
ทั่วไป
EvalSavedModel ยังจำเป็นต้องใช้หรือไม่
ก่อนหน้านี้ TFMA กำหนดให้หน่วยวัดทั้งหมดถูกจัดเก็บไว้ในกราฟเทนเซอร์โฟลว์โดยใช้ EvalSavedModel พิเศษ ขณะนี้ สามารถคำนวณหน่วยเมตริกนอกกราฟ TF ได้โดยใช้การใช้ beam.CombineFn .CombineFn
ความแตกต่างที่สำคัญบางประการ ได้แก่:
-
EvalSavedModelต้องมีการส่งออกแบบพิเศษจากเทรนเนอร์ ในขณะที่โมเดลการให้บริการสามารถใช้ได้โดยไม่ต้องเปลี่ยนแปลงใดๆ กับโค้ดการฝึก - เมื่อใช้
EvalSavedModelหน่วยวัดใดๆ ที่เพิ่มในเวลาการฝึกอบรมจะพร้อมใช้งานโดยอัตโนมัติในเวลาประเมิน หากไม่มีEvalSavedModelจะต้องเพิ่มเมตริกเหล่านี้อีกครั้ง- ข้อยกเว้นสำหรับกฎนี้คือ หากใช้โมเดล keras เมตริกก็สามารถเพิ่มได้โดยอัตโนมัติเนื่องจาก keras จะบันทึกข้อมูลเมตริกควบคู่ไปกับโมเดลที่บันทึกไว้
TFMA สามารถทำงานร่วมกับทั้งตัวชี้วัดในกราฟและตัวชี้วัดภายนอกได้หรือไม่
TFMA อนุญาตให้ใช้แนวทางแบบไฮบริดโดยที่บางเมตริกสามารถคำนวณในกราฟได้ ในขณะที่เมตริกอื่นๆ สามารถคำนวณภายนอกได้ หากปัจจุบันคุณมี EvalSavedModel คุณก็สามารถใช้งานได้ต่อไป
มีสองกรณี:
- ใช้ TFMA
EvalSavedModelสำหรับทั้งการแยกคุณลักษณะและการคำนวณหน่วยเมตริก แต่ยังเพิ่มหน่วยเมตริกแบบรวมเพิ่มเติมด้วย ในกรณีนี้ คุณจะได้รับตัววัดในกราฟทั้งหมดจากEvalSavedModelพร้อมด้วยตัววัดเพิ่มเติมจากตัวรวมที่อาจไม่ได้รับการสนับสนุนก่อนหน้านี้ - ใช้ TFMA
EvalSavedModelสำหรับการแยกคุณสมบัติ/การคาดการณ์ แต่ใช้ตัววัดแบบรวมสำหรับการคำนวณตัววัดทั้งหมด โหมดนี้มีประโยชน์หากมีการแปลงคุณสมบัติในEvalSavedModelที่คุณต้องการใช้สำหรับการแบ่งส่วน แต่ต้องการดำเนินการคำนวณหน่วยเมตริกทั้งหมดนอกกราฟ
ตั้งค่า
รองรับรุ่นใดบ้าง?
