
TensorFlow Data Validation (TFDV) สามารถวิเคราะห์การฝึกอบรมและการให้บริการข้อมูลเพื่อ:
คำนวณ สถิติ เชิงพรรณนา
อนุมานส คีมา
ตรวจจับ ความผิดปกติของข้อมูล
API หลักรองรับฟังก์ชันการทำงานแต่ละส่วน ด้วยวิธีการที่สะดวกสบายซึ่งสร้างขึ้นจากด้านบนและสามารถเรียกได้ในบริบทของโน้ตบุ๊ก
การคำนวณสถิติข้อมูลเชิงพรรณนา
TFDV สามารถคำนวณ สถิติ เชิงพรรณนาที่ให้ภาพรวมโดยย่อของข้อมูลในแง่ของคุณสมบัติที่มีอยู่และรูปร่างของการกระจายมูลค่า เครื่องมือต่างๆ เช่น ภาพรวมแง่มุม สามารถให้การแสดงภาพสถิติเหล่านี้โดยย่อเพื่อการเรียกดูที่ง่ายดาย
ตัวอย่างเช่น สมมติว่า path นั้นชี้ไปยังไฟล์ในรูปแบบ TFRecord (ซึ่งเก็บบันทึกประเภท tensorflow.Example ) ตัวอย่างต่อไปนี้แสดงการคำนวณสถิติโดยใช้ TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
ค่าที่ส่งคืนคือบัฟเฟอร์โปรโตคอล DatasetFeatureStatisticsList สมุดบันทึกตัวอย่าง มีการแสดงภาพสถิติโดยใช้ Facets Overall :
tfdv.visualize_statistics(stats)
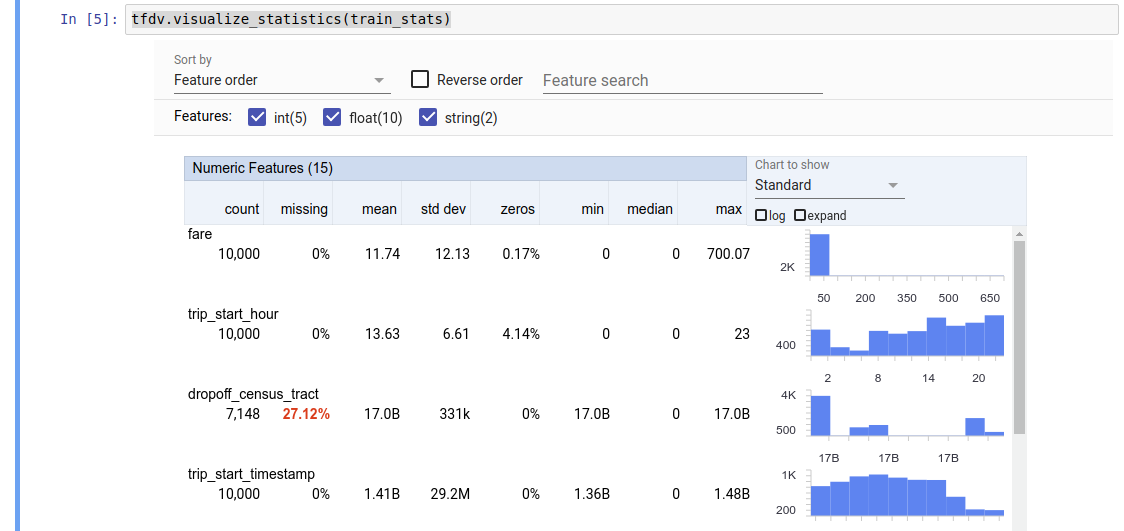
ตัวอย่างก่อนหน้านี้ถือว่าข้อมูลถูกเก็บไว้ในไฟล์ TFRecord TFDV ยังรองรับรูปแบบอินพุต CSV ด้วยความสามารถในการขยายสำหรับรูปแบบทั่วไปอื่นๆ คุณสามารถค้นหาตัวถอดรหัสข้อมูลที่มีอยู่ได้ ที่นี่ นอกจากนี้ TFDV ยังมีฟังก์ชันยูทิลิตี้ tfdv.generate_statistics_from_dataframe สำหรับผู้ใช้ที่มีข้อมูลในหน่วยความจำแสดงเป็น Pandas DataFrame
นอกเหนือจากการคำนวณชุดสถิติข้อมูลเริ่มต้นแล้ว TFDV ยังสามารถคำนวณสถิติสำหรับโดเมนความหมาย (เช่น รูปภาพ ข้อความ) หากต้องการเปิดใช้งานการคำนวณสถิติโดเมนเชิงความหมาย ให้ส่งอ็อบเจ็กต์ tfdv.StatsOptions โดยที่ enable_semantic_domain_stats ตั้งค่าเป็น True เป็น tfdv.generate_statistics_from_tfrecord
ทำงานบน Google Cloud
ภายใน TFDV ใช้เฟรมเวิร์กการประมวลผลข้อมูลแบบขนานของ Apache Beam เพื่อปรับขนาดการคำนวณสถิติบนชุดข้อมูลขนาดใหญ่ สำหรับแอปพลิเคชันที่ต้องการผสานรวมกับ TFDV ให้ลึกยิ่งขึ้น (เช่น สร้างสถิติที่ส่วนท้ายของไปป์ไลน์การสร้างข้อมูล สร้างสถิติสำหรับข้อมูลในรูปแบบที่กำหนดเอง ) API ยังเปิดเผย Beam PTransform สำหรับการสร้างสถิติอีกด้วย
