
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מדגים כיצד לעבד מראש קבצי אודיו בפורמט WAV ולבנות ולהכשיר מודל בסיסי של זיהוי דיבור אוטומטי (ASR) לזיהוי עשר מילים שונות. תשתמש בחלק ממערך הנתונים של פקודות דיבור ( Warden, 2018 ), המכיל קטעי אודיו קצרים (באורך שנייה אחת או פחות) של פקודות, כגון "למטה", "לך", "שמאלה", "לא", " נכון", "עצור", "למעלה" ו"כן".
מערכות זיהוי דיבור ואודיו בעולם האמיתי הן מורכבות. אבל, כמו סיווג תמונות עם מערך הנתונים של MNIST , מדריך זה אמור לתת לך הבנה בסיסית של הטכניקות המעורבות.
להכין
ייבוא מודולים ותלות נחוצים. שים לב שאתה תשתמש ב- seaborn להדמיה במדריך זה.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
ייבא את מערך הנתונים המיני של פקודות דיבור
כדי לחסוך זמן עם טעינת נתונים, תעבוד עם גרסה קטנה יותר של מערך הנתונים של פקודות דיבור. מערך הנתונים המקורי מורכב מיותר מ-105,000 קובצי אודיו בפורמט קובץ האודיו WAV (Waveform) של אנשים האומרים 35 מילים שונות. נתונים אלה נאספו על ידי Google ושוחררו תחת רישיון CC BY.
הורד וחלץ את הקובץ mini_speech_commands.zip המכיל את מערכי הנתונים הקטנים יותר של פקודות דיבור עם tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
קטעי האודיו של מערך הנתונים מאוחסנים בשמונה תיקיות המתאימות לכל פקודת דיבור: no , yes , down , go , left , up , right stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
חלץ את קטעי האודיו לרשימה שנקראת filenames , וערבב אותה:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
פיצול filenames לקבוצות אימון, אימות ובדיקות תוך שימוש ביחס של 80:10:10, בהתאמה:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
קרא את קובצי השמע והתוויות שלהם
בחלק זה תעבדו מראש את מערך הנתונים, ותצרו טנסורים מפוענחים עבור צורות הגל והתוויות המתאימות. ציין זאת:
- כל קובץ WAV מכיל נתונים מסדרת זמן עם מספר מוגדר של דגימות בשנייה.
- כל דגימה מייצגת את משרעת אות השמע באותו זמן ספציפי.
- במערכת של 16 סיביות , כמו קבצי ה-WAV במערך הנתונים המיני של פקודות דיבור, ערכי המשרעת נעים בין -32,768 ל-32,767.
- קצב הדגימה עבור מערך נתונים זה הוא 16kHz.
צורת הטנזור המוחזרת על ידי tf.audio.decode_wav היא [samples, channels] , כאשר channels הם 1 עבור מונו או 2 עבור סטריאו. מערך הנתונים המיני של פקודות דיבור מכיל רק הקלטות מונו.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
כעת, בואו נגדיר פונקציה שמעבדת מראש את קובצי ה-WAV הגולמיים של מערך הנתונים לטנסור אודיו:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
הגדר פונקציה שיוצרת תוויות באמצעות ספריות האב עבור כל קובץ:
- פצל את נתיבי הקבצים ל-
tf.RaggedTensors (טנסורים בעלי ממדים מרופטים - עם פרוסות שעשויות להיות בעלות אורך שונה).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
הגדר פונקציית מסייעת נוספת - get_waveform_and_label - שמחברת את הכל ביחד:
- הקלט הוא שם קובץ האודיו WAV.
- הפלט הוא טאפל המכיל את טנסור האודיו והתוויות מוכן ללמידה בפיקוח.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
בנה את ערכת ההדרכה כדי לחלץ את צמדי תוויות האודיו:
- צור
tf.data.DatasetעםDataset.from_tensor_slicesו-Dataset.map, באמצעותget_waveform_and_labelשהוגדרו קודם לכן.
