
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह मार्गदर्शिका प्रजातियों के आधार पर आइरिस के फूलों को वर्गीकृत करने के लिए मशीन लर्निंग का उपयोग करती है। यह TensorFlow का उपयोग करता है:
- मॉडल बनाना,
- उदाहरण डेटा पर इस मॉडल को प्रशिक्षित करें, और
- अज्ञात डेटा के बारे में भविष्यवाणी करने के लिए मॉडल का उपयोग करें।
टेंसरफ्लो प्रोग्रामिंग
यह मार्गदर्शिका इन उच्च-स्तरीय TensorFlow अवधारणाओं का उपयोग करती है:
- TensorFlow के डिफ़ॉल्ट उत्सुक निष्पादन विकास वातावरण का उपयोग करें,
- डेटासेट एपीआई के साथ डेटा आयात करें,
- TensorFlow के Keras API के साथ मॉडल और परतें बनाएं।
यह ट्यूटोरियल कई TensorFlow प्रोग्रामों की तरह संरचित है:
- डेटासेट आयात और पार्स करें।
- मॉडल के प्रकार का चयन करें।
- मॉडल को प्रशिक्षित करें।
- मॉडल की प्रभावशीलता का मूल्यांकन करें।
- भविष्यवाणी करने के लिए प्रशिक्षित मॉडल का उपयोग करें।
सेटअप कार्यक्रम
आयात कॉन्फ़िगर करें
TensorFlow और अन्य आवश्यक पायथन मॉड्यूल आयात करें। डिफ़ॉल्ट रूप से, TensorFlow तुरंत संचालन का मूल्यांकन करने के लिए उत्सुक निष्पादन का उपयोग करता है, बाद में निष्पादित एक कम्प्यूटेशनल ग्राफ बनाने के बजाय ठोस मान लौटाता है। यदि आप एक आरईपीएल या python इंटरेक्टिव कंसोल के लिए उपयोग किए जाते हैं, तो यह परिचित लगता है।
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
आईरिस वर्गीकरण समस्या
कल्पना कीजिए कि आप एक वनस्पति विज्ञानी हैं जो आपको मिलने वाले प्रत्येक आईरिस फूल को वर्गीकृत करने के लिए एक स्वचालित तरीका ढूंढ रहे हैं। मशीन लर्निंग फूलों को सांख्यिकीय रूप से वर्गीकृत करने के लिए कई एल्गोरिदम प्रदान करता है। उदाहरण के लिए, एक परिष्कृत मशीन लर्निंग प्रोग्राम तस्वीरों के आधार पर फूलों को वर्गीकृत कर सकता है। हमारी महत्वाकांक्षाएं अधिक विनम्र हैं - हम आइरिस के फूलों को उनके बाह्यदलों और पंखुड़ियों की लंबाई और चौड़ाई के माप के आधार पर वर्गीकृत करने जा रहे हैं।
आईरिस जीनस में लगभग 300 प्रजातियां शामिल हैं, लेकिन हमारा कार्यक्रम केवल निम्नलिखित तीन को वर्गीकृत करेगा:
- आइरिस सेटोसा
- आइरिस वर्जिनिका
- आईरिस वर्सिकलर
 |
| चित्र 1. आइरिस सेटोसा ( रेडोमिल द्वारा, सीसी बाय-एसए 3.0 द्वारा), आइरिस वर्सीकलर, ( डालंग्लॉइस द्वारा, सीसी बाय-एसए 3.0), और आइरिस वर्जिनिका ( फ्रैंक मेफील्ड द्वारा, सीसी बाय-एसए 2.0)। |
