
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह मार्गदर्शिका स्नीकर्स और शर्ट जैसे कपड़ों की छवियों को वर्गीकृत करने के लिए एक तंत्रिका नेटवर्क मॉडल को प्रशिक्षित करती है। यदि आप सभी विवरणों को नहीं समझते हैं तो कोई बात नहीं; यह एक संपूर्ण TensorFlow कार्यक्रम का एक तेज़-तर्रार अवलोकन है जिसमें आपके द्वारा बताए गए विवरण शामिल हैं।
यह मार्गदर्शिका TensorFlow में मॉडल बनाने और प्रशिक्षित करने के लिए tf.keras , एक उच्च-स्तरीय API का उपयोग करती है।
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0
फैशन एमएनआईएसटी डेटासेट आयात करें
यह मार्गदर्शिका फ़ैशन एमएनआईएसटी डेटासेट का उपयोग करती है जिसमें 10 श्रेणियों में 70,000 ग्रेस्केल छवियां शामिल हैं। छवियाँ कम रिज़ॉल्यूशन (28 गुणा 28 पिक्सेल) पर कपड़ों के अलग-अलग लेख दिखाती हैं, जैसा कि यहाँ देखा गया है:
| चित्रा 1. फैशन-एमएनआईएसटी नमूने (ज़ालैंडो, एमआईटी लाइसेंस द्वारा)। |
फैशन एमएनआईएसटी क्लासिक एमएनआईएसटी डेटासेट के लिए ड्रॉप-इन प्रतिस्थापन के रूप में अभिप्रेत है-अक्सर कंप्यूटर दृष्टि के लिए मशीन लर्निंग प्रोग्राम के "हैलो, वर्ल्ड" के रूप में उपयोग किया जाता है। MNIST डेटासेट में आपके द्वारा यहां उपयोग किए जाने वाले कपड़ों के लेखों के समान प्रारूप में हस्तलिखित अंकों (0, 1, 2, आदि) की छवियां होती हैं।
यह मार्गदर्शिका विविधता के लिए फैशन एमएनआईएसटी का उपयोग करती है, और क्योंकि यह नियमित एमएनआईएसटी की तुलना में थोड़ी अधिक चुनौतीपूर्ण समस्या है। दोनों डेटासेट अपेक्षाकृत छोटे हैं और यह सत्यापित करने के लिए उपयोग किया जाता है कि एक एल्गोरिथ्म अपेक्षित रूप से काम करता है। वे कोड का परीक्षण और डिबग करने के लिए अच्छे शुरुआती बिंदु हैं।
यहां, नेटवर्क को प्रशिक्षित करने के लिए 60,000 छवियों का उपयोग किया जाता है और 10,000 छवियों का उपयोग यह मूल्यांकन करने के लिए किया जाता है कि नेटवर्क ने छवियों को वर्गीकृत करना कितना सही सीखा। आप सीधे TensorFlow से Fashion MNIST को एक्सेस कर सकते हैं। सीधे टेंसरफ्लो से फैशन एमएनआईएसटी डेटा आयात और लोड करें :
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
डेटासेट लोड करना चार NumPy सरणियाँ लौटाता है:
-
train_imagesऔरtrain_labelsएरे प्रशिक्षण सेट हैं - वह डेटा जिसे मॉडल सीखने के लिए उपयोग करता है। - परीक्षण सेट ,
test_images, औरtest_labelsसरणियों के विरुद्ध मॉडल का परीक्षण किया जाता है।
चित्र 28x28 NumPy सरणियाँ हैं, जिनमें पिक्सेल मान 0 से 255 तक हैं। लेबल पूर्णांकों की एक सरणी है, जो 0 से 9 तक है। ये कपड़ों के उस वर्ग से मेल खाते हैं जो छवि दर्शाती है:
| लेबल | कक्षा |
|---|---|
| 0 | टी-शर्ट/टॉप |
| 1 | पतलून |
| 2 | पुल ओवर |
| 3 | पोशाक |
| 4 | कोट |
| 5 | चप्पल |
| 6 | कमीज |
| 7 | छिपकर जानेवाला |
| 8 | थैला |
| 9 | एडी तक पहुंचने वाला जूता |
प्रत्येक छवि को एकल लेबल पर मैप किया जाता है। चूंकि वर्ग के नाम डेटासेट में शामिल नहीं हैं, इसलिए छवियों को प्लॉट करते समय बाद में उपयोग करने के लिए उन्हें यहां स्टोर करें:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
डेटा का अन्वेषण करें
