
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Panoramica
Questo tutorial mostra l'aumento dei dati: una tecnica per aumentare la diversità del tuo set di allenamento applicando trasformazioni casuali (ma realistiche), come la rotazione dell'immagine.
Imparerai come applicare l'aumento dei dati in due modi:
- Usa i livelli di preelaborazione Keras, come
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlipetf.keras.layers.RandomRotation. - Utilizzare i metodi
tf.image, cometf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_cropetf.image.stateless_random*.
Impostare
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
Scarica un set di dati
Questo tutorial utilizza il set di dati tf_flowers . Per comodità, scarica il set di dati utilizzando TensorFlow Datasets . Se desideri conoscere altri modi per importare i dati, dai un'occhiata al tutorial di caricamento delle immagini .
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Il set di dati Flowers ha cinque classi.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Recuperiamo un'immagine dal set di dati e la usiamo per dimostrare l'aumento dei dati.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Usa i livelli di preelaborazione Keras
Ridimensionamento e ridimensionamento
Puoi utilizzare i livelli di preelaborazione di Keras per ridimensionare le immagini in una forma coerente (con tf.keras.layers.Resizing ) e per ridimensionare i valori dei pixel (con tf.keras.layers.Rescaling ).
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
È possibile visualizzare il risultato dell'applicazione di questi livelli a un'immagine.
result = resize_and_rescale(image)
_ = plt.imshow(result)
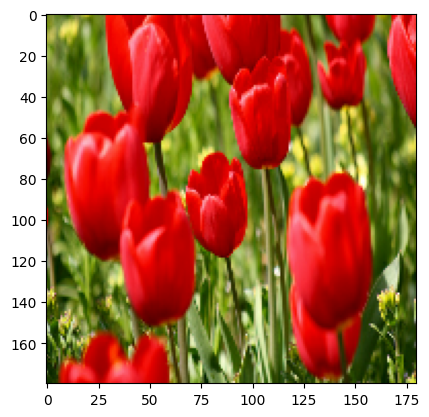
Verificare che i pixel siano compresi nell'intervallo [0, 1] :
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
Aumento dei dati
Puoi anche utilizzare i livelli di preelaborazione Keras per l'aumento dei dati, come tf.keras.layers.RandomFlip e tf.keras.layers.RandomRotation .
Creiamo alcuni livelli di preelaborazione e li applichiamo ripetutamente alla stessa immagine.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Esistono vari livelli di preelaborazione che puoi utilizzare per l'aumento dei dati, inclusi tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom e altri.
Due opzioni per utilizzare i livelli di preelaborazione Keras
Esistono due modi per utilizzare questi livelli di preelaborazione, con importanti compromessi.
Opzione 1: rendi i livelli di preelaborazione parte del tuo modello
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
Ci sono due punti importanti da tenere presente in questo caso:
L'aumento dei dati verrà eseguito sul dispositivo, in modo sincrono con il resto dei tuoi livelli e trarrà vantaggio dall'accelerazione GPU.
Quando esporti il tuo modello usando
model.save, i livelli di preelaborazione verranno salvati insieme al resto del tuo modello. Se in seguito distribuisci questo modello, standardizzerà automaticamente le immagini (in base alla configurazione dei tuoi livelli). Questo può salvarti dallo sforzo di dover reimplementare quella logica lato server.
Opzione 2: applica i livelli di preelaborazione al tuo set di dati
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
Con questo approccio, usi Dataset.map per creare un set di dati che produca batch di immagini aumentate. In questo caso:
- L'aumento dei dati avverrà in modo asincrono sulla CPU e non è bloccante. Puoi sovrapporre il training del tuo modello sulla GPU con la preelaborazione dei dati, usando
Dataset.prefetch, mostrato di seguito. - In questo caso i livelli di preelaborazione non verranno esportati con il modello quando si chiama
Model.save. Dovrai allegarli al tuo modello prima di salvarlo o reimplementarli lato server. Dopo l'addestramento, puoi allegare i livelli di preelaborazione prima dell'esportazione.