TFMA รองรับโมเดล keras ซึ่งเป็นโมเดลที่ใช้ API ลายเซ็น TF2 ทั่วไป รวมถึงโมเดลที่ใช้ตัวประมาณค่า TF (แม้ว่าจะขึ้นอยู่กับกรณีการใช้งาน โมเดลที่ใช้ตัวประมาณอาจต้องใช้ EvalSavedModel ก็ตาม)
ดูคู่มือ get_started สำหรับรายการประเภทโมเดลทั้งหมดที่รองรับและข้อจำกัดใดๆ
ฉันจะตั้งค่า TFMA ให้ทำงานกับโมเดลที่ใช้ Keras ดั้งเดิมได้อย่างไร
ต่อไปนี้เป็นตัวอย่างการกำหนดค่าสำหรับโมเดล keras ตามสมมติฐานต่อไปนี้:
- โมเดลที่บันทึกไว้มีไว้สำหรับการให้บริการและใช้ชื่อลายเซ็น
serving_default(ซึ่งสามารถเปลี่ยนแปลงได้โดยใช้model_specs[0].signature_name) - ควรประเมินเมตริกในตัวจาก
model.compile(...)(ซึ่งสามารถปิดใช้งานได้ผ่านoptions.include_default_metricภายใน tfma.EvalConfig )
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
ดู เมตริก สำหรับข้อมูลเพิ่มเติมเกี่ยวกับเมตริกประเภทอื่นๆ ที่สามารถกำหนดค่าได้
ฉันจะตั้งค่า TFMA ให้ทำงานกับโมเดลที่ใช้ลายเซ็น TF2 ทั่วไปได้อย่างไร
ต่อไปนี้เป็นตัวอย่างการกำหนดค่าสำหรับโมเดล TF2 ทั่วไป ด้านล่างนี้ signature_name คือชื่อของลายเซ็นเฉพาะที่ควรใช้สำหรับการประเมิน
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
ดู เมตริก สำหรับข้อมูลเพิ่มเติมเกี่ยวกับเมตริกประเภทอื่นๆ ที่สามารถกำหนดค่าได้
ฉันจะตั้งค่า TFMA ให้ทำงานกับแบบจำลองที่ใช้ตัวประมาณได้อย่างไร
ในกรณีนี้มีสามทางเลือก
ตัวเลือกที่ 1: ใช้รูปแบบการให้บริการ
หากใช้ตัวเลือกนี้ ตัวชี้วัดใดๆ ที่เพิ่มระหว่างการฝึกอบรมจะไม่รวมอยู่ในการประเมิน
ต่อไปนี้คือตัวอย่างการกำหนดค่าโดยสมมติว่า serving_default เป็นชื่อลายเซ็นที่ใช้:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
ดู เมตริก สำหรับข้อมูลเพิ่มเติมเกี่ยวกับเมตริกประเภทอื่นๆ ที่สามารถกำหนดค่าได้
ตัวเลือกที่ 2: ใช้ EvalSavedModel ร่วมกับตัววัดที่อิงตัวรวมเพิ่มเติม
ในกรณีนี้ ให้ใช้ EvalSavedModel สำหรับทั้งการแยกคุณสมบัติ/การทำนายและการประเมิน และยังเพิ่มตัววัดตามตัวรวมเพิ่มเติมอีกด้วย
ต่อไปนี้เป็นตัวอย่างการกำหนดค่า:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
ดู หน่วยวัด สำหรับข้อมูลเพิ่มเติมเกี่ยวกับหน่วยวัดประเภทอื่นๆ ที่สามารถกำหนดค่าได้ และ EvalSavedModel สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการตั้งค่า EvalSavedModel
ตัวเลือกที่ 3: ใช้โมเดล EvalSavedModel สำหรับการแยกคุณลักษณะ/การคาดการณ์เท่านั้น
คล้ายกับตัวเลือก (2) แต่ใช้ EvalSavedModel สำหรับการแยกคุณสมบัติ / การทำนายเท่านั้น ตัวเลือกนี้มีประโยชน์หากต้องการเฉพาะเมตริกภายนอก แต่มีการแปลงคุณลักษณะที่คุณต้องการแบ่งส่วน เช่นเดียวกับตัวเลือก (1) ตัวชี้วัดใดๆ ที่เพิ่มระหว่างการฝึกอบรมจะไม่รวมอยู่ในการประเมิน
