
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub |
Hướng dẫn này cung cấp các ví dụ về cách sử dụng dữ liệu CSV với TensorFlow.
Có hai phần chính cho điều này:
- Đang tải dữ liệu ra khỏi đĩa
- Sơ chế nó thành một dạng phù hợp để đào tạo.
Hướng dẫn này tập trung vào việc tải và đưa ra một số ví dụ nhanh về tiền xử lý. Đối với hướng dẫn tập trung vào khía cạnh tiền xử lý, hãy xem hướng dẫn và hướng dẫn về lớp tiền xử lý .
Thành lập
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
Trong dữ liệu bộ nhớ
Đối với bất kỳ tập dữ liệu CSV nhỏ nào, cách đơn giản nhất để đào tạo mô hình TensorFlow trên đó là tải nó vào bộ nhớ dưới dạng Khung dữ liệu gấu trúc hoặc mảng NumPy.
Một ví dụ tương đối đơn giản là tập dữ liệu bào ngư .
- Tập dữ liệu nhỏ.
- Tất cả các tính năng đầu vào đều là giá trị dấu phẩy động trong phạm vi giới hạn.
Đây là cách tải dữ liệu vào Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
Bộ dữ liệu bao gồm một tập hợp các phép đo của bào ngư , một loại ốc biển.

“Vỏ bào ngư” (của Nicki Dugan Pogue , CC BY-SA 2.0)
Nhiệm vụ danh nghĩa cho tập dữ liệu này là dự đoán tuổi từ các phép đo khác, vì vậy hãy tách các tính năng và nhãn để đào tạo:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
Đối với tập dữ liệu này, bạn sẽ xử lý tất cả các tính năng giống nhau. Đóng gói các tính năng vào một mảng NumPy duy nhất:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
Tiếp theo hãy lập mô hình hồi quy dự đoán tuổi. Vì chỉ có một tensor đầu vào duy nhất, một mô hình keras.Sequential là đủ ở đây.
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
Để đào tạo mô hình đó, hãy chuyển các tính năng và nhãn cho Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
Bạn vừa xem cách cơ bản nhất để đào tạo một mô hình sử dụng dữ liệu CSV. Tiếp theo, bạn sẽ học cách áp dụng tiền xử lý để chuẩn hóa các cột số.
Tiền xử lý cơ bản
Thực hành tốt để chuẩn hóa các đầu vào cho mô hình của bạn. Các lớp tiền xử lý của Keras cung cấp một cách thuận tiện để xây dựng quá trình chuẩn hóa này vào mô hình của bạn.
Lớp sẽ tính toán trước giá trị trung bình và phương sai của mỗi cột và sử dụng chúng để chuẩn hóa dữ liệu.
Đầu tiên, bạn tạo lớp:
normalize = layers.Normalization()
Sau đó, bạn sử dụng phương thức Normalization.adapt() để điều chỉnh lớp chuẩn hóa cho dữ liệu của bạn.
normalize.adapt(abalone_features)
Sau đó, sử dụng lớp chuẩn hóa trong mô hình của bạn:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
Các kiểu dữ liệu hỗn hợp
Bộ dữ liệu "Titanic" chứa thông tin về các hành khách trên tàu Titanic. Nhiệm vụ danh nghĩa trên tập dữ liệu này là dự đoán ai sống sót.

Hình ảnh từ Wikimedia
{kind=link}
Dữ liệu thô có thể dễ dàng được tải dưới dạng Pandas DataFrame , nhưng không thể sử dụng ngay làm dữ liệu đầu vào cho mô hình TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
Do các kiểu và phạm vi dữ liệu khác nhau, bạn không thể chỉ xếp chồng các tính năng vào mảng NumPy và chuyển nó vào mô hình keras.Sequential . Mỗi cột cần được xử lý riêng lẻ.
Là một tùy chọn, bạn có thể xử lý trước dữ liệu của mình khi ngoại tuyến (sử dụng bất kỳ công cụ nào bạn thích) để chuyển đổi cột phân loại thành cột số, sau đó chuyển đầu ra đã xử lý sang mô hình TensorFlow của bạn. Điểm bất lợi của cách tiếp cận đó là nếu bạn lưu và xuất mô hình của mình, quá trình tiền xử lý sẽ không được lưu cùng với nó. Các lớp tiền xử lý của Keras tránh được vấn đề này vì chúng là một phần của mô hình.
