
| | |  הצג ב-GitHub הצג ב-GitHub | | |
YAMNet היא רשת עצבית עמוקה מאומנת מראש שיכולה לחזות אירועי אודיו מ -521 שיעורים , כגון צחוק, נביחות או צפירה.
במדריך זה תלמדו כיצד:
- טען והשתמש במודל YAMNet להסקת מסקנות.
- בנו דגם חדש באמצעות הטמעות YAMNet כדי לסווג צלילים של חתול וכלב.
- הערך וייצא את המודל שלך.
ייבוא TensorFlow וספריות אחרות
התחל בהתקנת TensorFlow I/O , שתקל עליך לטעון קבצי שמע מהדיסק.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
על YAMNet
YAMNet היא רשת עצבית מאומנת מראש המשתמשת בארכיטקטורת הקונבולציה הניתנת להפרדה של MobileNetV1. זה יכול להשתמש בצורת גל אודיו כקלט ולבצע תחזיות עצמאיות עבור כל אחד מ-521 אירועי האודיו מהקורפוס של AudioSet .
באופן פנימי, הדגם מחלץ "פריימים" מאות האודיו ומעבד קבוצות של פריימים אלו. גרסה זו של הדגם משתמשת במסגרות באורך 0.96 שניות ומחלצת פריים אחד כל 0.48 שניות.
המודל מקבל מערך float32 Tensor או NumPy 1-D המכיל צורת גל באורך שרירותי, המיוצג כדגימות חד-ערוציות (מונו) של 16 קילו-הרץ בטווח [-1.0, +1.0] . מדריך זה מכיל קוד שיעזור לך להמיר קבצי WAV לפורמט הנתמך.
המודל מחזיר 3 פלטים, כולל ציוני הכיתה, הטמעות (בהן תשתמשו ללמידה בהעברה) והספקטרוגרמה של log mel . תוכל למצוא פרטים נוספים כאן .
שימוש ספציפי אחד ב-YAMNet הוא כמחלץ תכונות ברמה גבוהה - פלט הטבעה ב-1,024 מימדים. אתה תשתמש בתכונות הקלט של מודל הבסיס (YAMNet) ותזין אותם לתוך המודל הרדוד יותר שלך המורכב משכבה אחת נסתרת tf.keras.layers.Dense . לאחר מכן, תאמן את הרשת על כמות קטנה של נתונים לסיווג אודיו מבלי להידרש להרבה נתונים מסומנים והדרכה מקצה לקצה. (זה דומה להעברת למידה לסיווג תמונה עם TensorFlow Hub למידע נוסף.)
ראשית, תבדוק את המודל ותראה את התוצאות של סיווג אודיו. לאחר מכן תבנה את צינור עיבוד הנתונים מראש.
טוען YAMNet מ- TensorFlow Hub
אתה הולך להשתמש ב-YAMNet מאומן מראש מ- Tensorflow Hub כדי לחלץ את ההטבעות מקבצי הקול.
טעינת דגם מ- TensorFlow Hub היא פשוטה: בחר את הדגם, העתק את כתובת האתר שלו והשתמש בפונקציית load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
כשהדגם טעון, אתה יכול לעקוב אחר מדריך השימוש הבסיסי של YAMNet ולהוריד קובץ WAV לדוגמה כדי להפעיל את ההסקה.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
תזדקק לפונקציה לטעינת קבצי אודיו, שתשמש גם בהמשך בעבודה עם נתוני האימון. (למידע נוסף על קריאת קובצי שמע והתוויות שלהם בזיהוי שמע פשוט .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

טען את מיפוי הכיתה
חשוב לטעון את שמות המחלקות ש-YAMNet מסוגל לזהות. קובץ המיפוי קיים ב- yamnet_model.class_map_path() בפורמט CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
הפעל מסקנות
YAMNet מספקת ציוני כיתה ברמת המסגרת (כלומר, 521 ציונים לכל מסגרת). על מנת לקבוע תחזיות ברמת הקליפ, ניתן לצבור את הציונים לכל מחלקה על פני מסגרות (למשל, באמצעות צבירה ממוצעת או מקסימלית). זה נעשה להלן על ידי scores_np.mean(axis=0) . לבסוף, כדי למצוא את הכיתה עם הניקוד הגבוה ביותר ברמת הקליפ, אתה לוקח את המקסימום של 521 הציונים המצטברים.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
מערך נתונים של ESC-50
מערך הנתונים של ESC-50 ( Piczak, 2015 ) הוא אוסף מתויג של 2,000 הקלטות אודיו סביבתיות באורך חמש שניות. מערך הנתונים מורכב מ-50 מחלקות, עם 40 דוגמאות לכל מחלקה.
הורד את מערך הנתונים וחלץ אותו.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
חקור את הנתונים
המטא נתונים עבור כל קובץ מצוינים בקובץ ה-csv בכתובת ./datasets/ESC-50-master/meta/esc50.csv
וכל קבצי האודיו נמצאים ב-. ./datasets/ESC-50-master/audio/ /ESC-50-master/audio/
אתה תיצור פנדה DataFrame עם המיפוי ותשתמש בזה כדי לקבל תצוגה ברורה יותר של הנתונים.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
סנן את הנתונים
כעת, כשהנתונים מאוחסנים ב- DataFrame , החל כמה טרנספורמציות:
- סנן שורות והשתמש רק במחלקות שנבחרו -
dogcat. אם אתה רוצה להשתמש בשיעורים אחרים, זה המקום שבו אתה יכול לבחור אותם. - שנה את שם הקובץ כדי לקבל את הנתיב המלא. זה יקל על הטעינה מאוחר יותר.