सौभाग्य से, किसी ने सीपल और पंखुड़ी माप के साथ 120 आईरिस फूलों का एक डेटासेट पहले ही बना लिया है। यह एक क्लासिक डेटासेट है जो शुरुआती मशीन लर्निंग वर्गीकरण समस्याओं के लिए लोकप्रिय है।
प्रशिक्षण डेटासेट आयात और पार्स करें
डेटासेट फ़ाइल डाउनलोड करें और इसे एक संरचना में परिवर्तित करें जिसका उपयोग इस पायथन प्रोग्राम द्वारा किया जा सकता है।
डेटासेट डाउनलोड करें
tf.keras.utils.get_file फ़ंक्शन का उपयोग करके प्रशिक्षण डेटासेट फ़ाइल डाउनलोड करें। यह डाउनलोड की गई फ़ाइल का फ़ाइल पथ लौटाता है:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
डेटा का निरीक्षण करें
यह डेटासेट, iris_training.csv , एक सादा पाठ फ़ाइल है जो सारणीबद्ध डेटा को अल्पविराम से अलग किए गए मानों (CSV) के रूप में स्वरूपित करता है। पहली पांच प्रविष्टियों पर एक नज़र डालने के लिए head -n5 कमांड का उपयोग करें:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
डेटासेट के इस दृष्टिकोण से, निम्नलिखित पर ध्यान दें:
- पहली पंक्ति एक हेडर है जिसमें डेटासेट के बारे में जानकारी होती है:
- कुल 120 उदाहरण हैं। प्रत्येक उदाहरण में चार विशेषताएं हैं और तीन संभावित लेबल नामों में से एक है।
- बाद की पंक्तियाँ डेटा रिकॉर्ड हैं, प्रति पंक्ति एक उदाहरण , जहाँ:
आइए इसे कोड में लिखें:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
प्रत्येक लेबल स्ट्रिंग नाम से जुड़ा होता है (उदाहरण के लिए, "सेटोसा"), लेकिन मशीन लर्निंग आमतौर पर संख्यात्मक मानों पर निर्भर करता है। लेबल नंबर एक नामित प्रतिनिधित्व के लिए मैप किए जाते हैं, जैसे:
-
0: आइरिस सेटोसा -
1: आईरिस वर्सिकलर -
2: आईरिस वर्जिनिका
सुविधाओं और लेबल के बारे में अधिक जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स का एमएल शब्दावली अनुभाग देखें।
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
एक tf.data.Dataset बनाएँ
TensorFlow का डेटासेट API एक मॉडल में डेटा लोड करने के लिए कई सामान्य मामलों को संभालता है। यह डेटा पढ़ने और इसे प्रशिक्षण के लिए उपयोग किए जाने वाले रूप में बदलने के लिए एक उच्च स्तरीय एपीआई है।
चूंकि डेटासेट एक CSV-स्वरूपित टेक्स्ट फ़ाइल है, इसलिए डेटा को उपयुक्त प्रारूप में पार्स करने के लिए tf.data.experimental.make_csv_dataset फ़ंक्शन का उपयोग करें। चूंकि यह फ़ंक्शन प्रशिक्षण मॉडल के लिए डेटा उत्पन्न करता है, डिफ़ॉल्ट व्यवहार डेटा को फेरबदल करना है ( shuffle=True, shuffle_buffer_size=10000 ), और डेटासेट को हमेशा के लिए दोहराएं ( num_epochs=None )। हम बैच_साइज़ पैरामीटर भी सेट करते हैं:
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
make_csv_dataset फ़ंक्शन एक tf.data.Dataset देता है। (features, label) जोड़े का डेटासेट, जहां features एक शब्दकोश है: {'feature_name': value}
ये Dataset ऑब्जेक्ट चलने योग्य हैं। आइए सुविधाओं के एक बैच को देखें:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
ध्यान दें कि समान-सुविधाओं को एक साथ समूहीकृत किया जाता है, या बैच किया जाता है। प्रत्येक उदाहरण पंक्ति के क्षेत्रों को संबंधित फीचर सरणी में जोड़ा जाता है। इन सुविधा सरणियों में संग्रहीत उदाहरणों की संख्या निर्धारित करने के लिए batch_size बदलें।
आप बैच से कुछ सुविधाओं को प्लॉट करके कुछ क्लस्टर देखना शुरू कर सकते हैं:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
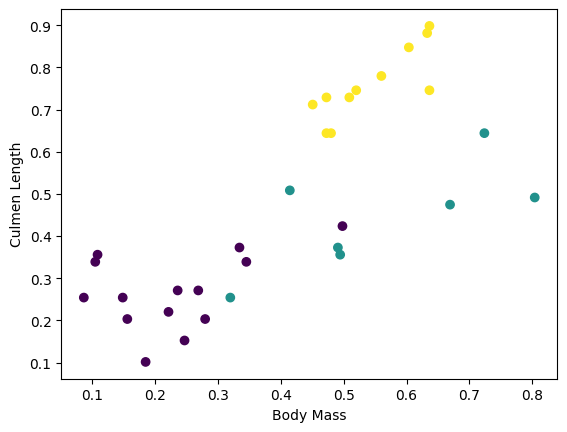
मॉडल निर्माण चरण को सरल बनाने के लिए, फीचर डिक्शनरी को आकार के साथ एक सरणी में दोबारा पैक करने के लिए एक फ़ंक्शन बनाएं: (batch_size, num_features) ।
यह फ़ंक्शन tf.stack विधि का उपयोग करता है जो टेंसर की सूची से मान लेता है और निर्दिष्ट आयाम पर एक संयुक्त टेंसर बनाता है:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
फिर प्रशिक्षण डेटासेट में प्रत्येक (features,label) जोड़ी की features को पैक करने के लिए tf.data.Dataset#map विधि का उपयोग करें:
train_dataset = train_dataset.map(pack_features_vector)
Dataset के फ़ीचर तत्व अब आकार के साथ सरणियाँ हैं (batch_size, num_features) । आइए पहले कुछ उदाहरण देखें:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
मॉडल के प्रकार का चयन करें
मॉडल क्यों?
एक मॉडल सुविधाओं और लेबल के बीच का संबंध है। आईरिस वर्गीकरण समस्या के लिए, मॉडल सेपल और पंखुड़ी माप और अनुमानित आईरिस प्रजातियों के बीच संबंध को परिभाषित करता है। कुछ सरल मॉडल को बीजगणित की कुछ पंक्तियों के साथ वर्णित किया जा सकता है, लेकिन जटिल मशीन लर्निंग मॉडल में बड़ी संख्या में पैरामीटर होते हैं जिन्हें संक्षेप में प्रस्तुत करना मुश्किल होता है।