Trong ví dụ này, bạn sẽ xây dựng một mô hình triển khai logic tiền xử lý bằng cách sử dụng API chức năng Keras . Bạn cũng có thể làm điều đó bằng cách phân lớp con .
API chức năng hoạt động trên các tensors "tượng trưng". Các tensors "háo hức" bình thường có một giá trị. Ngược lại, những tensors "tượng trưng" này thì không. Thay vào đó, họ theo dõi các hoạt động nào được chạy trên chúng và xây dựng biểu diễn của phép tính để bạn có thể chạy sau này. Đây là một ví dụ nhanh:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
Để xây dựng mô hình tiền xử lý, hãy bắt đầu bằng cách xây dựng một tập hợp các đối tượng keras.Input tượng trưng, khớp với tên và kiểu dữ liệu của các cột CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
Bước đầu tiên trong logic tiền xử lý của bạn là nối các đầu vào số với nhau và chạy chúng qua một lớp chuẩn hóa:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
Thu thập tất cả các kết quả tiền xử lý tượng trưng, để nối chúng sau này.
preprocessed_inputs = [all_numeric_inputs]
Đối với đầu vào chuỗi, hãy sử dụng hàm tf.keras.layers.StringLookup để ánh xạ từ chuỗi thành chỉ số nguyên trong một từ vựng. Tiếp theo, sử dụng tf.keras.layers.CategoryEncoding để chuyển đổi các chỉ mục thành dữ liệu float32 phù hợp với mô hình.
Cài đặt mặc định cho lớp tf.keras.layers.CategoryEncoding tạo ra một vectơ nóng cho mỗi đầu vào. A layers.Embedding cũng sẽ hoạt động. Xem hướng dẫn và hướng dẫn tiền xử lý lớp để biết thêm về chủ đề này.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
Với bộ sưu tập inputs và đầu vào processed_inputs , bạn có thể ghép tất cả các đầu vào được xử lý trước với nhau và xây dựng một mô hình xử lý tiền xử lý:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
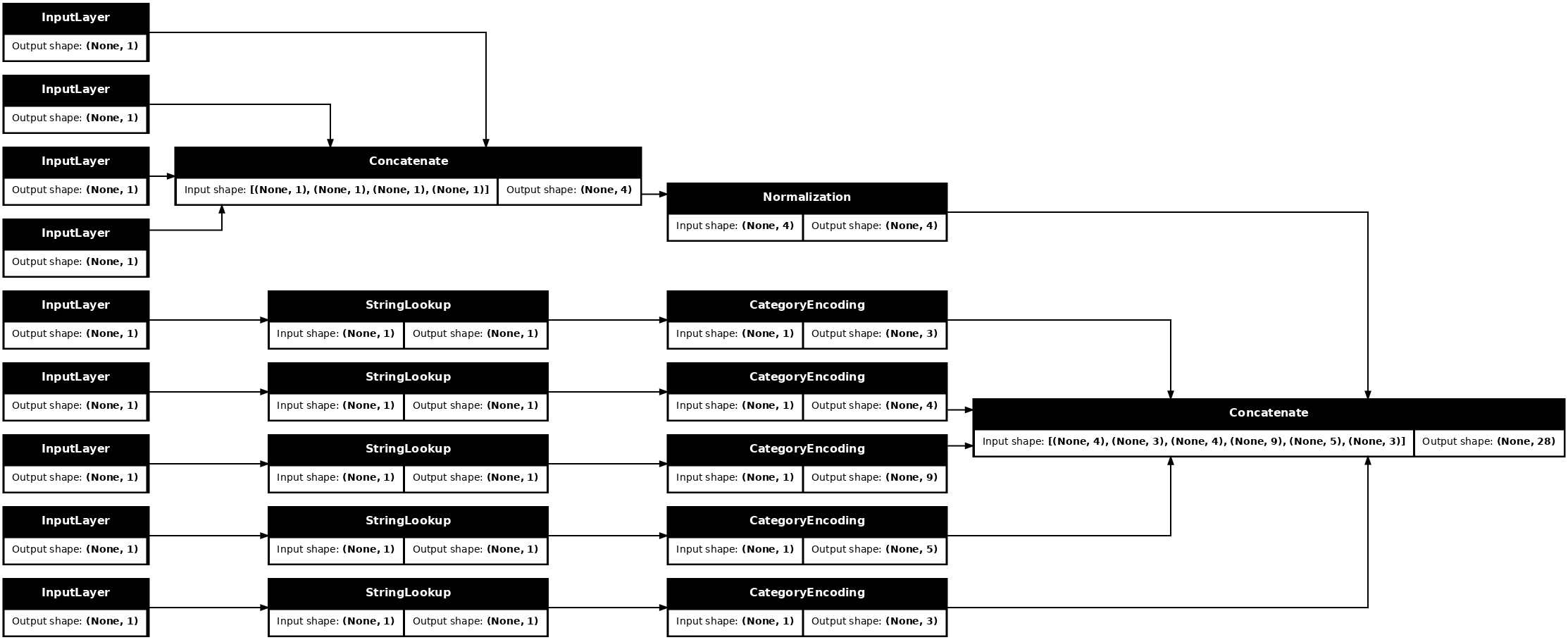
model này chỉ chứa tiền xử lý đầu vào. Bạn có thể chạy nó để xem nó ảnh hưởng gì đến dữ liệu của bạn. Các mô hình Keras không tự động chuyển đổi Pandas DataFrames vì không rõ liệu nó nên được chuyển đổi thành một tensor hay thành một từ điển tensor. Vì vậy, hãy chuyển đổi nó thành một từ điển của tenxơ:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