หากต้องการเรียกใช้ TFDV บน Google Cloud ต้องดาวน์โหลดไฟล์วงล้อ TFDV และมอบให้กับผู้ปฏิบัติงาน Dataflow ดาวน์โหลดไฟล์ wheel ไปยังไดเร็กทอรีปัจจุบันดังนี้:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
ตัวอย่างต่อไปนี้แสดงตัวอย่างการใช้งาน TFDV บน Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
ในกรณีนี้ สถิติต้นแบบที่สร้างขึ้นจะถูกจัดเก็บไว้ในไฟล์ TFRecord ที่เขียนลงใน GCS_STATS_OUTPUT_PATH
หมายเหตุ เมื่อเรียกใช้ฟังก์ชัน tfdv.generate_statistics_... ใดๆ (เช่น tfdv.generate_statistics_from_tfrecord ) บน Google Cloud คุณต้องระบุ output_path การระบุไม่มีอาจทำให้เกิดข้อผิดพลาด
การอนุมานสคีมาเหนือข้อมูล
สคีมา จะอธิบายคุณสมบัติที่คาดหวังของข้อมูล คุณสมบัติบางส่วนเหล่านี้คือ:
- คุณสมบัติใดบ้างที่คาดว่าจะมี
- ประเภทของพวกเขา
- จำนวนค่าสำหรับคุณลักษณะในแต่ละตัวอย่าง
- การมีอยู่ของแต่ละคุณลักษณะในตัวอย่างทั้งหมด
- โดเมนคุณสมบัติที่คาดหวัง
กล่าวโดยสรุป สคีมาจะอธิบายความคาดหวังสำหรับข้อมูลที่ "ถูกต้อง" และสามารถใช้เพื่อตรวจจับข้อผิดพลาดในข้อมูลได้ (อธิบายไว้ด้านล่าง) นอกจากนี้ สคีมาเดียวกันนี้ยังสามารถใช้เพื่อตั้งค่า TensorFlow Transform สำหรับการแปลงข้อมูลได้อีกด้วย โปรดทราบว่าสคีมานั้นคาดว่าจะค่อนข้างคงที่ เช่น ชุดข้อมูลหลายชุดสามารถเป็นไปตามสคีมาเดียวกัน ในขณะที่สถิติ (อธิบายไว้ข้างต้น) อาจแตกต่างกันไปในแต่ละชุดข้อมูล
เนื่องจากการเขียนสคีมาอาจเป็นงานที่น่าเบื่อ โดยเฉพาะอย่างยิ่งสำหรับชุดข้อมูลที่มีคุณสมบัติมากมาย TFDV จึงมีวิธีการสร้างสคีมาเวอร์ชันเริ่มต้นตามสถิติเชิงพรรณนา:
schema = tfdv.infer_schema(stats)
โดยทั่วไป TFDV จะใช้การวิเคราะห์พฤติกรรมแบบอนุรักษ์นิยมเพื่ออนุมานคุณสมบัติของข้อมูลที่เสถียรจากสถิติ เพื่อหลีกเลี่ยงการปรับสคีมามากเกินไปกับชุดข้อมูลเฉพาะ ขอแนะนำอย่างยิ่งให้ ตรวจสอบสคีมาที่อนุมานและปรับปรุงตามความจำเป็น เพื่อรวบรวมความรู้โดเมนเกี่ยวกับข้อมูลที่การวิเคราะห์พฤติกรรมของ TFDV อาจพลาดไป
