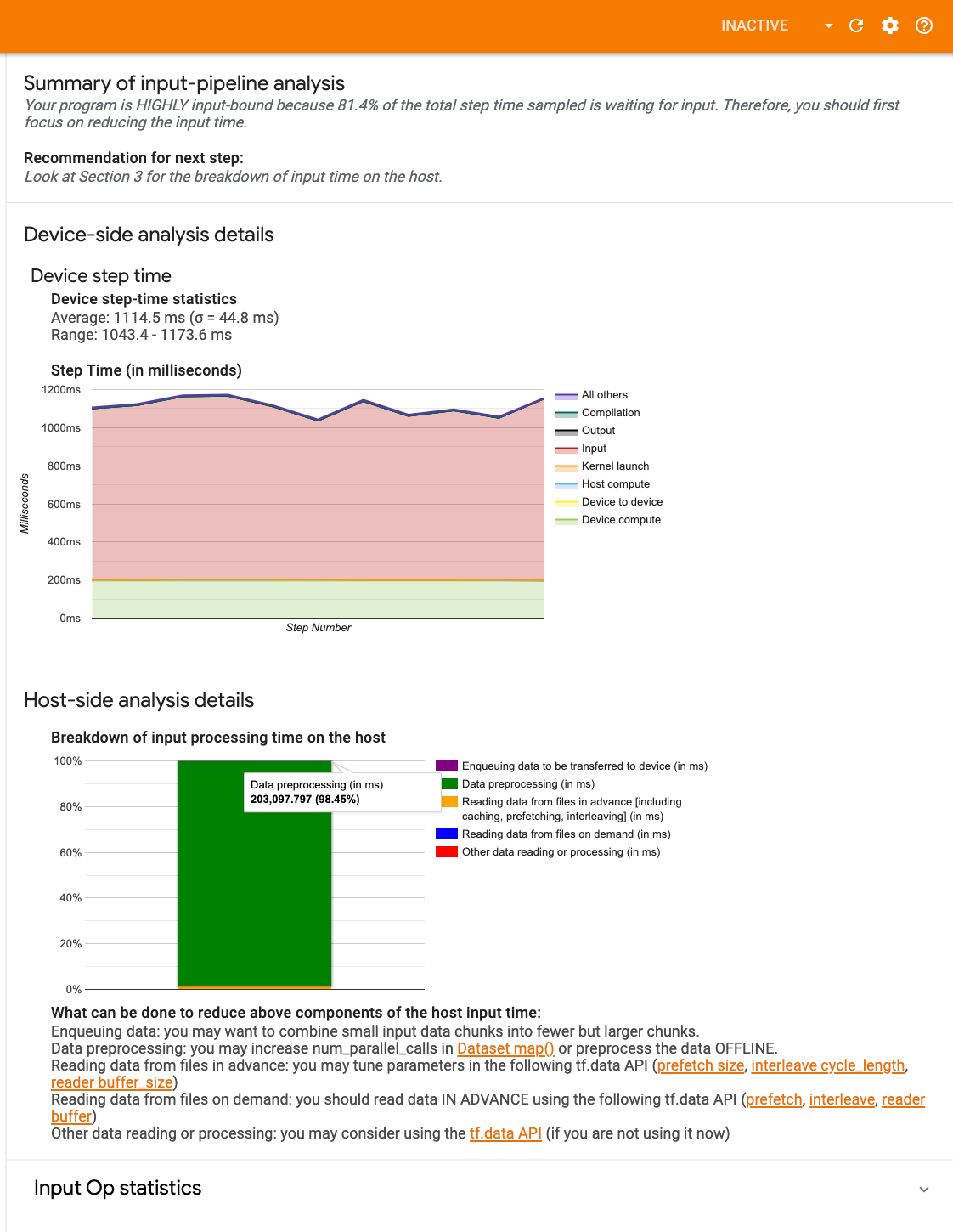
Bảng điều khiển có ba phần:
- Tóm tắt : Tóm tắt quy trình đầu vào tổng thể với thông tin về việc ứng dụng của bạn có bị giới hạn đầu vào hay không và nếu có thì bao nhiêu.
- Phân tích phía thiết bị : Hiển thị kết quả phân tích phía thiết bị chi tiết, bao gồm thời gian bước của thiết bị và phạm vi thời gian thiết bị dành để chờ dữ liệu đầu vào trên các lõi ở mỗi bước.
- Phân tích phía máy chủ : Hiển thị phân tích chi tiết về phía máy chủ, bao gồm phân tích chi tiết về thời gian xử lý đầu vào trên máy chủ.
Tóm tắt đường dẫn đầu vào
Báo cáo Tóm tắt xem chương trình của bạn có bị giới hạn đầu vào hay không bằng cách hiển thị phần trăm thời gian thiết bị dành để chờ đầu vào từ máy chủ. Nếu bạn đang sử dụng quy trình đầu vào tiêu chuẩn đã được trang bị thiết bị, công cụ sẽ báo cáo phần lớn thời gian xử lý đầu vào được sử dụng.
Phân tích phía thiết bị
Phân tích phía thiết bị cung cấp thông tin chi tiết về thời gian dành cho thiết bị so với trên máy chủ và lượng thời gian thiết bị đã dành để chờ dữ liệu đầu vào từ máy chủ.
- Thời gian bước được vẽ theo số bước : Hiển thị biểu đồ thời gian bước của thiết bị (tính bằng mili giây) trên tất cả các bước được lấy mẫu. Mỗi bước được chia thành nhiều danh mục (với các màu sắc khác nhau) về thời gian sử dụng. Vùng màu đỏ tương ứng với phần thời gian của bước mà thiết bị ở chế độ chờ chờ dữ liệu đầu vào từ máy chủ. Vùng màu xanh lá cây hiển thị lượng thời gian thiết bị thực sự hoạt động.
- Thống kê thời gian từng bước : Báo cáo mức trung bình, độ lệch chuẩn và phạm vi ([tối thiểu, tối đa]) của thời gian bước thiết bị.
Phân tích phía máy chủ
Phân tích phía máy chủ báo cáo phân tích thời gian xử lý đầu vào (thời gian dành cho các hoạt động API tf.data ) trên máy chủ thành nhiều danh mục:
- Đọc dữ liệu từ các tệp theo yêu cầu : Thời gian dành cho việc đọc dữ liệu từ các tệp mà không cần lưu vào bộ nhớ đệm, tìm nạp trước và xen kẽ.
- Đọc trước dữ liệu từ các tệp : Thời gian dành cho việc đọc các tệp, bao gồm bộ nhớ đệm, tìm nạp trước và xen kẽ.
- Xử lý trước dữ liệu : Thời gian dành cho các hoạt động tiền xử lý, chẳng hạn như giải nén hình ảnh.
- Xếp hàng dữ liệu để chuyển sang thiết bị : Thời gian dành cho việc đưa dữ liệu vào hàng đợi cấp dữ liệu trước khi truyền dữ liệu sang thiết bị.
Mở rộng Thống kê hoạt động đầu vào để kiểm tra số liệu thống kê cho từng hoạt động đầu vào và danh mục của chúng được chia nhỏ theo thời gian thực hiện.
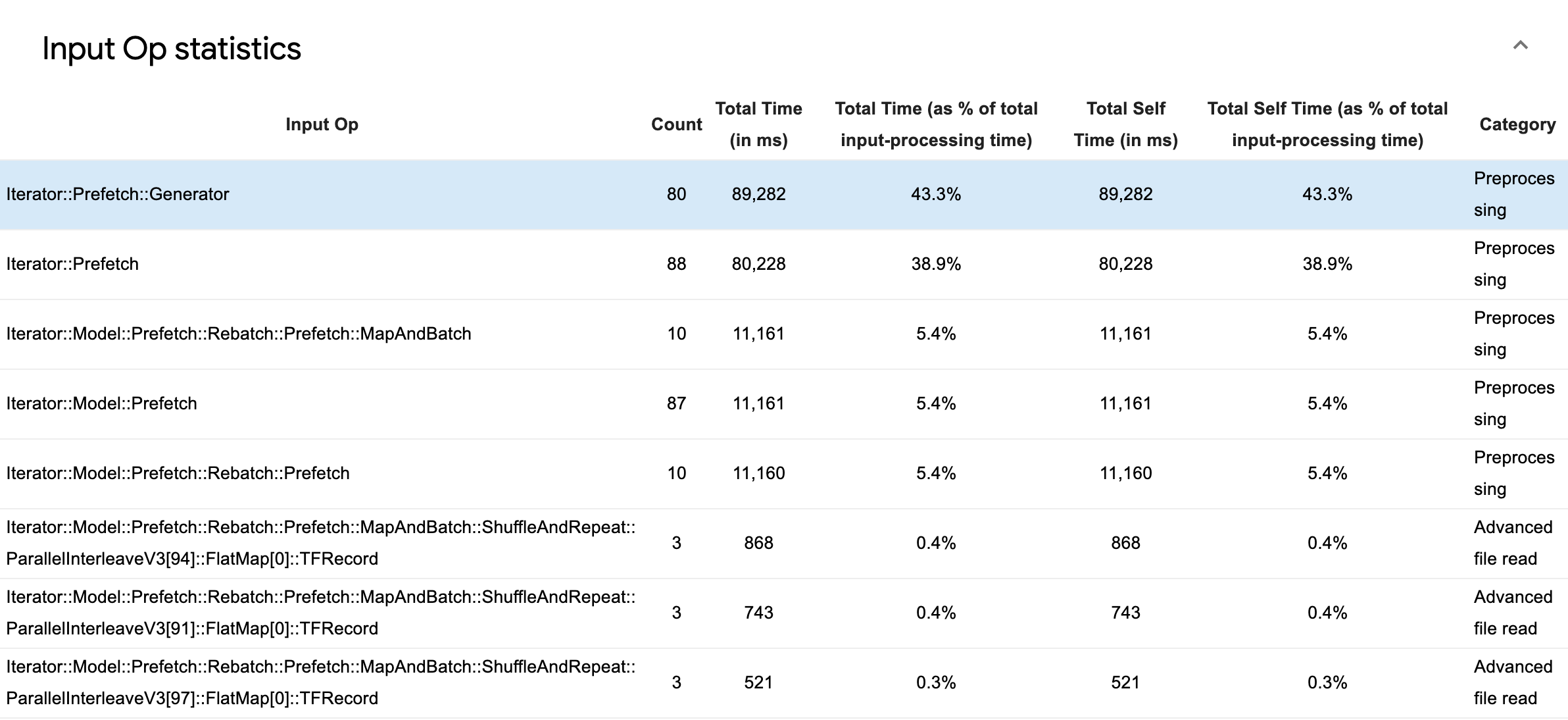
Một bảng dữ liệu nguồn sẽ xuất hiện với mỗi mục chứa thông tin sau:
- Op đầu vào : Hiển thị tên op TensorFlow của op đầu vào.