אתה תבנה את ערכות האימות והבדיקה באמצעות הליך דומה בהמשך.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
בואו נשרטט כמה צורות גל שמע:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
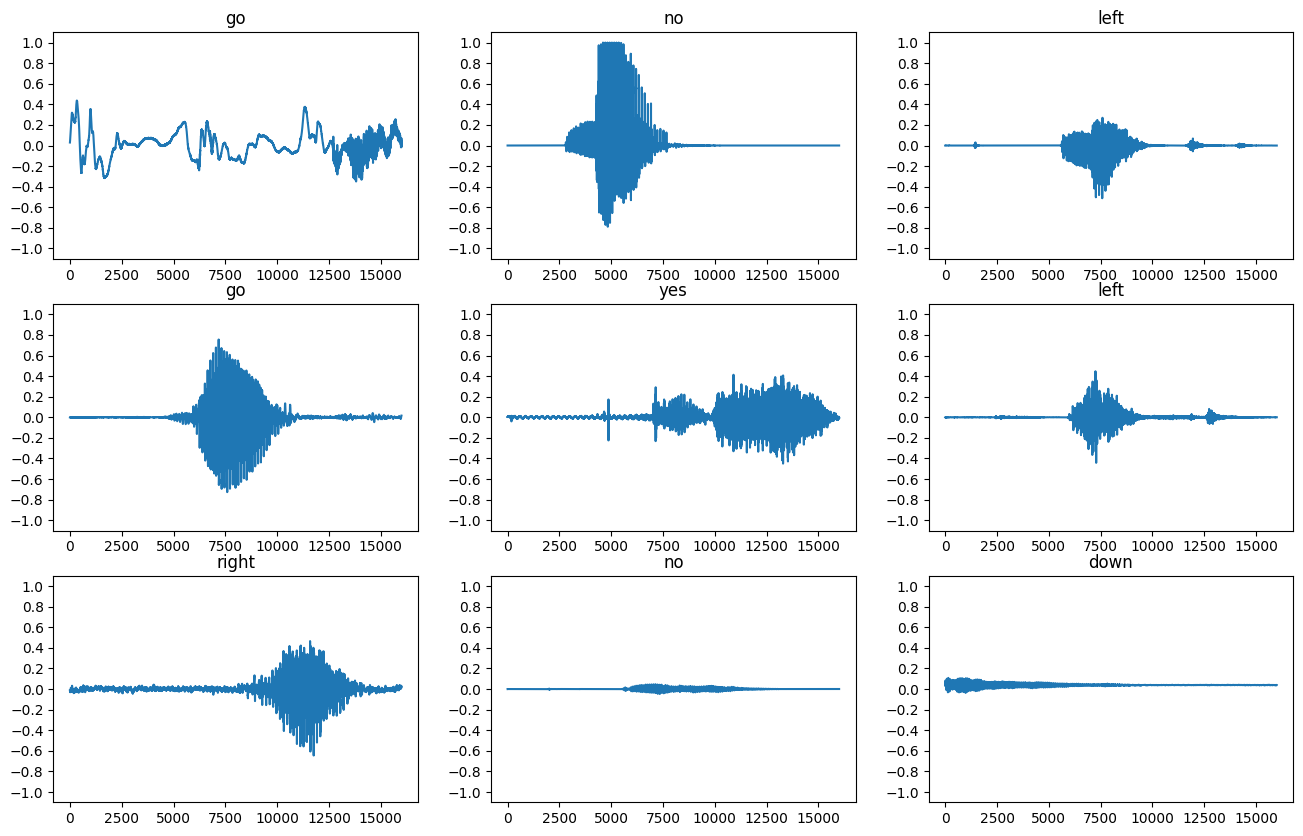
המרת צורות גל לספקטרוגרמות
צורות הגל במערך הנתונים מיוצגות בתחום הזמן. לאחר מכן, תמיר את צורות הגל מאותות תחום הזמן לאותות תחום הזמן על ידי חישוב טרנספורמציה פורייה קצרת זמן (STFT) כדי להמיר את צורות הגל כספקטרוגרמות , אשר מציגות שינויים בתדר לאורך זמן ויכולות להיות מיוצג כתמונות דו-ממדיות. אתה תזין את תמונות הספקטרוגרמה לרשת העצבית שלך כדי לאמן את המודל.
טרנספורמציה של פורייה ( tf.signal.fft ) ממירה אות לתדרים המרכיבים שלו, אך מאבדת את כל המידע. לשם השוואה, STFT ( tf.signal.stft ) מפצל את האות לחלונות זמן ומריץ טרנספורמציה של פורייה בכל חלון, תוך שמירה על מידע זמן והחזרת טנזור דו-ממדי שניתן להריץ עליו פיתולים סטנדרטיים.
