
ภาพรวม
ไปป์ไลน์ TensorFlow Model Analysis (TFMA) มีดังต่อไปนี้:
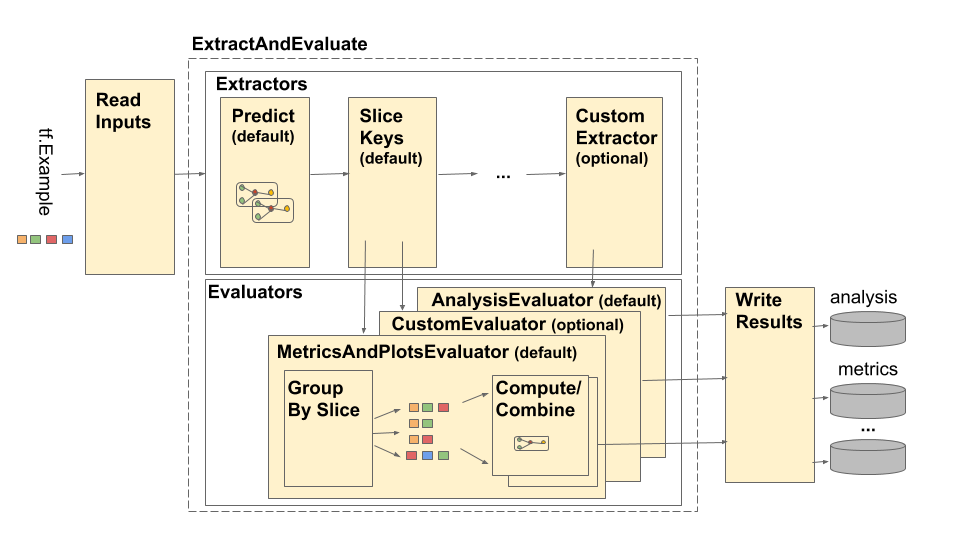
ท่อประกอบด้วยสี่องค์ประกอบหลัก:
- อ่านอินพุต
- การสกัด
- การประเมิน
- เขียนผลลัพธ์
ส่วนประกอบเหล่านี้ใช้สองประเภทหลัก: tfma.Extracts และ tfma.evaluators.Evaluation ประเภท tfma.Extracts แสดงถึงข้อมูลที่แยกออกมาในระหว่างการประมวลผลไปป์ไลน์ และอาจสอดคล้องกับตัวอย่างอย่างน้อย 1 ตัวอย่างสำหรับโมเดล tfma.evaluators.Evaluation แสดงถึงผลลัพธ์จากการประเมินสารสกัด ณ จุดต่างๆ ในระหว่างกระบวนการสกัด เพื่อจัดเตรียม API ที่ยืดหยุ่น ประเภทเหล่านี้เป็นเพียงการกำหนดคีย์ที่ถูกกำหนด (สงวนไว้สำหรับการใช้งาน) โดยการใช้งานที่แตกต่างกัน ประเภทมีการกำหนดดังนี้:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
โปรดทราบว่า tfma.Extracts จะไม่ถูกเขียนออกมาโดยตรง โดยจะต้องผ่านผู้ประเมินเสมอเพื่อสร้าง tfma.evaluators.Evaluation ราคาประเมิน จากนั้นจึงเขียนออกมา โปรดทราบด้วยว่า tfma.Extracts เป็น dicts ที่ถูกเก็บไว้ใน beam.pvalue.PCollection (เช่น beam.PTransform s ใช้เป็นอินพุต beam.pvalue.PCollection[tfma.Extracts] ) ในขณะที่ tfma.evaluators.Evaluation เป็น dict ที่มีค่า คือ beam.pvalue.PCollection s (เช่น beam.PTransform s ใช้ dict เองเป็นอาร์กิวเมนต์สำหรับอินพุต beam.value.PCollection ) กล่าวอีกนัยหนึ่ง tfma.evaluators.Evaluation จะใช้ในเวลาที่สร้างไปป์ไลน์ แต่ tfma.Extracts จะใช้ที่รันไทม์ของไปป์ไลน์
อ่านอินพุต
ระยะ ReadInputs ประกอบด้วยการแปลงที่รับอินพุตดิบ (tf.train.Example, CSV, ...) แล้วแปลงเป็นสารสกัด ปัจจุบันสารสกัดจะแสดงเป็นไบต์อินพุตดิบที่เก็บไว้ภายใต้ tfma.INPUT_KEY อย่างไรก็ตามสารสกัดสามารถอยู่ในรูปแบบใดก็ได้ที่เข้ากันได้กับไปป์ไลน์การแยก - ซึ่งหมายความว่าจะสร้าง tfma.Extracts เป็นเอาต์พุต และสารสกัดเหล่านั้นเข้ากันได้กับดาวน์สตรีม เครื่องสกัด ขึ้นอยู่กับเครื่องแยกต่างๆ ที่จะบันทึกสิ่งที่พวกเขาต้องการอย่างชัดเจน
การสกัด