क्या आप मशीन लर्निंग का उपयोग किए बिना चार विशेषताओं और आइरिस प्रजातियों के बीच संबंध निर्धारित कर सकते हैं? अर्थात्, क्या आप एक मॉडल बनाने के लिए पारंपरिक प्रोग्रामिंग तकनीकों (उदाहरण के लिए, बहुत सारे सशर्त कथन) का उपयोग कर सकते हैं? शायद — यदि आपने किसी विशेष प्रजाति के लिए पंखुड़ी और बाह्यदल माप के बीच संबंधों को निर्धारित करने के लिए पर्याप्त समय तक डेटासेट का विश्लेषण किया है। और यह कठिन हो जाता है—शायद असंभव—अधिक जटिल डेटासेट पर। एक अच्छा मशीन लर्निंग दृष्टिकोण आपके लिए मॉडल निर्धारित करता है । यदि आप पर्याप्त प्रतिनिधि उदाहरणों को सही मशीन लर्निंग मॉडल प्रकार में फीड करते हैं, तो प्रोग्राम आपके लिए संबंधों का पता लगाएगा।
मॉडल का चयन करें
हमें प्रशिक्षित करने के लिए मॉडल के प्रकार का चयन करने की आवश्यकता है। कई प्रकार के मॉडल हैं और एक अच्छा चुनने का अनुभव होता है। यह ट्यूटोरियल आईरिस वर्गीकरण समस्या को हल करने के लिए एक तंत्रिका नेटवर्क का उपयोग करता है। तंत्रिका नेटवर्क सुविधाओं और लेबल के बीच जटिल संबंध ढूंढ सकते हैं। यह एक अत्यधिक संरचित ग्राफ है, जो एक या अधिक छिपी परतों में व्यवस्थित होता है। प्रत्येक छिपी हुई परत में एक या अधिक न्यूरॉन्स होते हैं। तंत्रिका नेटवर्क की कई श्रेणियां हैं और यह प्रोग्राम घने, या पूरी तरह से जुड़े तंत्रिका नेटवर्क का उपयोग करता है: एक परत में न्यूरॉन्स पिछली परत में प्रत्येक न्यूरॉन से इनपुट कनेक्शन प्राप्त करते हैं। उदाहरण के लिए, चित्र 2 एक घने तंत्रिका नेटवर्क को दिखाता है जिसमें एक इनपुट परत, दो छिपी हुई परतें और एक आउटपुट परत होती है:
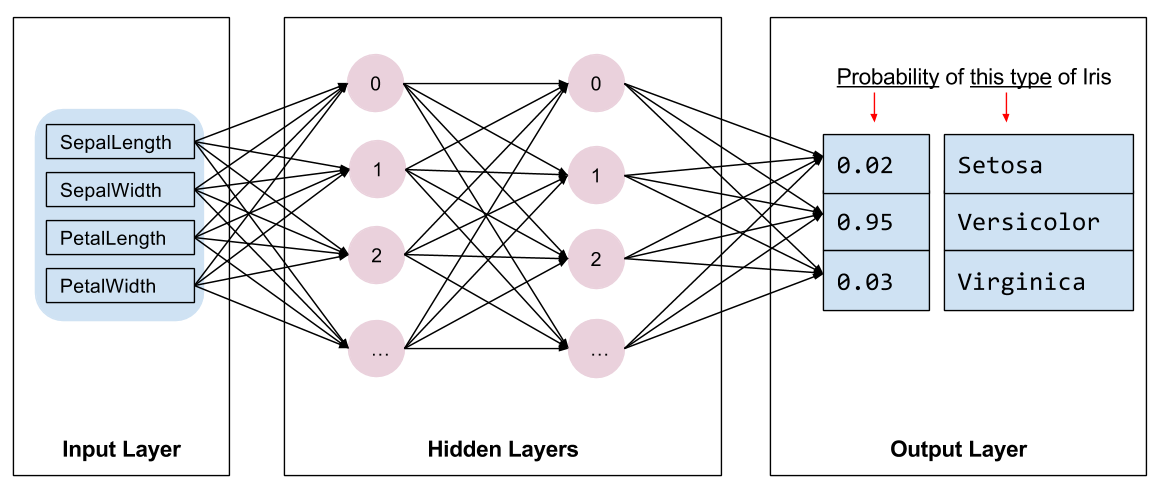 |
| चित्रा 2. सुविधाओं, छिपी परतों और भविष्यवाणियों के साथ एक तंत्रिका नेटवर्क। |
जब चित्र 2 के मॉडल को प्रशिक्षित किया जाता है और एक बिना लेबल वाला उदाहरण दिया जाता है, तो यह तीन भविष्यवाणियां देता है: संभावना है कि यह फूल दी गई आईरिस प्रजाति है। इस भविष्यवाणी को अनुमान कहा जाता है। इस उदाहरण के लिए, आउटपुट पूर्वानुमानों का योग 1.0 है। चित्रा 2 में, यह भविष्यवाणी इस प्रकार टूटती है: आईरिस सेटोसा के लिए 0.02 , आईरिस वर्सिकलर के लिए 0.95 , और आईरिस वर्जिनिका के लिए 0.03 । इसका मतलब यह है कि मॉडल भविष्यवाणी करता है - 95% संभावना के साथ - कि एक लेबल रहित उदाहरण फूल एक आईरिस वर्सिकलर है।
केरास का उपयोग करके एक मॉडल बनाएं
मॉडल और परतें बनाने के लिए TensorFlow tf.keras API पसंदीदा तरीका है। इससे मॉडल बनाना और प्रयोग करना आसान हो जाता है जबकि केरस सब कुछ एक साथ जोड़ने की जटिलता को संभालता है।
