
کلاس نهایی عمومی ParallelDynamicStitch
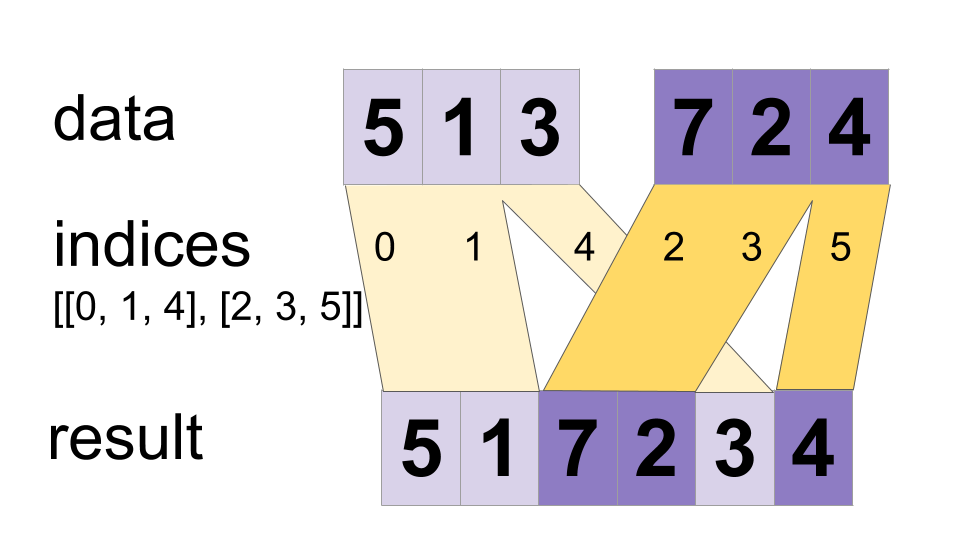
مقادیر تانسورهای «داده» را در یک تانسور واحد قرار دهید.
یک تانسور ادغام شده به گونه ای می سازد که
merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]
# Scalar indices:
merged[indices[m], ...] = data[m][...]
# Vector indices:
merged[indices[m][i], ...] = data[m][i, ...]
merged.shape = [حداکثر(شاخص)] + ثابت
ممکن است مقادیر به صورت موازی ادغام شوند، بنابراین اگر یک شاخص در هر دو «شاخص[m][i]» و «شاخص[n][j]» ظاهر شود، ممکن است نتیجه نامعتبر باشد. این با عملگر معمولی DynamicStitch که رفتار را در آن حالت تعریف می کند متفاوت است.
به عنوان مثال:
indices[0] = 6
indices[1] = [4, 1]
indices[2] = [[5, 2], [0, 3]]
data[0] = [61, 62]
data[1] = [[41, 42], [11, 12]]
data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]]
merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42],
[51, 52], [61, 62]]
# Apply function (increments x_i) on elements for which a certain condition
# apply (x_i != -1 in this example).
x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4])
condition_mask=tf.not_equal(x,tf.constant(-1.))
partitioned_data = tf.dynamic_partition(
x, tf.cast(condition_mask, tf.int32) , 2)
partitioned_data[1] = partitioned_data[1] + 1.0
condition_indices = tf.dynamic_partition(
tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2)
x = tf.dynamic_stitch(condition_indices, partitioned_data)
# Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain
# unchanged.
ثابت ها
| رشته | OP_NAME | نام این عملیات، همانطور که توسط موتور هسته TensorFlow شناخته می شود |
روش های عمومی
| خروجی <T> | asOutput () دسته نمادین تانسور را برمی گرداند. |
| static <T TType > ParallelDynamicStitch <T> را گسترش می دهد | |
| خروجی <T> | ادغام شده () |
روش های ارثی
ثابت ها
رشته نهایی ثابت عمومی OP_NAME
نام این عملیات، همانطور که توسط موتور هسته TensorFlow شناخته می شود
مقدار ثابت: "ParallelDynamicStitch"
روش های عمومی
خروجی عمومی <T> asOutput ()
دسته نمادین تانسور را برمی گرداند.
ورودی های عملیات TensorFlow خروجی های عملیات تنسورفلو دیگر هستند. این روش برای به دست آوردن یک دسته نمادین که نشان دهنده محاسبه ورودی است استفاده می شود.
عمومی ایستا ParallelDynamicStitch <T> ایجاد ( دامنه دامنه ، تکرارپذیر< Operand < TINT32 >> شاخصها، تکرارپذیر< Operand <T>> داده)
روش کارخانه برای ایجاد کلاسی که عملیات جدید ParallelDynamicStitch را بسته بندی می کند.
پارامترها
| دامنه | محدوده فعلی |
|---|
برمی گرداند
- یک نمونه جدید از ParallelDynamicStitch