आइए मॉडल को प्रशिक्षित करने से पहले डेटासेट के प्रारूप का पता लगाएं। निम्नलिखित दिखाता है कि प्रशिक्षण सेट में 60,000 चित्र हैं, प्रत्येक छवि को 28 x 28 पिक्सेल के रूप में दर्शाया गया है:
train_images.shape
(60000, 28, 28)
इसी तरह, प्रशिक्षण सेट में 60,000 लेबल हैं:
len(train_labels)
60000
प्रत्येक लेबल 0 और 9 के बीच एक पूर्णांक है:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
परीक्षण सेट में 10,000 छवियां हैं। फिर से, प्रत्येक छवि को 28 x 28 पिक्सेल के रूप में दर्शाया गया है:
test_images.shape
(10000, 28, 28)
और परीक्षण सेट में 10,000 छवि लेबल होते हैं:
len(test_labels)
10000
डेटा को प्रीप्रोसेस करें
नेटवर्क को प्रशिक्षण देने से पहले डेटा को प्रीप्रोसेस किया जाना चाहिए। यदि आप प्रशिक्षण सेट में पहली छवि का निरीक्षण करते हैं, तो आप देखेंगे कि पिक्सेल मान 0 से 255 की सीमा में आते हैं:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
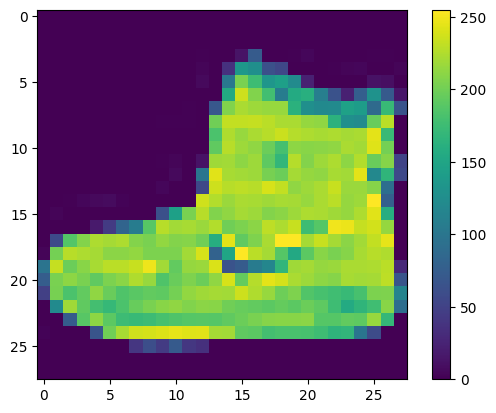
तंत्रिका नेटवर्क मॉडल को खिलाने से पहले इन मानों को 0 से 1 की सीमा तक स्केल करें। ऐसा करने के लिए, मानों को 255 से विभाजित करें। यह महत्वपूर्ण है कि प्रशिक्षण सेट और परीक्षण सेट को उसी तरह पूर्व-संसाधित किया जाए:
train_images = train_images / 255.0
test_images = test_images / 255.0
यह सत्यापित करने के लिए कि डेटा सही प्रारूप में है और आप नेटवर्क बनाने और प्रशिक्षित करने के लिए तैयार हैं, आइए प्रशिक्षण सेट से पहले 25 चित्र प्रदर्शित करें और प्रत्येक छवि के नीचे वर्ग का नाम प्रदर्शित करें।
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

मॉडल बनाएं
तंत्रिका नेटवर्क के निर्माण के लिए मॉडल की परतों को कॉन्फ़िगर करने, फिर मॉडल को संकलित करने की आवश्यकता होती है।
परतें सेट करें
तंत्रिका नेटवर्क का मूल निर्माण खंड परत है। परतें उनमें खिलाए गए डेटा से अभ्यावेदन निकालती हैं। उम्मीद है, ये प्रतिनिधित्व हाथ में समस्या के लिए सार्थक हैं।
अधिकांश गहरी शिक्षा में सरल परतों को एक साथ जोड़ना शामिल है। अधिकांश परतों, जैसे tf.keras.layers.Dense , में ऐसे पैरामीटर होते हैं जो प्रशिक्षण के दौरान सीखे जाते हैं।
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
इस नेटवर्क में पहली परत, tf.keras.layers.Flatten , छवियों के प्रारूप को दो-आयामी सरणी (28 गुणा 28 पिक्सेल) से एक-आयामी सरणी (28 * 28 = 784 पिक्सेल) में बदल देती है। इस लेयर को इमेज में पिक्सल की अनस्टैकिंग पंक्तियों और उन्हें लाइनिंग के रूप में सोचें। इस परत में सीखने के लिए कोई पैरामीटर नहीं है; यह केवल डेटा को पुन: स्वरूपित करता है।
पिक्सल के समतल होने के बाद, नेटवर्क में दो tf.keras.layers.Dense लेयर्स का एक क्रम होता है। ये घनी रूप से जुड़ी हुई हैं, या पूरी तरह से जुड़ी हुई हैं, तंत्रिका परतें। पहली Dense लेयर में 128 नोड (या न्यूरॉन्स) होते हैं। दूसरी (और आखिरी) परत 10 की लंबाई के साथ एक लॉगिट सरणी देता है। प्रत्येक नोड में एक स्कोर होता है जो इंगित करता है कि वर्तमान छवि 10 वर्गों में से एक से संबंधित है।
मॉडल संकलित करें
मॉडल के प्रशिक्षण के लिए तैयार होने से पहले, इसे कुछ और सेटिंग्स की आवश्यकता होती है। ये मॉडल के संकलन चरण के दौरान जोड़े जाते हैं:
- हानि कार्य - यह मापता है कि प्रशिक्षण के दौरान मॉडल कितना सटीक है। आप मॉडल को सही दिशा में "चलाने" के लिए इस फ़ंक्शन को छोटा करना चाहते हैं।
- ऑप्टिमाइज़र —इस तरह मॉडल को उसके द्वारा देखे गए डेटा और उसके नुकसान फ़ंक्शन के आधार पर अपडेट किया जाता है।
- मेट्रिक्स -प्रशिक्षण और परीक्षण चरणों की निगरानी के लिए उपयोग किया जाता है। निम्न उदाहरण सटीकता का उपयोग करता है, छवियों का वह अंश जिसे सही ढंग से वर्गीकृत किया गया है।
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
मॉडल को प्रशिक्षित करें
तंत्रिका नेटवर्क मॉडल के प्रशिक्षण के लिए निम्नलिखित चरणों की आवश्यकता होती है:
- मॉडल को प्रशिक्षण डेटा खिलाएं। इस उदाहरण में, प्रशिक्षण डेटा
train_imagesऔरtrain_labelsसरणियों में है। - मॉडल छवियों और लेबलों को संबद्ध करना सीखता है।
- आप मॉडल से एक परीक्षण सेट के बारे में भविष्यवाणी करने के लिए कहते हैं—इस उदाहरण में,
test_imagesसरणी। - सत्यापित करें कि भविष्यवाणियां
test_labelsसरणी के लेबल से मेल खाती हैं।
मॉडल को खिलाएं
प्रशिक्षण शुरू करने के लिए, model.fit मेथड को कॉल करें—तथाकथित क्योंकि यह प्रशिक्षण डेटा के लिए मॉडल को "फिट" करती है:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4986 - accuracy: 0.8253 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3751 - accuracy: 0.8651 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3364 - accuracy: 0.8769 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3124 - accuracy: 0.8858 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2949 - accuracy: 0.8913 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2776 - accuracy: 0.8977 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2669 - accuracy: 0.9022 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2552 - accuracy: 0.9046 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2463 - accuracy: 0.9089 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2376 - accuracy: 0.9117 <keras.callbacks.History at 0x7f5f2c785110>प्लेसहोल्डर22
जैसे ही मॉडल ट्रेन करता है, हानि और सटीकता मेट्रिक्स प्रदर्शित होते हैं। यह मॉडल प्रशिक्षण डेटा पर लगभग 0.91 (या 91%) की सटीकता तक पहुंचता है।
सटीकता का मूल्यांकन करें
इसके बाद, तुलना करें कि मॉडल परीक्षण डेटासेट पर कैसा प्रदर्शन करता है:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3176 - accuracy: 0.8895 - 553ms/epoch - 2ms/step Test accuracy: 0.8895000219345093
यह पता चला है कि परीक्षण डेटासेट पर सटीकता प्रशिक्षण डेटासेट की सटीकता से थोड़ी कम है। प्रशिक्षण सटीकता और परीक्षण सटीकता के बीच यह अंतर ओवरफिटिंग का प्रतिनिधित्व करता है। ओवरफिटिंग तब होती है जब मशीन लर्निंग मॉडल प्रशिक्षण डेटा की तुलना में नए, पहले अनदेखी इनपुट पर खराब प्रदर्शन करता है। एक ओवरफिट मॉडल प्रशिक्षण डेटासेट में शोर और विवरण को उस बिंदु तक "याद रखता है" जहां यह नए डेटा पर मॉडल के प्रदर्शन को नकारात्मक रूप से प्रभावित करता है। अधिक जानकारी के लिए, निम्नलिखित देखें:
अंदाजा लगाओ
प्रशिक्षित मॉडल के साथ, आप इसका उपयोग कुछ छवियों के बारे में भविष्यवाणी करने के लिए कर सकते हैं। मॉडल के लीनियर आउटपुट— लॉगिट —को प्रायिकता में बदलने के लिए एक सॉफ्टमैक्स परत संलग्न करें, जिसकी व्याख्या करना आसान होना चाहिए।
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
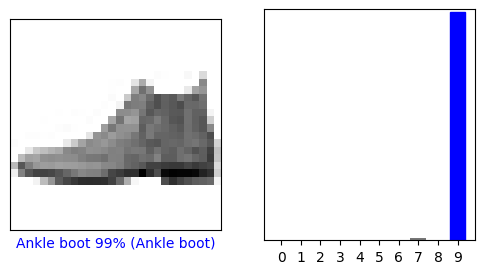
यहां, मॉडल ने परीक्षण सेट में प्रत्येक छवि के लिए लेबल की भविष्यवाणी की है। आइए एक नजर डालते हैं पहली भविष्यवाणी पर:
predictions[0]
array([1.3835326e-08, 2.7011181e-11, 2.6019606e-10, 5.6872784e-11,
1.2070331e-08, 4.1874609e-04, 1.1151612e-08, 5.7000564e-03,
8.1178889e-08, 9.9388099e-01], dtype=float32)
एक भविष्यवाणी 10 संख्याओं की एक सरणी है। वे मॉडल के "आत्मविश्वास" का प्रतिनिधित्व करते हैं कि छवि कपड़ों के 10 अलग-अलग लेखों में से प्रत्येक से मेल खाती है। आप देख सकते हैं कि किस लेबल का विश्वास मूल्य सबसे अधिक है:
np.argmax(predictions[0])
9
इसलिए, मॉडल को सबसे अधिक विश्वास है कि यह छवि टखने का बूट है, या class_names[9] । परीक्षण लेबल की जांच से पता चलता है कि यह वर्गीकरण सही है:
test_labels[0]
9
10 वर्ग भविष्यवाणियों के पूरे सेट को देखने के लिए इसे ग्राफ़ करें।
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
भविष्यवाणियों की पुष्टि करें
प्रशिक्षित मॉडल के साथ, आप इसका उपयोग कुछ छवियों के बारे में भविष्यवाणी करने के लिए कर सकते हैं।
आइए 0वीं छवि, भविष्यवाणियों और भविष्यवाणी सरणी को देखें। सही भविष्यवाणी लेबल नीले हैं और गलत भविष्यवाणी लेबल लाल हैं। संख्या अनुमानित लेबल के लिए प्रतिशत (100 में से) देती है।
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
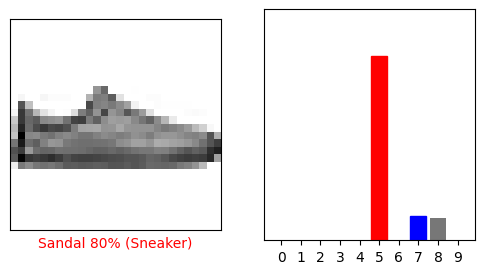
आइए उनकी भविष्यवाणियों के साथ कई चित्र बनाएं। ध्यान दें कि बहुत आश्वस्त होने पर भी मॉडल गलत हो सकता है।
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

प्रशिक्षित मॉडल का प्रयोग करें
अंत में, एकल छवि के बारे में भविष्यवाणी करने के लिए प्रशिक्षित मॉडल का उपयोग करें।
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
tf.keras मॉडल को एक बार में उदाहरणों के बैच , या संग्रह पर भविष्यवाणियां करने के लिए अनुकूलित किया जाता है। तदनुसार, भले ही आप एकल छवि का उपयोग कर रहे हों, आपको इसे एक सूची में जोड़ना होगा:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
अब इस छवि के लिए सही लेबल की भविष्यवाणी करें:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[8.26038831e-06 1.10213664e-13 9.98591125e-01 1.16777841e-08 1.29609776e-03 2.54965649e-11 1.04560357e-04 7.70050608e-19 4.55051066e-11 3.53864888e-17]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
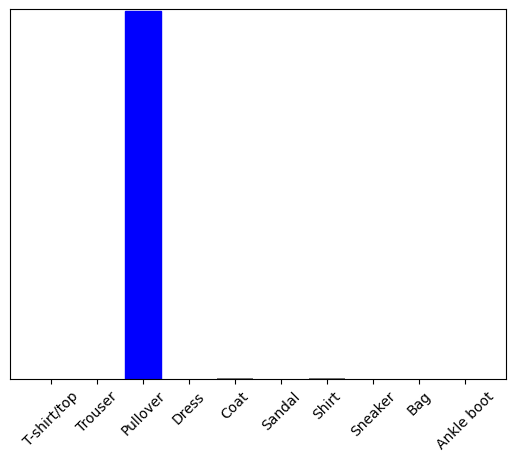
tf.keras.Model.predict सूचियों की एक सूची देता है—डेटा के बैच में प्रत्येक छवि के लिए एक सूची। बैच में हमारी (केवल) छवि के लिए पूर्वानुमान प्राप्त करें:
np.argmax(predictions_single[0])
2
और मॉडल अपेक्षा के अनुरूप एक लेबल की भविष्यवाणी करता है।
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.