
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini menunjukkan cara membangun dan melatih jaringan permusuhan generatif bersyarat (cGAN) yang disebut pix2pix yang mempelajari pemetaan dari gambar masukan ke gambar keluaran, seperti yang dijelaskan dalam Terjemahan gambar-ke-gambar dengan jaringan permusuhan bersyarat oleh Isola et al. (2017). pix2pix bukan aplikasi khusus—ini dapat diterapkan ke berbagai tugas, termasuk mensintesis foto dari peta label, menghasilkan foto berwarna dari gambar hitam putih, mengubah foto Google Maps menjadi gambar udara, dan bahkan mengubah sketsa menjadi foto.
Dalam contoh ini, jaringan Anda akan menghasilkan gambar fasad bangunan menggunakan Basis Data Fasad CMP yang disediakan oleh Pusat Persepsi Mesin di Universitas Teknik Ceko di Praha . Singkatnya, Anda akan menggunakan salinan praproses dari kumpulan data ini yang dibuat oleh penulis pix2pix.
Di pix2pix cGAN, Anda mengkondisikan gambar input dan menghasilkan gambar output yang sesuai. cGAN pertama kali diusulkan di Conditional Generative Adversarial Nets (Mirza dan Osindero, 2014)
Arsitektur jaringan Anda akan berisi:
- Generator dengan arsitektur berbasis U-Net .
- Diskriminator diwakili oleh pengklasifikasi PatchGAN convolutional (diusulkan dalam kertas pix2pix ).
Perhatikan bahwa setiap zaman dapat memakan waktu sekitar 15 detik pada satu GPU V100.
Di bawah ini adalah beberapa contoh output yang dihasilkan oleh pix2pix cGAN setelah pelatihan selama 200 epoch pada dataset fasad (80rb langkah).


Impor TensorFlow dan perpustakaan lainnya
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
Muat kumpulan data
Unduh data Basis Data Fasad CMP (30MB). Kumpulan data tambahan tersedia dalam format yang sama di sini . Di Colab, Anda dapat memilih set data lain dari menu drop-down. Perhatikan bahwa beberapa kumpulan data lain secara signifikan lebih besar ( edges2handbags adalah 8GB).
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
Setiap gambar asli berukuran 256 x 512 berisi dua gambar 256 x 256 :
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
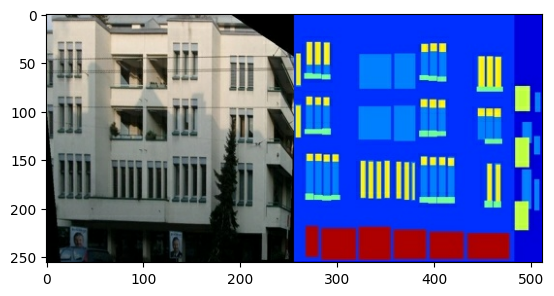
Anda perlu memisahkan gambar fasad bangunan asli dari gambar label arsitektur—semuanya akan berukuran 256 x 256 .
Tentukan fungsi yang memuat file gambar dan mengeluarkan dua tensor gambar:
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
Plot sampel input (gambar label arsitektur) dan gambar nyata (foto fasad bangunan):
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
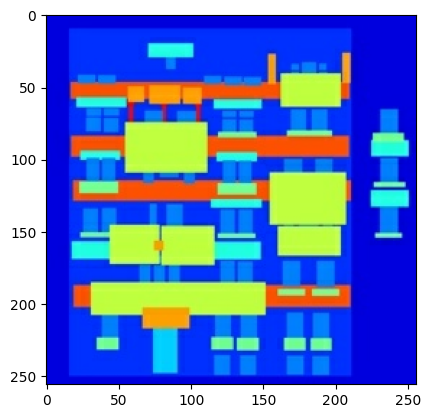
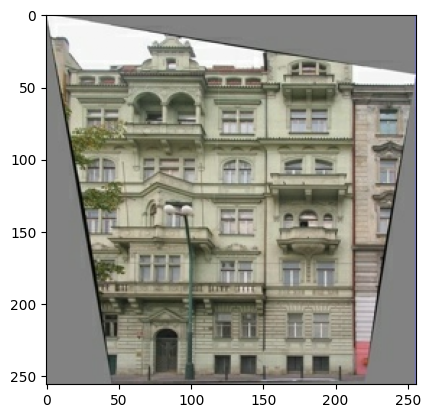
Seperti yang dijelaskan dalam makalah pix2pix , Anda perlu menerapkan jittering dan mirroring acak untuk melakukan praproses set pelatihan.
