
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin |
Bu öğretici, CSV verilerinin TensorFlow ile nasıl kullanılacağına ilişkin örnekler sağlar.
Bunun iki ana kısmı vardır:
- Verileri diskten yükleme
- Eğitim için uygun bir forma ön işleme.
Bu öğretici, yüklemeye odaklanır ve bazı hızlı ön işleme örnekleri verir. Ön işleme yönüne odaklanan bir eğitim için, ön işleme katmanları kılavuzuna ve eğitimine bakın.
Kurmak
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
hafızadaki veriler
Herhangi bir küçük CSV veri kümesi için, üzerinde bir TensorFlow modelini eğitmenin en basit yolu, onu pandas Dataframe veya NumPy dizisi olarak belleğe yüklemektir.
Nispeten basit bir örnek, abalone veri kümesidir .
- Veri seti küçüktür.
- Tüm giriş özelliklerinin tümü sınırlı aralıklı kayan nokta değerleridir.
Verileri bir Pandas DataFrame nasıl indireceğiniz aşağıda açıklanmıştır:
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
Veri kümesi, bir tür deniz salyangozu olan deniz kulağının bir dizi ölçümünü içerir.

“Abalone shell” ( Nicki Dugan Pogue tarafından, CC BY-SA 2.0)
Bu veri kümesinin nominal görevi, yaşı diğer ölçümlerden tahmin etmektir, bu nedenle eğitim için özellikleri ve etiketleri ayırın:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
Bu veri seti için tüm özelliklere aynı şekilde davranacaksınız. Özellikleri tek bir NumPy dizisine paketleyin.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
Daha sonra yaşı tahmin eden bir regresyon modeli yapın. Tek giriş tensörü olduğundan burada keras.Sequential modeli yeterlidir.
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
Bu modeli eğitmek için özellikleri ve etiketleri Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
CSV verilerini kullanarak bir modeli eğitmenin en temel yolunu gördünüz. Ardından, sayısal sütunları normalleştirmek için ön işlemenin nasıl uygulanacağını öğreneceksiniz.
Temel ön işleme
Modelinizin girdilerini normalleştirmek iyi bir uygulamadır. Keras ön işleme katmanları, bu normalleştirmeyi modelinize yerleştirmek için uygun bir yol sağlar.
Katman, her sütunun ortalamasını ve varyansını önceden hesaplayacak ve bunları verileri normalleştirmek için kullanacaktır.
İlk önce katmanı oluşturursunuz:
normalize = layers.Normalization()
Ardından, normalleştirme katmanını verilerinize uyarlamak için Normalization.adapt() yöntemini kullanırsınız.
normalize.adapt(abalone_features)
Ardından modelinizde normalleştirme katmanını kullanın:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
Karışık veri türleri
"Titanic" veri kümesi, Titanik'teki yolcular hakkında bilgi içerir. Bu veri setindeki nominal görev, kimin hayatta kaldığını tahmin etmektir.

Wikimedia'dan görüntü
{kind=link}
Ham veriler Pandas DataFrame olarak kolayca yüklenebilir, ancak bir TensorFlow modeline girdi olarak hemen kullanılamaz.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
Farklı veri türleri ve aralıkları nedeniyle, özellikleri basitçe NumPy dizisine yığamaz ve onu bir keras.Sequential modeline geçiremezsiniz. Her sütunun ayrı ayrı ele alınması gerekir.
Bir seçenek olarak, kategorik sütunları sayısal sütunlara dönüştürmek için verilerinizi çevrimdışı olarak (istediğiniz herhangi bir aracı kullanarak) önceden işleyebilir ve ardından işlenen çıktıyı TensorFlow modelinize iletebilirsiniz. Bu yaklaşımın dezavantajı, modelinizi kaydedip dışa aktarırsanız, ön işlemenin onunla birlikte kaydedilmemesidir. Keras ön işleme katmanları, modelin bir parçası oldukları için bu sorunu önler.
