
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве показано, как реализовать метод «актор -критик » с помощью TensorFlow для обучения агента в среде Open AI Gym CartPole-V0. Предполагается, что читатель немного знаком с градиентными методами обучения с подкреплением.
Актерско-критические методы
Методы «актор-критик» представляют собой методы обучения временной разности (TD) , которые представляют функцию политики, независимую от функции ценности.
Функция политики (или политика) возвращает распределение вероятностей по действиям, которые агент может предпринять на основе заданного состояния. Функция ценности определяет ожидаемую прибыль для агента, начиная с данного состояния и действуя в соответствии с определенной политикой навсегда после этого.
В методе «актор-критик» политика называется актором , который предлагает набор возможных действий при заданном состоянии, а функция оценочного значения называется критиком , который оценивает действия, предпринятые актором на основе заданной политики. .
В этом уроке и Актер , и Критик будут представлены с помощью одной нейронной сети с двумя выходами.
CartPole-v0
В среде CartPole-v0 к тележке, движущейся по безфрикционной дорожке, прикрепляется шест. Столб поднимается вверх, и цель агента состоит в том, чтобы предотвратить его падение, приложив к тележке силу -1 или +1. Награда +1 дается за каждый шаг, когда шест остается в вертикальном положении. Эпизод заканчивается, когда (1) шест отклоняется от вертикали более чем на 15 градусов или (2) тележка перемещается более чем на 2,4 единицы от центра.
Задача считается «решенной», когда средняя общая награда за эпизод достигает 195 за 100 последовательных испытаний.
Настраивать
Импортируйте необходимые пакеты и настройте глобальные параметры.
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
Модель
Актер и Критик будут смоделированы с использованием одной нейронной сети, которая генерирует вероятности действий и критическое значение соответственно. В этом руководстве для определения модели используется подкласс модели.
Во время прямого прохода модель будет принимать состояние в качестве входных данных и выводить как вероятности действий, так и критическое значение \(V\), которое моделирует функцию значения , зависящую от состояния. Цель состоит в том, чтобы обучить модель, которая выбирает действия на основе политики \(\pi\) , которая максимизирует ожидаемую отдачу .
Для Cartpole-v0 есть четыре значения, представляющие состояние: положение тележки, скорость тележки, угол полюса и скорость полюса соответственно. Агент может выполнить два действия, чтобы толкнуть тележку влево (0) и вправо (1) соответственно.
Обратитесь к вики-странице OpenAI Gym CartPole-v0 для получения дополнительной информации.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
Обучение
Для обучения агента выполните следующие действия:
- Запустите агент в среде, чтобы собрать обучающие данные для каждого эпизода.
- Вычислите ожидаемую доходность на каждом временном шаге.
- Вычислите потерю для объединенной модели актера-критика.
- Вычислите градиенты и обновите параметры сети.
- Повторяйте 1–4, пока не будет достигнут критерий успеха или максимальное количество эпизодов.
1. Сбор обучающих данных
Как и в случае обучения с учителем, для обучения модели «актор-критик» вам нужны обучающие данные. Однако для сбора таких данных модель необходимо «запустить» в среде.
Данные обучения собираются для каждого эпизода. Затем на каждом временном шаге будет выполняться прямой проход модели для состояния среды, чтобы генерировать вероятности действий и критическое значение на основе текущей политики, параметризованной весами модели.
Следующее действие будет выбрано из вероятностей действий, сгенерированных моделью, которые затем будут применены к среде, что приведет к созданию следующего состояния и вознаграждения.
Этот процесс реализован в функции run_episode , которая использует операции TensorFlow, чтобы впоследствии ее можно было скомпилировать в граф TensorFlow для более быстрого обучения. Обратите внимание, что tf.TensorArray использовались для поддержки итерации Tensor для массивов переменной длины.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. Расчет ожидаемой доходности
Последовательность вознаграждений для каждого временного шага \(t\), \(\{r_{t}\}^{T}_{t=1}\) , собранная в течение одного эпизода, преобразуется в последовательность ожидаемых доходов \(\{G_{t}\}^{T}_{t=1}\) , в которой сумма вознаграждений берется от текущего временного шага \(t\) до \(T\) и каждый вознаграждение умножается на экспоненциально затухающий коэффициент дисконтирования \(\gamma\):
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
Начиная с \(\gamma\in(0,1)\)вознаграждения, находящиеся дальше от текущего временного шага, имеют меньший вес.