Puoi trovare un esempio della prima opzione nel tutorial sulla classificazione delle immagini . Dimostriamo qui la seconda opzione.
Applicare i livelli di preelaborazione ai set di dati
Configura i set di dati di addestramento, convalida e test con i livelli di preelaborazione Keras che hai creato in precedenza. Inoltre, configurerai i set di dati per le prestazioni, utilizzando letture parallele e prelettura bufferizzata per produrre batch dal disco senza che l'I/O si blocchi. (Ulteriori informazioni sulle prestazioni del set di dati nella guida all'API tf.data .)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
Addestra un modello
Per completezza, ora addestrerai un modello utilizzando i set di dati che hai appena preparato.
Il modello sequenziale è costituito da tre blocchi di convoluzione ( tf.keras.layers.Conv2D ) con uno strato di pooling massimo ( tf.keras.layers.MaxPooling2D ) in ciascuno di essi. C'è uno strato completamente connesso ( tf.keras.layers.Dense ) con 128 unità sopra che viene attivato da una funzione di attivazione ReLU ( 'relu' ). Questo modello non è stato ottimizzato per la precisione (l'obiettivo è mostrarti la meccanica).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Scegli l'ottimizzatore tf.keras.optimizers.Adam e la funzione di perdita tf.keras.losses.SparseCategoricalCrossentropy . Per visualizzare l'accuratezza dell'addestramento e della convalida per ogni epoca di addestramento, passa l'argomento delle metrics a Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Allenati per alcune epoche:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
Aumento dei dati personalizzato
Puoi anche creare livelli di aumento dei dati personalizzati.
Questa sezione del tutorial mostra due modi per farlo:
- Innanzitutto, creerai un livello
tf.keras.layers.Lambda. Questo è un buon modo per scrivere codice conciso. - Successivamente, scriverai un nuovo livello tramite subclassing , che ti dà più controllo.
Entrambi i livelli invertiranno casualmente i colori in un'immagine, secondo una certa probabilità.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

Quindi, implementa un livello personalizzato sottoclasse :
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

Entrambi questi livelli possono essere utilizzati come descritto nelle opzioni 1 e 2 sopra.
Usando tf.image
Le utilità di preelaborazione Keras di cui sopra sono convenienti. Ma, per un controllo più preciso, puoi scrivere le tue pipeline o livelli di aumento dei dati usando tf.data e tf.image . (Potresti anche dare un'occhiata a TensorFlow Addons Image: Operations e TensorFlow I/O: Color Space Conversions .)