- Đếm : Hiển thị tổng số trường hợp thực hiện op trong khoảng thời gian lập hồ sơ.
- Tổng thời gian (tính bằng mili giây) : Hiển thị tổng thời gian tích lũy dành cho từng trường hợp đó.
- Tổng thời gian % : Hiển thị tổng thời gian dành cho một hoạt động dưới dạng một phần nhỏ của tổng thời gian dành cho xử lý đầu vào.
- Tổng thời gian tự sử dụng (tính bằng mili giây) : Hiển thị tổng tích lũy thời gian tự sử dụng cho từng trường hợp đó. Self time ở đây đo thời gian dành cho bên trong thân hàm, không bao gồm thời gian dành cho hàm mà nó gọi.
- Tổng thời gian riêng % . Hiển thị tổng thời gian tự động dưới dạng một phần nhỏ của tổng thời gian dành cho xử lý đầu vào.
- Loại . Hiển thị danh mục xử lý của op đầu vào.
Số liệu thống kê TensorFlow
Công cụ TensorFlow Stats hiển thị hiệu suất của mọi hoạt động (op) TensorFlow được thực thi trên máy chủ hoặc thiết bị trong phiên định hình.
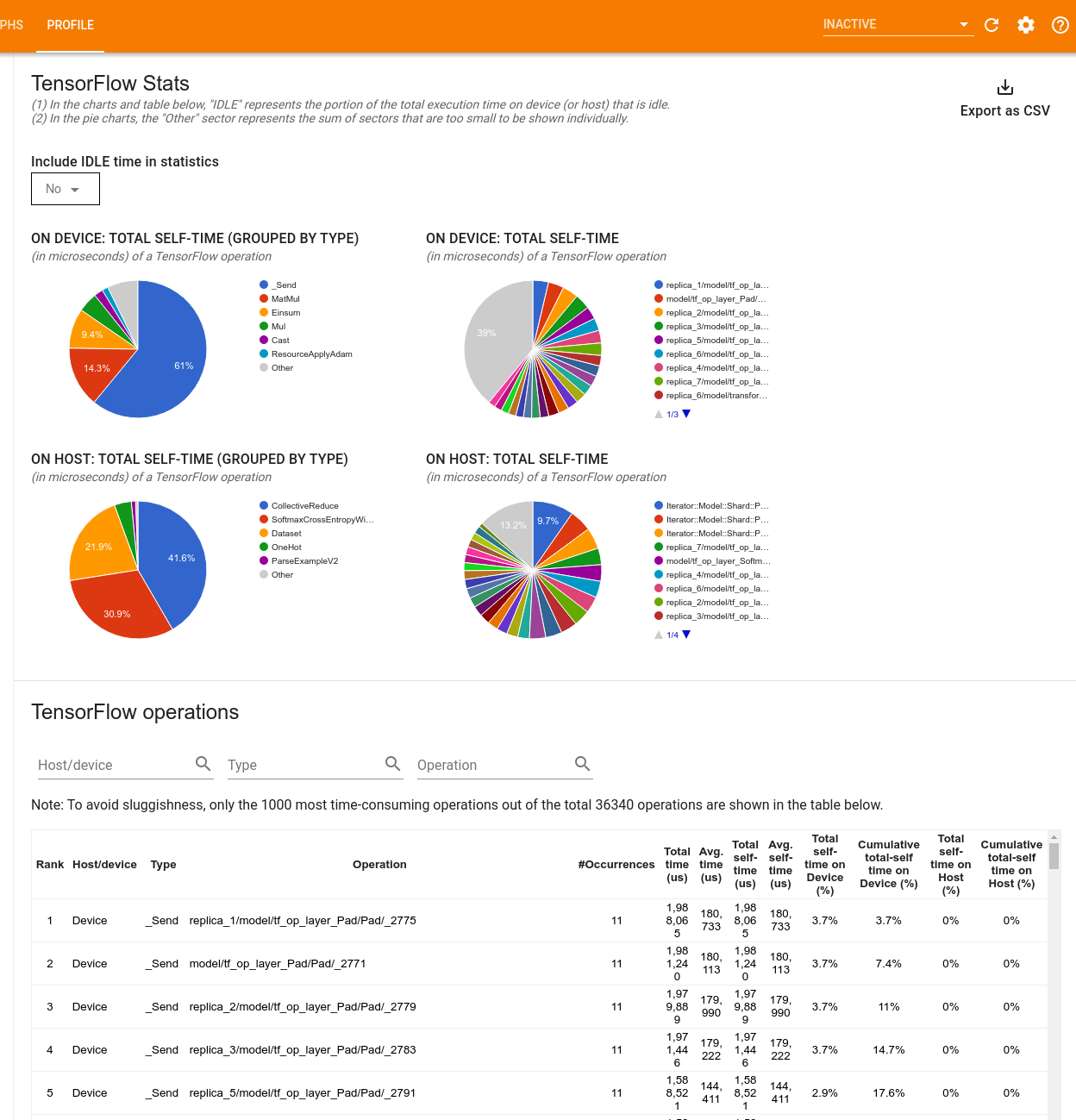
Công cụ hiển thị thông tin hiệu suất trong hai khung:
Khung phía trên hiển thị tối đa bốn biểu đồ hình tròn:
- Sự phân bổ thời gian tự thực hiện của từng op trên máy chủ.
- Sự phân bổ thời gian tự thực hiện của từng loại op trên máy chủ.
- Phân bố thời gian tự thực hiện của từng op trên thiết bị.
- Phân bố thời gian tự thực hiện của từng loại op trên thiết bị.
Ngăn bên dưới hiển thị một bảng báo cáo dữ liệu về các hoạt động của TensorFlow với một hàng cho mỗi hoạt động và một cột cho từng loại dữ liệu (sắp xếp các cột bằng cách nhấp vào tiêu đề của cột). Nhấp vào nút Xuất dưới dạng CSV ở phía bên phải của khung phía trên để xuất dữ liệu từ bảng này dưới dạng tệp CSV.
Lưu ý rằng:
Nếu bất kỳ op nào có op con:
- Tổng thời gian "tích lũy" của một op bao gồm thời gian dành cho các op con.
- Tổng thời gian "tự" của một op không bao gồm thời gian dành cho các op con.
Nếu một op thực thi trên máy chủ:
- Tỷ lệ phần trăm của tổng thời gian tự sử dụng trên thiết bị do thao tác bật sẽ là 0.
- Tỷ lệ phần trăm tích lũy của tổng thời gian tự động trên thiết bị cho đến và bao gồm cả tùy chọn này sẽ là 0.
Nếu một op thực thi trên thiết bị:
- Tỷ lệ phần trăm của tổng thời gian tự xử lý trên máy chủ do hoạt động này gây ra sẽ là 0.
- Phần trăm tích lũy của tổng thời gian tự động trên máy chủ cho đến và bao gồm cả hoạt động này sẽ là 0.
Bạn có thể chọn bao gồm hoặc loại trừ Thời gian nhàn rỗi trong biểu đồ hình tròn và bảng.
Trình xem dấu vết
Trình xem dấu vết hiển thị dòng thời gian cho thấy:
- Khoảng thời gian cho các hoạt động được mô hình TensorFlow của bạn thực thi
- Phần nào của hệ thống (máy chủ hoặc thiết bị) đã thực thi lệnh op. Thông thường, máy chủ thực hiện các thao tác đầu vào, xử lý trước dữ liệu huấn luyện và truyền nó đến thiết bị, trong khi thiết bị thực hiện huấn luyện mô hình thực tế.
Trình xem dấu vết cho phép bạn xác định các vấn đề về hiệu suất trong mô hình của mình, sau đó thực hiện các bước để giải quyết chúng. Ví dụ: ở cấp độ cao, bạn có thể xác định liệu việc đào tạo đầu vào hay mô hình đang chiếm phần lớn thời gian. Đi sâu hơn, bạn có thể xác định hoạt động nào mất nhiều thời gian nhất để thực hiện. Lưu ý rằng trình xem theo dõi bị giới hạn ở 1 triệu sự kiện trên mỗi thiết bị.
