
| | |  در GitHub مشاهده کنید در GitHub مشاهده کنید | |
این COLAB نمایشی از استفاده است Tensorflow توپی برای طبقه بندی متن در غیر انگلیسی / زبان های محلی. در اینجا ما را انتخاب بنگلادش به عنوان زبان محلی و استفاده از pretrained درونه گیریها کلمه برای حل یک کار طبقه بندی multiclass که در آن ما در 5 دسته طبقه بندی اخبار مقالات بنگلادش. درونه گیریها pretrained برای بنگلادش از fastText است که یک کتابخانه توسط فیس بوک با بردار کلمه pretrained منتشر شده برای 157 زبان.
ما صادر تعبیه pretrained TF-توپی برای تبدیل درونه گیریها کلمه به یک ماژول متن تعبیه اول استفاده کنید و سپس با استفاده از ماژول برای آموزش یک طبقه بندی با tf.keras ، سطح بالا کاربران API دوستانه Tensorflow برای ساخت مدل های یادگیری عمیق. حتی اگر در اینجا از جاسازیهای fastText استفاده میکنیم، میتوان هر جاسازی دیگر را که از پیش آموزش داده شدهاند از وظایف دیگر صادر کرد و به سرعت با هاب Tensorflow به نتیجه رسید.
برپایی
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
مجموعه داده
ما استفاده خواهد کرد BARD اقتصاد، دولت، بین المللی، ورزش و سرگرمی: (بنگلادش مقاله مجموعه داده) که در حدود 376226 مقالات جمع آوری شده از پورتال های مختلف خبری بنگلادش و نشاندار شده با 5 دسته. ما فایل از Google Drive این (دانلود bit.ly/BARD_DATASET ) لینک است با اشاره به از این مخزن گیتهاب.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
بردارهای کلمه از پیش آموزش دیده را به ماژول TF-Hub صادر کنید
TF-توپی برای تبدیل درونه گیریها کلمه به TF-هاب ماژول تعبیه متن فراهم می کند برخی از اسکریپت های مفید در اینجا . برای اینکه ماژول برای بنگلادش و یا هر زبان دیگر، ما به سادگی باید برای دانلود کلمه تعبیه .txt و یا .vec فایل را به دایرکتوری همان export_v2.py و اجرای اسکریپت.
صادر کننده خواند بردار تعبیه و صادرات آن به یک Tensorflow SavedModel . SavedModel شامل یک برنامه کامل TensorFlow شامل وزن و نمودار است. TF-توپی می توانید SavedModel به عنوان یک بار ماژول ، که ما استفاده خواهد کرد برای ساخت مدل برای طبقه بندی متن. از آنجا که ما با استفاده از tf.keras برای ایجاد مدل، ما استفاده از hub.KerasLayer ، فراهم می کند که یک wrapper برای یک ماژول TF-توپی برای استفاده به عنوان یک لایه Keras.
اول ما در درونه گیریها به حرف ما از fastText و تعبیه صادر کننده از TF-توپی از مخزن .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
سپس، اسکریپت صادرکننده را در فایل جاسازی خود اجرا می کنیم. از آنجایی که جاسازیهای fastText یک خط سرصفحه دارند و بسیار بزرگ هستند (حدود 3.3 گیگابایت برای Bangla پس از تبدیل به یک ماژول)، ما خط اول را نادیده میگیریم و تنها 100000 نشانه اول را به ماژول جاسازی متن صادر میکنیم.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
ماژول جاسازی متن دسته ای از جملات را در یک تانسور رشته های 1 بعدی به عنوان ورودی می گیرد و بردارهای جاسازی شکل (batch_size، embedding_dim) مربوط به جملات را خروجی می کند. این ورودی را با تقسیم بر روی فضاها پیش پردازش می کند. درونه گیریها ورد به درونه گیریها جمله با ترکیب sqrtn ترکیب (نگاه کنید به اینجا ). برای نمایش، فهرستی از کلمات Bangla را به عنوان ورودی ارسال می کنیم و بردارهای جاسازی مربوطه را دریافت می کنیم.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
به مجموعه داده Tensorflow تبدیل کنید
از آنجا که مجموعه داده های واقعا بزرگ به جای بارگذاری کل مجموعه داده در حافظه است که ما یک ژنراتور به عملکرد نمونه ها در زمان اجرا در دسته با استفاده از استفاده از Tensorflow مجموعه داده توابع. مجموعه داده نیز بسیار نامتعادل است، بنابراین، قبل از استفاده از ژنراتور، مجموعه داده را به هم می زنیم.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
