
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מדגים כיצד לבנות ולאמן רשת יריבות מותנית (cGAN) הנקראת pix2pix שלומדת מיפוי מתמונות קלט לתמונות פלט, כמתואר בתרגום תמונה לתמונה עם רשתות יריבות מותנות מאת Isola et al. (2017). pix2pix אינו ספציפי ליישום - ניתן ליישם אותו על מגוון רחב של משימות, כולל סינתזה של תמונות ממפות תוויות, יצירת תמונות צבעוניות מתמונות בשחור-לבן, הפיכת תמונות מפות גוגל לתמונות אוויר ואפילו הפיכת סקיצות לתמונות.
בדוגמה זו, הרשת שלך תייצר תמונות של חזיתות בניינים באמצעות מאגר חזיתות CMP שסופק על ידי המרכז לתפיסת מכונה באוניברסיטה הטכנית הצ'כית בפראג . כדי לשמור את זה קצר, תשתמש בעותק מעובד מראש של מערך הנתונים הזה שנוצר על ידי מחברי pix2pix.
ב-pix2pix cGAN, אתה מתנה על תמונות קלט ויוצר תמונות פלט מתאימות. cGANs הוצעו לראשונה ב- Conditional Generative Adversarial Nets (Mirza and Osindero, 2014)
הארכיטקטורה של הרשת שלך תכיל:
- גנרטור עם ארכיטקטורה מבוססת U-Net .
- מפלה המיוצג על ידי מסווג PatchGAN convolutional (מוצע בעיתון pix2pix ).
שימו לב שכל תקופה יכולה להימשך כ-15 שניות ב-V100 GPU יחיד.
להלן כמה דוגמאות של הפלט שנוצר על ידי pix2pix cGAN לאחר אימון במשך 200 עידנים על מערך הנתונים של החזיתות (80 אלף שלבים).


ייבוא TensorFlow וספריות אחרות
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
טען את מערך הנתונים
הורד את נתוני מסד הנתונים של CMP Facade (30MB). מערכי נתונים נוספים זמינים באותו פורמט כאן . ב-Colab אתה יכול לבחור מערכי נתונים אחרים מהתפריט הנפתח. שים לב שחלק ממערכי הנתונים האחרים גדולים משמעותית ( edges2handbags הוא 8GB).
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
כל תמונה מקורית היא בגודל 256 x 512 המכילה שתי תמונות 256 x 256 :
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
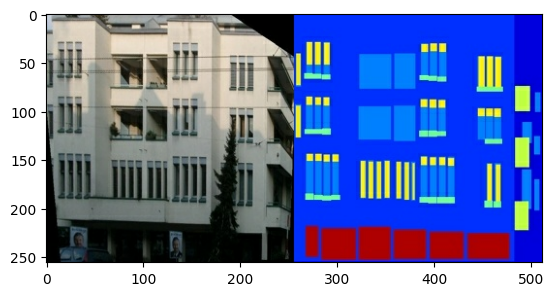
עליך להפריד תמונות חזית של בניין אמיתיות מתמונות תווית האדריכלות - כולן יהיו בגודל 256 x 256 .
הגדר פונקציה שטוענת קבצי תמונה ומוציאה שני טנסורי תמונה:
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
צייר דוגמה של הקלט (תמונת תווית אדריכלות) ותמונות אמיתיות (תמונת חזית הבניין):
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
כפי שמתואר בנייר pix2pix , עליך להחיל ריצוד ושיקוף אקראי כדי לעבד מראש את ערכת האימונים.
הגדירו מספר פונקציות ש:
- שנה את הגודל של כל תמונה
256 x 256לגובה ורוחב גדולים יותר -286 x 286. - חתוך אותו באופן אקראי ל
256 x 256. - הפוך את התמונה באופן אקראי, כלומר משמאל לימין (שיקוף אקראי).
- נרמל את התמונות לטווח
[-1, 1].