กระบวนการแยกคือรายการของ beam.PTransform ที่รันเป็นอนุกรม ตัวแยกข้อมูลจะใช้ tfma.Extracts เป็นอินพุต และส่งคืน tfma.Extracts เป็นเอาต์พุต ตัวแยกข้อมูลทั่วไปทั่วไปคือ tfma.extractors.PredictExtractor ซึ่งใช้สารสกัดอินพุตที่สร้างโดยการแปลงอินพุตการอ่าน และรันผ่านแบบจำลองเพื่อสร้างสารสกัดการคาดการณ์ สามารถแทรกตัวแยกข้อมูลแบบกำหนดเองได้ทุกเมื่อหากการแปลงเป็นไปตาม tfma.Extracts in และ tfma.Extracts out API ตัวแยกข้อมูลถูกกำหนดดังนี้:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
ตัวแยกอินพุต
tfma.extractors.InputExtractor ใช้เพื่อแยกคุณสมบัติดิบ ป้ายกำกับดิบ และน้ำหนักตัวอย่างดิบจากบันทึก tf.train.Example เพื่อใช้ในการแบ่งส่วนเมตริกและการคำนวณ ตามค่าเริ่มต้น ค่าจะถูกเก็บไว้ภายใต้คีย์แยก features , labels และ example_weights ตามลำดับ ป้ายกำกับโมเดลเอาต์พุตเดี่ยวและน้ำหนักตัวอย่างจะถูกจัดเก็บโดยตรงเป็นค่า np.ndarray ป้ายกำกับโมเดลหลายเอาต์พุตและน้ำหนักตัวอย่างจะถูกจัดเก็บไว้เป็นคำสั่งของค่า np.ndarray (คีย์ตามชื่อเอาต์พุต) หากดำเนินการประเมินหลายแบบจำลอง ป้ายกำกับและน้ำหนักตัวอย่างจะถูกฝังเพิ่มเติมภายในคำสั่งอื่น (กำหนดคีย์ตามชื่อรุ่น)
เครื่องทำนายผล
tfma.extractors.PredictExtractor รันการคาดการณ์โมเดลและจัดเก็บไว้ภายใต้ predictions ที่สำคัญใน tfma.Extracts dict การทำนายโมเดลเอาต์พุตเดี่ยวจะถูกจัดเก็บโดยตรงเป็นค่าเอาต์พุตที่คาดการณ์ไว้ การทำนายโมเดลหลายเอาต์พุตจะถูกจัดเก็บเป็นคำสั่งของค่าเอาต์พุต (คีย์ตามชื่อเอาต์พุต) หากทำการประเมินหลายแบบจำลอง การคาดคะเนจะถูกฝังเพิ่มเติมภายในคำสั่งอื่น (กำหนดคีย์ตามชื่อรุ่น) ค่าเอาต์พุตจริงที่ใช้ขึ้นอยู่กับโมเดล (เช่น เอาต์พุตส่งคืนของตัวประมาณค่า TF ในรูปแบบของ dict ในขณะที่ keras ส่งคืนค่า np.ndarray )
SliceKeyExtractor
tfma.extractors.SliceKeyExtractor ใช้ข้อมูลจำเพาะของการแบ่งส่วนเพื่อกำหนดว่าส่วนใดที่ใช้กับอินพุตตัวอย่างแต่ละรายการตามคุณลักษณะที่แยกออกมา และเพิ่มค่าการแบ่งส่วนที่สอดคล้องกันให้กับการแตกข้อมูลเพื่อใช้ในภายหลังโดยผู้ประเมิน
การประเมิน
การประเมินเป็นกระบวนการในการดึงข้อมูลออกมาและประเมินผล แม้ว่าจะเป็นเรื่องปกติที่จะดำเนินการประเมินที่ส่วนท้ายของไปป์ไลน์การสกัด แต่ก็มีกรณีการใช้งานที่ต้องมีการประเมินตั้งแต่เนิ่นๆ ในกระบวนการสกัด เนื่องจากผู้ประเมินดังกล่าวมีความเกี่ยวข้องกับผู้แยกข้อมูลซึ่งควรประเมินผลลัพธ์ด้วย ผู้ประเมินถูกกำหนดไว้ดังนี้:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