Bu örnekte, Keras işlevsel API'sini kullanarak ön işleme mantığını uygulayan bir model oluşturacaksınız. Alt sınıflama yaparak da yapabilirsiniz.
İşlevsel API, "sembolik" tensörler üzerinde çalışır. Normal "istekli" tensörlerin bir değeri vardır. Buna karşılık, bu "sembolik" tensörler yoktur. Bunun yerine, üzerlerinde hangi işlemlerin yürütüldüğünü takip ederler ve daha sonra çalıştırabileceğiniz hesaplamanın temsilini oluştururlar. İşte hızlı bir örnek:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
Ön işleme modelini oluşturmak için, CSV sütunlarının adlarını ve veri türlerini eşleştirerek bir dizi sembolik keras.Input nesnesi oluşturarak başlayın.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
Ön işleme mantığınızdaki ilk adım, sayısal girdileri bir araya getirmek ve bunları bir normalleştirme katmanından geçirmektir:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
Daha sonra birleştirmek için tüm sembolik ön işleme sonuçlarını toplayın.
preprocessed_inputs = [all_numeric_inputs]
Dize girişleri için, bir sözlükteki dizelerden tamsayı endekslerine eşlemek için tf.keras.layers.StringLookup işlevini kullanın. Ardından, dizinleri modele uygun float32 verilerine dönüştürmek için tf.keras.layers.CategoryEncoding kullanın.
tf.keras.layers.CategoryEncoding katmanının varsayılan ayarları, her giriş için bir sıcak vektör oluşturur. Bir layers.Embedding de işe yarar. Bu konu hakkında daha fazla bilgi için ön işleme katmanları kılavuzuna ve eğitimine bakın.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
inputs ve processed_inputs koleksiyonuyla, önceden işlenmiş tüm girdileri bir araya getirebilir ve ön işlemeyi gerçekleştiren bir model oluşturabilirsiniz:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
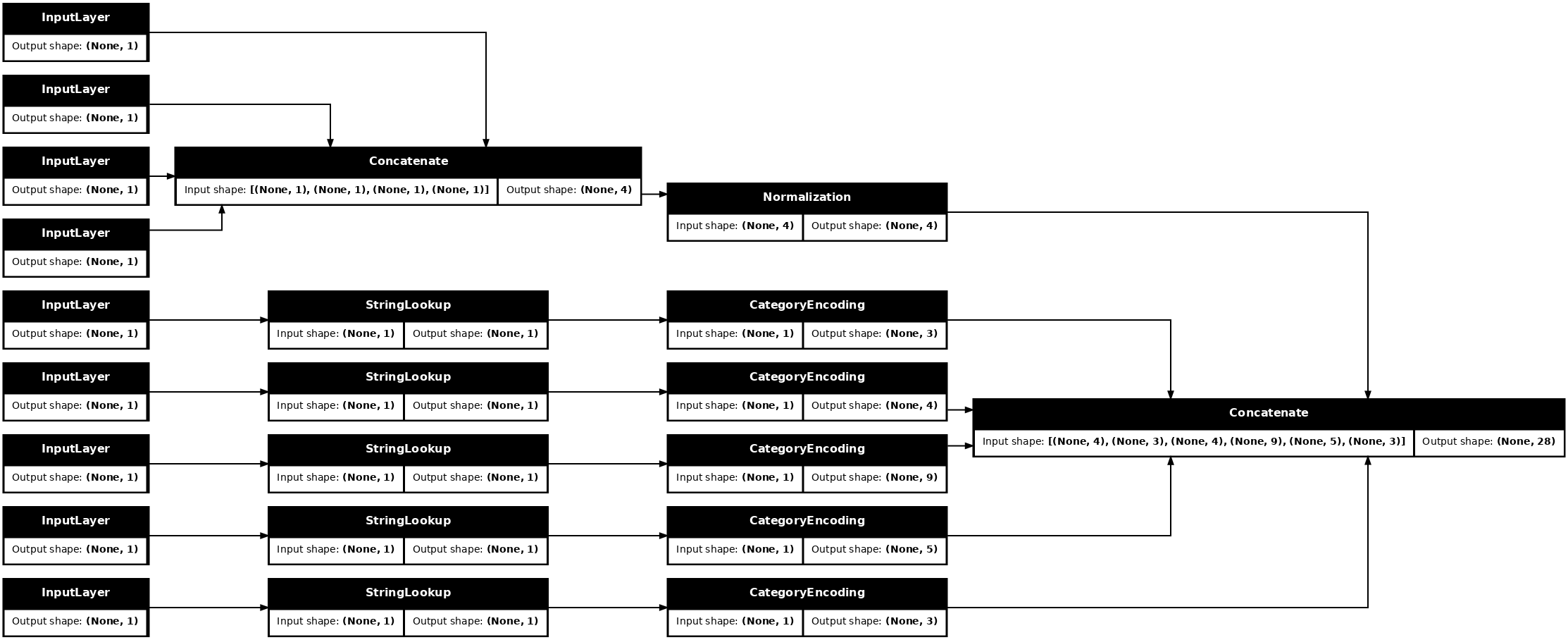
Bu model sadece girdi ön işlemesini içerir. Verilerinize ne yaptığını görmek için çalıştırabilirsiniz. Keras modelleri, Pandas DataFrames otomatik olarak dönüştürmez çünkü bir tensöre mi yoksa bir tensör sözlüğüne mi dönüştürülmesi gerektiği açık değildir. Öyleyse onu bir tensör sözlüğüne dönüştürün:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
İlk eğitim örneğini dilimleyin ve bu ön işleme modeline iletin, sayısal özellikleri ve tek-sıcaklık dizisini bir araya getirilmiş olarak görürsünüz:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Şimdi modeli bunun üzerine inşa edin:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