Giao diện xem dấu vết
Khi bạn mở trình xem theo dõi, nó sẽ xuất hiện hiển thị lần chạy gần đây nhất của bạn:
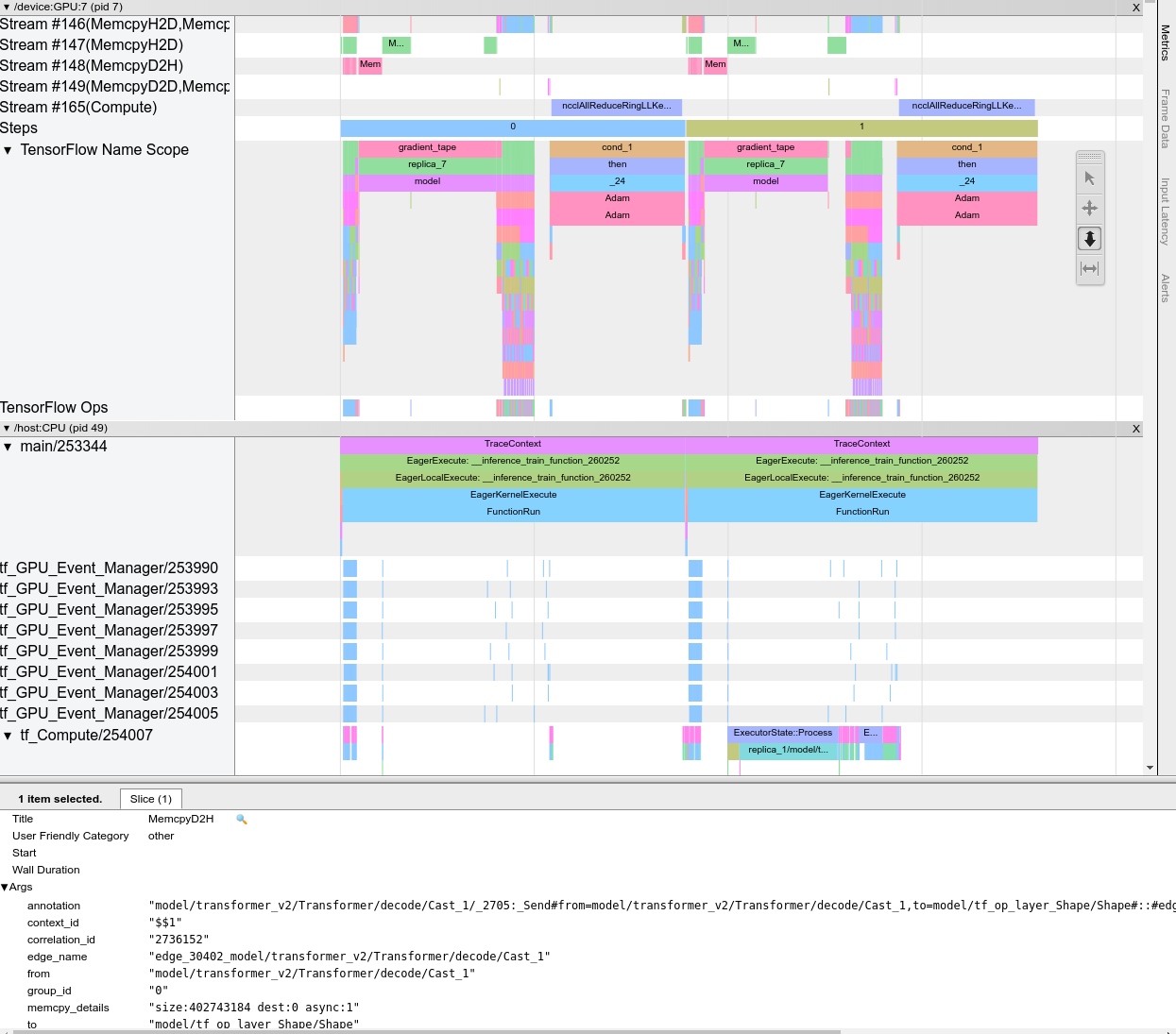
Màn hình này chứa các thành phần chính sau:
- Khung dòng thời gian : Hiển thị các hoạt động mà thiết bị và máy chủ thực hiện theo thời gian.
- Ngăn chi tiết : Hiển thị thông tin bổ sung cho các hoạt động được chọn trong ngăn Dòng thời gian.
Khung Dòng thời gian chứa các thành phần sau:
- Thanh trên cùng : Chứa nhiều điều khiển phụ trợ khác nhau.
- Trục thời gian : Hiển thị thời gian liên quan đến điểm bắt đầu của dấu vết.
- Nhãn phần và bản nhạc : Mỗi phần chứa nhiều bản nhạc và có một hình tam giác ở bên trái mà bạn có thể nhấp vào để mở rộng và thu gọn phần đó. Có một phần dành cho mọi phần tử xử lý trong hệ thống.
- Bộ chọn công cụ : Chứa nhiều công cụ khác nhau để tương tác với trình xem dấu vết như Thu phóng, Xoay, Chọn và Định giờ. Sử dụng công cụ Timing để đánh dấu một khoảng thời gian.
- Sự kiện : Chúng hiển thị thời gian thực hiện một hoạt động hoặc thời lượng của các siêu sự kiện, chẳng hạn như các bước huấn luyện.
Các phần và bài hát
Trình xem dấu vết chứa các phần sau:
- Một phần dành cho mỗi nút thiết bị , được gắn nhãn bằng số lượng chip thiết bị và nút thiết bị trong chip (ví dụ:
/device:GPU:0 (pid 0)). Mỗi phần nút thiết bị chứa các rãnh sau:- Bước : Hiển thị thời lượng của các bước đào tạo đang chạy trên thiết bị
- TensorFlow Ops : Hiển thị các op được thực thi trên thiết bị
- XLA Ops : Hiển thị các hoạt động XLA (ops) chạy trên thiết bị nếu XLA là trình biên dịch được sử dụng (mỗi hoạt động TensorFlow được dịch thành một hoặc một số hoạt động XLA. Trình biên dịch XLA sẽ dịch các hoạt động XLA thành mã chạy trên thiết bị).
- Một phần dành cho các luồng chạy trên CPU của máy chủ, được gắn nhãn "Chủ đề máy chủ" . Phần này chứa một rãnh cho mỗi luồng CPU. Lưu ý rằng bạn có thể bỏ qua thông tin hiển thị cùng với nhãn phần.
Sự kiện
Các sự kiện trong dòng thời gian được hiển thị bằng các màu khác nhau; bản thân màu sắc không có ý nghĩa cụ thể.
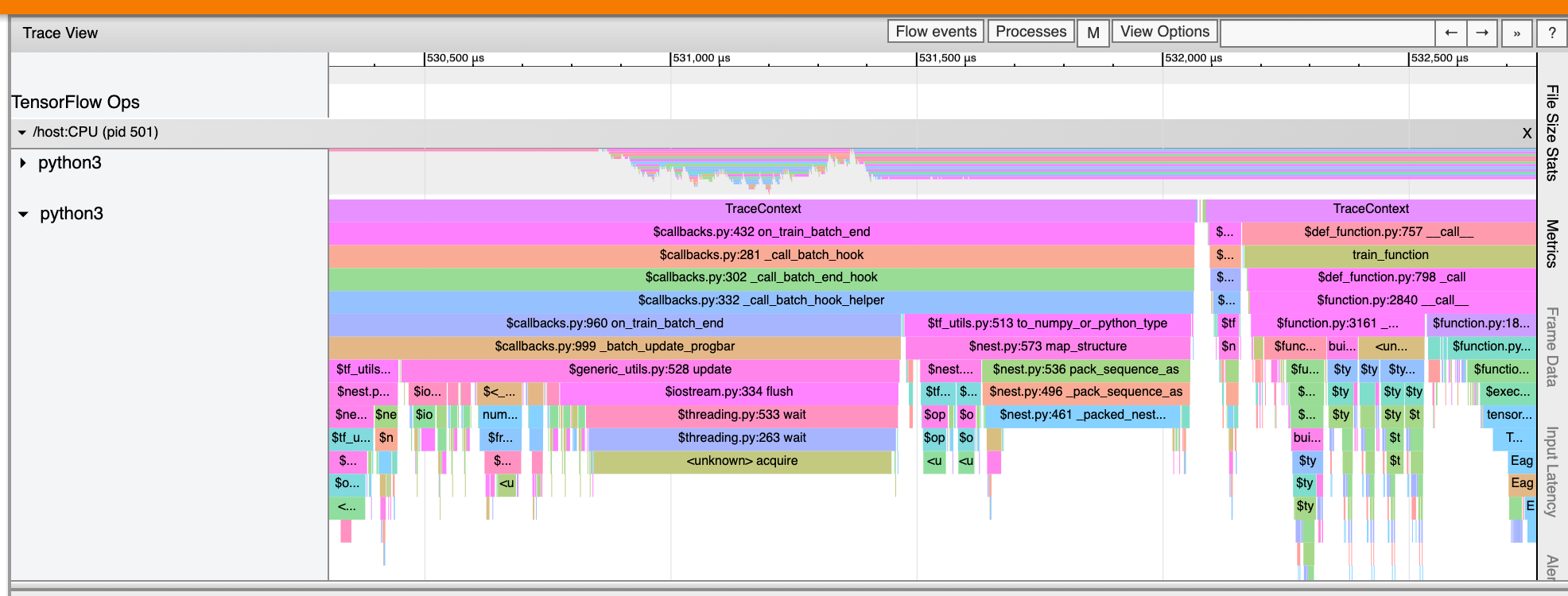
Trình xem dấu vết cũng có thể hiển thị dấu vết của lệnh gọi hàm Python trong chương trình TensorFlow của bạn. Nếu sử dụng API tf.profiler.experimental.start , bạn có thể bật tính năng theo dõi Python bằng cách sử dụng ProfilerOptions có têntuple khi bắt đầu lập hồ sơ. Ngoài ra, nếu bạn sử dụng chế độ lấy mẫu để lập hồ sơ, bạn có thể chọn mức độ theo dõi bằng cách sử dụng các tùy chọn thả xuống trong hộp thoại Capture Profile .
Số liệu thống kê hạt nhân GPU
Công cụ này hiển thị số liệu thống kê hiệu suất và hoạt động ban đầu cho mọi hạt nhân được tăng tốc GPU.
