
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek pokazuje, jak wstępnie przetwarzać pliki audio w formacie WAV oraz budować i trenować podstawowy model automatycznego rozpoznawania mowy (ASR) do rozpoznawania dziesięciu różnych słów. Użyjesz części zestawu danych poleceń mowy ( Warden, 2018 ), który zawiera krótkie (jednosekundowe lub krótsze) klipy dźwiękowe z poleceniami, takie jak „w dół”, „idź”, „w lewo”, „nie”, „ w prawo”, „stop”, „w górę” i „tak”.
Systemy rozpoznawania mowy i dźwięku w świecie rzeczywistym są złożone. Jednak podobnie jak klasyfikacja obrazów za pomocą zestawu danych MNIST , ten samouczek powinien zapewnić podstawowe zrozumienie stosowanych technik.
Ustawiać
Importuj niezbędne moduły i zależności. Pamiętaj, że w tym samouczku do wizualizacji będziesz używać seaborna .
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
Zaimportuj minizestaw danych poleceń mowy
Aby zaoszczędzić czas podczas ładowania danych, będziesz pracować z mniejszą wersją zestawu danych poleceń mowy. Oryginalny zbiór danych składa się z ponad 105 000 plików audio w formacie WAV (Waveform) z osobami wypowiadającymi 35 różnych słów. Te dane zostały zebrane przez Google i udostępnione na licencji CC BY.
Pobierz i wyodrębnij plik mini_speech_commands.zip zawierający mniejsze zestawy danych poleceń mowy za pomocą tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
Klipy audio zestawu danych są przechowywane w ośmiu folderach odpowiadających każdemu poleceniu mowy: no , yes , down , go , left , up , right i stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
Wyodrębnij klipy audio na listę o nazwie filenames i przetasuj ją:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
Podziel filenames na zestawy treningowe, walidacyjne i testowe przy użyciu proporcji 80:10:10, odpowiednio:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
Przeczytaj pliki audio i ich etykiety
W tej sekcji wstępnie przetworzysz zbiór danych, tworząc zdekodowane tensory dla przebiegów i odpowiednich etykiet. Zwróć uwagę, że:
- Każdy plik WAV zawiera dane szeregów czasowych z ustaloną liczbą próbek na sekundę.
- Każda próbka reprezentuje amplitudę sygnału audio w określonym czasie.
- W systemie 16-bitowym , takim jak pliki WAV w zestawie danych mini Speech Commands, wartości amplitudy mieszczą się w zakresie od -32 768 do 32 767.
- Częstotliwość próbkowania dla tego zestawu danych wynosi 16 kHz.
Kształt tensora zwracanego przez tf.audio.decode_wav to [samples, channels] , gdzie channels to 1 dla mono lub 2 dla stereo. Minizestaw danych poleceń mowy zawiera tylko nagrania mono.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
Teraz zdefiniujmy funkcję, która wstępnie przetwarza nieprzetworzone pliki audio WAV zestawu danych na tensory audio:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
Zdefiniuj funkcję, która tworzy etykiety przy użyciu katalogów nadrzędnych dla każdego pliku:
- Podziel ścieżki plików na
tf.RaggedTensors (tensory o poszarpanych wymiarach — z plastrami, które mogą mieć różne długości).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
Zdefiniuj inną funkcję pomocniczą — get_waveform_and_label — która łączy to wszystko w jedną całość:
- Dane wejściowe to nazwa pliku audio WAV.
- Dane wyjściowe to krotka zawierająca tensory audio i etykiet gotowe do nadzorowanego uczenia się.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
Zbuduj zestaw szkoleniowy, aby wyodrębnić pary etykiet audio:
- Utwórz
tf.data.DatasetzDataset.from_tensor_slicesiDataset.map, używając wcześniej zdefiniowanych funkcjiget_waveform_and_label.
Później zbudujesz zestawy do walidacji i testów, używając podobnej procedury.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
Narysujmy kilka przebiegów dźwiękowych:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
Konwertuj przebiegi na spektrogramy
Przebiegi w zestawie danych są reprezentowane w dziedzinie czasu. Następnie przekształcisz przebiegi z sygnałów w dziedzinie czasu na sygnały w dziedzinie czasu i częstotliwości, obliczając krótkotrwałą transformację Fouriera (STFT) , aby przekształcić przebiegi w spektrogramy , które pokazują zmiany częstotliwości w czasie i mogą być reprezentowane jako obrazy 2D. Wprowadzisz obrazy spektrogramu do swojej sieci neuronowej, aby wytrenować model.
Transformacja Fouriera ( tf.signal.fft ) przekształca sygnał na jego częstotliwości składowe, ale traci wszystkie informacje o czasie. Dla porównania, STFT ( tf.signal.stft ) dzieli sygnał na okna czasu i przeprowadza transformację Fouriera w każdym oknie, zachowując pewne informacje o czasie i zwracając tensor 2D, na którym można przeprowadzać standardowe sploty.