צור פונקציית עזר להמרת צורות גל לספקטרוגרמות:
- צורות הגל צריכות להיות באותו אורך, כך שכאשר אתה ממיר אותן לספקטרוגרמות, לתוצאות יש ממדים דומים. ניתן לעשות זאת פשוט על ידי ריפוד אפס של קטעי האודיו שהם קצרים משנייה אחת (באמצעות
tf.zeros). - בעת קריאה
tf.signal.stft, בחר את הפרמטריםframe_lengthו-frame_stepכך ש"תמונה" הספקטרוגרמה שנוצרה תהיה כמעט מרובעת. למידע נוסף על בחירת פרמטרי STFT, עיין בסרטון Coursera זה על עיבוד אותות אודיו ו-STFT. - ה-STFT מייצר מערך של מספרים מרוכבים המייצגים גודל ופאזה. עם זאת, במדריך זה תשתמש רק בגודל, שאתה יכול להסיק על ידי החלת
tf.absעל הפלט שלtf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
לאחר מכן, התחל לחקור את הנתונים. הדפס את הצורות של צורת הגל המתוחה של דוגמה אחת והספקטרוגרמה המתאימה, והשמע את האודיו המקורי:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
כעת, הגדר פונקציה להצגת ספקטרוגרמה:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
צייר את צורת הגל של הדוגמה לאורך זמן ואת הספקטרוגרמה המתאימה (תדרים לאורך זמן):
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
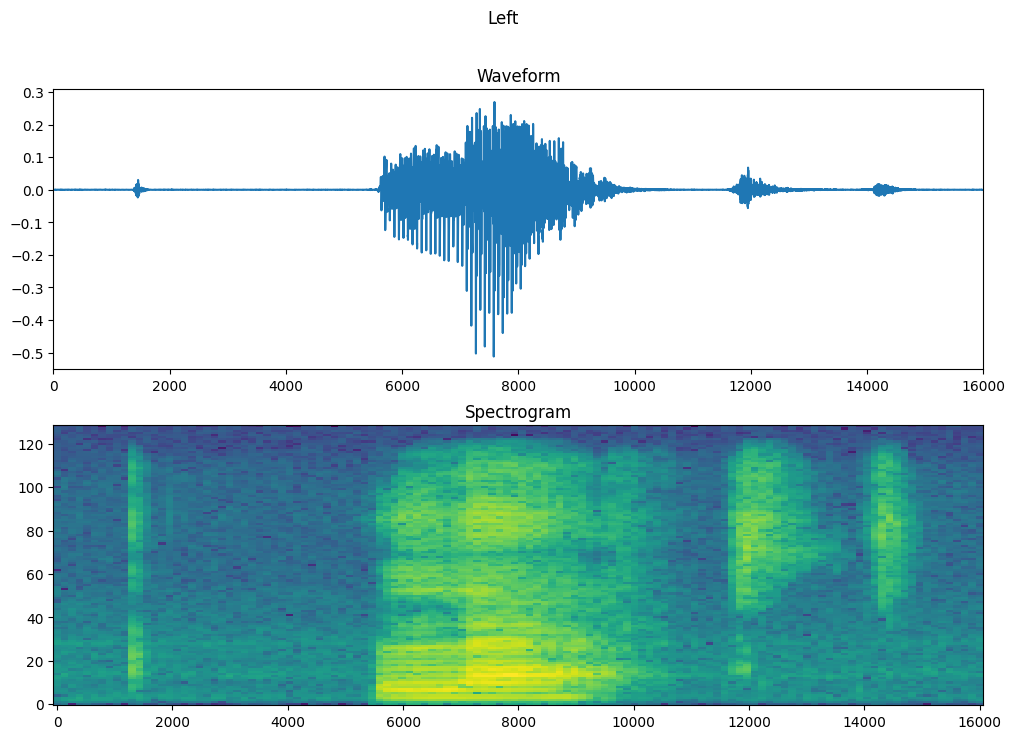