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
אתה יכול לבדוק חלק מהפלט המעובד מראש:
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
לאחר שבדקנו שהטעינה והעיבוד המקדים עובדים, הבה נגדיר כמה פונקציות מסייעות הטוענות ומעבדות מראש את מערכי ההדרכה והבדיקות:
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
בנה צינור קלט עם tf.data
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
בנה את הגנרטור
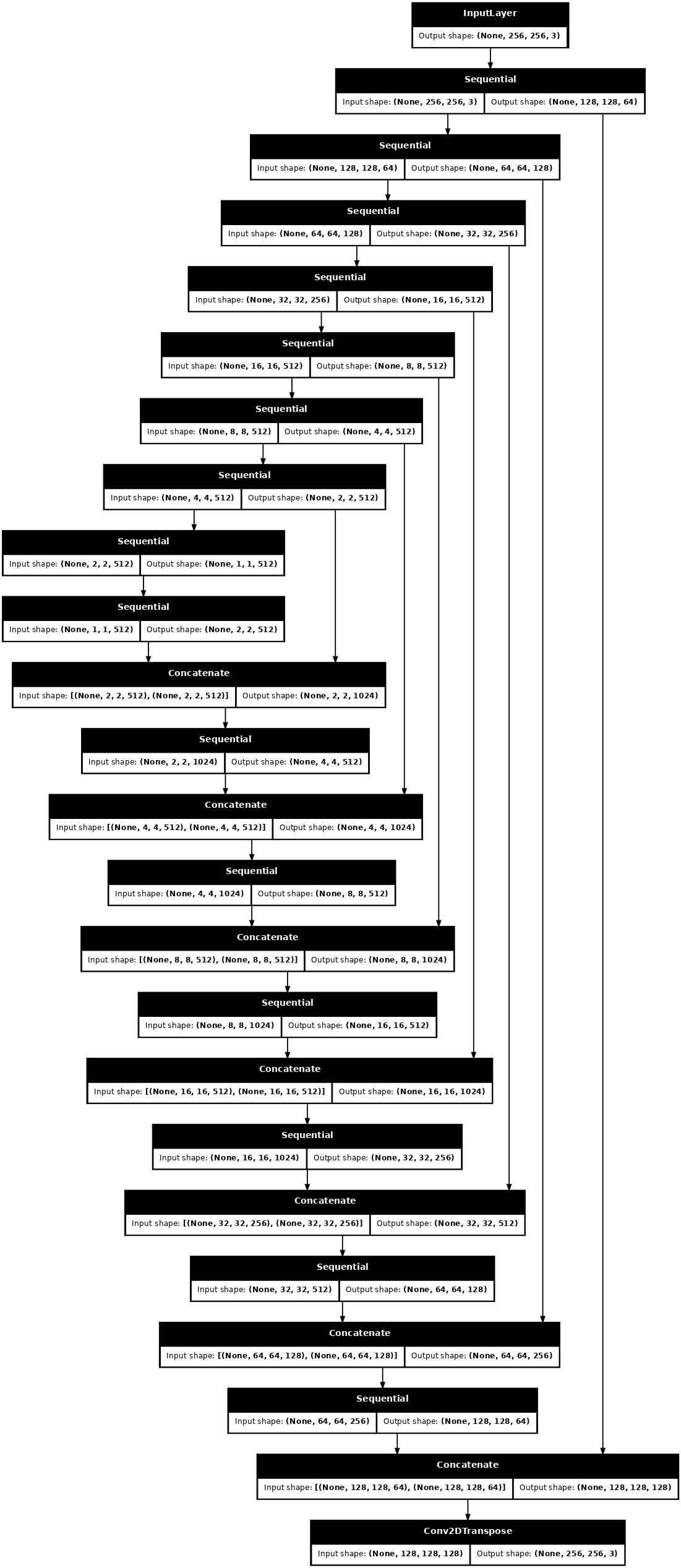
המחולל של pix2pix cGAN שלך הוא U-Net שונה . רשת U-Net מורכבת מקודד (Downsampler) ומפענח (Upsampler). (תוכלו לברר על כך במדריך פילוח תמונות ובאתר פרויקט U-Net .)
- כל בלוק במקודד הוא: Convolution -> נורמליזציה של אצווה -> Leaky ReLU
- כל בלוק במפענח הוא: טרנספוזיציה -> נורמליזציה של אצווה -> נשירה (מוחל על 3 הבלוקים הראשונים) -> ReLU
- ישנם חיבורי דילוג בין המקודד למפענח (כמו ב-U-Net).
הגדר את ה-downsampler (מקודד):
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
הגדר את ה-upsampler (מפענח):
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
הגדר את המחולל עם ה-downsampler וה-upsampler:
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
דמיינו את ארכיטקטורת מודל המחולל:
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
בדוק את הגנרטור:
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
הגדר את אובדן הגנרטור
GANs לומדים הפסד שמסתגל לנתונים, בעוד cGANs לומדים הפסד מובנה שמעניש מבנה אפשרי השונה מפלט הרשת ותמונת היעד, כפי שמתואר בנייר pix2pix .
- אובדן המחולל הוא אובדן סיגמואידי צולב אנטרופיה של התמונות שנוצרו ושל מערך של אלה .
