
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве создается состязательный пример с использованием атаки Fast Gradient Signed Method (FGSM), как описано в статье « Объяснение и использование состязательных примеров » Goodfellow et al . Это была одна из первых и самых популярных атак для обмана нейронной сети.
Что такое состязательный пример?
Враждебные примеры — это специализированные входные данные, созданные с целью запутать нейронную сеть, что приводит к неправильной классификации данного входного сигнала. Эти пресловутые входные данные неразличимы для человеческого глаза, но приводят к тому, что сеть не может идентифицировать содержимое изображения. Существует несколько типов таких атак, однако здесь основное внимание уделяется атаке методом быстрого знака градиента, которая представляет собой атаку белого ящика , целью которой является обеспечение ошибочной классификации. Атака белого ящика — это когда злоумышленник имеет полный доступ к атакуемой модели. Один из самых известных примеров состязательного изображения, показанный ниже, взят из вышеупомянутой статьи.

Здесь, начиная с изображения панды, злоумышленник добавляет небольшие возмущения (искажения) к исходному изображению, в результате чего модель с высокой достоверностью помечает это изображение как гиббон. Процесс добавления этих возмущений поясняется ниже.
Метод быстрого знака градиента
Метод быстрого знака градиента работает, используя градиенты нейронной сети для создания состязательного примера. Для входного изображения метод использует градиенты потерь по отношению к входному изображению, чтобы создать новое изображение, которое максимизирует потери. Этот новый образ называется состязательным образом. Это можно резюмировать с помощью следующего выражения:
\[adv\_x = x + \epsilon*\text{sign}(\nabla_xJ(\theta, x, y))\]
где
- adv_x : Враждебное изображение.
- x : Исходное входное изображение.
- y : Исходная метка ввода.
- \(\epsilon\) : Множитель для обеспечения малых возмущений.
- \(\theta\) : Параметры модели.
- \(J\) : Потеря.
Интригующим свойством здесь является тот факт, что градиенты берутся относительно входного изображения. Это делается потому, что цель состоит в том, чтобы создать изображение, которое максимизирует потери. Метод для достижения этого состоит в том, чтобы найти, какой вклад вносит каждый пиксель изображения в значение потерь, и соответствующим образом добавить возмущение. Это работает довольно быстро, потому что легко найти вклад каждого входного пикселя в потери, используя цепное правило и найдя необходимые градиенты. Следовательно, градиенты берутся относительно изображения. Кроме того, поскольку модель больше не обучается (таким образом, градиент не берется относительно обучаемых переменных, т. е. параметров модели), параметры модели остаются постоянными. Единственная цель — обмануть уже обученную модель.
Итак, давайте попробуем обмануть предварительно обученную модель. В этом руководстве используется модель MobileNetV2 , предварительно обученная на ImageNet .
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
Давайте загрузим предварительно обученную модель MobileNetV2 и имена классов ImageNet.
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_224.h5 14540800/14536120 [==============================] - 0s 0us/step 14548992/14536120 [==============================] - 0s 0us/step
# Helper function to preprocess the image so that it can be inputted in MobileNetV2
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
Исходное изображение
Давайте возьмем пример изображения лабрадора-ретривера Мирко CC-BY-SA 3.0 из Wikimedia Common и создадим на его основе враждебные примеры. Первым шагом является его предварительная обработка, чтобы его можно было использовать в качестве входных данных для модели MobileNetV2.
{kind=link}
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg 90112/83281 [================================] - 0s 0us/step 98304/83281 [===================================] - 0s 0us/step
Давайте посмотрим на изображение.
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step 49152/35363 [=========================================] - 0s 0us/step