כעת, הגדר פונקציה שהופכת את מערך הנתונים של צורות הגל לספקטרוגרמות והתוויות המתאימות להן כמזהי מספרים שלמים:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
מפה get_spectrogram_and_label_id על פני רכיבי מערך הנתונים באמצעות Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
בדוק את הספקטרוגרמות עבור דוגמאות שונות של מערך הנתונים:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
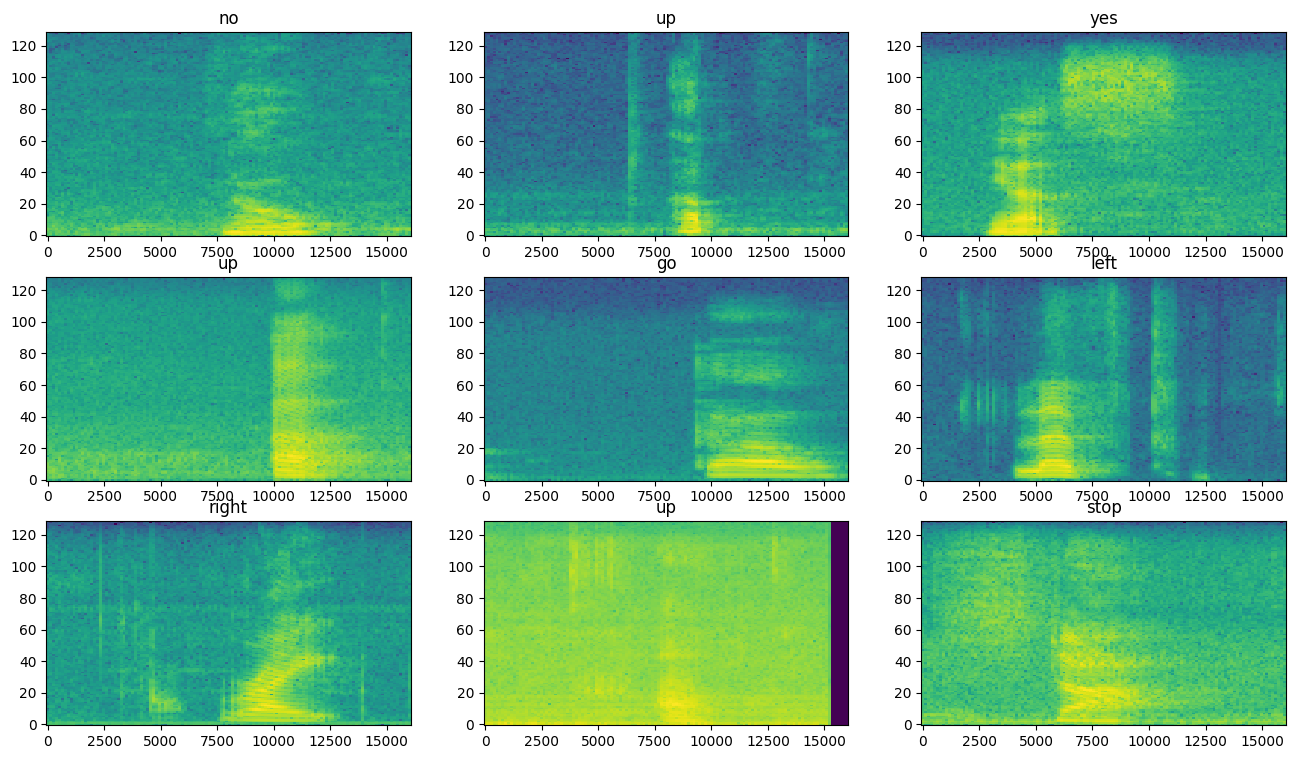
בנה ואימון המודל
חזור על העיבוד המקדים של ערכת ההדרכה על ערכות האימות והבדיקות:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
אצווה את ערכות ההדרכה והאימות לאימון מודלים:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
הוסף פעולות Dataset.cache ו- Dataset.prefetch כדי להפחית את זמן האחזור לקריאה בזמן אימון המודל:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
עבור המודל, תשתמש ברשת עצבית קונבולוציונית פשוטה (CNN), מכיוון שהפכת את קבצי האודיו לתמונות ספקטרוגרמה.
מודל tf.keras.Sequential שלך ישתמש בשכבות העיבוד המקדים הבאות של Keras:
-
tf.keras.layers.Resizing: להקטין דגימה של הקלט כדי לאפשר למודל להתאמן מהר יותר. -
tf.keras.layers.Normalization.נורמליזציה : לנרמל כל פיקסל בתמונה על סמך הממוצע וסטיית התקן שלו.