tf.keras.Sequential मॉडल परतों का एक रैखिक ढेर है। इसका कंस्ट्रक्टर परत उदाहरणों की एक सूची लेता है, इस मामले में, दो tf.keras.layers.Dense परतें जिनमें प्रत्येक में 10 नोड होते हैं, और एक आउटपुट परत होती है जिसमें 3 नोड्स होते हैं जो हमारे लेबल भविष्यवाणियों का प्रतिनिधित्व करते हैं। पहली परत का input_shape पैरामीटर डेटासेट से सुविधाओं की संख्या से मेल खाता है, और यह आवश्यक है:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
सक्रियण फ़ंक्शन परत में प्रत्येक नोड के आउटपुट आकार को निर्धारित करता है। ये गैर-रैखिकताएं महत्वपूर्ण हैं- इनके बिना मॉडल एक परत के बराबर होगा। कई tf.keras.activations हैं, लेकिन छिपी हुई परतों के लिए ReLU सामान्य है।
छिपी हुई परतों और न्यूरॉन्स की आदर्श संख्या समस्या और डेटासेट पर निर्भर करती है। मशीन लर्निंग के कई पहलुओं की तरह, तंत्रिका नेटवर्क का सबसे अच्छा आकार चुनने के लिए ज्ञान और प्रयोग के मिश्रण की आवश्यकता होती है। एक नियम के रूप में, छिपी हुई परतों और न्यूरॉन्स की संख्या में वृद्धि आम तौर पर एक अधिक शक्तिशाली मॉडल बनाती है, जिसे प्रभावी ढंग से प्रशिक्षित करने के लिए अधिक डेटा की आवश्यकता होती है।
मॉडल का उपयोग करना
आइए एक नज़र डालते हैं कि यह मॉडल सुविधाओं के एक बैच के साथ क्या करता है:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
प्लेसहोल्डर22यहां, प्रत्येक उदाहरण प्रत्येक वर्ग के लिए एक लॉगिट देता है।
प्रत्येक वर्ग के लिए इन लॉग्स को प्रायिकता में बदलने के लिए, सॉफ्टमैक्स फ़ंक्शन का उपयोग करें:
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
tf.argmax को सभी वर्गों में लेने से हमें अनुमानित वर्ग अनुक्रमणिका मिलती है। लेकिन, मॉडल को अभी तक प्रशिक्षित नहीं किया गया है, इसलिए ये अच्छी भविष्यवाणियां नहीं हैं:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
प्लेसहोल्डर26मॉडल को प्रशिक्षित करें
प्रशिक्षण मशीन सीखने का चरण है जब मॉडल को धीरे-धीरे अनुकूलित किया जाता है, या मॉडल डेटासेट सीखता है। लक्ष्य अनदेखी डेटा के बारे में भविष्यवाणियां करने के लिए प्रशिक्षण डेटासेट की संरचना के बारे में पर्याप्त सीखना है। यदि आप प्रशिक्षण डेटासेट के बारे में बहुत अधिक सीखते हैं, तो भविष्यवाणियां केवल उस डेटा के लिए काम करती हैं जिसे उसने देखा है और सामान्यीकरण योग्य नहीं होगा। इस समस्या को ओवरफिटिंग कहा जाता है - यह किसी समस्या को हल करने के तरीके को समझने के बजाय उत्तरों को याद रखने जैसा है।
आइरिस वर्गीकरण समस्या पर्यवेक्षित मशीन लर्निंग का एक उदाहरण है: मॉडल को उन उदाहरणों से प्रशिक्षित किया जाता है जिनमें लेबल होते हैं। अनुपयोगी मशीन लर्निंग में, उदाहरणों में लेबल नहीं होते हैं। इसके बजाय, मॉडल आमतौर पर सुविधाओं के बीच पैटर्न ढूंढता है।