- נייר pix2pix מזכיר גם את אובדן L1, שהוא MAE (ממוצע שגיאה מוחלטת) בין התמונה שנוצרה לתמונת היעד.
- זה מאפשר לתמונה שנוצרה להיות דומה מבחינה מבנית לתמונת היעד.
- הנוסחה לחישוב הפסד הגנרטור הכולל היא
gan_loss + LAMBDA * l1_loss, כאשרLAMBDA = 100. ערך זה הוחלט על ידי מחברי המאמר.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
הליך ההכשרה של הגנרטור הוא כדלקמן:

בנה את המפלה
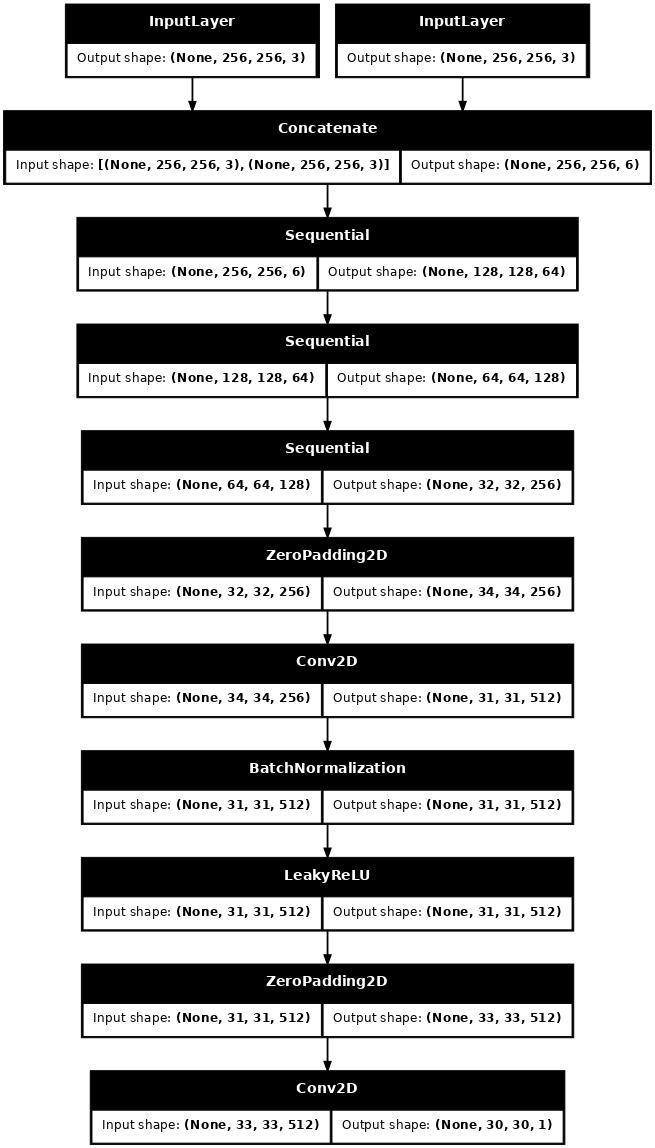
המאבחן ב-pix2pix cGAN הוא מסווג PatchGAN convolution - הוא מנסה לסווג אם כל תיקון תמונה אמיתי או לא אמיתי, כפי שמתואר בעיתון pix2pix .
- כל בלוק במאפיין הוא: Convolution -> נורמליזציה של אצווה -> Leaky ReLU.
- צורת הפלט אחרי השכבה האחרונה היא
(batch_size, 30, 30, 1). - כל תיקון תמונה
30 x 30של הפלט מסווג חלק70 x 70של תמונת הקלט. - המאבחן מקבל 2 כניסות:
- תמונת הקלט ותמונת היעד, שאותם היא צריכה לסווג כאמיתית.
- תמונת הקלט והתמונה שנוצרה (הפלט של המחולל), שאותן הוא צריך לסווג כזיוף.
- השתמש
tf.concat([inp, tar], axis=-1)כדי לשרשר את 2 הכניסות הללו יחד.
בואו נגדיר את המפלה:
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
דמיינו את ארכיטקטורת מודל המפלה:
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
בדוק את המפלה:
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>
הגדר את אובדן המפלה
- הפונקציה
discriminator_lossלוקחת 2 כניסות: תמונות אמיתיות ותמונות שנוצרו . -
real_lossהוא אובדן צולב אנטרופיה סיגמואידי של התמונות האמיתיות ומערך של אלה (מכיוון שאלו הן התמונות האמיתיות) . -
generated_lossהוא אובדן צולב אנטרופיה סיגמואידי של התמונות שנוצרו ומערך של אפסים (מכיוון שאלו הן התמונות המזויפות) . - ה-
total_lossהוא הסכום שלreal_lossו-generated_loss.