ตามค่าเริ่มต้น tfdv.infer_schema จะอนุมานรูปร่างของคุณลักษณะที่ต้องการแต่ละรายการ หาก value_count.min เท่ากับ value_count.max สำหรับคุณลักษณะดังกล่าว ตั้งค่าอาร์กิวเมนต์ infer_feature_shape เป็น False เพื่อปิดใช้งานการอนุมานรูปร่าง
สคีมานั้นถูกจัดเก็บเป็น บัฟเฟอร์โปรโตคอลสคีมา และสามารถอัปเดต/แก้ไขได้โดยใช้ API บัฟเฟอร์โปรโตคอลมาตรฐาน TFDV ยังมี วิธีการอรรถประโยชน์บางประการ เพื่อทำให้การอัปเดตเหล่านี้ง่ายขึ้น ตัวอย่างเช่น สมมติว่าสคีมามีบทต่อไปนี้เพื่ออธิบายคุณลักษณะสตริงที่ต้องการ payment_type ที่รับค่าเดียว:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
หากต้องการทำเครื่องหมายว่าสถานที่นี้ควรมีประชากรอย่างน้อย 50% ของตัวอย่าง:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
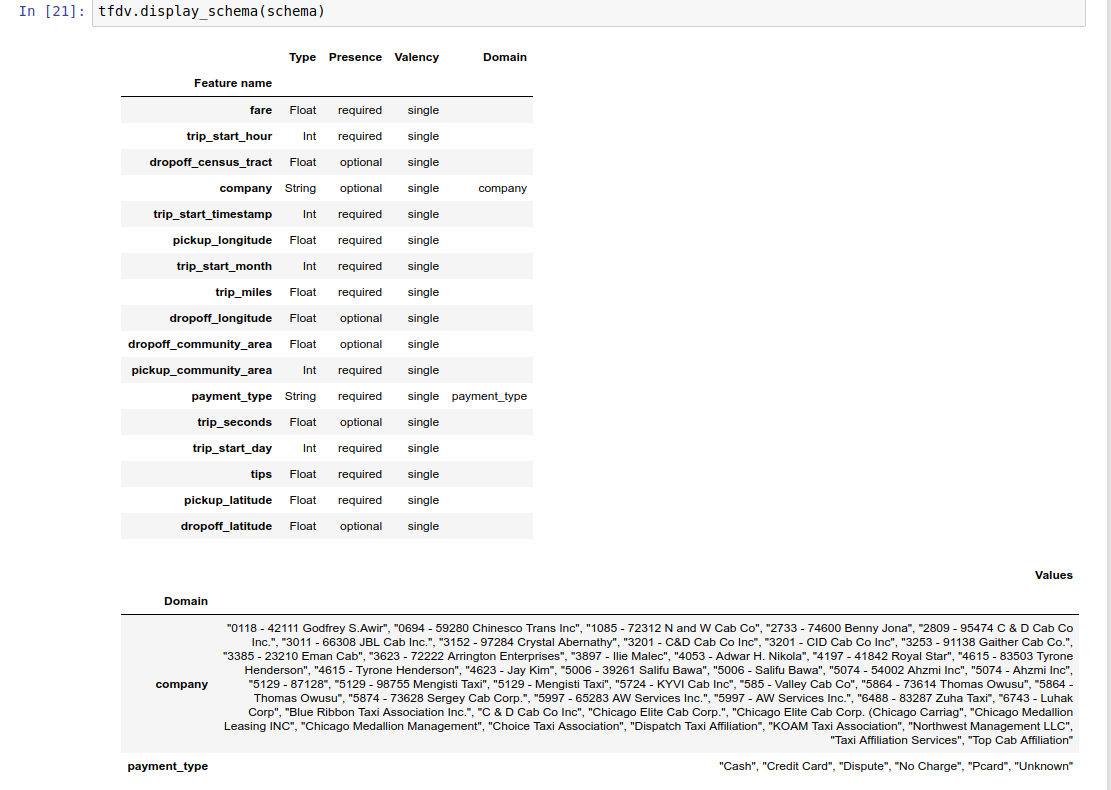
สมุดบันทึกตัวอย่าง ประกอบด้วยการแสดงภาพอย่างง่ายของสคีมาเป็นตาราง โดยแสดงรายการคุณลักษณะแต่ละรายการและคุณลักษณะหลักตามที่เข้ารหัสไว้ในสคีมา
การตรวจสอบข้อมูลเพื่อหาข้อผิดพลาด
ด้วยสคีมา คุณสามารถตรวจสอบว่าชุดข้อมูลสอดคล้องกับความคาดหวังที่ตั้งไว้ในสคีมา หรือมี ข้อมูลผิดปกติ หรือไม่ คุณสามารถตรวจสอบข้อผิดพลาดของข้อมูล (ก) โดยรวมจากชุดข้อมูลทั้งหมดได้โดยการจับคู่สถิติของชุดข้อมูลกับสคีมา หรือ (ข) โดยการตรวจสอบข้อผิดพลาดตามตัวอย่างแต่ละตัวอย่าง
การจับคู่สถิติของชุดข้อมูลกับสคีมา
หากต้องการตรวจสอบข้อผิดพลาดในการรวม TFDV จะจับคู่สถิติของชุดข้อมูลกับสคีมาและทำเครื่องหมายความคลาดเคลื่อน ตัวอย่างเช่น:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
ผลลัพธ์คืออินสแตนซ์ของบัฟเฟอร์โปรโตคอล Anomalies และอธิบายข้อผิดพลาดใดๆ ที่สถิติไม่สอดคล้องกับสคีมา ตัวอย่างเช่น สมมติว่าข้อมูลที่ other_path มีตัวอย่างที่มีค่าสำหรับคุณลักษณะ payment_type นอกโดเมนที่ระบุในสคีมา
สิ่งนี้ทำให้เกิดความผิดปกติ
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
บ่งชี้ว่าพบค่านอกโดเมนในสถิติใน < 1% ของค่าฟีเจอร์