Tentukan beberapa fungsi yang:
- Ubah ukuran setiap gambar
256 x 256ke tinggi dan lebar yang lebih besar—286 x 286. - Pangkas secara acak kembali ke
256 x 256. - Balikkan gambar secara acak secara horizontal yaitu dari kiri ke kanan (pencerminan acak).
- Normalisasikan gambar ke kisaran
[-1, 1].
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
Anda dapat memeriksa beberapa keluaran yang telah diproses sebelumnya:
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
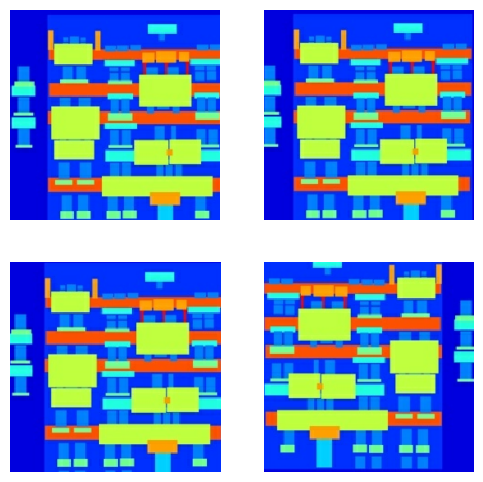
Setelah memeriksa apakah pemuatan dan prapemrosesan berfungsi, mari kita definisikan beberapa fungsi pembantu yang memuat dan melakukan praproses set pelatihan dan pengujian:
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
Bangun saluran input dengan tf.data
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
Bangun generatornya
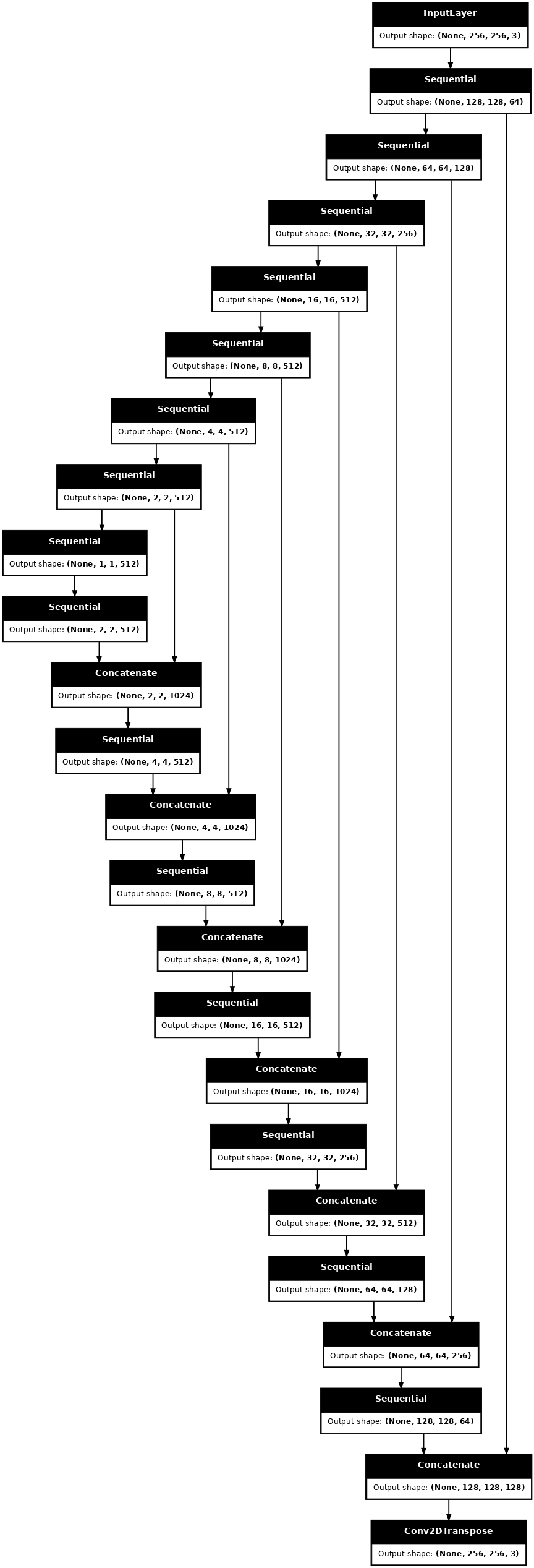
Generator pix2pix cGAN Anda adalah U-Net yang dimodifikasi . Sebuah U-Net terdiri dari encoder (downsampler) dan decoder (upsampler). (Anda dapat mengetahui lebih lanjut tentangnya di tutorial Segmentasi gambar dan di situs web proyek U-Net .)
- Setiap blok di encoder adalah: Konvolusi -> Normalisasi batch -> Leaky ReLU
- Setiap blok dalam dekoder adalah: Transposed convolution -> Batch normalization -> Dropout (diterapkan pada 3 blok pertama) -> ReLU
- Ada koneksi lewati antara encoder dan decoder (seperti di U-Net).
Tentukan downsampler (encoder):
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
Tentukan upsampler (dekoder):
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
Tentukan generator dengan downsampler dan upsampler:
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Visualisasikan arsitektur model generator:
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
Uji generatornya:
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
Tentukan kerugian generator
GAN mempelajari kerugian yang beradaptasi dengan data, sementara cGAN mempelajari kerugian terstruktur yang menghukum kemungkinan struktur yang berbeda dari keluaran jaringan dan gambar target, seperti yang dijelaskan dalam makalah pix2pix .
- Kehilangan generator adalah kehilangan entropi silang sigmoid dari gambar yang dihasilkan dan array gambar .
- Kertas pix2pix juga menyebutkan hilangnya L1, yang merupakan MAE (kesalahan absolut rata-rata) antara gambar yang dihasilkan dan gambar target.
- Ini memungkinkan gambar yang dihasilkan menjadi mirip secara struktural dengan gambar target.
- Rumus untuk menghitung total loss generator adalah
gan_loss + LAMBDA * l1_loss, dimana LAMBDALAMBDA = 100. Nilai ini diputuskan oleh penulis makalah.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
Prosedur pelatihan untuk generator adalah sebagai berikut:

Bangun diskriminator
Diskriminator dalam pix2pix cGAN adalah pengklasifikasi PatchGAN convolutional—ia mencoba mengklasifikasikan apakah setiap patch gambar nyata atau tidak, seperti yang dijelaskan dalam kertas pix2pix .
- Setiap blok dalam diskriminator adalah: Konvolusi -> Normalisasi batch -> Leaky ReLU.
- Bentuk output setelah lapisan terakhir adalah
(batch_size, 30, 30, 1). - Setiap tambalan gambar
30 x 30dari keluaran mengklasifikasikan bagian70 x 70dari gambar masukan. - Diskriminator menerima 2 masukan:
- Gambar input dan gambar target, yang harus diklasifikasikan sebagai nyata.
- Gambar input dan gambar yang dihasilkan (output dari generator), yang harus diklasifikasikan sebagai palsu.
- Gunakan
tf.concat([inp, tar], axis=-1)untuk menggabungkan 2 input ini bersama-sama.
Mari kita definisikan diskriminatornya:
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
Visualisasikan arsitektur model diskriminator:
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)

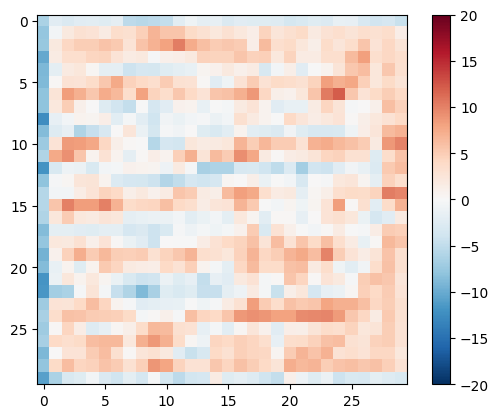
Uji diskriminator:
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>
Tentukan kerugian diskriminator
- Fungsi
discriminator_lossmengambil 2 input: gambar nyata dan gambar yang dihasilkan . -
real_lossadalah sigmoid cross-entropy loss dari gambar nyata dan array (karena ini adalah gambar nyata) . -
generated_lossadalah kerugian lintas entropi sigmoid dari gambar yang dihasilkan dan larik nol (karena ini adalah gambar palsu) . -
total_lossadalah jumlah darireal_lossdangenerated_loss.
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
Prosedur pelatihan untuk diskriminator ditunjukkan di bawah ini.
Untuk mempelajari lebih lanjut tentang arsitektur dan hyperparameter, Anda dapat merujuk ke makalah pix2pix .

Tentukan pengoptimal dan penghemat pos pemeriksaan
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Hasilkan gambar
Tulis fungsi untuk memplot beberapa gambar selama pelatihan.
- Lewati gambar dari set pengujian ke generator.
- Generator kemudian akan menerjemahkan gambar input menjadi output.
- Langkah terakhir adalah merencanakan prediksi dan voila !
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Uji fungsinya:
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

Pelatihan
- Untuk setiap contoh input menghasilkan output.
- Diskriminator menerima
input_imagedan gambar yang dihasilkan sebagai input pertama. Input kedua adalahinput_imagedantarget_image. - Selanjutnya, hitung generator dan rugi-rugi diskriminator.
- Kemudian, hitung gradien kerugian sehubungan dengan generator dan variabel diskriminator (input) dan terapkan pada pengoptimal.
- Terakhir, catat kerugian ke TensorBoard.
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
Lingkaran pelatihan yang sebenarnya. Karena tutorial ini dapat menjalankan lebih dari satu set data, dan ukuran set data sangat bervariasi, loop pelatihan diatur untuk bekerja dalam langkah, bukan epoch.
- Iterasi atas jumlah langkah.
- Setiap 10 langkah cetak titik (
.). - Setiap 1.000 langkah: bersihkan tampilan dan jalankan
generate_imagesuntuk menunjukkan kemajuan. - Setiap 5k langkah: simpan pos pemeriksaan.
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
Loop pelatihan ini menyimpan log yang dapat Anda lihat di TensorBoard untuk memantau kemajuan pelatihan.
Jika Anda bekerja pada mesin lokal, Anda akan meluncurkan proses TensorBoard terpisah. Saat bekerja di notebook, luncurkan penampil sebelum memulai pelatihan untuk memantau dengan TensorBoard.
Untuk meluncurkan penampil, rekatkan yang berikut ini ke dalam sel kode:
%load_ext tensorboard
%tensorboard --logdir {log_dir}
Terakhir, jalankan loop pelatihan:
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
Jika Anda ingin membagikan hasil TensorBoard secara publik , Anda dapat mengunggah log ke TensorBoard.dev dengan menyalin kode berikut ke dalam sel kode.
tensorboard dev upload --logdir {log_dir}
Anda dapat melihat hasil dari menjalankan notebook ini sebelumnya di TensorBoard.dev .
TensorBoard.dev adalah pengalaman terkelola untuk menghosting, melacak, dan berbagi eksperimen ML dengan semua orang.
Itu juga dapat dimasukkan sebaris menggunakan <iframe> :
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
Menafsirkan log lebih halus saat melatih GAN (atau cGAN seperti pix2pix) dibandingkan dengan klasifikasi sederhana atau model regresi. Hal-hal yang harus dicari:
- Periksa apakah generator maupun model diskriminator tidak "menang". Jika
gen_gan_lossataudisc_lossmenjadi sangat rendah, ini merupakan indikator bahwa model ini mendominasi yang lain, dan Anda tidak berhasil melatih model gabungan. - Nilai
log(2) = 0.69adalah titik referensi yang baik untuk kerugian ini, karena menunjukkan kebingungan 2 - pembeda, rata-rata, sama-sama tidak pasti tentang dua opsi. - Untuk
disc_loss, nilai di bawah0.69berarti diskriminator bekerja lebih baik daripada acak pada kumpulan gabungan gambar nyata dan gambar yang dihasilkan. - Untuk
gen_gan_loss, nilai di bawah0.69berarti generator bekerja lebih baik daripada acak dalam membodohi diskriminator. - Saat pelatihan berlangsung,
gen_l1_lossakan turun.
Pulihkan pos pemeriksaan terbaru dan uji jaringan
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.index
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
Hasilkan beberapa gambar menggunakan set tes
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