ในกรณีนี้การกำหนดค่าเหมือนกับด้านบน เฉพาะ include_default_metrics เท่านั้นที่ถูกปิดใช้งาน
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
ดู หน่วยวัด สำหรับข้อมูลเพิ่มเติมเกี่ยวกับหน่วยวัดประเภทอื่นๆ ที่สามารถกำหนดค่าได้ และ EvalSavedModel สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการตั้งค่า EvalSavedModel
ฉันจะตั้งค่า TFMA ให้ทำงานกับโมเดลที่ใช้โมเดล keras-to-estimator ได้อย่างไร
การตั้งค่า keras model_to_estimator คล้ายกับการกำหนดค่าตัวประมาณค่า อย่างไรก็ตาม มีความแตกต่างเล็กน้อยเกี่ยวกับวิธีการทำงานของตัวประมาณค่า โดยเฉพาะอย่างยิ่ง model-to-esimtator ส่งคืนเอาต์พุตในรูปแบบของ dict โดยที่คีย์ dict คือชื่อของเลเยอร์เอาต์พุตสุดท้ายในโมเดล keras ที่เกี่ยวข้อง (หากไม่มีการระบุชื่อ keras จะเลือกชื่อเริ่มต้นสำหรับคุณ เช่น dense_1 หรือ output_1 ) จากมุมมองของ TFMA ลักษณะการทำงานนี้จะคล้ายกับสิ่งที่จะเป็นเอาต์พุตสำหรับโมเดลแบบหลายเอาต์พุต แม้ว่าแบบจำลองไปจนถึงตัวประมาณค่าอาจเป็นเพียงโมเดลเดียวเท่านั้น เพื่อพิจารณาความแตกต่างนี้ จำเป็นต้องมีขั้นตอนเพิ่มเติมเพื่อตั้งชื่อเอาต์พุต อย่างไรก็ตาม ใช้สามตัวเลือกเดียวกันนี้เป็นตัวประมาณค่า
ต่อไปนี้เป็นตัวอย่างของการเปลี่ยนแปลงที่จำเป็นสำหรับการกำหนดค่าตามตัวประมาณการ:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
ฉันจะตั้งค่า TFMA ให้ทำงานกับการคาดการณ์ที่คำนวณไว้ล่วงหน้า (เช่น ไม่เชื่อเรื่องโมเดล) ได้อย่างไร ( TFRecord และ tf.Example )
ในการกำหนดค่า TFMA ให้ทำงานกับการคาดการณ์ที่คำนวณไว้ล่วงหน้า จะต้องปิดใช้งาน tfma.PredictExtractor เริ่มต้น และต้องกำหนด tfma.InputExtractor เพื่อแยกวิเคราะห์การคาดการณ์พร้อมกับฟีเจอร์อินพุตอื่นๆ ซึ่งสามารถทำได้โดยการกำหนดค่า tfma.ModelSpec ด้วยชื่อของคีย์คุณลักษณะที่ใช้สำหรับการคาดการณ์ควบคู่ไปกับป้ายกำกับและน้ำหนัก
ต่อไปนี้เป็นตัวอย่างการตั้งค่า:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
ดู เมตริก สำหรับข้อมูลเพิ่มเติมเกี่ยวกับเมตริกที่สามารถกำหนดค่าได้
โปรดทราบว่าแม้ว่า tfma.ModelSpec กำลังได้รับการกำหนดค่า แต่โมเดลไม่ได้ใช้งานจริง (เช่น ไม่มี tfma.EvalSharedModel ) การเรียกใช้การวิเคราะห์แบบจำลองอาจมีลักษณะดังนี้:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
ฉันจะตั้งค่า TFMA ให้ทำงานกับการคาดการณ์ที่คำนวณไว้ล่วงหน้า (เช่น ไม่เชื่อเรื่องโมเดล) ได้อย่างไร ( pd.DataFrame )