नुकसान और ग्रेडिएंट फ़ंक्शन को परिभाषित करें
प्रशिक्षण और मूल्यांकन दोनों चरणों को मॉडल के नुकसान की गणना करने की आवश्यकता है। यह मापता है कि मॉडल की भविष्यवाणियां वांछित लेबल से कितनी दूर हैं, दूसरे शब्दों में, मॉडल कितना खराब प्रदर्शन कर रहा है। हम इस मान को कम करना या अनुकूलित करना चाहते हैं।
हमारा मॉडल tf.keras.losses.SparseCategoricalCrossentropy फ़ंक्शन का उपयोग करके इसके नुकसान की गणना करेगा जो मॉडल की वर्ग संभाव्यता भविष्यवाणियों और वांछित लेबल को लेता है, और उदाहरणों में औसत नुकसान देता है।
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
अपने मॉडल को अनुकूलित करने के लिए उपयोग किए गए ग्रेडिएंट की गणना करने के लिए tf.GradientTape संदर्भ का उपयोग करें:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
एक अनुकूलक बनाएं
एक अनुकूलक loss फ़ंक्शन को कम करने के लिए मॉडल के चर के लिए गणना किए गए ग्रेडिएंट लागू करता है। आप हानि फलन को एक घुमावदार सतह के रूप में सोच सकते हैं (चित्र 3 देखें)। ढाल सबसे तेज चढ़ाई की दिशा में इंगित करते हैं—इसलिए हम विपरीत दिशा में यात्रा करेंगे और पहाड़ी से नीचे जाएंगे। प्रत्येक बैच के नुकसान और ढाल की गणना करके, हम प्रशिक्षण के दौरान मॉडल को समायोजित करेंगे। धीरे-धीरे, मॉडल को नुकसान को कम करने के लिए वज़न और पूर्वाग्रह का सबसे अच्छा संयोजन मिलेगा। और नुकसान जितना कम होगा, मॉडल की भविष्यवाणी उतनी ही बेहतर होगी।
 |
| चित्रा 3. 3डी अंतरिक्ष में समय के साथ देखे गए अनुकूलन एल्गोरिदम। (स्रोत: स्टैनफोर्ड क्लास CS231n , MIT लाइसेंस, इमेज क्रेडिट: एलेक रेडफोर्ड ) |
TensorFlow में प्रशिक्षण के लिए कई अनुकूलन एल्गोरिदम उपलब्ध हैं। यह मॉडल tf.keras.optimizers.SGD का उपयोग करता है जो स्टोकेस्टिक ग्रेडिएंट डिसेंट (SGD) एल्गोरिथम को लागू करता है। learning_rate पहाड़ी के नीचे प्रत्येक पुनरावृत्ति के लिए चरण आकार निर्धारित करता है। यह एक हाइपरपैरामीटर है जिसे आप आमतौर पर बेहतर परिणाम प्राप्त करने के लिए समायोजित करेंगे।
आइए ऑप्टिमाइज़र सेट करें:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
हम इसका उपयोग एकल अनुकूलन चरण की गणना के लिए करेंगे:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932प्लेसहोल्डर33
प्रशिक्षण पाश