Создайте враждебный образ
Реализация метода быстрого знака градиента
Первым шагом является создание возмущений, которые будут использоваться для искажения исходного изображения, в результате чего получится состязательное изображение. Как уже упоминалось, для этой задачи градиенты берутся по отношению к изображению.
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
Результирующие возмущения также можно визуализировать.
# Get the input label of the image.
labrador_retriever_index = 208
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]
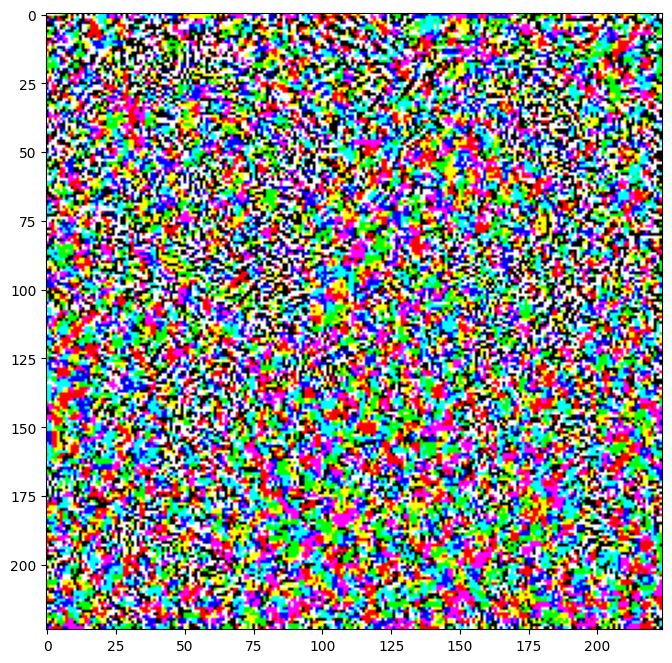
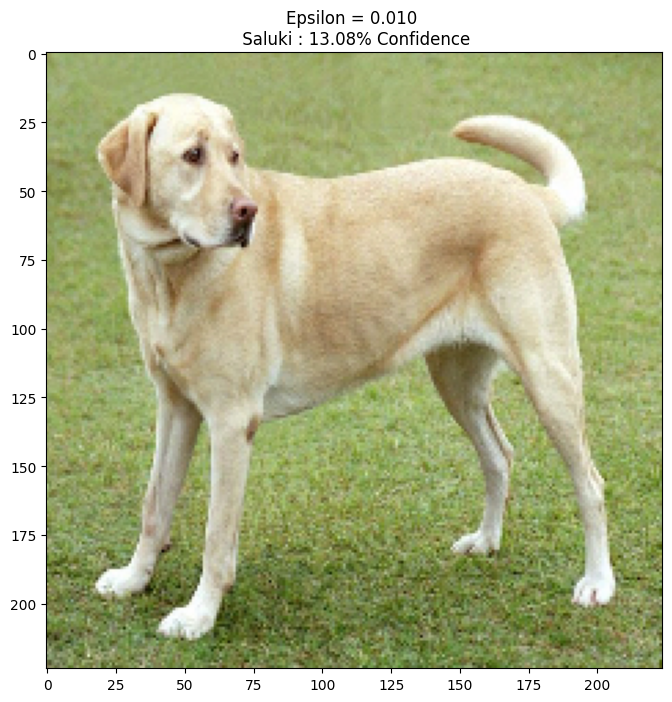
Давайте попробуем это для разных значений эпсилон и посмотрим на результирующее изображение. Вы заметите, что по мере увеличения значения эпсилон становится легче обмануть сеть. Однако это происходит как компромисс, который приводит к тому, что возмущения становятся более идентифицируемыми.
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])



Следующие шаги
Теперь, когда вы знаете о состязательных атаках, попробуйте это на разных наборах данных и разных архитектурах. Вы также можете создать и обучить свою собственную модель, а затем попытаться обмануть ее, используя тот же метод. Вы также можете попробовать и посмотреть, как меняется достоверность прогнозов при изменении эпсилон.
Несмотря на свою мощь, атака, показанная в этом руководстве, была лишь началом исследований состязательных атак, и с тех пор было опубликовано несколько статей, посвященных более мощным атакам. В дополнение к состязательным атакам исследования также привели к созданию средств защиты, целью которых является создание надежных моделей машинного обучения. Вы можете просмотреть этот обзорный документ для получения полного списка состязательных атак и средств защиты.
Для многих других реализаций состязательных атак и защиты вы можете посмотреть библиотеку состязательных примеров CleverHans .