สำหรับชุดข้อมูลขนาดเล็กที่สามารถใส่ในหน่วยความจำได้ อีกทางเลือกหนึ่งของ TFRecord คือ pandas.DataFrame s TFMA สามารถดำเนินการบน pandas.DataFrame ได้โดยใช้ tfma.analyze_raw_data API สำหรับคำอธิบายของ tfma.MetricsSpec และ tfma.SlicingSpec โปรดดูคู่มือ การตั้งค่า ดู เมตริก สำหรับข้อมูลเพิ่มเติมเกี่ยวกับเมตริกที่สามารถกำหนดค่าได้
ต่อไปนี้เป็นตัวอย่างการตั้งค่า:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
เมตริก
รองรับเมตริกประเภทใดบ้าง
TFMA รองรับตัวชี้วัดที่หลากหลาย รวมถึง:
- ตัวชี้วัดการถดถอย
- เมตริกการจำแนกประเภทไบนารี
- เมตริกการจำแนกประเภทแบบหลายคลาส/หลายป้ายกำกับ
- ตัวชี้วัดค่าเฉลี่ยจุลภาค / ค่าเฉลี่ยมหภาค
- เมตริกตามคำค้นหา / การจัดอันดับ
รองรับหน่วยเมตริกจากโมเดลหลายเอาต์พุตหรือไม่
ใช่. ดูคู่มือ การวัด สำหรับรายละเอียดเพิ่มเติม
รองรับการวัดจากหลายรุ่นหรือไม่
ใช่. ดูคู่มือ การวัด สำหรับรายละเอียดเพิ่มเติม
สามารถปรับแต่งการตั้งค่าเมตริก (ชื่อ ฯลฯ) ได้หรือไม่
ใช่. การตั้งค่าเมตริกสามารถปรับแต่งได้ (เช่น การตั้งค่าเกณฑ์เฉพาะ ฯลฯ) โดยการเพิ่มการตั้งค่า config ให้กับการกำหนดค่าเมตริก ดูคู่มือ เมตริก มีรายละเอียดเพิ่มเติม
รองรับการวัดแบบกำหนดเองหรือไม่
ใช่. ไม่ว่าจะโดยการเขียนการใช้งาน tf.keras.metrics.Metric แบบกำหนดเอง หรือโดยการเขียนการใช้งาน beam.CombineFn แบบกำหนดเอง คู่มือ การวัด มีรายละเอียดเพิ่มเติม
ไม่รองรับเมตริกประเภทใดบ้าง
ตราบใดที่ระบบคำนวณของคุณสามารถคำนวณได้โดยใช้ beam.CombineFn ก็ไม่มีข้อจำกัดเกี่ยวกับประเภทของหน่วยวัดที่สามารถคำนวณตาม tfma.metrics.Metric หากทำงานกับเมตริกที่ได้รับจาก tf.keras.metrics.Metric จะต้องเป็นไปตามเกณฑ์ต่อไปนี้:
- ควรเป็นไปได้ที่จะคำนวณสถิติที่เพียงพอสำหรับหน่วยเมตริกในแต่ละตัวอย่างแยกกัน จากนั้นจึงรวมสถิติที่เพียงพอเหล่านี้โดยการเพิ่มลงในตัวอย่างทั้งหมด และกำหนดค่าเมตริกจากสถิติที่เพียงพอเหล่านี้เพียงอย่างเดียว
- ตัวอย่างเช่น เพื่อความถูกต้อง สถิติที่เพียงพอคือ "ถูกต้องทั้งหมด" และ "ตัวอย่างทั้งหมด" คุณสามารถคำนวณตัวเลขทั้งสองนี้สำหรับแต่ละตัวอย่าง และเพิ่มเป็นกลุ่มตัวอย่างเพื่อให้ได้ค่าที่ถูกต้องสำหรับตัวอย่างเหล่านั้น สามารถคำนวณความแม่นยำขั้นสุดท้ายได้โดยใช้ "ตัวอย่างที่ถูกต้องทั้งหมด / ตัวอย่างทั้งหมด"
ส่วนเสริม
ฉันสามารถใช้ TFMA เพื่อประเมินความเป็นธรรมหรืออคติในแบบจำลองของฉันได้หรือไม่
TFMA มีโปรแกรมเสริม FairnessIndicators ที่ให้ตัววัดหลังการส่งออกสำหรับการประเมินผลกระทบของอคติที่ไม่ได้ตั้งใจในแบบจำลองการจัดหมวดหมู่
การปรับแต่ง
จะทำอย่างไรถ้าฉันต้องการการปรับแต่งเพิ่มเติม?