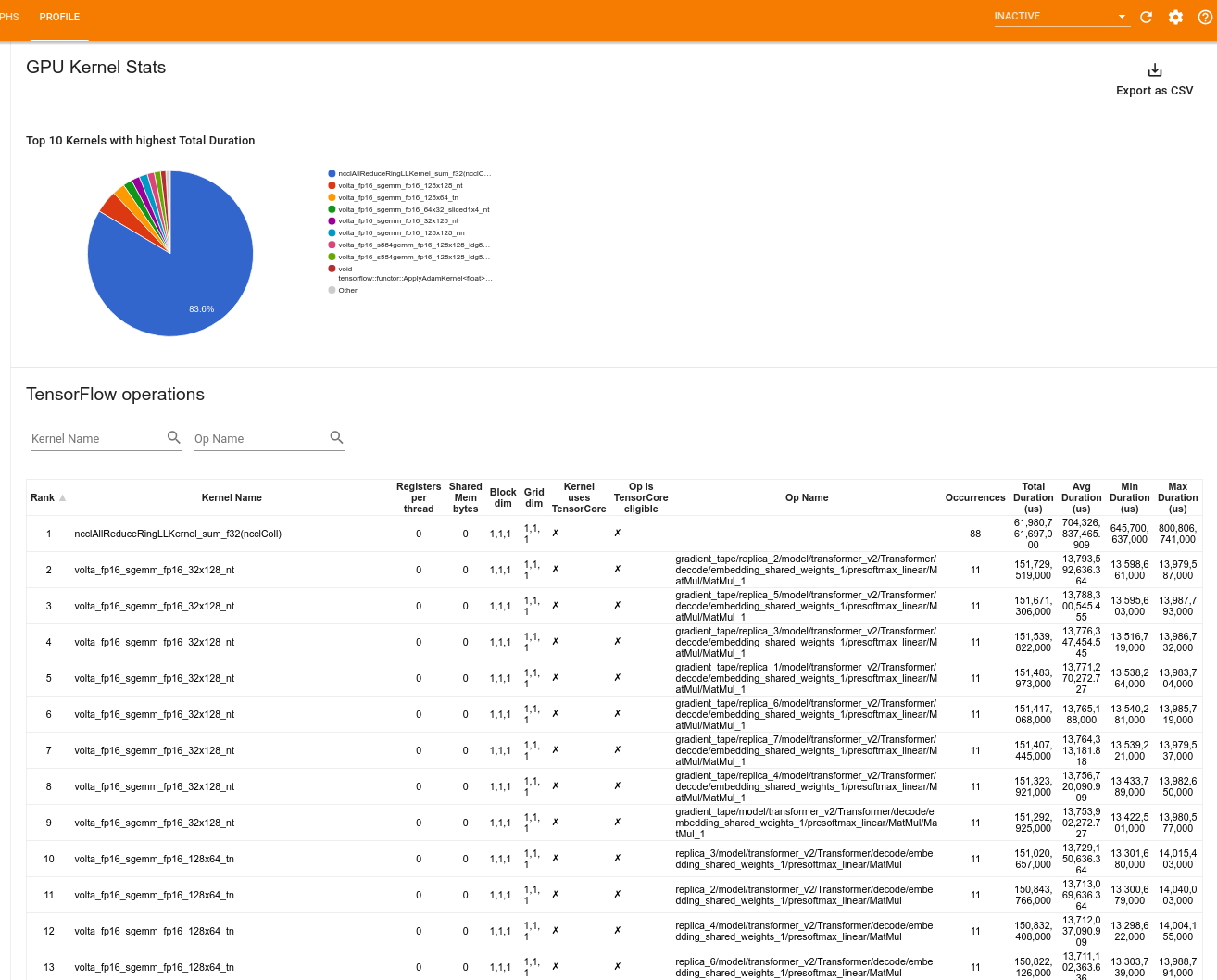
Công cụ hiển thị thông tin trong hai khung:
Khung phía trên hiển thị biểu đồ hình tròn hiển thị các hạt nhân CUDA có tổng thời gian trôi qua cao nhất.
Khung bên dưới hiển thị một bảng có dữ liệu sau cho từng cặp kernel-op duy nhất:
- Xếp hạng theo thứ tự giảm dần của tổng thời lượng GPU đã trôi qua được nhóm theo cặp kernel-op.
- Tên của kernel đã khởi chạy.
- Số lượng thanh ghi GPU được kernel sử dụng.
- Tổng kích thước của bộ nhớ chia sẻ (tĩnh + chia sẻ động) được sử dụng tính bằng byte.
- Kích thước khối được biểu thị dưới dạng
blockDim.x, blockDim.y, blockDim.z. - Kích thước lưới được biểu thị dưới dạng
gridDim.x, gridDim.y, gridDim.z. - Liệu op có đủ điều kiện để sử dụng Tensor Cores hay không.
- Liệu hạt nhân có chứa các hướng dẫn Tensor Core hay không.
- Tên của op đã khởi chạy kernel này.
- Số lần xuất hiện của cặp kernel-op này.
- Tổng thời gian GPU đã trôi qua tính bằng micro giây.
- Thời gian GPU đã trôi qua trung bình tính bằng micro giây.
- Thời gian GPU trôi qua tối thiểu tính bằng micro giây.
- Thời gian GPU đã trôi qua tối đa tính bằng micro giây.
Công cụ hồ sơ bộ nhớ
Công cụ Hồ sơ bộ nhớ giám sát việc sử dụng bộ nhớ của thiết bị trong khoảng thời gian lập hồ sơ. Bạn có thể sử dụng công cụ này để:
- Gỡ lỗi các vấn đề về bộ nhớ (OOM) bằng cách xác định mức sử dụng bộ nhớ cao nhất và phân bổ bộ nhớ tương ứng cho các hoạt động của TensorFlow. Bạn cũng có thể gỡ lỗi các sự cố OOM có thể phát sinh khi bạn chạy suy luận nhiều bên thuê .
- Gỡ lỗi các vấn đề phân mảnh bộ nhớ.
Công cụ hồ sơ bộ nhớ hiển thị dữ liệu theo ba phần:
- Tóm tắt hồ sơ bộ nhớ
- Biểu đồ dòng thời gian bộ nhớ
- Bảng phân tích bộ nhớ
Tóm tắt hồ sơ bộ nhớ
Phần này hiển thị bản tóm tắt cấp cao về cấu hình bộ nhớ của chương trình TensorFlow của bạn như hiển thị bên dưới:

Tóm tắt hồ sơ bộ nhớ có sáu trường:
- ID bộ nhớ : Danh sách thả xuống liệt kê tất cả các hệ thống bộ nhớ có sẵn của thiết bị. Chọn hệ thống bộ nhớ bạn muốn xem từ danh sách thả xuống.
- #Allocation : Số lượng phân bổ bộ nhớ được thực hiện trong khoảng thời gian lập hồ sơ.
- #Deallocation : Số lượng phân bổ bộ nhớ trong khoảng thời gian định hình
- Dung lượng bộ nhớ : Tổng dung lượng (tính bằng GiBs) của hệ thống bộ nhớ mà bạn chọn.
- Mức sử dụng Heap tối đa : Mức sử dụng bộ nhớ cao nhất (tính bằng GiB) kể từ khi mô hình bắt đầu chạy.
- Mức sử dụng bộ nhớ cao nhất : Mức sử dụng bộ nhớ cao nhất (tính bằng GiB) trong khoảng thời gian lập hồ sơ. Trường này chứa các trường con sau:
- Dấu thời gian : Dấu thời gian xảy ra mức sử dụng bộ nhớ cao nhất trên Biểu đồ dòng thời gian.
- Đặt trước ngăn xếp : Lượng bộ nhớ dành riêng trên ngăn xếp (tính bằng GiB).
- Phân bổ Heap : Lượng bộ nhớ được phân bổ trên heap (tính bằng GiB).
- Bộ nhớ trống : Dung lượng bộ nhớ trống (tính bằng GiB). Dung lượng bộ nhớ là tổng của Đặt trước ngăn xếp, Phân bổ vùng heap và Bộ nhớ trống.
- Phân mảnh : Tỷ lệ phân mảnh (càng thấp càng tốt). Nó được tính theo tỷ lệ phần trăm của
(1 - Size of the largest chunk of free memory / Total free memory).
Biểu đồ dòng thời gian bộ nhớ
Phần này hiển thị biểu đồ về mức sử dụng bộ nhớ (tính bằng GiB) và tỷ lệ phần trăm phân mảnh theo thời gian (tính bằng mili giây).