עבור שכבת Normalization , תחילה יהיה צורך לקרוא לשיטת adapt שלה על נתוני האימון על מנת לחשב סטטיסטיקה מצטברת (כלומר, הממוצע וסטיית התקן).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
הגדר את מודל Keras עם אופטימיזציית Adam ואובדן האנטרופיה הצולבת:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
אמן את הדגם במשך 10 עידנים למטרות הדגמה:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
בואו נשרטט את עקומות אובדן האימון והאימות כדי לבדוק כיצד המודל שלך השתפר במהלך האימון:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

הערך את ביצועי המודל
הפעל את הדגם על ערכת הבדיקה ובדוק את ביצועי הדגם:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
הצג מטריצת בלבול
השתמש במטריצת בלבול כדי לבדוק עד כמה המודל הצליח לסיווג כל אחת מהפקודות בערכת הבדיקה:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
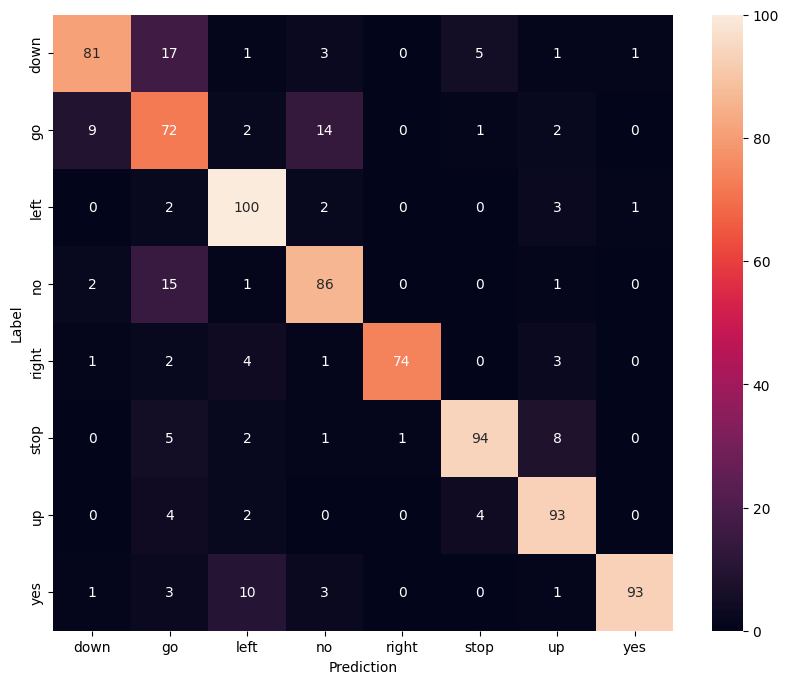
הפעל מסקנות על קובץ שמע
לבסוף, אמת את פלט החיזוי של המודל באמצעות קובץ שמע קלט של מישהו שאומר "לא". עד כמה הדגם שלך מתפקד?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
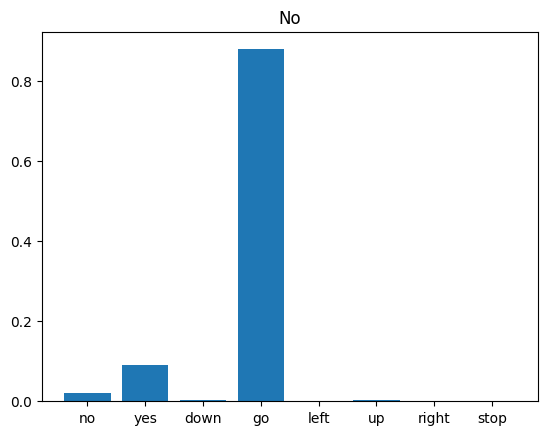
כפי שהפלט מרמז, הדגם שלך היה צריך לזהות את פקודת האודיו כ"לא".
הצעדים הבאים
מדריך זה הדגים כיצד לבצע סיווג אודיו פשוט/זיהוי דיבור אוטומטי באמצעות רשת עצבית קונבולוציונית עם TensorFlow ו-Python. למידע נוסף, שקול את המשאבים הבאים:
- ערכת הלימוד של סיווג סאונד עם YAMNet מראה כיצד להשתמש בלימוד העברה לסיווג אודיו.
- המחברות מאתגר זיהוי הדיבור TensorFlow של Kaggle .
- ה- TensorFlow.js - זיהוי אודיו באמצעות מעבדת למידה של העברה מלמד כיצד לבנות אפליקציית אינטרנט אינטראקטיבית משלך לסיווג אודיו.
- מדריך על למידה עמוקה לאחזור מידע מוזיקלי (Choi et al., 2017) ב-arXiv.
- ל-TensorFlow יש גם תמיכה נוספת בהכנה והגדלה של נתוני אודיו כדי לעזור בפרויקטים מבוססי אודיו משלך.
- שקול להשתמש בספריית librosa - חבילת Python לניתוח מוזיקה ואודיו.