โปรดสังเกตว่าผู้ประเมินคือ beam.PTransform ที่รับ tfma.Extracts เป็นอินพุต ไม่มีอะไรที่จะหยุดการดำเนินการจากการดำเนินการแปลงเพิ่มเติมในการแยกข้อมูลซึ่งเป็นส่วนหนึ่งของกระบวนการประเมิน ต่างจากตัวแยกข้อมูลที่ต้องส่งคืน tfma.Extracts dict ไม่มีข้อจำกัดเกี่ยวกับประเภทของเอาต์พุตที่ผู้ประเมินสามารถสร้างได้ แม้ว่าผู้ประเมินส่วนใหญ่จะส่งคืน dict เช่นกัน (เช่น ชื่อและค่าเมตริก)
MetricsAndPlotsEvaluator
tfma.evaluators.MetricsAndPlotsEvaluator ใช้ features labels และ predictions เป็นอินพุต เรียกใช้ผ่าน tfma.slicer.FanoutSlices เพื่อจัดกลุ่มตามส่วนต่างๆ จากนั้นจึงดำเนินการวัดและคำนวณการคำนวณ สร้างเอาต์พุตในรูปแบบของพจนานุกรมของเมทริกและพล็อตคีย์และค่า (ซึ่งต่อมาจะถูกแปลงเป็นโปรโตแบบอนุกรมสำหรับเอาต์พุตโดย tfma.writers.MetricsAndPlotsWriter )
เขียนผลลัพธ์
ขั้นตอน WriteResults คือจุดที่เอาต์พุตการประเมินถูกเขียนลงดิสก์ WriteResults ใช้ตัวเขียนเพื่อเขียนข้อมูลตามคีย์เอาต์พุต ตัวอย่างเช่น tfma.evaluators.Evaluation Valuators การประเมินอาจมีคีย์สำหรับ metrics และ plots สิ่งเหล่านี้จะเชื่อมโยงกับพจนานุกรมหน่วยเมตริกและแปลงที่เรียกว่า 'เมตริก' และ 'แปลง' ผู้เขียนระบุวิธีการเขียนแต่ละไฟล์:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
เรามี tfma.writers.MetricsAndPlotsWriter ที่จะแปลงตัววัดและแปลงพจนานุกรมเป็นโปรโตแบบอนุกรมและเขียนลงดิสก์
หากคุณต้องการใช้รูปแบบการทำให้เป็นอนุกรมอื่น คุณสามารถสร้างตัวเขียนแบบกำหนดเองและใช้รูปแบบนั้นแทนได้ เนื่องจาก tfma.evaluators.Evaluation ที่ส่งผ่านไปยังผู้เขียนจะมีเอาต์พุตสำหรับผู้ประเมินทั้งหมดที่รวมกัน การแปลงตัวช่วย tfma.writers.Write จึงมีไว้เพื่อให้ผู้เขียนสามารถใช้ในการใช้งาน ptransform เพื่อเลือก beam.PCollection ที่เหมาะสม PCollection โดยอิงจาก ปุ่มเอาต์พุต (ดูตัวอย่างด้านล่าง)
การปรับแต่ง
เมธอด tfma.run_model_analysis จะนำอาร์กิวเมนต์ extractors , evaluators และ writers มาใช้เพื่อกำหนดตัวแยกข้อมูล ผู้ประเมิน และผู้เขียนที่ใช้โดยไปป์ไลน์เอง หากไม่มีการระบุอาร์กิวเมนต์ tfma.default_extractors , tfma.default_evaluators และ tfma.default_writers จะถูกใช้เป็นค่าเริ่มต้น