Modeli eğitirken, özellikler sözlüğünü x ve etiketi y olarak iletin.
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
Ön işleme, modelin bir parçası olduğundan, modeli kaydedebilir ve başka bir yere yeniden yükleyebilir ve aynı sonuçları alabilirsiniz:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assetsyer tutucu35 l10n-yer
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
tf.data'yı kullanma
Önceki bölümde, modeli eğitirken modelin yerleşik veri karıştırma ve gruplandırmasına güvendiniz.
Giriş verisi ardışık düzeni üzerinde daha fazla kontrole ihtiyacınız varsa veya belleğe kolayca sığmayan verileri kullanmanız gerekiyorsa: tf.data kullanın.
Daha fazla örnek için tf.data kılavuzuna bakın.
Açık bellek verisi
CSV verilerine tf.data uygulamasının ilk örneği olarak, önceki bölümdeki özellikler sözlüğünü manuel olarak dilimlemek için aşağıdaki kodu göz önünde bulundurun. Her dizin için, her özellik için o dizini alır:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Bunu çalıştırın ve ilk örneği yazdırın:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
Bellek veri yükleyicisindeki en temel tf.data.Dataset , Dataset.from_tensor_slices yapıcısıdır. Bu, TensorFlow'da yukarıdaki slices işlevinin genelleştirilmiş bir sürümünü uygulayan bir tf.data.Dataset döndürür.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
Yinelenebilir diğer herhangi bir python gibi bir tf.data.Dataset üzerinde yineleme yapabilirsiniz:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
from_tensor_slices işlevi, iç içe geçmiş sözlüklerin veya tanımlama gruplarının herhangi bir yapısını işleyebilir. Aşağıdaki kod, (features_dict, labels) çiftlerinden oluşan bir veri kümesi oluşturur:
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
Bu Dataset kullanarak bir modeli eğitmek için en azından verileri shuffle ve batch gerekir.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
features ve labels Model.fit iletmek yerine veri kümesini iletirsiniz:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
Tek bir dosyadan
Şimdiye kadar bu öğretici, bellek içi verilerle çalıştı. tf.data , veri ardışık düzenleri oluşturmak için yüksek düzeyde ölçeklenebilir bir araç takımıdır ve CSV dosyalarının yüklenmesiyle ilgili birkaç işlev sağlar.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
Şimdi dosyadan CSV verilerini okuyun ve bir tf.data.Dataset oluşturun.