सभी टुकड़ों के साथ, मॉडल प्रशिक्षण के लिए तैयार है! एक प्रशिक्षण लूप बेहतर भविष्यवाणियां करने में मदद करने के लिए डेटासेट उदाहरणों को मॉडल में फीड करता है। निम्नलिखित कोड ब्लॉक इन प्रशिक्षण चरणों को सेट करता है:
- प्रत्येक युग को पुनरावृत्त करें। एक युग डेटासेट के माध्यम से एक पास है।
- एक युग के भीतर, प्रशिक्षण
Datasetमें प्रत्येक उदाहरण पर इसकी विशेषताओं (x) और लेबल (y) को हथियाने के लिए पुनरावृति करें। - उदाहरण की विशेषताओं का उपयोग करते हुए, एक भविष्यवाणी करें और इसकी तुलना लेबल से करें। भविष्यवाणी की अशुद्धि को मापें और इसका उपयोग मॉडल के नुकसान और ग्रेडिएंट की गणना करने के लिए करें।
- मॉडल के चरों को अद्यतन करने के लिए एक
optimizerका उपयोग करें। - विज़ुअलाइज़ेशन के लिए कुछ आँकड़ों पर नज़र रखें।
- प्रत्येक युग के लिए दोहराएं।
num_epochs वैरिएबल डेटासेट संग्रह पर लूप करने की संख्या है। प्रति-सहज रूप से, एक मॉडल को लंबे समय तक प्रशिक्षित करना बेहतर मॉडल की गारंटी नहीं देता है। num_epochs एक हाइपरपैरामीटर है जिसे आप ट्यून कर सकते हैं। सही संख्या चुनने के लिए आमतौर पर अनुभव और प्रयोग दोनों की आवश्यकता होती है:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
समय के साथ हानि फ़ंक्शन की कल्पना करें
हालांकि यह मॉडल की प्रशिक्षण प्रगति को प्रिंट करने में मददगार है, लेकिन इस प्रगति को देखना अक्सर अधिक सहायक होता है। TensorBoard एक अच्छा विज़ुअलाइज़ेशन टूल है जो TensorFlow के साथ पैक किया गया है, लेकिन हम matplotlib मॉड्यूल का उपयोग करके बुनियादी चार्ट बना सकते हैं।
इन चार्टों की व्याख्या करने में कुछ अनुभव होता है, लेकिन आप वास्तव में नुकसान को कम होते देखना चाहते हैं और सटीकता में वृद्धि करना चाहते हैं:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
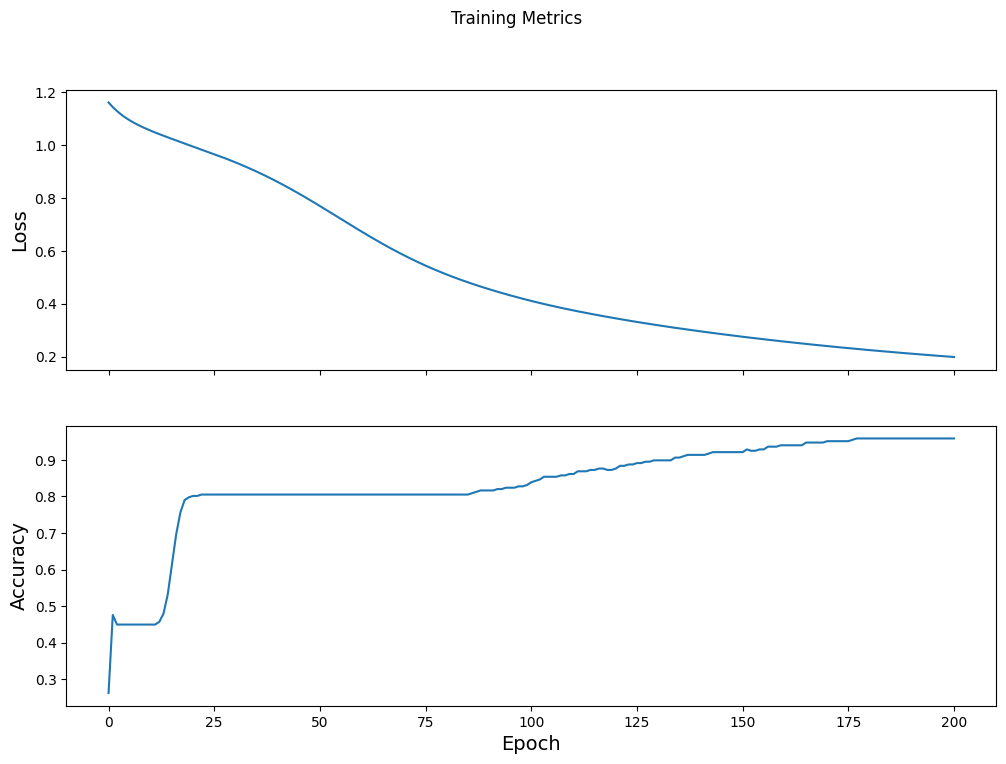
मॉडल की प्रभावशीलता का मूल्यांकन करें
अब जब मॉडल प्रशिक्षित हो गया है, तो हम इसके प्रदर्शन के कुछ आंकड़े प्राप्त कर सकते हैं।
मूल्यांकन का मतलब यह निर्धारित करना है कि मॉडल कितनी प्रभावी ढंग से भविष्यवाणियां करता है। आइरिस वर्गीकरण में मॉडल की प्रभावशीलता को निर्धारित करने के लिए, मॉडल को कुछ सीपल और पंखुड़ी माप पास करें और मॉडल से यह अनुमान लगाने के लिए कहें कि वे किस आईरिस प्रजाति का प्रतिनिधित्व करते हैं। फिर वास्तविक लेबल के विरुद्ध मॉडल की भविष्यवाणियों की तुलना करें। उदाहरण के लिए, एक मॉडल जिसने आधे इनपुट उदाहरणों पर सही प्रजाति चुनी है, उसकी सटीकता 0.5 है। चित्र 4 थोड़ा अधिक प्रभावी मॉडल दिखाता है, जिसमें 5 में से 4 भविष्यवाणियां 80% सटीकता पर सही होती हैं:
| उदाहरण विशेषताएं | लेबल | मॉडल भविष्यवाणी | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| चित्रा 4. एक आईरिस क्लासिफायरियर जो 80% सटीक है। | |||||
परीक्षण डेटासेट सेट करें
मॉडल का मूल्यांकन मॉडल के प्रशिक्षण के समान है। सबसे बड़ा अंतर यह है कि उदाहरण प्रशिक्षण सेट के बजाय एक अलग परीक्षण सेट से आते हैं। किसी मॉडल की प्रभावशीलता का निष्पक्ष मूल्यांकन करने के लिए, किसी मॉडल का मूल्यांकन करने के लिए उपयोग किए जाने वाले उदाहरण मॉडल को प्रशिक्षित करने के लिए उपयोग किए गए उदाहरणों से भिन्न होने चाहिए।
परीक्षण Dataset के लिए सेटअप Dataset के प्रशिक्षण के लिए सेटअप के समान है। CSV टेक्स्ट फ़ाइल डाउनलोड करें और उस मान को पार्स करें, फिर उसमें थोड़ा फेरबदल करें:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
परीक्षण डेटासेट पर मॉडल का मूल्यांकन करें
प्रशिक्षण चरण के विपरीत, मॉडल केवल परीक्षण डेटा के एकल युग का मूल्यांकन करता है। निम्नलिखित कोड सेल में, हम परीक्षण सेट में प्रत्येक उदाहरण पर पुनरावृति करते हैं और वास्तविक लेबल के विरुद्ध मॉडल की भविष्यवाणी की तुलना करते हैं। इसका उपयोग पूरे परीक्षण सेट में मॉडल की सटीकता को मापने के लिए किया जाता है:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
हम पिछले बैच पर देख सकते हैं, उदाहरण के लिए, मॉडल आमतौर पर सही होता है:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
भविष्यवाणी करने के लिए प्रशिक्षित मॉडल का उपयोग करें
हमने एक मॉडल को प्रशिक्षित किया है और "सिद्ध" किया है कि यह अच्छा है - लेकिन सही नहीं है - आइरिस प्रजातियों को वर्गीकृत करने में। अब बिना लेबल वाले उदाहरणों पर कुछ भविष्यवाणियां करने के लिए प्रशिक्षित मॉडल का उपयोग करते हैं; यानी ऐसे उदाहरणों पर जिनमें विशेषताएं तो हैं लेकिन लेबल नहीं हैं।
वास्तविक जीवन में, लेबल न किए गए उदाहरण कई अलग-अलग स्रोतों से आ सकते हैं जिनमें ऐप्स, CSV फ़ाइलें और डेटा फ़ीड शामिल हैं। अभी के लिए, हम उनके लेबल की भविष्यवाणी करने के लिए तीन गैर-लेबल वाले उदाहरण मैन्युअल रूप से प्रदान करने जा रहे हैं। याद रखें, लेबल नंबरों को एक नामित प्रतिनिधित्व के रूप में मैप किया जाता है:
-
0: आइरिस सेटोसा -
1: आईरिस वर्सिकलर -
2: आईरिस वर्जिनिका
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)