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
הליך ההכשרה של המפלה מוצג להלן.
כדי ללמוד עוד על הארכיטקטורה ועל הפרמטרים ההיפר אתה יכול לעיין בנייר pix2pix .

הגדר את מטבי האופטימיזציה ושומר נקודות ביקורת
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
צור תמונות
כתוב פונקציה כדי לשרטט כמה תמונות במהלך האימון.
- העבירו תמונות ממערך המבחן לגנרטור.
- לאחר מכן, המחולל יתרגם את תמונת הקלט לפלט.
- השלב האחרון הוא לתכנן את התחזיות והלא !
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
בדוק את הפונקציה:
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

הַדְרָכָה
- עבור כל דוגמה קלט יוצר פלט.
- המאבחן מקבל את ה-
input_imageואת התמונה שנוצרה בתור הקלט הראשון. הקלט השני הואinput_imageו-target_image. - לאחר מכן, חשב את המחולל ואת אובדן המפלה.
- לאחר מכן, חשב את דרגות האובדן הן ביחס למחולל והן למשתנים (תשומות) המפלה והחל את אלה על האופטימיזר.
- לבסוף, רשום את ההפסדים ל-TensorBoard.
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
לולאת האימון בפועל. מכיוון שמדריך זה יכול להופיע על יותר ממערך נתונים אחד, ומערכי הנתונים משתנים מאוד בגודלם, לולאת האימון מוגדרת לעבוד בשלבים במקום בתקופות.
- חוזר על מספר השלבים.
- כל 10 שלבים מדפיסים נקודה (
.). - כל אלף שלבים: נקה את התצוגה והפעל את
generate_imagesכדי להציג את ההתקדמות. - כל 5,000 שלבים: שמור מחסום.
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
לולאת אימון זו שומרת יומנים שתוכל להציג ב-TensorBoard כדי לעקוב אחר התקדמות האימון.
אם אתה עובד על מכונה מקומית, תפעיל תהליך TensorBoard נפרד. כאשר עובדים במחברת, הפעל את הצופה לפני תחילת ההדרכה לניטור עם TensorBoard.
כדי להפעיל את הצופה הדבק את הדברים הבאים לתוך תא קוד:
%load_ext tensorboard
%tensorboard --logdir {log_dir}
לבסוף, הפעל את לולאת האימון:
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
אם ברצונך לשתף את תוצאות TensorBoard בפומבי , תוכל להעלות את היומנים אל TensorBoard.dev על ידי העתקת הדברים הבאים לתא קוד.
tensorboard dev upload --logdir {log_dir}
אתה יכול לראות את התוצאות של הפעלה קודמת של מחברת זו ב- TensorBoard.dev .
TensorBoard.dev היא חוויה מנוהלת לאירוח, מעקב ושיתוף של ניסויי ML עם כולם.
זה יכול גם לכלול בתוך שורה באמצעות <iframe> :
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
פירוש היומנים הוא עדין יותר בעת אימון GAN (או cGAN כמו pix2pix) בהשוואה למודל סיווג פשוט או רגרסיה. דברים שצריך לחפש:
- בדוק שלא הגנרטור ולא דגם המפלה "ניצחו". אם ה-
gen_gan_lossאוdisc_lossנמוכים מאוד, זה אינדיקציה לכך שהמודל הזה שולט באחר, ואתה לא מצליח לאמן את המודל המשולב. - הערך
log(2) = 0.69הוא נקודת התייחסות טובה להפסדים אלה, שכן הוא מצביע על תמיהה של 2 - המאבחן, בממוצע, לא בטוח באותה מידה לגבי שתי האפשרויות. - עבור
disc_loss, ערך מתחת ל0.69פירושו שהמאבחן מצליח יותר מאשר אקראי בקבוצה המשולבת של תמונות אמיתיות ומוצרות. - עבור
gen_gan_loss, ערך מתחת ל0.69פירושו שהמחולל מצליח יותר מאשר אקראי בהטעיית המפלה. - ככל שהאימונים מתקדמים, ההפסד של
gen_l1_lossאמור לרדת.
שחזר את נקודת הבידוק העדכנית ובדוק את הרשת
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.index
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
צור כמה תמונות באמצעות ערכת הבדיקה
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