TFMA มีความยืดหยุ่นมากและช่วยให้คุณสามารถปรับแต่งไปป์ไลน์เกือบทั้งหมดได้โดยใช้ Extractors , Evaluators และ/หรือ Writers แบบกำหนดเอง บทคัดย่อเหล่านี้จะกล่าวถึงรายละเอียดเพิ่มเติมในเอกสาร สถาปัตยกรรม
การแก้ไขปัญหา การแก้ไขจุดบกพร่อง และการขอความช่วยเหลือ
เหตุใดตัววัด MultiClassConfusionMatrix จึงไม่ตรงกับตัววัด ConfusionMatrix แบบไบนาไรซ์
จริงๆ แล้วนี่เป็นการคำนวณที่แตกต่างกัน ไบนาไรเซชันจะทำการเปรียบเทียบสำหรับ ID คลาสแต่ละรายการโดยแยกจากกัน (เช่น การคาดการณ์สำหรับแต่ละคลาสจะถูกเปรียบเทียบแยกกันกับเกณฑ์ที่ให้ไว้) ในกรณีนี้ เป็นไปได้ที่คลาสตั้งแต่สองคลาสขึ้นไปจะระบุว่าตรงกับการทำนาย เนื่องจากค่าที่คาดการณ์ไว้มากกว่าเกณฑ์ (ซึ่งจะเห็นได้ชัดเจนยิ่งขึ้นที่เกณฑ์ต่ำกว่า) ในกรณีของเมทริกซ์ความสับสนแบบหลายคลาส ยังคงมีค่าทำนายจริงเพียงค่าเดียวเท่านั้น และค่าดังกล่าวจะตรงกับค่าจริงหรือไม่ก็ได้ เกณฑ์นี้ใช้เพื่อบังคับให้การคาดคะเนไม่ตรงกับคลาสใดคลาสหนึ่งเท่านั้น หากมีค่าน้อยกว่าเกณฑ์ ยิ่งเกณฑ์สูงเท่าไร การทำนายของคลาสแบบไบนารี่ก็จะยิ่งยากขึ้นเท่านั้น ในทำนองเดียวกันยิ่งเกณฑ์ที่ต่ำลงก็ยิ่งง่ายขึ้นสำหรับการคาดการณ์ของคลาสไบนารี่ที่จะจับคู่กัน หมายความว่าที่ขีดจำกัด > 0.5 ค่าไบนารี่และค่าเมทริกซ์หลายคลาสจะถูกจัดชิดให้ใกล้ชิดยิ่งขึ้น และที่ขีดจำกัด < 0.5 ค่าทั้งสองจะอยู่ห่างกันมากขึ้น
ตัวอย่างเช่น สมมติว่าเรามี 10 คลาสโดยที่คลาส 2 ถูกทำนายไว้ด้วยความน่าจะเป็น 0.8 แต่คลาสจริงคือคลาส 1 ซึ่งมีความน่าจะเป็น 0.15 หากคุณไบนาไรซ์ในคลาส 1 และใช้เกณฑ์ที่ 0.1 คลาส 1 จะถือว่าถูกต้อง (0.15 > 0.1) ดังนั้นจะถูกนับเป็น TP อย่างไรก็ตาม สำหรับกรณีมัลติคลาส คลาส 2 จะถือว่าถูกต้อง (0.8 > 0.1) และเนื่องจากคลาส 1 เป็นคลาสจริง จึงจะนับเป็น FN เนื่องจากที่เกณฑ์ที่ต่ำกว่า ค่าต่างๆ จะถูกพิจารณาว่าเป็นบวก โดยทั่วไปจะมีการนับ TP และ FP สำหรับเมทริกซ์ความสับสนแบบไบนาไรซ์ที่สูงกว่าเมทริกซ์ความสับสนแบบหลายคลาส และ TN และ FN ที่ต่ำกว่าในทำนองเดียวกัน
ต่อไปนี้เป็นตัวอย่างของความแตกต่างที่สังเกตได้ระหว่าง MultiClassConfusionMatrixAtThresholds และการนับที่สอดคล้องกันจากไบนาไรเซชันของคลาสใดคลาสหนึ่ง
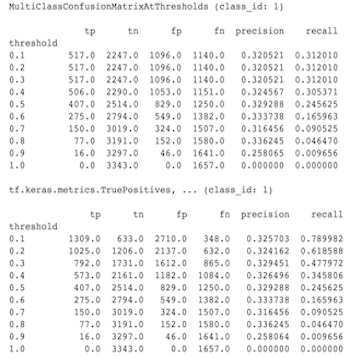