Cắt nhỏ ví dụ đào tạo đầu tiên và chuyển nó vào mô hình tiền xử lý này, bạn sẽ thấy các tính năng số và chuỗi một-hots tất cả được nối với nhau:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Bây giờ xây dựng mô hình trên đầu trang này:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
Khi bạn đào tạo mô hình, hãy chuyển từ điển các đối tượng là x và nhãn là y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
Vì tiền xử lý là một phần của mô hình, bạn có thể lưu mô hình và tải lại ở một nơi khác và nhận được kết quả giống hệt nhau:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
Sử dụng tf.data
Trong phần trước, bạn đã dựa vào việc trộn và trộn dữ liệu có sẵn của mô hình trong khi đào tạo mô hình.
Nếu bạn cần kiểm soát nhiều hơn đối với đường ống dữ liệu đầu vào hoặc cần sử dụng dữ liệu không dễ dàng vừa với bộ nhớ: hãy sử dụng tf.data .
Để biết thêm ví dụ, hãy xem hướng dẫn tf.data .
Bật trong dữ liệu bộ nhớ
Như một ví dụ đầu tiên về việc áp dụng tf.data cho dữ liệu CSV, hãy xem đoạn mã sau để chia nhỏ từ điển các tính năng từ phần trước theo cách thủ công. Đối với mỗi chỉ mục, nó lấy chỉ mục đó cho từng tính năng:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Chạy cái này và in ví dụ đầu tiên:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
tf.data.Dataset cơ bản nhất trong bộ tải dữ liệu bộ nhớ là hàm tạo Dataset.from_tensor_slices . Điều này trả về một tf.data.Dataset thực hiện một phiên bản tổng quát của hàm slices ở trên, trong TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
Bạn có thể lặp qua tf.data.Dataset giống như bất kỳ tệp python nào có thể lặp lại khác:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
Hàm from_tensor_slices có thể xử lý bất kỳ cấu trúc nào của các bộ từ điển hoặc bộ từ điển lồng nhau. Đoạn mã sau tạo tập dữ liệu gồm các cặp (features_dict, labels) :
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
Để đào tạo một mô hình bằng cách sử dụng Dataset này, ít nhất bạn sẽ cần shuffle và trộn dữ liệu batch .