Интуитивно ожидаемый доход просто означает, что вознаграждение сейчас лучше, чем вознаграждение позже. В математическом смысле это гарантирует сходимость суммы вознаграждений.
Для стабилизации обучения результирующая последовательность результатов также стандартизируется (т.е. имеет нулевое среднее значение и единичное стандартное отклонение).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. Проигрыш актера-критика
Поскольку используется гибридная модель актер-критик, выбранная функция потерь представляет собой комбинацию потерь актера и критика для обучения, как показано ниже:
\[L = L_{actor} + L_{critic}\]
Потеря актера
Потери актера основаны на градиентах политики с критиком в качестве базового уровня, зависящего от состояния, и вычисляются с помощью оценок для одной выборки (для каждого эпизода).
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
где:
- \(T\): количество временных шагов в эпизоде, которое может варьироваться в зависимости от эпизода.
- \(s_{t}\): состояние на временном шаге \(t\)
- \(a_{t}\): выбранное действие на временном шаге \(t\) заданным состоянием \(s\)
- \(\pi_{\theta}\): политика (актер), параметризованная \(\theta\)
- \(V^{\pi}_{\theta}\): функция значения (критическая), также параметризованная \(\theta\)
- \(G = G_{t}\): ожидаемый доход для данного состояния, пара действий на временном шаге \(t\)
К сумме добавляется отрицательный член, поскольку идея состоит в том, чтобы максимизировать вероятность действий, приносящих более высокие вознаграждения, путем минимизации совокупных потерь.
Преимущество
Термин \(G - V\) в нашей формулировке \(L_{actor}\) называется преимуществом , которое указывает, насколько лучше действие получает конкретное состояние по сравнению со случайным действием, выбранным в соответствии с политикой \(\pi\) для этого состояния.
Хотя можно исключить базовый уровень, это может привести к высокой дисперсии во время обучения. И хорошая вещь в выборе критика \(V\) в качестве базовой линии заключается в том, что он обучен быть как можно ближе к \(G\), что приводит к более низкой дисперсии.
Кроме того, без критика алгоритм попытается увеличить вероятность действий, предпринятых в определенном состоянии, на основе ожидаемой отдачи, что может не иметь большого значения, если относительные вероятности между действиями останутся прежними.
Например, предположим, что два действия для данного состояния дадут один и тот же ожидаемый доход. Без критика алгоритм попытался бы повысить вероятность этих действий на основе цели \(J\). С критиком может оказаться, что преимущества нет (\(G - V = 0\)) и, следовательно, нет никакой выгоды от увеличения вероятности действий, и алгоритм установит градиенты на ноль.
Критическая потеря
Обучение \(V\) максимальному приближению к \(G\) можно настроить как задачу регрессии со следующей функцией потерь:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
где \(L_{\delta}\) — потери Хьюбера , которые менее чувствительны к выбросам в данных, чем потери квадрата ошибки.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. Определение шага обучения для обновления параметров
Все вышеперечисленные шаги объединены в этап обучения, который выполняется в каждом эпизоде. Все шаги, ведущие к функции потерь, выполняются с контекстом tf.GradientTape , чтобы включить автоматическое дифференцирование.
В этом руководстве используется оптимизатор Adam для применения градиентов к параметрам модели.
На этом шаге также вычисляется сумма недисконтированных вознаграждений, episode_reward . Это значение будет использоваться позже для оценки соответствия критерию успеха.
Контекст tf.function применяется к функции train_step , чтобы ее можно было скомпилировать в вызываемый граф TensorFlow, что может привести к 10-кратному ускорению обучения.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. Запустите тренировочный цикл
Обучение выполняется путем запуска шага обучения до тех пор, пока не будет достигнут критерий успеха или максимальное количество эпизодов.
Текущая запись наград за эпизод хранится в очереди. По достижении 100 испытаний самая старая награда удаляется из левого (хвостового) конца очереди, а самая новая добавляется в начало (справа). Текущая сумма вознаграждений также поддерживается для вычислительной эффективности.