หากเป็นไปตามที่คาดไว้ คุณสามารถอัปเดตสคีมาได้ดังนี้:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
หากความผิดปกติบ่งชี้ถึงข้อผิดพลาดของข้อมูลอย่างแท้จริง ควรแก้ไขข้อมูลพื้นฐานก่อนนำไปใช้สำหรับการฝึกอบรม
ประเภทความผิดปกติต่างๆ ที่โมดูลนี้สามารถตรวจพบได้แสดง ไว้ที่นี่
สมุดบันทึกตัวอย่าง ประกอบด้วยการแสดงภาพความผิดปกติอย่างง่ายเป็นตาราง โดยแสดงรายการคุณลักษณะที่ตรวจพบข้อผิดพลาด และคำอธิบายสั้นๆ ของข้อผิดพลาดแต่ละรายการ

การตรวจสอบข้อผิดพลาดตามตัวอย่าง
TFDV ยังมีตัวเลือกในการตรวจสอบข้อมูลตามตัวอย่าง แทนที่จะเปรียบเทียบสถิติทั้งชุดข้อมูลกับสคีมา TFDV มีฟังก์ชันสำหรับตรวจสอบข้อมูลตามตัวอย่าง จากนั้นสร้างสถิติสรุปสำหรับตัวอย่างที่ผิดปกติที่พบ ตัวอย่างเช่น:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats ที่ validate_examples_in_tfrecord ส่งคืนคือบัฟเฟอร์โปรโตคอล DatasetFeatureStatisticsList ซึ่งแต่ละชุดข้อมูลประกอบด้วยชุดตัวอย่างที่แสดงความผิดปกติเฉพาะ คุณสามารถใช้สิ่งนี้เพื่อกำหนดจำนวนตัวอย่างในชุดข้อมูลของคุณที่แสดงความผิดปกติที่กำหนดและลักษณะของตัวอย่างเหล่านั้น
สภาพแวดล้อมสคีมา
ตามค่าเริ่มต้น การตรวจสอบจะถือว่าชุดข้อมูลทั้งหมดในไปป์ไลน์เป็นไปตามสคีมาเดียว ในบางกรณี จำเป็นต้องมีการเปลี่ยนแปลงสคีมาเล็กน้อย เช่น คุณลักษณะที่ใช้เป็นป้ายกำกับจำเป็นในระหว่างการฝึก (และควรได้รับการตรวจสอบความถูกต้อง) แต่ขาดหายไประหว่างการแสดงผล
สภาพแวดล้อม สามารถใช้เพื่อแสดงข้อกำหนดดังกล่าวได้ โดยเฉพาะอย่างยิ่ง คุณลักษณะในสคีมาสามารถเชื่อมโยงกับชุดของสภาพแวดล้อมโดยใช้ default_environment, in_environment และ not_in_environment
ตัวอย่างเช่น หากมีการใช้ฟีเจอร์ เคล็ดลับ เป็นป้ายกำกับในการฝึกอบรม แต่ไม่มีข้อมูลการให้บริการ หากไม่มีการระบุสภาพแวดล้อม ก็จะแสดงขึ้นเป็นความผิดปกติ
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

เพื่อแก้ไขปัญหานี้ เราจำเป็นต้องตั้งค่าสภาพแวดล้อมเริ่มต้นสำหรับคุณลักษณะทั้งหมดให้เป็นทั้ง 'การฝึกอบรม' และ 'การให้บริการ' และแยกคุณลักษณะ 'เคล็ดลับ' ออกจากสภาพแวดล้อมการให้บริการ