(Belgelerin tamamı için bkz. tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
Bu işlev, verilerle çalışmanın kolay olması için birçok kullanışlı özellik içerir. Bu içerir:
- Sütun başlıklarını sözlük anahtarları olarak kullanma.
- Her sütunun türünü otomatik olarak belirleme.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
Ayrıca, verileri anında açabilir. İşte metro eyaletler arası trafik veri kümesini içeren gzip'li bir CSV dosyası

Wikimedia'dan görüntü
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
compression_type bağımsız değişkenini doğrudan sıkıştırılmış dosyadan okunacak şekilde ayarlayın:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
Önbelleğe almak
csv verilerini ayrıştırmak için biraz ek yük vardır. Küçük modeller için bu, eğitimdeki darboğaz olabilir.
Kullanım durumunuza bağlı olarak, csv verilerinin yalnızca ilk dönemde ayrıştırılması için Dataset.cache veya data.experimental.snapshot kullanmak iyi bir fikir olabilir.
cache ve snapshot yöntemleri arasındaki temel fark, cache dosyalarının yalnızca onları oluşturan TensorFlow işlemi tarafından kullanılabilmesi, ancak snapshot dosyalarının diğer işlemler tarafından okunabilmesidir.
Örneğin, traffic_volume_csv_gz_ds üzerinde 20 kez yineleme, önbelleğe alma olmadan ~15 saniye veya önbelleğe alma ile ~2s sürer.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
Veri yüklemeniz csv dosyalarının yüklenmesi nedeniyle yavaşlıyorsa ve cache ve snapshot kullanım durumunuz için yetersizse, verilerinizi daha akıcı bir biçimde yeniden kodlamayı düşünün.
Birden çok dosya
Bu bölümde şimdiye kadar verilen tüm örnekler tf.data olmadan kolayca yapılabilir. tf.data işleri gerçekten basitleştirebileceği yerlerden biri, dosya koleksiyonlarıyla uğraşmaktır.
Örneğin, karakter yazı tipi görüntüleri veri seti, yazı tipi başına bir tane olmak üzere bir csv dosyaları koleksiyonu olarak dağıtılır.

Resim Willi Heidelbach tarafından Pixabay'a yüklendi
Veri kümesini indirin ve içindeki dosyalara bir göz atın:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
Bir grup dosyayla uğraşırken, experimental.make_csv_dataset işlevine glob stili bir file_pattern iletebilirsiniz. Dosyaların sırası her yinelemede karıştırılır.
Paralel olarak kaç dosyanın okunacağını ve araya serpiştirileceğini ayarlamak için num_parallel_reads bağımsız değişkenini kullanın.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
Bu csv dosyaları, görüntüleri tek bir sıra halinde düzleştirir. Sütun adları r{row}c{column} şeklinde biçimlendirilir. İşte ilk parti:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
İsteğe bağlı: Paketleme alanları
Muhtemelen bunun gibi ayrı sütunlarda her pikselle çalışmak istemezsiniz. Bu veri kümesini kullanmaya çalışmadan önce pikselleri bir görüntü tensörüne yerleştirdiğinizden emin olun.
Her örnek için görüntüler oluşturmak üzere sütun adlarını ayrıştıran kod:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Bu işlevi veri kümesindeki her toplu iş için uygulayın:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Ortaya çıkan görüntüleri çizin:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

Alt seviye fonksiyonlar
Şimdiye kadar bu öğretici, csv verilerini okumak için en üst düzey yardımcı programlara odaklandı. Kullanım durumunuz temel kalıplara uymuyorsa, ileri düzey kullanıcılar için yararlı olabilecek başka iki API vardır.