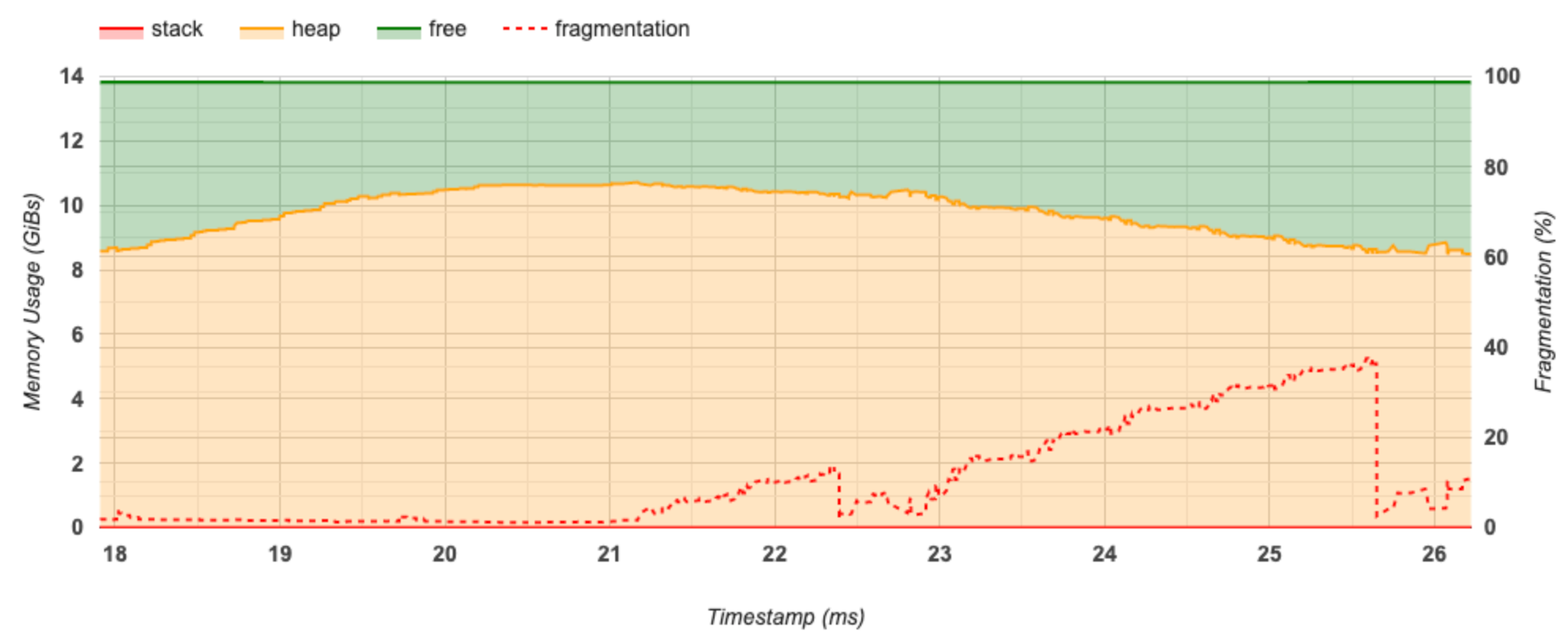
Trục X biểu thị dòng thời gian (tính bằng ms) của khoảng thời gian lập hồ sơ. Trục Y ở bên trái biểu thị mức sử dụng bộ nhớ (tính bằng GiB) và trục Y ở bên phải biểu thị tỷ lệ phân mảnh. Tại mỗi thời điểm trên trục X, tổng bộ nhớ được chia thành ba loại: ngăn xếp (màu đỏ), đống (màu cam) và trống (màu xanh lá cây). Di chuột qua dấu thời gian cụ thể để xem chi tiết về các sự kiện cấp phát/giải phóng bộ nhớ tại thời điểm đó như bên dưới:
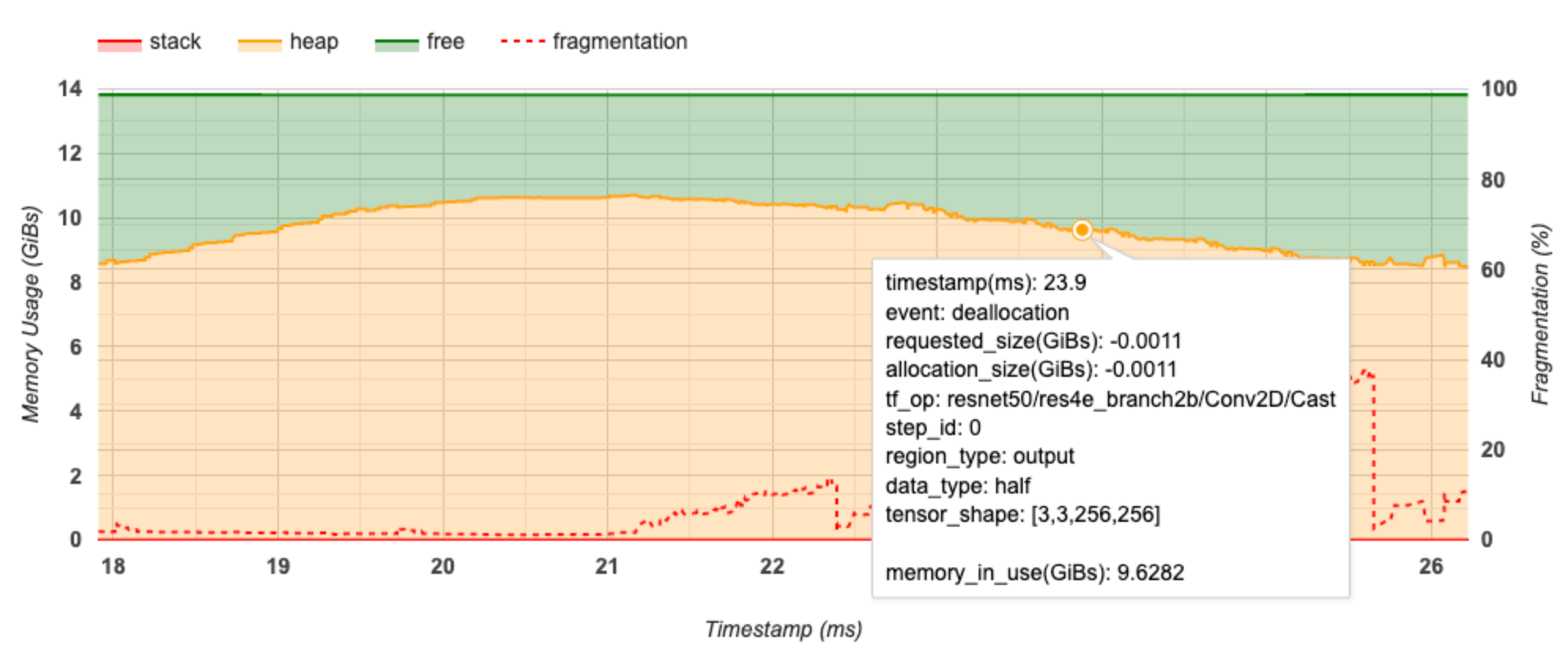
Cửa sổ bật lên hiển thị thông tin sau:
- timestamp(ms) : Vị trí của sự kiện được chọn trên dòng thời gian.
- sự kiện : Loại sự kiện (phân bổ hoặc giải quyết).
- request_size(GiBs) : Dung lượng bộ nhớ được yêu cầu. Đây sẽ là số âm cho các sự kiện phân bổ.
- alocation_size(GiBs) : Dung lượng bộ nhớ thực tế được phân bổ. Đây sẽ là số âm cho các sự kiện phân bổ.
- tf_op : Hoạt động TensorFlow yêu cầu phân bổ/thỏa thuận.
- step_id : Bước huấn luyện mà sự kiện này xảy ra.
- Region_type : Loại thực thể dữ liệu mà bộ nhớ được phân bổ này dành cho. Các giá trị có thể có là
tempcho giá trị tạm thời,outputcho kích hoạt và độ dốc cũng như giá trịpersist/dynamiccho trọng số và hằng số. - data_type : Loại phần tử tensor (ví dụ: uint8 cho số nguyên không dấu 8 bit).
- tensor_shape : Hình dạng của tensor được phân bổ/hủy phân bổ.
- Memory_in_use(GiBs) : Tổng bộ nhớ đang được sử dụng tại thời điểm này.
Bảng phân tích bộ nhớ
Bảng này hiển thị phân bổ bộ nhớ hoạt động tại thời điểm sử dụng bộ nhớ cao nhất trong khoảng thời gian lập hồ sơ.
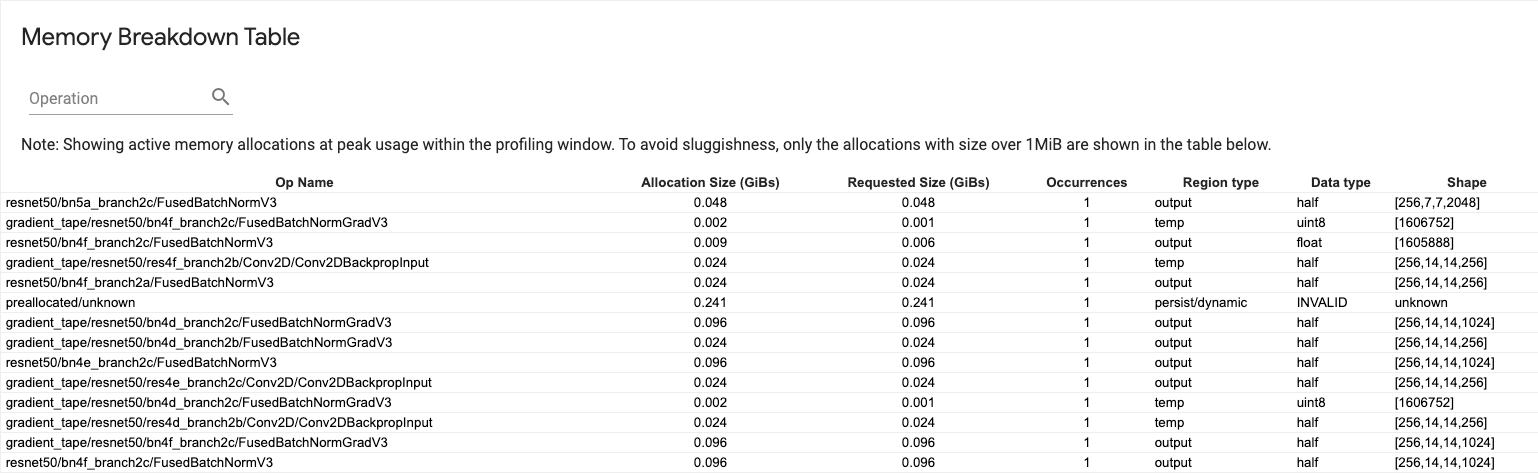
Có một hàng cho mỗi TensorFlow Op và mỗi hàng có các cột sau:
- Tên hoạt động : Tên của TensorFlow op.
- Kích thước phân bổ (GiBs) : Tổng dung lượng bộ nhớ được phân bổ cho op này.
- Kích thước được yêu cầu (GiBs) : Tổng dung lượng bộ nhớ được yêu cầu cho hoạt động này.
- Lần xuất hiện : Số lượng phân bổ cho op này.
- Loại vùng : Loại thực thể dữ liệu mà bộ nhớ được phân bổ này dành cho. Các giá trị có thể có là
tempcho giá trị tạm thời,outputcho kích hoạt và độ dốc cũng như giá trịpersist/dynamiccho trọng số và hằng số. - Kiểu dữ liệu : Kiểu phần tử tensor.
- Shape : Hình dạng của tensor được phân bổ.
Trình xem nhóm
Công cụ Pod Viewer hiển thị thông tin chi tiết về bước đào tạo của tất cả nhân viên.