В зависимости от времени выполнения обучение может завершиться менее чем за минуту.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
Визуализация
После обучения было бы хорошо визуализировать, как модель ведет себя в окружающей среде. Вы можете запустить ячейки ниже, чтобы создать GIF-анимацию одного эпизода модели. Обратите внимание, что для правильного рендеринга изображений среды в Colab необходимо установить дополнительные пакеты для OpenAI Gym.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
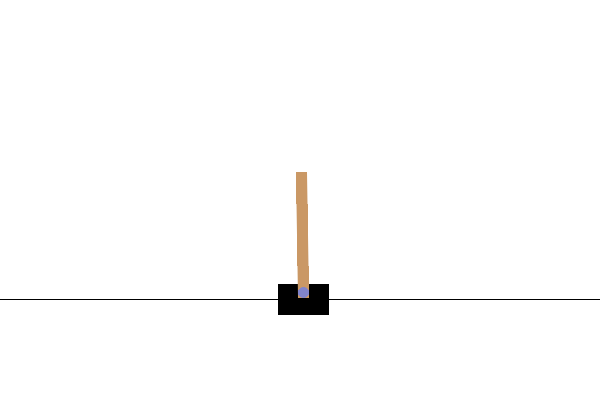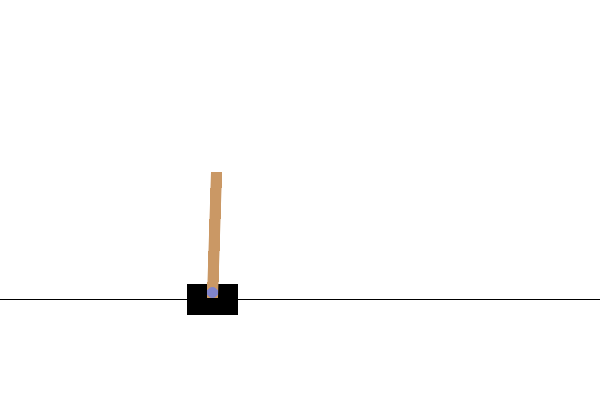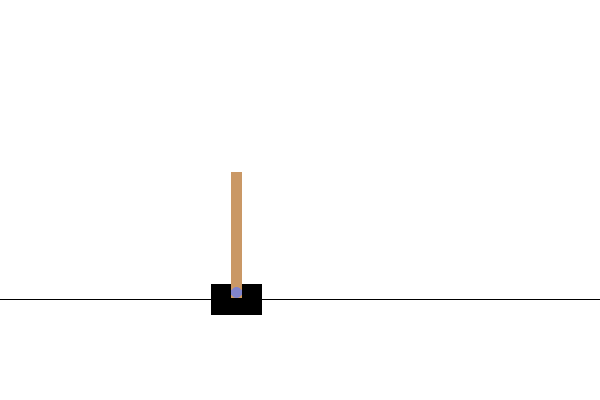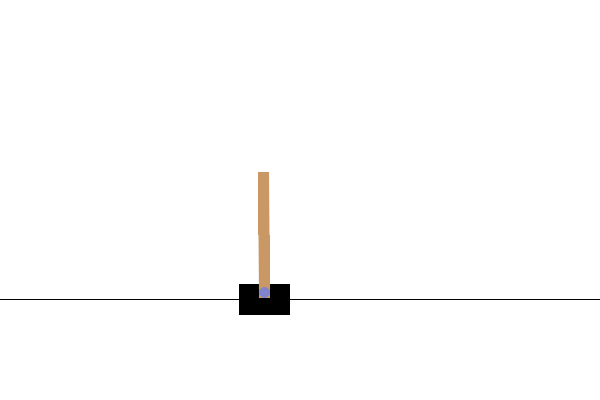
Следующие шаги
В этом руководстве показано, как реализовать метод актер-критик с помощью Tensorflow.
В качестве следующего шага вы можете попробовать обучить модель в другой среде в OpenAI Gym.
Для получения дополнительной информации о методах актер-критик и проблеме Cartpole-v0 вы можете обратиться к следующим ресурсам:
- Метод актерской критики
- Лекция актерского критика (CAL)
- Проблема управления обучением Cartpole [Barto, et al. 1983]
Дополнительные примеры обучения с подкреплением в TensorFlow можно найти на следующих ресурсах: