
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
API tf.distribute.Strategy cung cấp một bản tóm tắt để phân phối đào tạo của bạn trên nhiều đơn vị xử lý. Nó cho phép bạn thực hiện đào tạo phân tán bằng cách sử dụng các mô hình và mã đào tạo hiện có với những thay đổi tối thiểu.
Hướng dẫn này trình bày cách sử dụng tf.distribute.MirroredStrategy để thực hiện sao chép trong đồ thị với đào tạo đồng bộ trên nhiều GPU trên một máy . Về cơ bản, chiến lược sao chép tất cả các biến của mô hình vào mỗi bộ xử lý. Sau đó, nó sử dụng all-Reduce để kết hợp các gradient từ tất cả các bộ xử lý và áp dụng giá trị kết hợp cho tất cả các bản sao của mô hình.
Bạn sẽ sử dụng các API tf.keras để xây dựng mô hình và Model.fit để đào tạo nó. (Để tìm hiểu về đào tạo phân tán với vòng lặp đào tạo tùy chỉnh và MirroredStrategy , hãy xem hướng dẫn này .)
MirroredStrategy đào tạo mô hình của bạn trên nhiều GPU trên một máy duy nhất. Để đào tạo đồng bộ trên nhiều GPU trên nhiều nhân viên , hãy sử dụng tf.distribute.MultiWorkerMirroredStrategy với Keras Model.fit hoặc vòng đào tạo tùy chỉnh . Đối với các tùy chọn khác, hãy tham khảo Hướng dẫn đào tạo phân tán .
Để tìm hiểu về nhiều chiến lược khác, có hướng dẫn Đào tạo phân tán với TensorFlow .
Thành lập
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
2.8.0-rc1
Tải xuống tập dữ liệu
Tải tập dữ liệu MNIST từ Tập dữ liệu TensorFlow . Điều này trả về một tập dữ liệu ở định dạng tf.data .
Đặt đối số with_info thành True bao gồm siêu dữ liệu cho toàn bộ tập dữ liệu, đang được lưu ở đây để làm info . Trong số những thứ khác, đối tượng siêu dữ liệu này bao gồm số lượng các ví dụ về huấn luyện và thử nghiệm.
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
Xác định chiến lược phân phối
Tạo một đối tượng MirroredStrategy . Điều này sẽ xử lý phân phối và cung cấp trình quản lý ngữ cảnh ( MirroredStrategy.scope ) để xây dựng mô hình của bạn bên trong.
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 1
Thiết lập đường dẫn đầu vào
Khi đào tạo một mô hình có nhiều GPU, bạn có thể sử dụng hiệu quả sức mạnh tính toán bổ sung bằng cách tăng kích thước lô. Nói chung, hãy sử dụng kích thước lô lớn nhất phù hợp với bộ nhớ GPU và điều chỉnh tốc độ học tập cho phù hợp.
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
Xác định một hàm chuẩn hóa các giá trị pixel hình ảnh từ phạm vi [0, 255] đến phạm vi [0, 1] ( tỷ lệ tính năng ):
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
Áp dụng hàm scale này cho dữ liệu đào tạo và kiểm tra, sau đó sử dụng các API tf.data.Dataset để xáo trộn dữ liệu đào tạo ( Dataset.shuffle ) và hàng loạt ( Dataset.batch ). Lưu ý rằng bạn cũng đang giữ một bộ nhớ đệm trong bộ nhớ của dữ liệu đào tạo để cải thiện hiệu suất ( Dataset.cache ).
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
Tạo mô hình
Tạo và biên dịch mô hình Keras trong bối cảnh của Strategy.scope :
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
Xác định các lệnh gọi lại
Xác định tf.keras.callbacks sau:
-
tf.keras.callbacks.TensorBoard: ghi nhật ký cho TensorBoard, cho phép bạn trực quan hóa các biểu đồ. -
tf.keras.callbacks.ModelCheckpoint: lưu mô hình ở một tần suất nhất định, chẳng hạn như sau mỗi kỷ nguyên. -
tf.keras.callbacks.LearningRateScheduler: lập lịch trình tốc độ học tập thay đổi sau, ví dụ: mỗi kỷ nguyên / đợt.
Đối với các mục đích minh họa, hãy thêm một lệnh gọi lại tùy chỉnh được gọi là PrintLR để hiển thị tốc độ học tập trong sổ ghi chép.
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
Đào tạo và đánh giá
Bây giờ, đào tạo mô hình theo cách thông thường bằng cách gọi Model.fit trên mô hình và chuyển vào tập dữ liệu được tạo ở đầu hướng dẫn. Bước này giống nhau cho dù bạn có đang phân phối chương trình đào tạo hay không.
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-01-26 05:38:28.865380: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
933/938 [============================>.] - ETA: 0s - loss: 0.2029 - accuracy: 0.9399
Learning rate for epoch 1 is 0.0010000000474974513
938/938 [==============================] - 10s 4ms/step - loss: 0.2022 - accuracy: 0.9401 - lr: 0.0010
Epoch 2/12
930/938 [============================>.] - ETA: 0s - loss: 0.0654 - accuracy: 0.9813
Learning rate for epoch 2 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0652 - accuracy: 0.9813 - lr: 0.0010
Epoch 3/12
931/938 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9864
Learning rate for epoch 3 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0453 - accuracy: 0.9864 - lr: 0.0010
Epoch 4/12
923/938 [============================>.] - ETA: 0s - loss: 0.0246 - accuracy: 0.9933
Learning rate for epoch 4 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0244 - accuracy: 0.9934 - lr: 1.0000e-04
Epoch 5/12
929/938 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9944
Learning rate for epoch 5 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0212 - accuracy: 0.9944 - lr: 1.0000e-04
Epoch 6/12
930/938 [============================>.] - ETA: 0s - loss: 0.0192 - accuracy: 0.9950
Learning rate for epoch 6 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0194 - accuracy: 0.9950 - lr: 1.0000e-04
Epoch 7/12
927/938 [============================>.] - ETA: 0s - loss: 0.0179 - accuracy: 0.9953
Learning rate for epoch 7 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0179 - accuracy: 0.9953 - lr: 1.0000e-04
Epoch 8/12
938/938 [==============================] - ETA: 0s - loss: 0.0153 - accuracy: 0.9966
Learning rate for epoch 8 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0153 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 9/12
927/938 [============================>.] - ETA: 0s - loss: 0.0151 - accuracy: 0.9966
Learning rate for epoch 9 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0150 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 10/12
935/938 [============================>.] - ETA: 0s - loss: 0.0148 - accuracy: 0.9966
Learning rate for epoch 10 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0148 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 11/12
937/938 [============================>.] - ETA: 0s - loss: 0.0146 - accuracy: 0.9967
Learning rate for epoch 11 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0146 - accuracy: 0.9967 - lr: 1.0000e-05
Epoch 12/12
926/938 [============================>.] - ETA: 0s - loss: 0.0145 - accuracy: 0.9967
Learning rate for epoch 12 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0144 - accuracy: 0.9967 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fad70067c10>
Kiểm tra các điểm kiểm tra đã lưu:
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
Để kiểm tra xem mô hình hoạt động tốt như thế nào, hãy tải điểm kiểm tra mới nhất và gọi Model.evaluate trên dữ liệu thử nghiệm:
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:15.260539: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 2s 4ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval accuracy: 0.9879000186920166
Để trực quan hóa kết quả đầu ra, hãy khởi chạy TensorBoard và xem nhật ký:
%tensorboard --logdir=logs
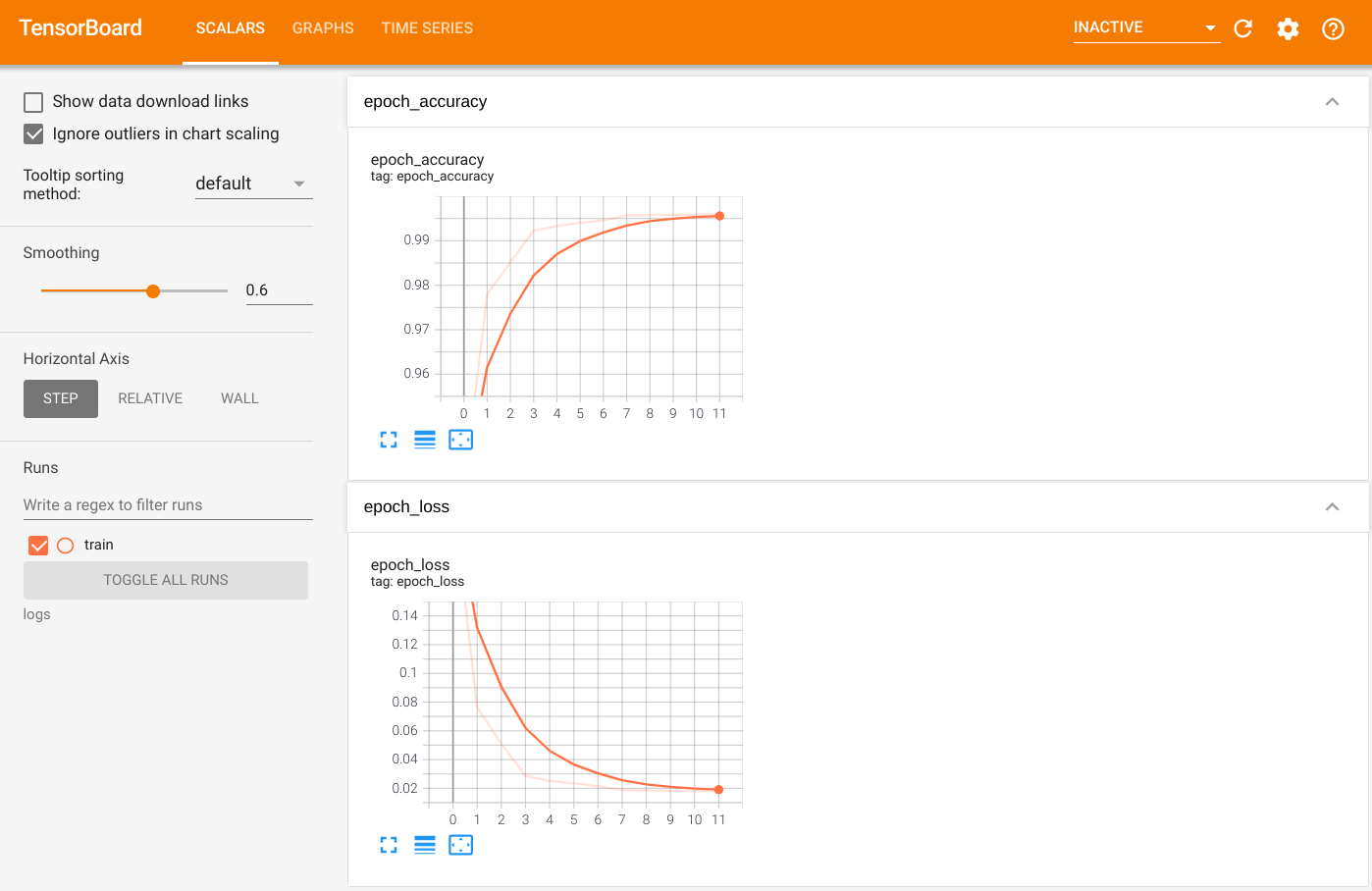
ls -sh ./logs
total 4.0K 4.0K train
Xuất sang SavedModel
Xuất biểu đồ và các biến sang định dạng SavedModel bất khả tri nền tảng bằng cách sử dụng Model.save . Sau khi mô hình của bạn được lưu, bạn có thể tải nó có hoặc không có Strategy.scope .
path = 'saved_model/'
model.save(path, save_format='tf')
2022-01-26 05:39:18.012847: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
Bây giờ, tải mô hình mà không có Strategy.scope :
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
157/157 [==============================] - 1s 2ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
Tải mô hình bằng Strategy.scope :
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:19.489971: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 3s 3ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
Tài nguyên bổ sung
Các ví dụ khác sử dụng các chiến lược phân phối khác nhau với API Model.fit :
- Hướng dẫn Giải quyết các tác vụ GLUE bằng BERT trên TPU sử dụng
tf.distribute.MirroredStrategyđể đào tạo về GPU vàtf.distribute.TPUStrategy—trên TPU. - Lưu và tải mô hình bằng hướng dẫn chiến lược phân phối trình bày cách sử dụng các API SavedModel với
tf.distribute.Strategy. - Các mô hình TensorFlow chính thức có thể được định cấu hình để chạy nhiều chiến lược phân phối.
Để tìm hiểu thêm về các chiến lược phân phối TensorFlow:
- Hướng dẫn đào tạo tùy chỉnh với tf.distribute.Strategy cho biết cách sử dụng
tf.distribute.MirroredStrategyđể đào tạo một nhân viên với vòng lặp đào tạo tùy chỉnh. - Hướng dẫn đào tạo nhiều nhân viên với Keras chỉ ra cách sử dụng
MultiWorkerMirroredStrategyvớiModel.fit. - Vòng đào tạo tùy chỉnh với Keras và MultiWorkerMirroredStrategy hướng dẫn cách sử dụng
MultiWorkerMirroredStrategyvới Keras và một vòng đào tạo tùy chỉnh. - Hướng dẫn đào tạo Phân phối trong TensorFlow cung cấp tổng quan về các chiến lược phân phối có sẵn.
- Hướng dẫn Hiệu suất tốt hơn với tf. Chức năng cung cấp thông tin về các chiến lược và công cụ khác, chẳng hạn như TensorFlow Profiler mà bạn có thể sử dụng để tối ưu hóa hiệu suất của các mô hình TensorFlow của mình.