- שנה יעדים כך שיהיו בטווח מסוים. בדוגמה זו,
dogיישאר ב0, אבלcatיהפוך ל1במקום הערך המקורי שלו5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
טען את קבצי האודיו ואחזר הטמעות
כאן תחיל את ה- load_wav_16k_mono ותכין את נתוני ה-WAV עבור הדגם.
בעת חילוץ הטמעות מנתוני WAV, אתה מקבל מערך של צורות (N, 1024) כאשר N הוא מספר הפריימים ש-YAMNet מצא (אחת לכל 0.48 שניות של שמע).
הדגם שלך ישתמש בכל מסגרת כקלט אחד. לכן, עליך ליצור עמודה חדשה עם מסגרת אחת בכל שורה. עליך גם להרחיב את התוויות ואת עמודת fold כדי לשקף כהלכה את השורות החדשות הללו.
עמודת fold המורחבת שומרת על הערכים המקוריים. אתה לא יכול לערבב מסגרות כי בעת ביצוע הפיצולים, ייתכן בסופו של דבר יהיו לך חלקים מאותו אודיו בפיצולים שונים, מה שיהפוך את שלבי האימות והבדיקה שלך לפחות יעילים.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
פצל את הנתונים
אתה תשתמש בעמודת fold כדי לפצל את מערך הנתונים לקבוצות רכבת, אימות ובדיקות.
ESC-50 מסודר לחמישה fold של אימות צולב בגודל אחיד, כך שקליפים מאותו מקור מקורי נמצאים תמיד באותו fold - גלה עוד ב- ESC: ערכת נתונים לסיווג סאונד סביבתי .
השלב האחרון הוא להסיר את עמודת fold ממערך הנתונים מכיוון שאתה לא מתכוון להשתמש בו במהלך האימון.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
צור את הדגם שלך
עשית את רוב העבודה! לאחר מכן, הגדר מודל רצף פשוט מאוד עם שכבה אחת נסתרת ושתי יציאות לזיהוי חתולים וכלבים מצלילים.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
בואו נריץ את שיטת evaluate על נתוני הבדיקה רק כדי להיות בטוחים שאין התאמה יתר.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
עשית את זה!
בדוק את הדגם שלך
לאחר מכן, נסה את הדגם שלך על ההטמעה מהבדיקה הקודמת באמצעות YAMNet בלבד.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
שמור דגם שיכול לקחת ישירות קובץ WAV כקלט
המודל שלך עובד כשאתה נותן לו את ההטמעות כקלט.
בתרחיש אמיתי, תרצה להשתמש בנתוני אודיו כקלט ישיר.
לשם כך, תשלב את YAMNet עם הדגם שלך לדגם אחד שתוכל לייצא עבור יישומים אחרים.
כדי להקל על השימוש בתוצאת המודל, השכבה הסופית תהיה פעולת reduce_mean . בעת שימוש במודל זה להגשה (עליו תלמדו בהמשך המדריך), תצטרכו את שם השכבה הסופית. אם לא תגדיר אחד, TensorFlow יגדיר אוטומטית אחד מצטבר שמקשה על הבדיקה, מכיוון שהוא ימשיך להשתנות בכל פעם שתאמן את הדגם. בעת שימוש בפעולת TensorFlow גולמית, לא ניתן להקצות לה שם. כדי לטפל בבעיה זו, תיצור שכבה מותאמת אישית שמחילה את reduce_mean ותקרא לה 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
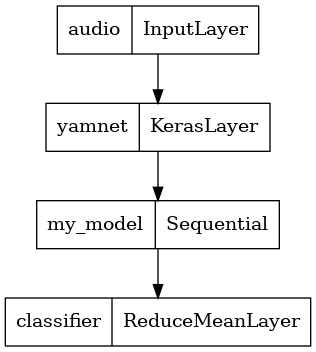
טען את הדגם השמור שלך כדי לוודא שהוא פועל כמצופה.
reloaded_model = tf.saved_model.load(saved_model_path)
ולמבחן האחרון: בהינתן כמה נתוני סאונד, האם הדגם שלך מחזיר את התוצאה הנכונה?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
אם אתה רוצה לנסות את הדגם החדש שלך בהגדרת הגשה, אתה יכול להשתמש בחתימת 'serving_default'.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(אופציונלי) עוד כמה בדיקות
הדגם מוכן.
הבה נשווה את זה ל-YAMNet במערך הנתונים של הבדיקה.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
הצעדים הבאים
יצרת מודל שיכול לסווג צלילים מכלבים או חתולים. עם אותו רעיון ומערך נתונים אחר תוכלו לנסות, למשל, לבנות מזהה אקוסטי של ציפורים על סמך שירתם.
שתף את הפרויקט שלך עם צוות TensorFlow במדיה החברתית!