Poiché il set di dati dei fiori è stato precedentemente configurato con l'aumento dei dati, reimportiamolo per ricominciare da capo:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Recupera un'immagine con cui lavorare:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Usiamo la seguente funzione per visualizzare e confrontare le immagini originali e aumentate affiancate:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
Aumento dei dati
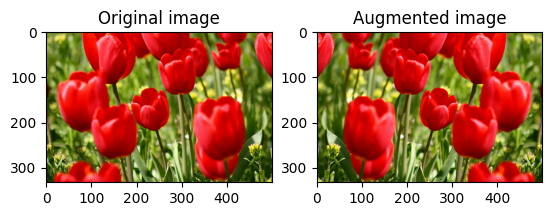
Capovolgi un'immagine
Capovolgi un'immagine verticalmente o orizzontalmente con tf.image.flip_left_right :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
Scala di grigi un'immagine
Puoi ridimensionare un'immagine in scala di grigi con tf.image.rgb_to_grayscale :
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

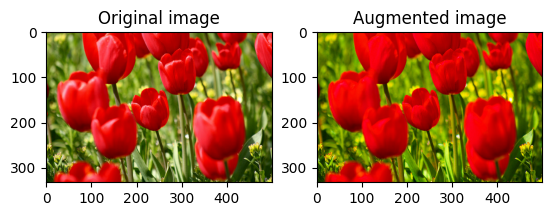
Satura un'immagine
Saturare un'immagine con tf.image.adjust_saturation fornendo un fattore di saturazione:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
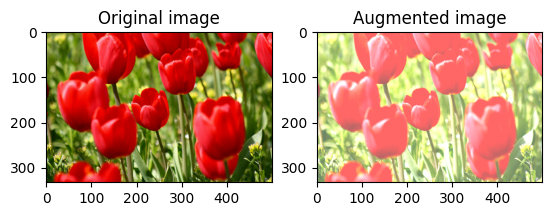
Modifica la luminosità dell'immagine
Modifica la luminosità dell'immagine con tf.image.adjust_brightness fornendo un fattore di luminosità:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
Ritaglia un'immagine al centro
Ritaglia l'immagine dal centro verso l'alto nella parte dell'immagine che desideri utilizzando tf.image.central_crop :
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
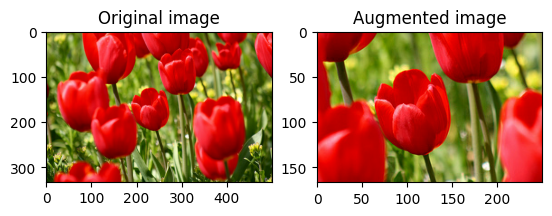
Ruota un'immagine
Ruota un'immagine di 90 gradi con tf.image.rot90 :
rotated = tf.image.rot90(image)
visualize(image, rotated)

Trasformazioni casuali
L'applicazione di trasformazioni casuali alle immagini può aiutare ulteriormente a generalizzare ed espandere il set di dati. L'attuale API tf.image fornisce otto operazioni di immagine casuali (operazioni):
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
Queste operazioni di immagine casuali sono puramente funzionali: l'output dipende solo dall'input. Questo li rende semplici da usare in pipeline di input deterministiche ad alte prestazioni. Richiedono un valore seed da inserire in ogni passaggio. Dato lo stesso seed , restituiscono gli stessi risultati indipendentemente da quante volte vengono chiamati.
Nelle seguenti sezioni, dovrai:
- Esamina esempi di utilizzo di operazioni casuali su immagini per trasformare un'immagine.
- Dimostrare come applicare trasformazioni casuali a un set di dati di addestramento.
Cambia casualmente la luminosità dell'immagine