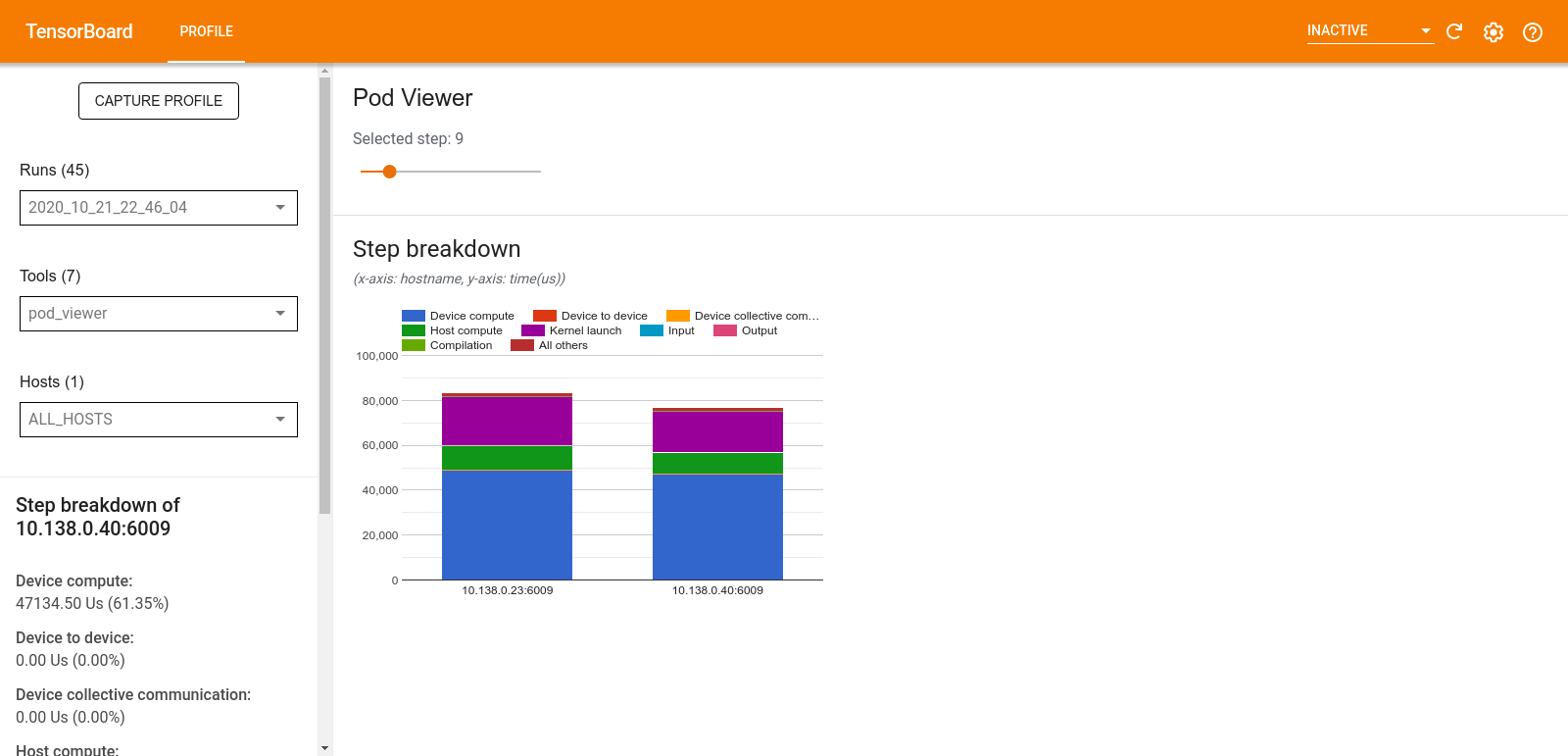
- Khung phía trên có một thanh trượt để chọn số bước.
- Ngăn bên dưới hiển thị biểu đồ cột xếp chồng lên nhau. Đây là chế độ xem cấp cao về các danh mục thời gian được chia nhỏ được đặt chồng lên nhau. Mỗi cột xếp chồng lên nhau đại diện cho một công nhân duy nhất.
- Khi bạn di chuột qua cột xếp chồng, thẻ ở phía bên trái sẽ hiển thị thêm chi tiết về phân tích bước.
phân tích tắc nghẽn tf.data
Công cụ phân tích tắc nghẽn tf.data tự động phát hiện các tắc nghẽn trong quy trình đầu vào tf.data trong chương trình của bạn và đưa ra các đề xuất về cách khắc phục chúng. Nó hoạt động với bất kỳ chương trình nào sử dụng tf.data bất kể nền tảng (CPU/GPU/TPU). Phân tích và khuyến nghị của nó dựa trên hướng dẫn này.
Nó phát hiện tắc nghẽn bằng cách làm theo các bước sau:
- Tìm máy chủ có giới hạn đầu vào nhất.
- Tìm cách thực thi chậm nhất của đường dẫn đầu vào
tf.data. - Xây dựng lại biểu đồ đường dẫn đầu vào từ dấu vết của trình lược tả.
- Tìm đường dẫn quan trọng trong biểu đồ đường ống đầu vào.
- Xác định sự chuyển đổi chậm nhất trên con đường quan trọng là một nút cổ chai.
Giao diện người dùng được chia thành ba phần: Tóm tắt phân tích hiệu suất , Tóm tắt tất cả các đường ống đầu vào và Biểu đồ đường ống đầu vào .
Tóm tắt phân tích hiệu suất

Phần này cung cấp bản tóm tắt của phân tích. Nó báo cáo về đường dẫn đầu vào tf.data chậm được phát hiện trong hồ sơ. Phần này cũng hiển thị máy chủ có giới hạn đầu vào nhiều nhất và đường dẫn đầu vào chậm nhất với độ trễ tối đa. Quan trọng nhất là nó xác định phần nào của đường ống đầu vào bị tắc nghẽn và cách khắc phục. Thông tin về nút thắt cổ chai được cung cấp cùng với loại vòng lặp và tên dài của nó.
Cách đọc tên dài của tf.data iterator
Một tên dài được định dạng là Iterator::<Dataset_1>::...::<Dataset_n> . Trong tên dài, <Dataset_n> khớp với loại trình vòng lặp và các tập dữ liệu khác trong tên dài biểu thị các phép biến đổi xuôi dòng.
Ví dụ: hãy xem xét tập dữ liệu đường ống đầu vào sau:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Tên dài của các trình vòng lặp từ tập dữ liệu trên sẽ là:
| Loại vòng lặp | Tên dài |
|---|---|
| Phạm vi | Trình vòng lặp::Batch::Lặp lại::Bản đồ::Phạm vi |
| Bản đồ | Trình vòng lặp::Batch::Lặp lại::Bản đồ |
| Lặp lại | Trình vòng lặp::Batch::Lặp lại |
| Lô | Trình vòng lặp::Batch |
Tóm tắt tất cả các đường ống đầu vào
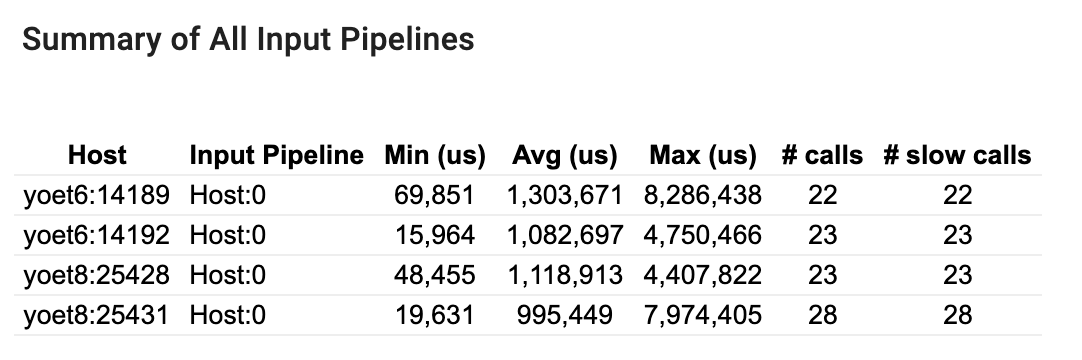
Phần này cung cấp bản tóm tắt của tất cả các đường dẫn đầu vào trên tất cả các máy chủ. Thông thường có một đường ống đầu vào. Khi sử dụng chiến lược phân phối, có một đường dẫn đầu vào máy chủ chạy mã tf.data của chương trình và nhiều đường dẫn đầu vào thiết bị lấy dữ liệu từ đường dẫn đầu vào máy chủ và truyền dữ liệu đó đến các thiết bị.
Đối với mỗi đường dẫn đầu vào, nó hiển thị số liệu thống kê về thời gian thực hiện của nó. Một cuộc gọi được tính là chậm nếu kéo dài hơn 50 μs.
Biểu đồ đường ống đầu vào

Phần này hiển thị biểu đồ đường dẫn đầu vào với thông tin về thời gian thực hiện. Bạn có thể sử dụng "Máy chủ" và "Đường ống đầu vào" để chọn máy chủ và đường dẫn đầu vào cần xem. Việc thực thi quy trình đầu vào được sắp xếp theo thời gian thực hiện theo thứ tự giảm dần mà bạn có thể chọn bằng cách sử dụng danh sách thả xuống Xếp hạng.
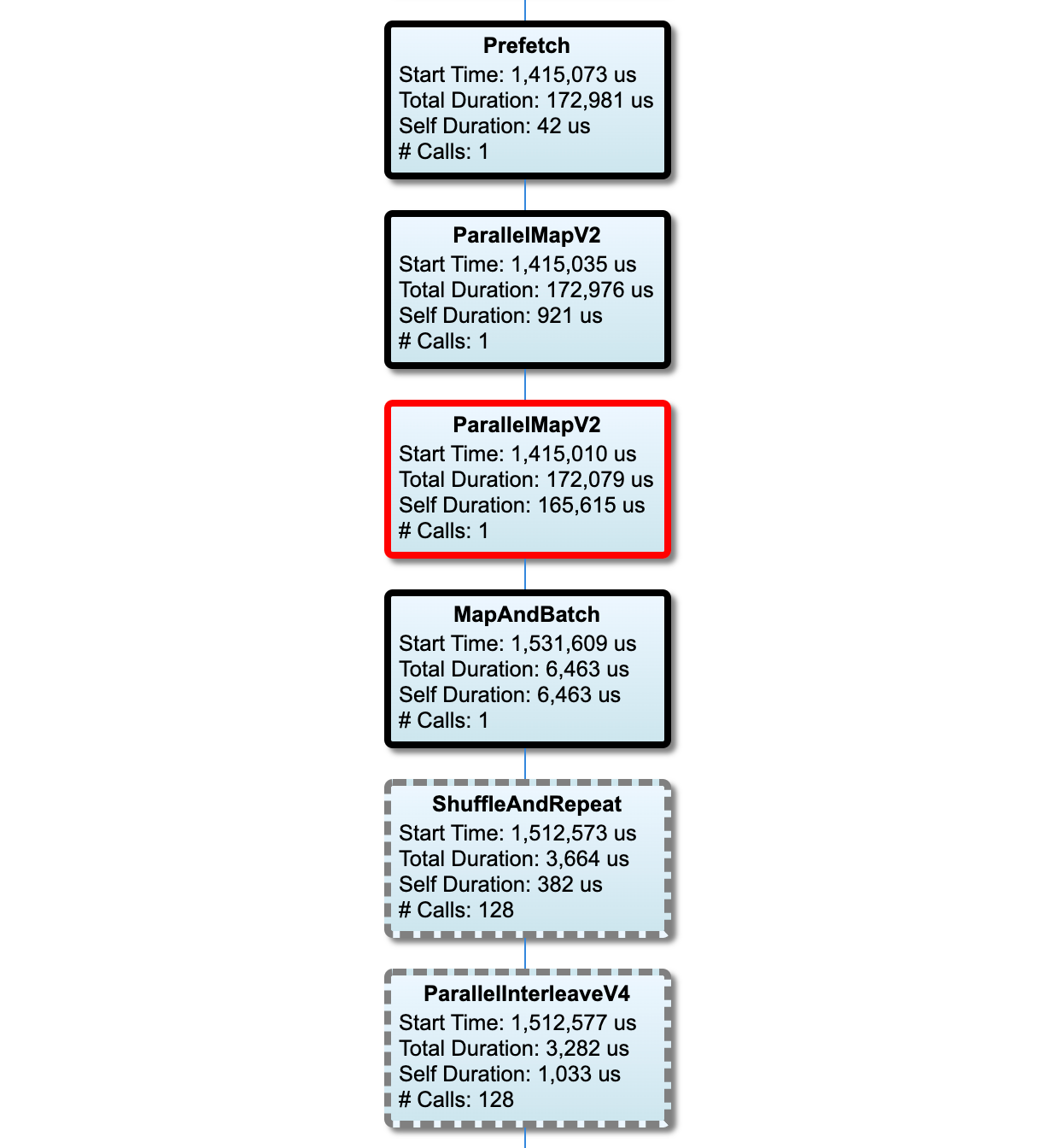
Các nút trên đường tới hạn có đường viền đậm. Nút cổ chai, là nút có thời gian tồn tại lâu nhất trên đường dẫn quan trọng, có đường viền màu đỏ. Các nút không quan trọng khác có đường viền nét đứt màu xám.