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
ตรวจสอบข้อมูลบิดเบือนและดริฟท์
นอกเหนือจากการตรวจสอบว่าชุดข้อมูลสอดคล้องกับความคาดหวังที่ตั้งไว้ในสคีมาแล้ว TFDV ยังมีฟังก์ชันในการตรวจจับ:
- บิดเบือนระหว่างข้อมูลการฝึกอบรมและข้อมูลการให้บริการ
- เลื่อนไปมาระหว่างวันต่างๆ ของข้อมูลการฝึกอบรม
TFDV ดำเนินการตรวจสอบนี้โดยการเปรียบเทียบสถิติของชุดข้อมูลต่างๆ โดยอิงตามตัวเปรียบเทียบการเบี่ยงเบน/การเอียงที่ระบุในสคีมา ตัวอย่างเช่น หากต้องการตรวจสอบว่าคุณลักษณะ "ประเภทการชำระเงิน" เบี่ยงเบนไปจากชุดข้อมูลการฝึกอบรมและการให้บริการหรือไม่ ให้ทำดังนี้
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
หมายเหตุ บรรทัดฐาน L-อนันต์จะตรวจจับเฉพาะการเอียงสำหรับคุณสมบัติตามหมวดหมู่เท่านั้น แทนที่จะระบุเกณฑ์ infinity_norm การระบุเกณฑ์ jensen_shannon_divergence ใน skew_comparator จะตรวจจับการเอียงสำหรับทั้งคุณลักษณะที่เป็นตัวเลขและหมวดหมู่
เช่นเดียวกับการตรวจสอบว่าชุดข้อมูลสอดคล้องกับความคาดหวังที่ตั้งไว้ในสคีมาหรือไม่ ผลลัพธ์ยังเป็นอินสแตนซ์ของบัฟเฟอร์โปรโตคอล Anomalies และอธิบายความเบี่ยงเบนระหว่างชุดข้อมูลการฝึกและการให้บริการ ตัวอย่างเช่น สมมติว่าข้อมูลการแสดงผลมีตัวอย่างมากกว่าที่มีคุณลักษณะ payement_type มีค่า Cash มากขึ้น ซึ่งทำให้เกิดความผิดปกติที่บิดเบือน
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
หากความผิดปกติบ่งชี้ถึงความเบี่ยงเบนระหว่างข้อมูลการฝึกและข้อมูลการให้บริการอย่างแท้จริง จำเป็นต้องมีการตรวจสอบเพิ่มเติม เนื่องจากอาจส่งผลโดยตรงต่อประสิทธิภาพของโมเดล
สมุดบันทึกตัวอย่าง ประกอบด้วยตัวอย่างง่ายๆ ของการตรวจสอบความผิดปกติที่มีการเอียง
การตรวจจับความคลาดเคลื่อนระหว่างวันต่างๆ ของข้อมูลการฝึกสามารถทำได้ในลักษณะเดียวกัน
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
หมายเหตุ บรรทัดฐาน L-อนันต์จะตรวจจับเฉพาะการเอียงสำหรับคุณสมบัติตามหมวดหมู่เท่านั้น แทนที่จะระบุเกณฑ์ infinity_norm การระบุเกณฑ์ jensen_shannon_divergence ใน skew_comparator จะตรวจจับการเอียงสำหรับทั้งคุณลักษณะที่เป็นตัวเลขและหมวดหมู่