เครื่องแยกแบบกำหนดเอง
หากต้องการสร้างตัวแยกข้อมูลแบบกำหนดเอง ให้สร้างประเภท tfma.extractors.Extractor ที่ล้อมรอบ beam.PTransform โดยใช้ tfma.Extracts เป็นอินพุต และส่งคืน tfma.Extracts เป็นเอาต์พุต ตัวอย่างของ extractor มีอยู่ภายใต้ tfma.extractors
ผู้ประเมินแบบกำหนดเอง
หากต้องการสร้างตัวประเมินแบบกำหนดเอง ให้สร้างประเภท tfma.evaluators.Evaluator ที่ล้อมรอบ beam.PTransform PTransform โดยรับ tfma.Extracts เป็นอินพุต และส่งคืน tfma.evaluators.Evaluation เป็นเอาต์พุต ผู้ประเมินขั้นพื้นฐานอาจเพียงแค่ใช้ tfma.Extracts ขาเข้าและส่งออกข้อมูลเหล่านั้นเพื่อเก็บไว้ในตาราง นี่คือสิ่งที่ tfma.evaluators.AnalysisTableEvaluator ทำจริงๆ ผู้ประเมินที่ซับซ้อนมากขึ้นอาจดำเนินการประมวลผลและรวบรวมข้อมูลเพิ่มเติม ดู tfma.evaluators.MetricsAndPlotsEvaluator เป็นตัวอย่าง
โปรดทราบว่า tfma.evaluators.MetricsAndPlotsEvaluator สามารถปรับแต่งเพื่อรองรับเมตริกที่กำหนดเองได้ (ดูรายละเอียดเพิ่มเติมใน เมตริก )
นักเขียนที่กำหนดเอง
หากต้องการสร้างตัวเขียนแบบกำหนดเอง ให้สร้างประเภท tfma.writers.Writer ที่ล้อม beam.PTransform โดยรับ tfma.evaluators.Evaluation เป็นอินพุต และส่งคืน beam.pvalue.PDone เป็นเอาต์พุต ต่อไปนี้เป็นตัวอย่างพื้นฐานของผู้เขียนสำหรับการเขียน TFRecords ที่มีเมตริก:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
ข้อมูลนำเข้าของผู้เขียนขึ้นอยู่กับผลลัพธ์ของผู้ประเมินที่เกี่ยวข้อง สำหรับตัวอย่างข้างต้น เอาต์พุตจะเป็นโปรโตแบบอนุกรมที่สร้างโดย tfma.evaluators.MetricsAndPlotsEvaluator ผู้เขียน tfma.evaluators.AnalysisTableEvaluator จะต้องรับผิดชอบในการเขียน beam.pvalue.PCollection ของ tfma.Extracts
โปรดทราบว่าผู้เขียนจะเชื่อมโยงกับเอาต์พุตของผู้ประเมินผ่านคีย์เอาต์พุตที่ใช้ (เช่น tfma.METRICS_KEY , tfma.ANALYSIS_KEY ฯลฯ)
ตัวอย่างทีละขั้นตอน
ต่อไปนี้เป็นตัวอย่างของขั้นตอนที่เกี่ยวข้องกับไปป์ไลน์การแยกและการประเมินผล เมื่อใช้ทั้ง tfma.evaluators.MetricsAndPlotsEvaluator และ tfma.evaluators.AnalysisTableEvaluator :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files