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
Thay vì chuyển features và labels cho Model.fit , bạn chuyển tập dữ liệu:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
Từ một tệp duy nhất
Cho đến nay, hướng dẫn này đã hoạt động với dữ liệu trong bộ nhớ. tf.data là bộ công cụ có khả năng mở rộng cao để xây dựng đường ống dữ liệu và cung cấp một số chức năng để xử lý việc tải tệp CSV.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
Bây giờ đọc dữ liệu CSV từ tệp và tạo tf.data.Dataset .
(Để có tài liệu đầy đủ, hãy xem tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
Chức năng này bao gồm nhiều tính năng tiện lợi nên dữ liệu dễ làm việc. Điêu nay bao gôm:
- Sử dụng tiêu đề cột làm khóa từ điển.
- Tự động xác định loại của mỗi cột.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
Nó cũng có thể giải nén dữ liệu một cách nhanh chóng. Đây là một tệp CSV được nén có chứa tập dữ liệu về giao thông giữa các tiểu bang của thành phố lớn

Hình ảnh từ Wikimedia
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
Đặt đối số kiểu compression_type để đọc trực tiếp từ tệp nén:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
Bộ nhớ đệm
Có một số chi phí để phân tích cú pháp dữ liệu csv. Đối với những người mẫu nhỏ đây có thể là điểm nghẽn trong đào tạo.
Tùy thuộc vào trường hợp sử dụng của bạn, bạn có thể sử dụng Dataset.cache hoặc data.experimental.snapshot để dữ liệu csv chỉ được phân tích cú pháp trong kỷ nguyên đầu tiên.
Sự khác biệt chính giữa phương pháp cache và snapshot là các tệp cache chỉ có thể được sử dụng bởi quy trình TensorFlow đã tạo ra chúng, nhưng các tệp snapshot có thể được đọc bởi các quy trình khác.
Ví dụ: lặp lại traffic_volume_csv_gz_ds 20 lần, mất ~ 15 giây nếu không có bộ nhớ đệm hoặc ~ 2 giây với bộ đệm.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
Nếu quá trình tải dữ liệu của bạn bị chậm lại do tải tệp csv và cache và snapshot không đủ cho trường hợp sử dụng của bạn, hãy xem xét mã hóa lại dữ liệu của bạn thành một định dạng hợp lý hơn.
Nhiều tệp
Tất cả các ví dụ cho đến nay trong phần này có thể dễ dàng được thực hiện mà không cần tf.data . Một nơi mà tf.data thực sự có thể đơn giản hóa mọi thứ là khi xử lý các bộ sưu tập tệp.
Ví dụ: tập dữ liệu hình ảnh phông chữ ký tự được phân phối dưới dạng tập hợp các tệp csv, mỗi tệp một phông chữ.

Hình ảnh được cung cấp bởi Willi Heidelbach từ Pixabay
Tải xuống tập dữ liệu và xem các tệp bên trong:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
Khi xử lý một loạt các tệp, bạn có thể chuyển một file_pattern kiểu hình cầu vào hàm experimental.make_csv_dataset nghiệm.make_csv_dataset. Thứ tự của các tệp được xáo trộn mỗi lần lặp lại.
Sử dụng đối số num_parallel_reads để đặt số lượng tệp được đọc song song và xen kẽ với nhau.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
Các tệp csv này có các hình ảnh được làm phẳng thành một hàng. Tên cột được định dạng r{row}c{column} . Đây là đợt đầu tiên:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
Tùy chọn: Các trường đóng gói
Bạn có thể không muốn làm việc với từng pixel trong các cột riêng biệt như thế này. Trước khi cố gắng sử dụng tập dữ liệu này, hãy đảm bảo đóng gói các pixel thành một bộ căng hình ảnh.
Đây là mã phân tích cú pháp tên cột để tạo hình ảnh cho từng ví dụ:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Áp dụng chức năng đó cho từng lô trong tập dữ liệu:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Vẽ các hình ảnh kết quả:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

Các chức năng cấp thấp hơn
Cho đến nay, hướng dẫn này đã tập trung vào các tiện ích cấp cao nhất để đọc dữ liệu csv. Có hai API khác có thể hữu ích cho người dùng nâng cao nếu trường hợp sử dụng của bạn không phù hợp với các mẫu cơ bản.
