
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu kılavuz, spor ayakkabı ve gömlek gibi giysi görüntülerini sınıflandırmak için bir sinir ağı modeli eğitiyor. Tüm detayları anlamadıysanız sorun değil; Bu, siz ilerledikçe açıklanan ayrıntılarla birlikte eksiksiz bir TensorFlow programına hızlı bir genel bakıştır.
Bu kılavuz, TensorFlow'da modeller oluşturmak ve eğitmek için üst düzey bir API olan tf.keras'ı kullanır.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0
Fashion MNIST veri setini içe aktarın
Bu kılavuz, 10 kategoride 70.000 gri tonlamalı görüntü içeren Fashion MNIST veri kümesini kullanır. Görüntüler, burada görüldüğü gibi düşük çözünürlükte (28 x 28 piksel) tek tek giyim eşyalarını göstermektedir:
| Şekil 1. Fashion-MNIST örnekleri (Zalando tarafından, MIT Lisansı). |
Fashion MNIST, genellikle bilgisayarla görme için makine öğrenimi programlarının "Merhaba Dünyası" olarak kullanılan klasik MNIST veri kümesinin yerini alacak şekilde tasarlanmıştır. MNIST veri kümesi, burada kullanacağınız giyim eşyalarının formatına benzer bir biçimde el yazısı rakamların (0, 1, 2, vb.) görüntülerini içerir.
Bu kılavuz, Fashion MNIST'i çeşitlilik için kullanır ve çünkü bu, normal MNIST'ten biraz daha zorlayıcı bir problemdir. Her iki veri kümesi de nispeten küçüktür ve bir algoritmanın beklendiği gibi çalıştığını doğrulamak için kullanılır. Kodu test etmek ve hata ayıklamak için iyi başlangıç noktalarıdır.
Burada, ağı eğitmek için 60.000 görüntü ve ağın görüntüleri sınıflandırmayı ne kadar doğru öğrendiğini değerlendirmek için 10.000 görüntü kullanılır. Fashion MNIST'e doğrudan TensorFlow'dan erişebilirsiniz. Fashion MNIST verilerini doğrudan TensorFlow'dan içe aktarın ve yükleyin :
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
Veri kümesini yüklemek, dört NumPy dizisi döndürür:
-
train_imagesvetrain_labelsdizileri, eğitim kümesidir - modelin öğrenmek için kullandığı veriler. - Model, test seti ,
test_imagesvetest_labelsdizilerine karşı test edilir.
Görüntüler, 0 ile 255 arasında değişen piksel değerlerine sahip 28x28 NumPy dizileridir. Etiketler , 0 ile 9 arasında değişen bir tamsayı dizisidir. Bunlar, görüntünün temsil ettiği giysi sınıfına karşılık gelir:
| Etiket | Sınıf |
|---|---|
| 0 | tişört/üst |
| 1 | pantolon |
| 2 | Kenara çekmek |
| 3 | Elbise |
| 4 | Kaban |
| 5 | Sandalet |
| 6 | Gömlek |
| 7 | Spor ayakkabı |
| 8 | Çanta |
| 9 | Bilek boyu bot |
Her görüntü tek bir etikete eşlenir. Sınıf adları veri kümesine dahil edilmediğinden, daha sonra görüntüleri çizerken kullanmak üzere bunları burada saklayın:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Verileri keşfedin
Modeli eğitmeden önce veri kümesinin biçimini keşfedelim. Aşağıdakiler, eğitim setinde her bir görüntünün 28 x 28 piksel olarak temsil edildiği 60.000 görüntü olduğunu göstermektedir:
train_images.shape
(60000, 28, 28)
Aynı şekilde eğitim setinde 60.000 adet etiket bulunmaktadır:
len(train_labels)
60000
Her etiket 0 ile 9 arasında bir tamsayıdır:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
Test setinde 10.000 adet görsel bulunmaktadır. Yine, her görüntü 28 x 28 piksel olarak temsil edilir:
test_images.shape
(10000, 28, 28)
Test seti 10.000 görüntü etiketi içerir:
len(test_labels)
10000
Verileri önceden işleyin
Ağı eğitmeden önce veriler önceden işlenmelidir. Eğitim setindeki ilk görüntüyü incelerseniz piksel değerlerinin 0 ile 255 aralığında olduğunu göreceksiniz:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
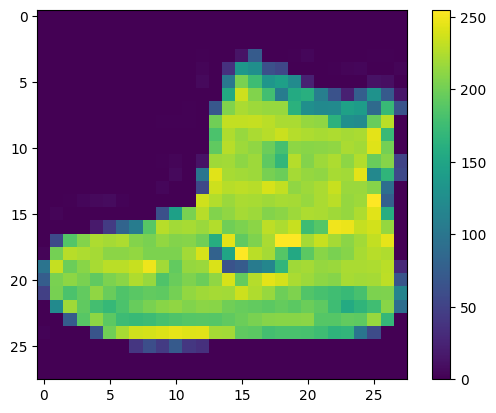
Sinir ağı modeline beslemeden önce bu değerleri 0 ile 1 arasında ölçeklendirin. Bunu yapmak için değerleri 255'e bölün. Eğitim setinin ve test setinin aynı şekilde ön işleme tabi tutulması önemlidir:
train_images = train_images / 255.0
test_images = test_images / 255.0
Verilerin doğru formatta olduğunu ve ağı kurmaya ve eğitmeye hazır olduğunuzu doğrulamak için, eğitim setinden ilk 25 görüntüyü görüntüleyelim ve her görüntünün altında sınıf adını görüntüleyelim.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Modeli oluşturun
Sinir ağının oluşturulması, modelin katmanlarının yapılandırılmasını ve ardından modelin derlenmesini gerektirir.
Katmanları ayarlayın
Bir sinir ağının temel yapı taşı katmandır . Katmanlar, kendilerine beslenen verilerden temsilleri çıkarır. Umarım, bu temsiller eldeki sorun için anlamlıdır.
Derin öğrenmenin çoğu, basit katmanları birbirine zincirlemekten oluşur. tf.keras.layers.Dense gibi çoğu katman, eğitim sırasında öğrenilen parametrelere sahiptir.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
Bu ağdaki ilk katman olan tf.keras.layers.Flatten , görüntülerin formatını iki boyutlu bir diziden (28 x 28 piksel) tek boyutlu bir diziye (28 * 28 = 784 piksel) dönüştürür. Bu katmanı, görüntüdeki piksel sıralarını kaldırmak ve bunları hizalamak olarak düşünün. Bu katmanın öğrenilecek parametresi yoktur; yalnızca verileri yeniden biçimlendirir.
Pikseller düzleştirildikten sonra ağ, iki tf.keras.layers.Dense katmanından oluşan bir diziden oluşur. Bunlar yoğun şekilde bağlı veya tamamen bağlı sinir katmanlarıdır. İlk Dense katmanda 128 düğüm (veya nöron) bulunur. İkinci (ve son) katman, 10 uzunluğunda bir logits dizisi döndürür. Her düğüm, geçerli görüntünün 10 sınıftan birine ait olduğunu gösteren bir puan içerir.
Modeli derleyin
Model eğitime hazır olmadan önce birkaç ayara daha ihtiyacı var. Bunlar, modelin derleme adımı sırasında eklenir:
- Kayıp işlevi —Bu, eğitim sırasında modelin ne kadar doğru olduğunu ölçer. Modeli doğru yöne "yönlendirmek" için bu işlevi en aza indirmek istiyorsunuz.
- Optimize Edici — Model, gördüğü verilere ve kayıp işlevine göre bu şekilde güncellenir.
- Metrikler —Eğitim ve test adımlarını izlemek için kullanılır. Aşağıdaki örnek, doğru sınıflandırılmış görüntülerin kesri olan doğruluk kullanır.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Modeli eğit
Sinir ağı modelinin eğitimi aşağıdaki adımları gerektirir:
- Eğitim verilerini modele besleyin. Bu örnekte, eğitim verileri
train_imagesvetrain_labelsdizilerindedir. - Model, görüntüleri ve etiketleri ilişkilendirmeyi öğrenir.
- Modelden bir test seti hakkında tahminler yapmasını istersiniz - bu örnekte
test_imagesdizisi. - Tahminlerin
test_labelsdizisindeki etiketlerle eşleştiğini doğrulayın.
Modeli besle
Eğitimi başlatmak için model.fit yöntemini çağırın; bu, modele eğitim verilerine "uydurduğu" için böyle adlandırılır:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4986 - accuracy: 0.8253 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3751 - accuracy: 0.8651 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3364 - accuracy: 0.8769 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3124 - accuracy: 0.8858 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2949 - accuracy: 0.8913 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2776 - accuracy: 0.8977 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2669 - accuracy: 0.9022 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2552 - accuracy: 0.9046 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2463 - accuracy: 0.9089 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2376 - accuracy: 0.9117 <keras.callbacks.History at 0x7f5f2c785110>
Model ilerlerken, kayıp ve doğruluk metrikleri görüntülenir. Bu model, eğitim verilerinde yaklaşık 0.91 (veya %91) doğruluğa ulaşır.
Doğruluğu değerlendirin
Ardından, modelin test veri kümesinde nasıl performans gösterdiğini karşılaştırın:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3176 - accuracy: 0.8895 - 553ms/epoch - 2ms/step Test accuracy: 0.8895000219345093
Test veri setindeki doğruluğun, eğitim veri setindeki doğruluktan biraz daha az olduğu ortaya çıktı. Eğitim doğruluğu ve test doğruluğu arasındaki bu boşluk, fazla uydurmayı temsil eder. Bir makine öğrenimi modeli, yeni, daha önce görülmemiş girdilerde eğitim verilerinde olduğundan daha kötü performans gösterdiğinde, aşırı uyum gerçekleşir. Fazla takılan bir model, eğitim veri kümesindeki gürültüyü ve ayrıntıları, modelin yeni veriler üzerindeki performansını olumsuz yönde etkileyecek bir noktaya "belleğe alır". Daha fazla bilgi için aşağıdakilere bakın:
tahminlerde bulunun
Eğitilen model ile bazı görüntüler hakkında tahminler yapmak için kullanabilirsiniz. Modelin doğrusal çıktılarını - logitleri - yorumlaması daha kolay olması gereken olasılıklara dönüştürmek için bir softmax katmanı ekleyin.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
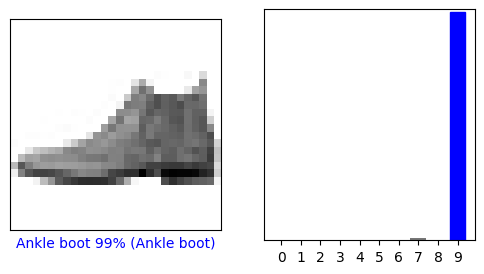
Burada model, test setindeki her görüntü için etiketi tahmin etmiştir. İlk tahmine bir göz atalım:
predictions[0]
array([1.3835326e-08, 2.7011181e-11, 2.6019606e-10, 5.6872784e-11,
1.2070331e-08, 4.1874609e-04, 1.1151612e-08, 5.7000564e-03,
8.1178889e-08, 9.9388099e-01], dtype=float32)
Tahmin, 10 sayıdan oluşan bir dizidir. Modelin, görüntünün 10 farklı giysi parçasının her birine karşılık geldiğine dair "güvenini" temsil ediyorlar. Hangi etiketin en yüksek güven değerine sahip olduğunu görebilirsiniz:
np.argmax(predictions[0])
9
Bu nedenle model, bu görüntünün bir ayak bileği botu veya class_names[9] olduğundan en çok emindir. Test etiketinin incelenmesi, bu sınıflandırmanın doğru olduğunu gösterir:
test_labels[0]
9
10 sınıf tahmininin tamamına bakmak için bunun grafiğini çizin.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Tahminleri doğrula
Eğitilen model ile bazı görüntüler hakkında tahminler yapmak için kullanabilirsiniz.
0. resme, tahminlere ve tahmin dizisine bakalım. Doğru tahmin etiketleri mavidir ve yanlış tahmin etiketleri kırmızıdır. Sayı, tahmin edilen etiketin yüzdesini (100 üzerinden) verir.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
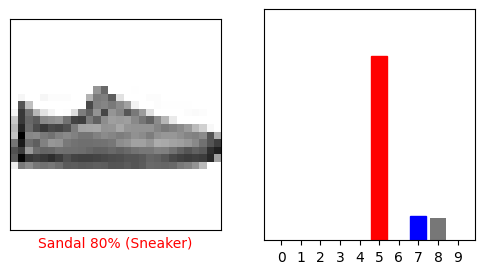
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
Tahminleriyle birlikte birkaç resim çizelim. Modelin kendinden çok emin olsa bile yanlış olabileceğini unutmayın.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

Eğitilmiş modeli kullanın
Son olarak, tek bir görüntü hakkında tahminde bulunmak için eğitilmiş modeli kullanın.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
tf.keras modelleri, bir kerede bir toplu iş veya örnek koleksiyonu üzerinde tahminler yapmak için optimize edilmiştir. Buna göre, tek bir görsel kullanıyor olsanız bile, onu bir listeye eklemeniz gerekiyor:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
Şimdi bu görüntü için doğru etiketi tahmin edin:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[8.26038831e-06 1.10213664e-13 9.98591125e-01 1.16777841e-08 1.29609776e-03 2.54965649e-11 1.04560357e-04 7.70050608e-19 4.55051066e-11 3.53864888e-17]]-yer tutucu42 l10n-yer
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
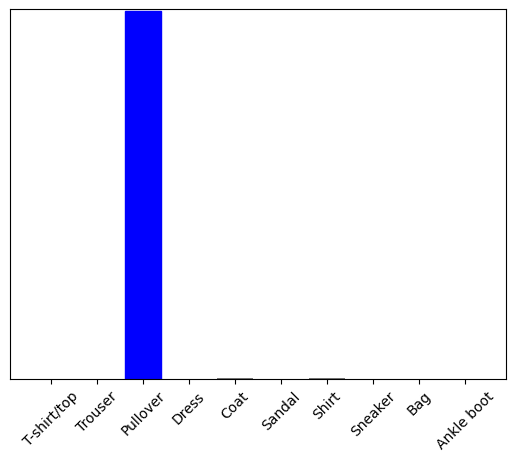
tf.keras.Model.predict , veri yığınındaki her görüntü için bir liste olmak üzere bir liste listesi döndürür. Partideki (yalnızca) resmimiz için tahminleri alın:
np.argmax(predictions_single[0])
2
Ve model beklendiği gibi bir etiket öngörüyor.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.