
| | |  ดูบน GitHub ดูบน GitHub | | |
Colab นี้สาธิตการใช้โมดูล TF Hub ตามเครือข่ายปฏิปักษ์กำเนิด (GAN) โมดูลจะแมปจากเวกเตอร์มิติ N ที่เรียกว่า สเปซแฝง ไปยังรูปภาพ RGB
มีตัวอย่างสองตัวอย่าง:
- การทำแผนที่จากพื้นที่ที่แฝงอยู่กับภาพและ
- ได้รับภาพเป้าหมายโดยใช้การไล่ระดับสีโคตรจะหาเวกเตอร์แฝงที่สร้างภาพคล้ายกับภาพเป้าหมาย
ข้อกำหนดเบื้องต้นเพิ่มเติม
- คุ้นเคยกับ ระดับต่ำแนวคิด Tensorflow
- กำเนิดขัดแย้งเครือข่าย วิกิพีเดีย
- กระดาษก้าวหน้า Gans: ก้าวหน้าการเติบโตของ Gans สำหรับการปรับปรุงคุณภาพเสถียรภาพและการเปลี่ยนแปลง
รุ่นอื่นๆ
ที่นี่ คุณสามารถหาทุกรุ่นเป็นเจ้าภาพในปัจจุบันใน tfhub.dev ที่สามารถสร้างภาพ
ติดตั้ง
# Install imageio for creating animations.pip -q install imageiopip -q install scikit-imagepip install git+https://github.com/tensorflow/docs
คำจำกัดความของการนำเข้าและฟังก์ชัน
from absl import logging
import imageio
import PIL.Image
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
tf.random.set_seed(0)
import tensorflow_hub as hub
from tensorflow_docs.vis import embed
import time
try:
from google.colab import files
except ImportError:
pass
from IPython import display
from skimage import transform
# We could retrieve this value from module.get_input_shapes() if we didn't know
# beforehand which module we will be using.
latent_dim = 512
# Interpolates between two vectors that are non-zero and don't both lie on a
# line going through origin. First normalizes v2 to have the same norm as v1.
# Then interpolates between the two vectors on the hypersphere.
def interpolate_hypersphere(v1, v2, num_steps):
v1_norm = tf.norm(v1)
v2_norm = tf.norm(v2)
v2_normalized = v2 * (v1_norm / v2_norm)
vectors = []
for step in range(num_steps):
interpolated = v1 + (v2_normalized - v1) * step / (num_steps - 1)
interpolated_norm = tf.norm(interpolated)
interpolated_normalized = interpolated * (v1_norm / interpolated_norm)
vectors.append(interpolated_normalized)
return tf.stack(vectors)
# Simple way to display an image.
def display_image(image):
image = tf.constant(image)
image = tf.image.convert_image_dtype(image, tf.uint8)
return PIL.Image.fromarray(image.numpy())
# Given a set of images, show an animation.
def animate(images):
images = np.array(images)
converted_images = np.clip(images * 255, 0, 255).astype(np.uint8)
imageio.mimsave('./animation.gif', converted_images)
return embed.embed_file('./animation.gif')
logging.set_verbosity(logging.ERROR)
การแก้ไขช่องว่างแฝง
สุ่มเวกเตอร์
การแก้ไขช่องว่างแฝงระหว่างเวกเตอร์เริ่มต้นแบบสุ่มสองตัว เราจะใช้โมดูล TF Hub progan-128 ที่มีก่อนการฝึกอบรมก้าวหน้า GAN
progan = hub.load("https://tfhub.dev/google/progan-128/1").signatures['default']
def interpolate_between_vectors():
v1 = tf.random.normal([latent_dim])
v2 = tf.random.normal([latent_dim])
# Creates a tensor with 25 steps of interpolation between v1 and v2.
vectors = interpolate_hypersphere(v1, v2, 50)
# Uses module to generate images from the latent space.
interpolated_images = progan(vectors)['default']
return interpolated_images
interpolated_images = interpolate_between_vectors()
animate(interpolated_images)