Trong mỗi nút, Thời gian bắt đầu cho biết thời gian bắt đầu thực hiện. Ví dụ, cùng một nút có thể được thực thi nhiều lần nếu có một Batch op trong đường dẫn đầu vào. Nếu nó được thực thi nhiều lần thì đó là thời điểm bắt đầu thực hiện lần đầu tiên.
Tổng thời lượng là thời gian thực hiện. Nếu nó được thực thi nhiều lần thì đó là tổng số lần thực thi của tất cả các lần thực hiện.
Thời gian riêng là Tổng thời gian không có thời gian chồng chéo với các nút con trực tiếp của nó.
"# Cuộc gọi" là số lần đường dẫn đầu vào được thực thi.
Thu thập dữ liệu hiệu suất
Trình cấu hình TensorFlow thu thập các hoạt động trên máy chủ và dấu vết GPU của mô hình TensorFlow của bạn. Bạn có thể định cấu hình Trình phân tích để thu thập dữ liệu hiệu suất thông qua chế độ lập trình hoặc chế độ lấy mẫu.
API hồ sơ
Bạn có thể sử dụng các API sau để thực hiện lập hồ sơ.
Chế độ lập trình sử dụng TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])Chế độ lập trình sử dụng API chức năng
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()Chế độ lập trình sử dụng trình quản lý bối cảnh
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Chế độ lấy mẫu: Thực hiện lập hồ sơ theo yêu cầu bằng cách sử dụng
tf.profiler.experimental.server.startđể khởi động máy chủ gRPC với mô hình TensorFlow của bạn. Sau khi khởi động máy chủ gRPC và chạy mô hình của mình, bạn có thể chụp hồ sơ thông qua nút Chụp hồ sơ trong plugin hồ sơ TensorBoard. Sử dụng tập lệnh trong phần Cài đặt hồ sơ ở trên để khởi chạy phiên bản TensorBoard nếu nó chưa chạy.Như một ví dụ,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Một ví dụ về lập hồ sơ nhiều công nhân:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
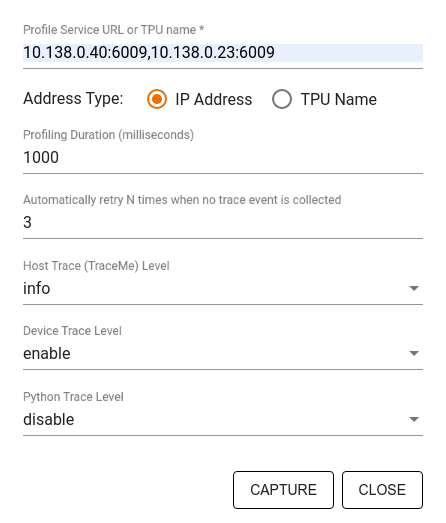
Sử dụng hộp thoại Capture Profile để chỉ định:
- Danh sách URL dịch vụ hồ sơ hoặc tên TPU được phân cách bằng dấu phẩy.
- Một khoảng thời gian hồ sơ.
- Cấp độ theo dõi cuộc gọi của thiết bị, máy chủ và hàm Python.
- Bạn muốn Trình hồ sơ thử lại việc chụp hồ sơ bao nhiêu lần nếu lần đầu không thành công.
Lập hồ sơ các vòng đào tạo tùy chỉnh
Để lập hồ sơ các vòng đào tạo tùy chỉnh trong mã TensorFlow của bạn, hãy trang bị vòng lặp đào tạo bằng API tf.profiler.experimental.Trace để đánh dấu ranh giới bước cho Profiler.
Đối số name được sử dụng làm tiền tố cho tên bước, đối số từ khóa step_num được thêm vào tên bước và đối số từ khóa _r làm cho sự kiện theo dõi này được Trình phân tích hồ sơ xử lý như một sự kiện bước.
Như một ví dụ,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Điều này sẽ kích hoạt phân tích hiệu suất dựa trên bước của Profiler và khiến các sự kiện bước hiển thị trong trình xem theo dõi.
Đảm bảo rằng bạn bao gồm trình lặp tập dữ liệu trong ngữ cảnh tf.profiler.experimental.Trace để phân tích chính xác quy trình đầu vào.
Đoạn mã bên dưới là một mẫu chống:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Lập hồ sơ các trường hợp sử dụng
Trình lược tả bao gồm một số trường hợp sử dụng dọc theo bốn trục khác nhau. Một số kết hợp hiện được hỗ trợ và những kết hợp khác sẽ được thêm vào trong tương lai. Một số trường hợp sử dụng là:
- Lập hồ sơ cục bộ và từ xa : Đây là hai cách phổ biến để thiết lập môi trường hồ sơ của bạn. Trong lập hồ sơ cục bộ, API hồ sơ được gọi trên cùng một máy mà mô hình của bạn đang thực thi, ví dụ: một máy trạm cục bộ có GPU. Trong lập hồ sơ từ xa, API hồ sơ được gọi trên một máy khác với nơi mô hình của bạn đang thực thi, chẳng hạn như trên Cloud TPU.
- Lập hồ sơ nhiều công nhân : Bạn có thể lập hồ sơ cho nhiều máy khi sử dụng khả năng đào tạo phân tán của TensorFlow.
- Nền tảng phần cứng : Cấu hình CPU, GPU và TPU.
Bảng bên dưới cung cấp thông tin tổng quan nhanh về các trường hợp sử dụng được TensorFlow hỗ trợ đã đề cập ở trên:
| API hồ sơ | Địa phương | Xa | Nhiều công nhân | Nền tảng phần cứng |
|---|---|---|---|---|
| Gọi lại TensorBoard Keras | Được hỗ trợ | Không được hỗ trợ | Không được hỗ trợ | CPU, GPU |
API bắt đầu/dừng tf.profiler.experimental | Được hỗ trợ | Không được hỗ trợ | Không được hỗ trợ | CPU, GPU |
API tf.profiler.experimental client.trace | Được hỗ trợ | Được hỗ trợ | Được hỗ trợ | CPU, GPU, TPU |
| API quản lý bối cảnh | Được hỗ trợ | Không được hỗ trợ | Không được hỗ trợ | CPU, GPU |
Các phương pháp hay nhất để có hiệu suất mô hình tối ưu
Sử dụng các đề xuất sau nếu có thể áp dụng cho mô hình TensorFlow của bạn để đạt được hiệu suất tối ưu.
Nói chung, hãy thực hiện tất cả các chuyển đổi trên thiết bị và đảm bảo rằng bạn sử dụng phiên bản thư viện tương thích mới nhất như cuDNN và Intel MKL cho nền tảng của mình.
Tối ưu hóa đường dẫn dữ liệu đầu vào
Sử dụng dữ liệu từ [#input_pipeline_analyzer] để tối ưu hóa quy trình đầu vào dữ liệu của bạn. Đường dẫn đầu vào dữ liệu hiệu quả có thể cải thiện đáng kể tốc độ thực thi mô hình của bạn bằng cách giảm thời gian rảnh của thiết bị. Hãy thử kết hợp các phương pháp hay nhất được nêu chi tiết trong phần Hiệu suất tốt hơn với hướng dẫn API tf.data và bên dưới để làm cho quy trình nhập dữ liệu của bạn hiệu quả hơn.
Nhìn chung, việc song song hóa bất kỳ hoạt động nào không cần thực hiện tuần tự có thể tối ưu hóa đáng kể đường dẫn dữ liệu đầu vào.
Trong nhiều trường hợp, việc thay đổi thứ tự của một số lệnh gọi hoặc điều chỉnh các đối số sao cho phù hợp nhất với mô hình của bạn sẽ giúp ích. Trong khi tối ưu hóa đường dẫn dữ liệu đầu vào, chỉ đánh giá trình tải dữ liệu mà không có các bước đào tạo và truyền ngược để định lượng độc lập tác động của việc tối ưu hóa.
Hãy thử chạy mô hình của bạn với dữ liệu tổng hợp để kiểm tra xem đường dẫn đầu vào có phải là nút thắt cổ chai về hiệu suất hay không.