กำลังเขียนตัวเชื่อมต่อข้อมูลที่กำหนดเอง
ในการคำนวณสถิติข้อมูล TFDV มี วิธีที่สะดวก หลายวิธีในการจัดการข้อมูลอินพุตในรูปแบบต่างๆ (เช่น TFRecord ของ tf.train.Example , CSV ฯลฯ) หากรูปแบบข้อมูลของคุณไม่อยู่ในรายการนี้ คุณจะต้องเขียนตัวเชื่อมต่อข้อมูลแบบกำหนดเองสำหรับการอ่านข้อมูลอินพุต และเชื่อมต่อกับ TFDV core API เพื่อคำนวณสถิติข้อมูล
API แกน TFDV สำหรับสถิติข้อมูลการประมวลผล คือ Beam PTransform ที่รับ PCollection ของชุดตัวอย่างอินพุต (ชุดตัวอย่างอินพุตจะแสดงเป็น Arrow RecordBatch) และส่งออก PCollection ที่มีบัฟเฟอร์โปรโตคอล DatasetFeatureStatisticsList เดียว
เมื่อคุณใช้ตัวเชื่อมต่อข้อมูลแบบกำหนดเองที่รวมตัวอย่างอินพุตของคุณใน Arrow RecordBatch แล้ว คุณจะต้องเชื่อมต่อกับ tfdv.GenerateStatistics API เพื่อคำนวณสถิติข้อมูล ยกตัวอย่าง TFRecord ของ tf.train.Example tfx_bsl มีตัวเชื่อมต่อข้อมูล TFExampleRecord และด้านล่างนี้คือตัวอย่างวิธีเชื่อมต่อกับ tfdv.GenerateStatistics API
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
การคำนวณสถิติบนส่วนของข้อมูล
TFDV สามารถกำหนดค่าให้คำนวณสถิติผ่านส่วนของข้อมูลได้ การแบ่งส่วนสามารถเปิดใช้งานได้โดยจัดให้มีฟังก์ชันการแบ่งส่วนซึ่งใช้ Arrow RecordBatch และส่งออกลำดับของสิ่งอันดับของฟอร์ม (slice key, record batch) TFDV มอบวิธีง่ายๆ ใน การสร้างฟังก์ชันการแบ่งส่วนตามค่าคุณลักษณะ ซึ่งสามารถจัดให้เป็นส่วนหนึ่งของ tfdv.StatsOptions เมื่อคำนวณสถิติ
เมื่อเปิดใช้งานการแบ่งส่วน เอาต์พุต DatasetFeatureStatisticsList proto จะมี DatasetFeatureStatistics protos หลายโปรโตส หนึ่งโปรโตสำหรับแต่ละสไลซ์ แต่ละชิ้นจะถูกระบุด้วยชื่อเฉพาะซึ่งตั้งเป็น ชื่อชุดข้อมูลใน DatasetFeatureStatistics proto ตามค่าเริ่มต้น TFDV จะคำนวณสถิติสำหรับชุดข้อมูลโดยรวม นอกเหนือจากส่วนที่กำหนดค่าไว้
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])