การหาเวกเตอร์ที่ใกล้ที่สุดในพื้นที่แฝง
แก้ไขภาพเป้าหมาย ตัวอย่างเช่น ใช้รูปภาพที่สร้างจากโมดูลหรืออัปโหลดของคุณเอง
image_from_module_space = True # @param { isTemplate:true, type:"boolean" }
def get_module_space_image():
vector = tf.random.normal([1, latent_dim])
images = progan(vector)['default'][0]
return images
def upload_image():
uploaded = files.upload()
image = imageio.imread(uploaded[list(uploaded.keys())[0]])
return transform.resize(image, [128, 128])
if image_from_module_space:
target_image = get_module_space_image()
else:
target_image = upload_image()
display_image(target_image)

หลังจากกำหนดฟังก์ชันการสูญเสียระหว่างรูปภาพเป้าหมายและรูปภาพที่สร้างโดยตัวแปรพื้นที่แฝงแล้ว เราสามารถใช้การไล่ระดับสีเพื่อค้นหาค่าตัวแปรที่ลดการสูญเสียให้เหลือน้อยที่สุด
tf.random.set_seed(42)
initial_vector = tf.random.normal([1, latent_dim])
display_image(progan(initial_vector)['default'][0])

def find_closest_latent_vector(initial_vector, num_optimization_steps,
steps_per_image):
images = []
losses = []
vector = tf.Variable(initial_vector)
optimizer = tf.optimizers.Adam(learning_rate=0.01)
loss_fn = tf.losses.MeanAbsoluteError(reduction="sum")
for step in range(num_optimization_steps):
if (step % 100)==0:
print()
print('.', end='')
with tf.GradientTape() as tape:
image = progan(vector.read_value())['default'][0]
if (step % steps_per_image) == 0:
images.append(image.numpy())
target_image_difference = loss_fn(image, target_image[:,:,:3])
# The latent vectors were sampled from a normal distribution. We can get
# more realistic images if we regularize the length of the latent vector to
# the average length of vector from this distribution.
regularizer = tf.abs(tf.norm(vector) - np.sqrt(latent_dim))
loss = target_image_difference + regularizer
losses.append(loss.numpy())
grads = tape.gradient(loss, [vector])
optimizer.apply_gradients(zip(grads, [vector]))
return images, losses
num_optimization_steps=200
steps_per_image=5
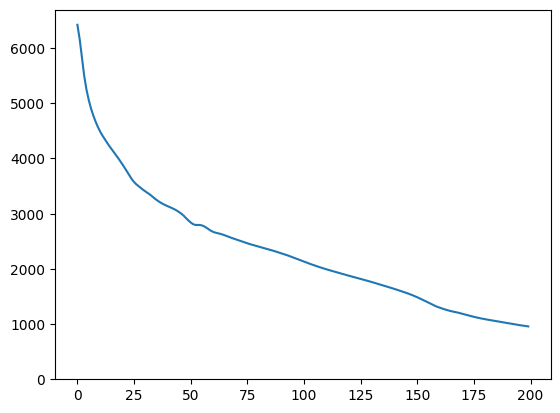
images, loss = find_closest_latent_vector(initial_vector, num_optimization_steps, steps_per_image)
.................................................................................................... ....................................................................................................
plt.plot(loss)
plt.ylim([0,max(plt.ylim())])
(0.0, 6696.301751708985)
animate(np.stack(images))

เปรียบเทียบผลลัพธ์กับเป้าหมาย:
display_image(np.concatenate([images[-1], target_image], axis=1))

เล่นกับตัวอย่างข้างต้น
หากรูปภาพมาจากพื้นที่โมดูล การลงจะเร็วและบรรจบกันเป็นกลุ่มตัวอย่างที่เหมาะสม ลองลงไปภาพที่ไม่ได้มาจากพื้นที่โมดูลที่ โคตรจะบรรจบกันก็ต่อเมื่อภาพอยู่ใกล้กับพื้นที่ของภาพการฝึกพอสมควร
จะทำให้ลงมาเร็วขึ้นและได้ภาพที่สมจริงยิ่งขึ้นได้อย่างไร? หนึ่งสามารถลอง:
- โดยใช้การสูญเสียความต่างของภาพต่างกัน เช่น กำลังสอง
- โดยใช้ตัวปรับมาตรฐานที่แตกต่างกันบนเวกเตอร์แฝง
- การเริ่มต้นจากเวกเตอร์สุ่มในการรันหลายครั้ง
- ฯลฯ