เหตุใดตัววัด precision@1 และcall@1 ของฉันจึงมีค่าเท่ากัน
ที่ค่า k บนสุดเท่ากับ 1 ความแม่นยำและการเรียกคืนเป็นสิ่งเดียวกัน ความแม่นยำเท่ากับ TP / (TP + FP) และการเรียกคืนเท่ากับ TP / (TP + FN) การทำนายอันดับสูงสุดจะเป็นค่าบวกเสมอ และจะตรงกันหรือไม่ตรงกับป้ายกำกับ กล่าวอีกนัยหนึ่ง ด้วยตัวอย่าง N TP + FP = N อย่างไรก็ตาม หากป้ายกำกับไม่ตรงกับคำทำนายอันดับบนสุด ก็หมายความว่าการทำนาย k ที่ไม่ใช่อันดับสูงสุดนั้นตรงกัน และเมื่อ k อันดับสูงสุดตั้งค่าเป็น 1 การทำนายอันดับ 1 ที่ไม่ใช่อันดับสูงสุดทั้งหมดจะเป็น 0 นี่หมายถึง FN ต้องเป็น (N - TP) หรือ N = TP + FN . ผลลัพธ์ที่ได้คือ precision@1 = TP / N = recall@1 โปรดทราบว่าการดำเนินการนี้มีผลเฉพาะเมื่อมีป้ายกำกับเดียวต่อตัวอย่าง ไม่ใช่สำหรับหลายป้ายกำกับ
เหตุใดเมตริก Mean_label และ Mean_prediction ของฉันจึงเป็น 0.5 เสมอ
กรณีนี้น่าจะเกิดขึ้นได้มากที่สุดเนื่องจากมีการกำหนดค่าหน่วยเมตริกสำหรับปัญหาการจำแนกประเภทไบนารี แต่แบบจำลองกำลังแสดงความน่าจะเป็นสำหรับทั้งสองคลาส แทนที่จะเป็นเพียงคลาสเดียว นี่เป็นเรื่องปกติเมื่อใช้ Classification API ของ tensorflow วิธีแก้ไขคือเลือกคลาสที่คุณต้องการให้การทำนายยึดตาม จากนั้นจึงแบ่งไบนารีของคลาสนั้น ตัวอย่างเช่น:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
จะตีความ MultiLabelConfusionMatrixPlot ได้อย่างไร
เมื่อพิจารณาจากป้ายกำกับเฉพาะ MultiLabelConfusionMatrixPlot (และ MultiLabelConfusionMatrix ที่เกี่ยวข้อง) สามารถใช้เพื่อเปรียบเทียบผลลัพธ์ของป้ายกำกับอื่นและการคาดคะเนเมื่อป้ายกำกับที่เลือกเป็นจริง ตัวอย่างเช่น สมมติว่าเรามีสามคลาสคือ bird , plane และ superman และเรากำลังจัดหมวดหมู่รูปภาพเพื่อระบุว่ารูปภาพเหล่านั้นมีคลาสใดคลาสหนึ่งหรือหลายคลาสเหล่านี้ MultiLabelConfusionMatrix จะคำนวณผลคูณคาร์ทีเซียนของแต่ละคลาสจริงเทียบกับคลาสอื่น (เรียกว่าคลาสที่คาดการณ์) โปรดทราบว่าในขณะที่การจับคู่คือ (actual, predicted) คลาส predicted ไม่จำเป็นต้องหมายความถึงการทำนายเชิงบวก แต่เพียงแสดงถึงคอลัมน์ที่ทำนายในเมทริกซ์จริงเทียบกับที่ทำนายไว้ ตัวอย่างเช่น สมมติว่าเราได้คำนวณเมทริกซ์ต่อไปนี้:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot มีสามวิธีในการแสดงข้อมูลนี้ ในทุกกรณี วิธีการอ่านตารางจะเป็นแบบแถวต่อแถวจากมุมมองของคลาสจริง