-
tf.io.decode_csv- một hàm để phân tích cú pháp các dòng văn bản thành danh sách các bộ căng cột CSV. -
tf.data.experimental.CsvDataset- một phương thức khởi tạo tập dữ liệu csv cấp thấp hơn.
Phần này tạo lại chức năng do make_csv_dataset cung cấp, để chứng minh cách sử dụng chức năng cấp thấp hơn này.
tf.io.decode_csv
Hàm này giải mã một chuỗi hoặc danh sách các chuỗi thành một danh sách các cột.
Không giống như make_csv_dataset , hàm này không cố gắng đoán kiểu dữ liệu cột. Bạn chỉ định các loại cột bằng cách cung cấp danh sách các giá trị mặc định của record_defaults chứa giá trị của loại đúng, cho mỗi cột.
Để đọc dữ liệu Titanic dưới dạng chuỗi bằng decode_csv , bạn sẽ nói:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
Để phân tích cú pháp chúng với các loại thực tế của chúng, hãy tạo danh sách record_defaults của các loại tương ứng:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
Lớp tf.data.experimental.CsvDataset cung cấp giao diện Dataset CSV tối thiểu mà không có các tính năng tiện lợi của hàm make_csv_dataset : phân tích cú pháp tiêu đề cột, kiểu suy luận cột, xáo trộn tự động, xen kẽ tệp.
Hàm tạo này sau sử dụng record_defaults giống như io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Đoạn mã trên về cơ bản tương đương với:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Nhiều tệp
Để phân tích cú pháp tập dữ liệu phông chữ bằng cách sử dụng experimental.CsvDataset nghiệm.CsvDataset, trước tiên bạn cần xác định loại cột cho record_defaults . Bắt đầu bằng cách kiểm tra hàng đầu tiên của một tệp:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Chỉ hai trường đầu tiên là chuỗi, phần còn lại là int hoặc float và bạn có thể nhận tổng số đối tượng bằng cách đếm dấu phẩy:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
Phương thức khởi tạo CsvDatasaet có thể lấy một danh sách các tệp đầu vào, nhưng đọc chúng theo tuần tự. Tệp đầu tiên trong danh sách CSV là AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
Vì vậy, khi bạn chuyển danh sách tệp sang CsvDataaset , các bản ghi từ AGENCY.csv sẽ được đọc trước:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
Để xen kẽ nhiều tệp, hãy sử dụng Dataset.interleave .
Đây là tập dữ liệu ban đầu chứa tên tệp csv:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
Thao tác này xáo trộn tên tệp từng kỷ nguyên:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
Phương thức interleave lấy một map_func tạo ra một Dataset con cho mỗi phần tử của Dataset cha.
Tại đây, bạn muốn tạo CsvDataset từ mỗi phần tử của tập dữ liệu tệp:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Dataset được trả về bởi interleave trả về các phần tử bằng cách xoay vòng qua một số tập Dataset con. Lưu ý, bên dưới, cách bộ dữ liệu xoay vòng qua cycle_length=3 ba tệp phông chữ:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
Màn biểu diễn
Trước đó, người ta đã lưu ý rằng io.decode_csv hiệu quả hơn khi chạy trên một loạt chuỗi.
Có thể tận dụng thực tế này, khi sử dụng kích thước lô lớn, để cải thiện hiệu suất tải CSV (nhưng hãy thử lưu vào bộ nhớ đệm trước).
Với bộ nạp 20 tích hợp, các lô ví dụ 2048 mất khoảng 17 giây.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
Chuyển hàng loạt dòng văn bản tới decode_csv chạy nhanh hơn, trong khoảng 5 giây:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
Để có một ví dụ khác về việc tăng hiệu suất csv bằng cách sử dụng các lô lớn, hãy xem hướng dẫn về trang phục thừa và trang phục thiếu .
Cách tiếp cận này có thể hiệu quả, nhưng hãy xem xét các tùy chọn khác như cache và snapshot hoặc mã hóa lại dữ liệu của bạn thành một định dạng hợp lý hơn.