Sử dụng
tf.data.Dataset.shardđể đào tạo đa GPU. Đảm bảo bạn phân đoạn từ rất sớm trong vòng lặp đầu vào để tránh giảm thông lượng. Khi làm việc với TFRecords, hãy đảm bảo bạn chia nhỏ danh sách TFRecords chứ không phải nội dung của TFRecords.Song song hóa một số hoạt động bằng cách tự động đặt giá trị của
num_parallel_callsbằng cách sử dụngtf.data.AUTOTUNE.Hãy cân nhắc việc hạn chế sử dụng
tf.data.Dataset.from_generatorvì nó chậm hơn so với các hoạt động TensorFlow thuần túy.Hãy cân nhắc việc hạn chế sử dụng
tf.py_functionvì nó không thể được tuần tự hóa và không được hỗ trợ để chạy trong TensorFlow phân tán.Sử dụng
tf.data.Optionsđể kiểm soát tối ưu hóa tĩnh cho đường dẫn đầu vào.
Đồng thời đọc hướng dẫn phân tích hiệu suất tf.data để được hướng dẫn thêm về cách tối ưu hóa quy trình đầu vào của bạn.
Tối ưu hóa tăng cường dữ liệu
Khi làm việc với dữ liệu hình ảnh, hãy làm cho việc tăng cường dữ liệu của bạn hiệu quả hơn bằng cách chuyển sang các loại dữ liệu khác nhau sau khi áp dụng các phép biến đổi không gian, chẳng hạn như lật, cắt, xoay, v.v.
Sử dụng NVIDIA® DALI
Trong một số trường hợp, chẳng hạn như khi bạn có hệ thống có tỷ lệ GPU trên CPU cao, tất cả các tối ưu hóa ở trên có thể không đủ để loại bỏ tắc nghẽn trong bộ tải dữ liệu gây ra do giới hạn của chu kỳ CPU.
Nếu bạn đang sử dụng GPU NVIDIA® cho các ứng dụng deep learning âm thanh và thị giác máy tính, hãy cân nhắc sử dụng Thư viện tải dữ liệu ( DALI ) để tăng tốc đường dẫn dữ liệu.
Kiểm tra tài liệu NVIDIA® DALI: Hoạt động để biết danh sách các hoạt động DALI được hỗ trợ.
Sử dụng luồng và thực thi song song
Chạy các hoạt động trên nhiều luồng CPU bằng API tf.config.threading để thực thi chúng nhanh hơn.
TensorFlow tự động đặt số lượng luồng song song theo mặc định. Nhóm luồng có sẵn để chạy các hoạt động TensorFlow phụ thuộc vào số lượng luồng CPU có sẵn.
Kiểm soát tốc độ tăng tốc song song tối đa cho một op bằng cách sử dụng tf.config.threading.set_intra_op_parallelism_threads . Lưu ý rằng nếu bạn chạy song song nhiều hoạt động, tất cả chúng sẽ chia sẻ nhóm luồng có sẵn.
Nếu bạn có các hoạt động không chặn độc lập (các hoạt động không có đường dẫn trực tiếp giữa chúng trên biểu đồ), hãy sử dụng tf.config.threading.set_inter_op_parallelism_threads để chạy chúng đồng thời bằng cách sử dụng nhóm luồng có sẵn.
Linh tinh
Khi làm việc với các mô hình nhỏ hơn trên GPU NVIDIA®, bạn có thể đặt tf.compat.v1.ConfigProto.force_gpu_compatible=True để buộc tất cả các bộ căng CPU được phân bổ bằng bộ nhớ được ghim CUDA nhằm tăng đáng kể hiệu suất của mô hình. Tuy nhiên, hãy thận trọng khi sử dụng tùy chọn này cho các kiểu máy không xác định/rất lớn vì điều này có thể tác động tiêu cực đến hiệu suất của máy chủ (CPU).
Cải thiện hiệu suất thiết bị
Hãy làm theo các phương pháp hay nhất được nêu chi tiết tại đây và trong hướng dẫn tối ưu hóa hiệu suất GPU để tối ưu hóa hiệu suất mô hình TensorFlow trên thiết bị.
Nếu bạn đang sử dụng GPU NVIDIA, hãy ghi lại mức sử dụng GPU và bộ nhớ vào tệp CSV bằng cách chạy:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Định cấu hình bố cục dữ liệu
Khi làm việc với dữ liệu chứa thông tin kênh (như hình ảnh), hãy tối ưu hóa định dạng bố cục dữ liệu để ưu tiên các kênh cuối cùng (NHWC hơn NCHW).
Các định dạng dữ liệu cuối cùng của kênh cải thiện việc sử dụng Tensor Core và mang lại những cải tiến hiệu suất đáng kể, đặc biệt là trong các mô hình tích chập khi kết hợp với AMP. Bố cục dữ liệu NCHW vẫn có thể được vận hành bởi Tensor Cores, nhưng gây ra thêm chi phí do các hoạt động chuyển đổi tự động.
Bạn có thể tối ưu hóa bố cục dữ liệu để thích bố cục NHWC hơn bằng cách đặt data_format="channels_last" cho các lớp như tf.keras.layers.Conv2D , tf.keras.layers.Conv3D và tf.keras.layers.RandomRotation .
Sử dụng tf.keras.backend.set_image_data_format để đặt định dạng bố cục dữ liệu mặc định cho API phụ trợ Keras.
Tối đa hóa bộ đệm L2
Khi làm việc với GPU NVIDIA®, hãy thực thi đoạn mã bên dưới trước vòng lặp đào tạo để tăng tối đa độ chi tiết tìm nạp L2 lên 128 byte.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
Định cấu hình sử dụng luồng GPU
Chế độ luồng GPU quyết định cách sử dụng các luồng GPU.
Đặt chế độ luồng thành gpu_private để đảm bảo rằng quá trình xử lý trước không lấy cắp tất cả các luồng GPU. Điều này sẽ làm giảm độ trễ khởi chạy kernel trong quá trình đào tạo. Bạn cũng có thể đặt số lượng luồng trên mỗi GPU. Đặt các giá trị này bằng các biến môi trường.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
Định cấu hình các tùy chọn bộ nhớ GPU
Nói chung, tăng kích thước lô và mở rộng mô hình để sử dụng GPU tốt hơn và có được thông lượng cao hơn. Lưu ý rằng việc tăng kích thước lô sẽ thay đổi độ chính xác của mô hình, do đó, mô hình cần được thu nhỏ bằng cách điều chỉnh các siêu âm như tốc độ học tập để đáp ứng độ chính xác của mục tiêu.
Ngoài ra, sử dụng tf.config.experimental.set_memory_growth để cho phép bộ nhớ GPU phát triển để ngăn tất cả bộ nhớ có sẵn được phân bổ đầy đủ cho OP chỉ yêu cầu một phần của bộ nhớ. Điều này cho phép các quy trình khác tiêu thụ bộ nhớ GPU chạy trên cùng một thiết bị.
Để tìm hiểu thêm, hãy xem hướng dẫn tăng trưởng bộ nhớ GPU giới hạn trong Hướng dẫn GPU để tìm hiểu thêm.
Linh tinh
Tăng kích thước lô đào tạo (số lượng mẫu đào tạo được sử dụng cho mỗi thiết bị trong một lần lặp của vòng đào tạo) với số lượng tối đa phù hợp mà không có lỗi bộ nhớ (OOM) trên GPU. Tăng kích thước lô ảnh hưởng đến độ chính xác của mô hình, vì vậy hãy đảm bảo bạn mở rộng mô hình bằng cách điều chỉnh các siêu âm để đáp ứng độ chính xác của mục tiêu.
Vô hiệu hóa báo cáo lỗi OOM trong quá trình phân bổ tenxơ trong mã sản xuất. Đặt
report_tensor_allocations_upon_oom=Falseintf.compat.v1.RunOptions.Đối với các mô hình có các lớp tích chập, hãy xóa bổ sung thiên vị nếu sử dụng bình thường hóa hàng loạt. Chuẩn hóa lô dịch chuyển các giá trị theo giá trị trung bình của chúng và điều này loại bỏ sự cần thiết phải có một thuật ngữ sai lệch không đổi.
Sử dụng các số liệu thống kê TF để tìm hiểu mức độ hiệu quả của các ops trên thiết bị chạy.
Sử dụng
tf.functionđể thực hiện các tính toán và tùy chọn, bậtjit_compile=Truecờ (tf.function(jit_compile=True). Để tìm hiểu thêm, hãy sử dụng xla tf.function .Giảm thiểu các hoạt động python máy chủ giữa các bước và giảm các cuộc gọi lại. Tính toán số liệu cứ sau vài bước thay vì ở mỗi bước.
Giữ cho thiết bị tính toán các đơn vị bận rộn.
Gửi dữ liệu đến nhiều thiết bị song song.
Xem xét sử dụng các biểu diễn số 16 bit , chẳng hạn như định dạng điểm nổi nửa độ chính xác của
fp16được chỉ định bởi định dạng BFLOAT16 điểm nổi của IEEE hoặc não.
Tài nguyên bổ sung
- Tenorflow Profiler: Hướng dẫn hiệu suất mô hình hồ sơ với Keras và Tensorboard nơi bạn có thể áp dụng lời khuyên trong hướng dẫn này.
- Hiệu suất hồ sơ trong Tensorflow 2 Talk từ Hội nghị thượng đỉnh Tensorflow Dev 2020.
- Bản demo hồ sơ Tensorflow từ Hội nghị thượng đỉnh Tensorflow Dev 2020.
Những hạn chế đã biết
Hồ sơ nhiều GPU trên Tensorflow 2.2 và TensorFlow 2.3
Tensorflow 2.2 và 2.3 chỉ hỗ trợ nhiều hồ sơ GPU cho các hệ thống máy chủ đơn; Nhiều hồ sơ GPU cho các hệ thống nhiều máy chủ không được hỗ trợ. Để cấu hình cấu hình GPU nhiều công nhân, mỗi công nhân phải được định cấu hình độc lập. Từ TensorFlow 2.4 Nhiều công nhân có thể được định cấu hình bằng cách sử dụng API tf.profiler.experimental.client.trace .
Cuda® Bộ công cụ 10.2 trở lên được yêu cầu để lập cấu hình nhiều GPU. Vì TensorFlow 2.2 và 2.3 Hỗ trợ các phiên bản bộ công cụ Cuda® chỉ lên tới 10.1, bạn cần tạo các liên kết tượng trưng đến libcudart.so.10.1 và libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1