1) จำนวนการคาดการณ์ทั้งหมด
ในกรณีนี้ สำหรับแถวที่กำหนด (เช่น คลาสจริง) TP + FP นับเท่าใดสำหรับคลาสอื่นๆ สำหรับการนับข้างต้น การแสดงผลของเราจะเป็นดังนี้:
| นกที่ทำนายไว้ | เครื่องบินที่คาดการณ์ไว้ | ซูเปอร์แมนที่ทำนายไว้ | |
|---|---|---|---|
| นกจริง | 6 | 4 | 2 |
| เครื่องบินจริง | 4 | 4 | 4 |
| ซุปเปอร์แมนจริงๆ | 5 | 5 | 4 |
เมื่อรูปภาพมี bird อยู่จริงๆ เราก็ทำนายได้ถูกต้องถึง 6 ตัว ในเวลาเดียวกัน เราก็ทำนาย plane (ถูกหรือผิด) 4 ครั้ง และ superman (ถูกหรือผิด) 2 ครั้ง
2) การนับการคาดการณ์ไม่ถูกต้อง
ในกรณีนี้ สำหรับแถวที่กำหนด (เช่น คลาสจริง) FP นับเท่าใดสำหรับคลาสอื่นๆ สำหรับการนับข้างต้น การแสดงผลของเราจะเป็นดังนี้:
| นกที่ทำนายไว้ | เครื่องบินที่คาดการณ์ไว้ | ซูเปอร์แมนที่ทำนายไว้ | |
|---|---|---|---|
| นกจริง | 0 | 2 | 1 |
| เครื่องบินจริง | 1 | 0 | 3 |
| ซุปเปอร์แมนจริงๆ | 2 | 3 | 0 |
เมื่อรูปภาพมี bird จริงๆ เราทำนาย plane ผิด 2 ครั้ง และ superman 1 ครั้ง
3) จำนวนลบที่เป็นเท็จ
ในกรณีนี้ สำหรับแถวที่กำหนด (เช่น คลาสจริง) FN นับเท่าใดสำหรับคลาสอื่นๆ สำหรับการนับข้างต้น การแสดงผลของเราจะเป็นดังนี้:
| นกที่ทำนายไว้ | เครื่องบินที่คาดการณ์ไว้ | ซูเปอร์แมนที่ทำนายไว้ | |
|---|---|---|---|
| นกจริง | 2 | 2 | 4 |
| เครื่องบินจริง | 1 | 4 | 3 |
| ซุปเปอร์แมนจริงๆ | 2 | 2 | 5 |
เมื่อรูปภาพมี bird อยู่จริงๆ เราล้มเหลวในการคาดเดาถึง 2 ครั้ง ในเวลาเดียวกัน เราล้มเหลวในการทำนาย plane 2 ครั้ง และ superman 4 ครั้ง
เหตุใดฉันจึงได้รับข้อผิดพลาดเกี่ยวกับไม่พบคีย์การทำนาย
โมเดลบางรุ่นก็แสดงคำทำนายออกมาในรูปแบบของพจนานุกรม ตัวอย่างเช่น ตัวประมาณค่า TF สำหรับปัญหาการจำแนกประเภทไบนารี่จะส่งออกพจนานุกรมที่มี probabilities , class_ids เป็นต้น ในกรณีส่วนใหญ่ TFMA จะมีค่าเริ่มต้นสำหรับการค้นหาชื่อคีย์ที่ใช้กันทั่วไป เช่น predictions probabilities เป็น ฯลฯ อย่างไรก็ตาม หากแบบจำลองของคุณได้รับการปรับแต่งอย่างมาก ก็อาจ คีย์เอาต์พุตภายใต้ชื่อที่ TFMA ไม่รู้จัก ในกรณีเหล่านี้ จะต้องเพิ่มการตั้ง prediciton_key ใน tfma.ModelSpec เพื่อระบุชื่อของคีย์ที่ใช้จัดเก็บเอาต์พุต