Utwórz funkcję użytkową do konwersji przebiegów na spektrogramy:
- Przebiegi muszą mieć tę samą długość, aby po konwersji na spektrogram wyniki miały podobne wymiary. Można to zrobić po prostu dopełniając zerami klipy audio, które są krótsze niż jedna sekunda (za pomocą
tf.zeros). - Podczas wywoływania
tf.signal.stft, wybierz parametryframe_lengthiframe_steptak, aby wygenerowany "obraz" spektrogramu był prawie kwadratowy. Aby uzyskać więcej informacji na temat wyboru parametrów STFT, zapoznaj się z tym filmem Coursera dotyczącym przetwarzania sygnału audio i STFT. - STFT tworzy tablicę liczb zespolonych reprezentujących wielkość i fazę. Jednak w tym samouczku użyjesz tylko wielkości, którą możesz uzyskać, stosując
tf.absna wyjściutf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
Następnie zacznij eksplorować dane. Wydrukuj kształty tensoryzowanego kształtu fali z jednego przykładu oraz odpowiadający mu spektrogram i odtwórz oryginalny dźwięk:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
Teraz zdefiniuj funkcję wyświetlania spektrogramu:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
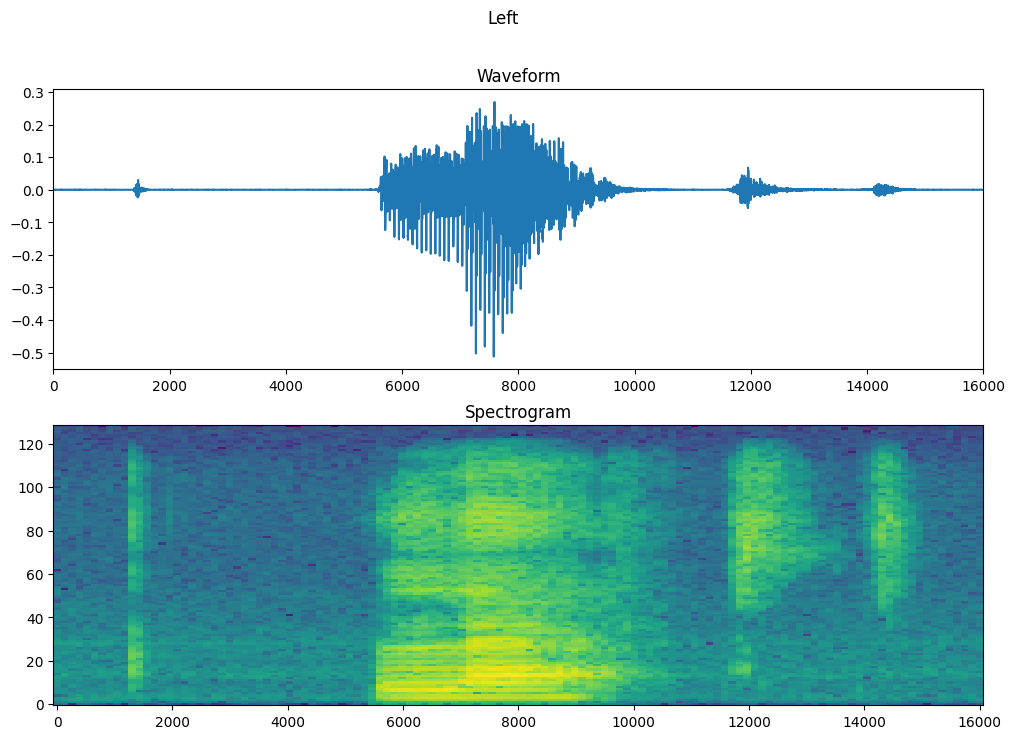
Wykreśl przebieg w czasie z przykładu i odpowiadający mu spektrogram (częstotliwości w czasie):
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
Teraz zdefiniuj funkcję, która przekształca zbiór danych przebiegu w spektrogramy i odpowiadające im etykiety jako identyfikatory całkowite:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
get_spectrogram_and_label_id na elementy zestawu danych za pomocą Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
Zbadaj spektrogramy pod kątem różnych przykładów zbioru danych:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
Zbuduj i wytrenuj model
Powtórz wstępne przetwarzanie zestawu szkoleniowego na zestawach walidacyjnych i testowych:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
Wsadowe zestawy uczące i walidacyjne do uczenia modelu:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Dodaj Dataset.cache i Dataset.prefetch , aby zmniejszyć opóźnienie odczytu podczas uczenia modelu:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
W modelu użyjesz prostej splotowej sieci neuronowej (CNN), ponieważ przekształciłeś pliki audio w obrazy spektrogramów.
Twój model tf.keras.Sequential będzie korzystał z następujących warstw przetwarzania wstępnego Keras:
-
tf.keras.layers.Resizing: próbkowanie danych wejściowych w dół, aby umożliwić szybsze trenowanie modelu. -
tf.keras.layers.Normalization: normalizacja każdego piksela na obrazie na podstawie jego średniej i odchylenia standardowego.