ما میتوانیم توزیع برچسبها را در نمونههای آموزشی و اعتبارسنجی پس از زدن بررسی کنیم.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
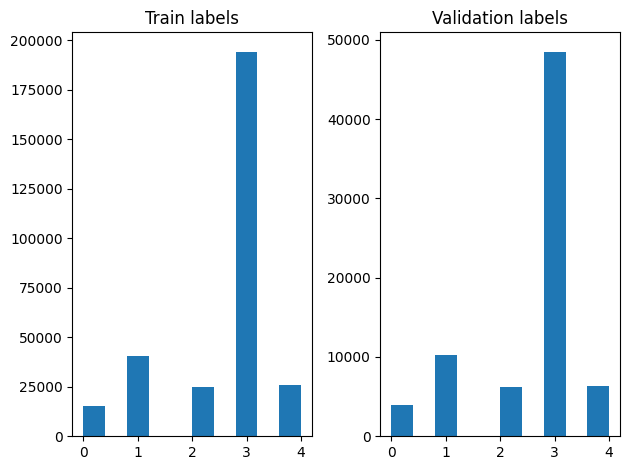
برای ایجاد یک مجموعه داده با استفاده از یک ژنراتور، ما برای اولین بار نوشتن یک تابع ژنراتور که بار خوانده شده هر یک از مقالات از file_paths و برچسب از آرایه برچسب، و بازده به عنوان مثال یکی از آموزش در هر مرحله. ما این تابع مولد به تصویب tf.data.Dataset.from_generator روش و تعیین نوع خروجی. هر مثال آموزشی یک تاپل حاوی یک مقاله از است tf.string نوع داده ها و برچسب های کد گذاری یک گرم است. ما در مجموعه داده با تقسیم قطار اعتبار 80-20 با استفاده از تقسیم tf.data.Dataset.skip و tf.data.Dataset.take روش.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
آموزش و ارزیابی مدل
از آنجا که ما در حال حاضر یک پوشش در اطراف ماژول ما به استفاده از آن به عنوان هر لایه دیگر در Keras اضافه شده است، ما می توانیم یک کوچک ایجاد متوالی مدل است که یک پشته خطی از لایه ها. ما می توانیم متن تعبیه ماژول با اضافه model.add درست مانند هر لایه دیگر. ما مدل را با تعیین ضرر و بهینه ساز جمع آوری می کنیم و آن را برای 10 دوره آموزش می دهیم. tf.keras API می توانید Tensorflow مجموعه داده به عنوان ورودی را اداره کند، بنابراین ما می توانیم یک نمونه مجموعه داده به روش مناسب برای آموزش مدل منتقل می کند. از آنجا که ما با استفاده از تابع ژنراتور، tf.data رسیدگی خواهد شد تولید نمونه، جداجدا سفارش داده شده آنها و تغذیه آنها به مدل.
مدل
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
آموزش
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
ارزیابی
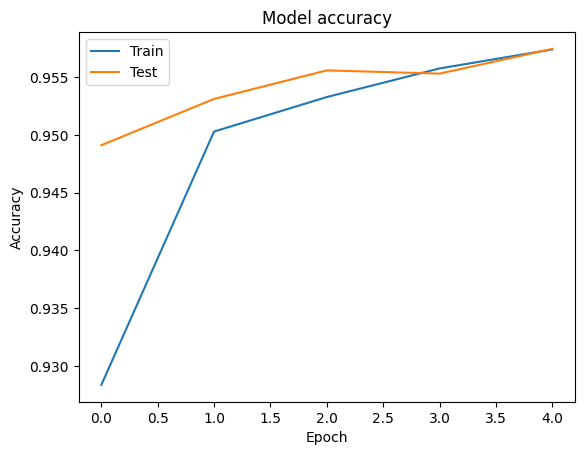
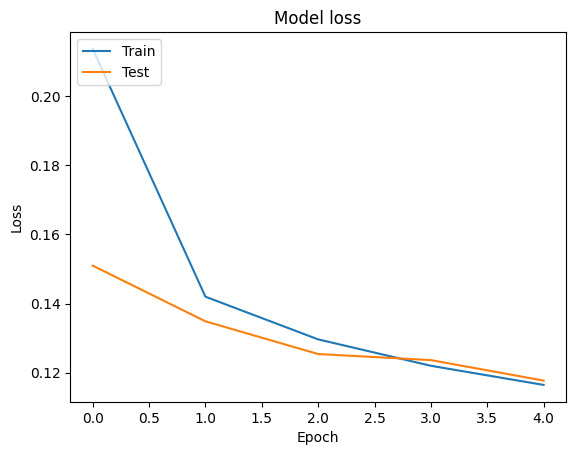
ما می توانیم دقت و از دست دادن منحنی برای داده های آموزشی و اعتبار با استفاده از تجسم tf.keras.callbacks.History شی بازگردانده شده توسط tf.keras.Model.fit روش، که شامل از دست دادن ارزش و دقت برای هر دوره.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
پیش بینی
میتوانیم پیشبینیهای دادههای اعتبارسنجی را دریافت کنیم و ماتریس سردرگمی را بررسی کنیم تا عملکرد مدل را برای هر یک از 5 کلاس ببینیم. از آنجا tf.keras.Model.predict روش یک آرایه دوم برای احتمال ها برای هر کلاس را برمی گرداند، آنها را می توان به برچسب کلاس با استفاده از تبدیل np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
مقایسه عملکرد
در حال حاضر ما می توانید برچسب های صحیح برای داده ها اعتبار از را labels و مقایسه آنها با پیش بینی های ما به دست آوردن یک classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
ما همچنین می توانیم عملکرد مدل ما با نتایج منتشر شده به دست آمده در اصل مقایسه مقاله ، که به حال 0.96 دقت .این نویسندگان اصلی توصیف بسیاری از مراحل قبل از پردازش در مجموعه داده انجام، از قبیل انداختن علائم نشانهگذاری و ارقام، از بین بردن 25 ترین frequest کلمات توقف. همانطور که ما می تواند در دیدن classification_report ، ما نیز مدیریت برای به دست آوردن 0.96 دقت و صحت بعد از آموزش تنها 5 دوره بدون هیچ پیش پردازش.
در این مثال، زمانی که ما لایه Keras از ماژول تعبیه ما ایجاد شده، ما تنظیم پارامتر trainable=False ، که به معنی وزن تعبیه خواهد در طول آموزش به روز نمی شود. سعی کنید آن را به True برای رسیدن به حدود 97٪ دقت با استفاده از این مجموعه داده پس از تنها 2 دوره.