-
tf.io.decode_csv- metin satırlarını bir CSV sütun tensörleri listesine ayrıştırmak için bir işlev. -
tf.data.experimental.CsvDataset- daha düşük seviyeli bir csv veri kümesi oluşturucusu.
Bu bölüm, bu alt düzey işlevselliğin nasıl kullanılabileceğini göstermek için make_csv_dataset tarafından sağlanan işlevselliği yeniden oluşturur.
tf.io.decode_csv
Bu işlev, bir dizeyi veya dize listesini bir sütun listesine çözer.
make_csv_dataset farklı olarak bu işlev, sütun veri türlerini tahmin etmeye çalışmaz. Her sütun için doğru türde bir değer içeren bir record_defaults listesi sağlayarak sütun türlerini belirtirsiniz.
Titanik verilerini decode_csv kullanarak dizeler olarak okumak için şunu söylersiniz:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']yer tutucu76 l10n-yer
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
Bunları gerçek türleriyle ayrıştırmak için karşılık gelen türlerin bir record_defaults listesi oluşturun:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
tf.data.experimental.CsvDataset sınıfı, make_csv_dataset işlevinin kolaylık özellikleri olmadan minimal bir CSV Dataset arabirimi sağlar: sütun başlığı ayrıştırma, sütun türü çıkarımı, otomatik karıştırma, dosya serpiştirme.
Bu kurucu, record_defaults ile aynı şekilde io.parse_csv kullanır:
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Yukarıdaki kod temelde şuna eşdeğerdir:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Birden çok dosya
Yazı tipi veri kümesini experimental.CsvDataset kullanarak ayrıştırmak için, önce record_defaults için sütun türlerini belirlemeniz gerekir. Bir dosyanın ilk satırını inceleyerek başlayın:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Yalnızca ilk iki alan dizedir, geri kalanı ints veya float'tır ve virgülleri sayarak toplam özellik sayısını elde edebilirsiniz:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
CsvDatasaet yapıcısı girdi dosyalarının bir listesini alabilir, ancak bunları sırayla okur. CSV'ler listesindeki ilk dosya AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
Bu nedenle, dosya listesini CsvDataaset'e AGENCY.csv , önce CsvDataaset gelen kayıtlar okunur:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
Birden çok dosyayı serpiştirmek için Dataset.interleave kullanın.
İşte csv dosya adlarını içeren bir ilk veri kümesi:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
Bu, her dönem dosya adlarını karıştırır:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
interleave yöntemi, üst Veri Kümesinin her öğesi için bir alt Dataset Dataset bir map_func alır.
Burada, dosya veri kümesinin her bir öğesinden bir CsvDataset oluşturmak istiyorsunuz:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Interleave tarafından döndürülen Dataset , bir dizi alt Dataset üzerinde döngü yaparak öğeleri döndürür. Aşağıda, veri kümesinin cycle_length=3 üç yazı tipi dosyası üzerinde nasıl döngü yaptığına dikkat edin:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
Verim
Daha önce, io.decode_csv bir dizi dizi üzerinde çalıştırıldığında daha verimli olduğu belirtilmişti.
Büyük parti boyutları kullanıldığında, CSV yükleme performansını iyileştirmek için bu durumdan yararlanmak mümkündür (ancak önce önbelleğe almayı deneyin).
Yerleşik 20 yükleyici ile 2048 örnek partiler yaklaşık 17 saniye sürer.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
Toplu metin satırlarını decode_csv yaklaşık 5 saniye içinde daha hızlı çalışır:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
Büyük partiler kullanarak csv performansını artırmanın başka bir örneği için, fazla ve eksik eğitim öğreticisine bakın.
Bu tür bir yaklaşım işe yarayabilir, ancak cache ve snapshot gibi diğer seçenekleri veya verilerinizi daha akıcı bir biçimde yeniden kodlamayı düşünün.