W przypadku warstwy Normalization jej metoda adapt musiałaby najpierw zostać wywołana na danych uczących w celu obliczenia zagregowanych statystyk (tj. średniej i odchylenia standardowego).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Skonfiguruj model Keras z optymalizatorem Adama i stratą entropii krzyżowej:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
Trenuj model przez 10 epok w celach demonstracyjnych:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
Wykreślmy krzywe utraty treningu i walidacji, aby sprawdzić, jak poprawił się Twój model podczas uczenia:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

Oceń wydajność modelu
Uruchom model na zestawie testowym i sprawdź wydajność modelu:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
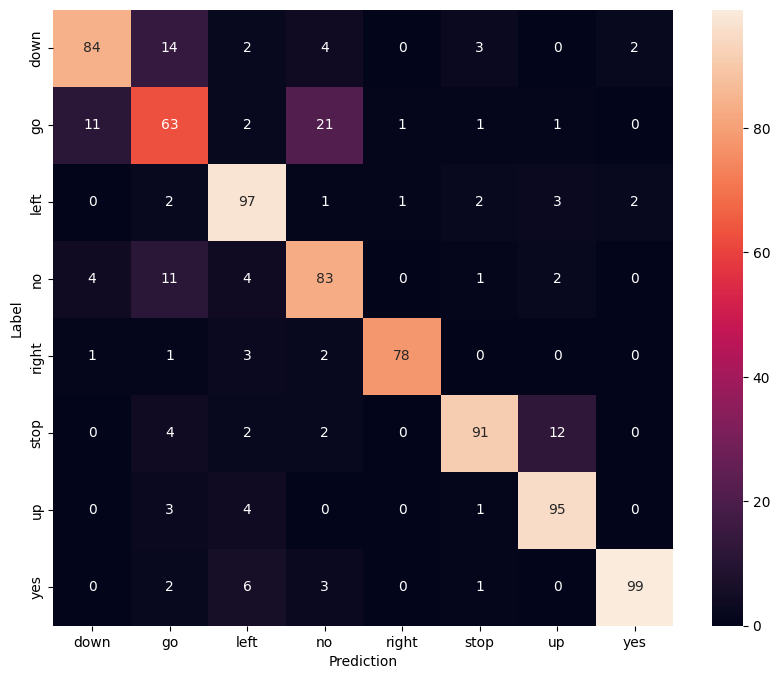
Wyświetl macierz pomyłek
Użyj macierzy pomyłek, aby sprawdzić, jak dobrze model zaklasyfikował każde z poleceń w zestawie testowym:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
Uruchom wnioskowanie na pliku audio
Na koniec zweryfikuj dane wyjściowe prognozowania modelu, korzystając z wejściowego pliku audio osoby, która mówi „nie”. Jak dobrze spisuje się Twój model?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
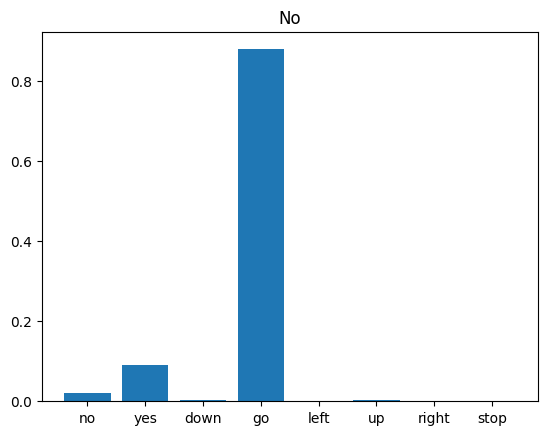
Jak sugeruje dane wyjściowe, twój model powinien rozpoznać polecenie audio jako „nie”.
Następne kroki
Ten samouczek zademonstrował, jak przeprowadzić prostą klasyfikację dźwięku/automatyczne rozpoznawanie mowy przy użyciu splotowej sieci neuronowej z TensorFlow i Pythonem. Aby dowiedzieć się więcej, rozważ następujące zasoby:
- Samouczek klasyfikacji dźwięku za pomocą YAMNet pokazuje, jak używać uczenia transferu do klasyfikacji dźwięku.
- Notatniki z wyzwania rozpoznawania mowy TensorFlow firmy Kaggle .
- TensorFlow.js — Rozpoznawanie dźwięku za pomocą ćwiczenia kodowania uczenia transferu uczy, jak zbudować własną interaktywną aplikację internetową do klasyfikacji dźwięku.
- Samouczek dotyczący głębokiego uczenia się do wyszukiwania informacji muzycznych (Choi i in., 2017) na arXiv.
- TensorFlow oferuje również dodatkowe wsparcie w zakresie przygotowywania i rozszerzania danych dźwiękowych, aby pomóc we własnych projektach opartych na dźwięku.
- Rozważ użycie biblioteki librosa — pakietu Pythona do analizy muzyki i dźwięku.