Cambia casualmente la luminosità image usando tf.image.stateless_random_brightness fornendo un fattore di luminosità e seed . Il fattore di luminosità viene scelto casualmente nell'intervallo [-max_delta, max_delta) ed è associato al seed dato.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
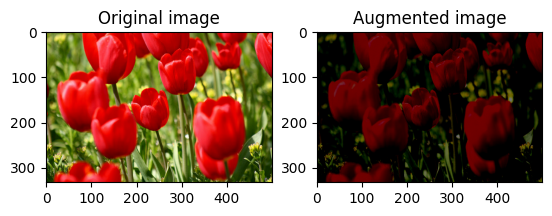
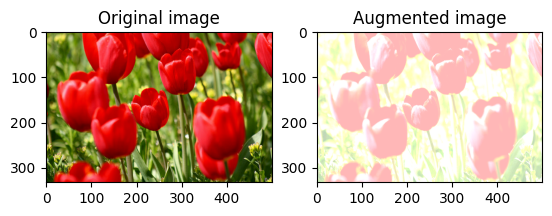
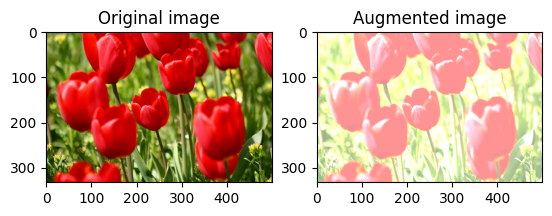
Cambia casualmente il contrasto dell'immagine
Cambia casualmente il contrasto image usando tf.image.stateless_random_contrast fornendo un intervallo di contrasto e seed . L'intervallo di contrasto viene scelto casualmente nell'intervallo [lower, upper] ed è associato al seed dato.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
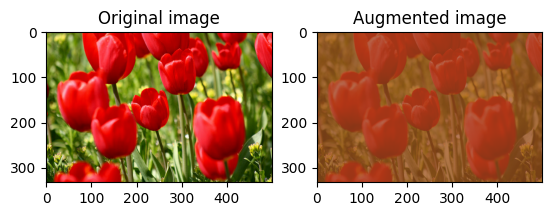
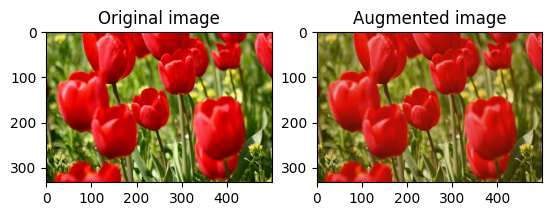
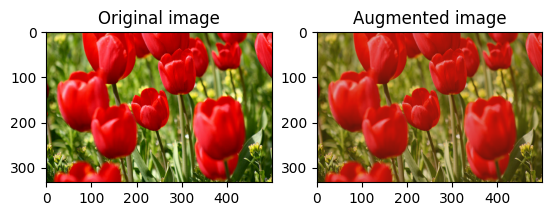
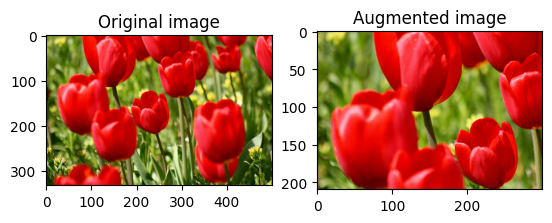
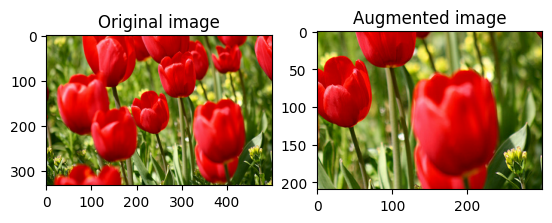
Ritaglia un'immagine in modo casuale
Ritaglia casualmente l' image usando tf.image.stateless_random_crop fornendo la size e seed di destinazione. La parte che viene ritagliata image si trova in un offset scelto casualmente ed è associata al seed dato.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
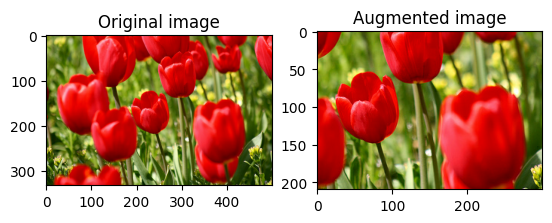
Applicare l'aumento a un set di dati
Per prima cosa scarichiamo nuovamente il dataset dell'immagine nel caso in cui siano stati modificati nelle sezioni precedenti.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Quindi, definisci una funzione di utilità per ridimensionare e ridimensionare le immagini. Questa funzione verrà utilizzata per unificare la dimensione e la scala delle immagini nel set di dati:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
Definiamo anche la funzione di augment che può applicare le trasformazioni casuali alle immagini. Questa funzione verrà utilizzata sul set di dati nel passaggio successivo.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
Opzione 1: utilizzo di tf.data.experimental.Counter
Crea un oggetto tf.data.experimental.Counter (chiamiamolo counter ) e Dataset.zip il set di dati con (counter, counter) . Ciò assicurerà che ogni immagine nel set di dati venga associata a un valore univoco (di shape (2,) ) basato sul counter che in seguito può essere passato alla funzione di augment come valore seed per trasformazioni casuali.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
augment la funzione di aumento sul set di dati di addestramento:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Opzione 2: utilizzo di tf.random.Generator
- Crea un oggetto
tf.random.Generatorcon un valoreseediniziale. La chiamata della funzionemake_seedssullo stesso oggetto generatore restituisce sempre un nuovo valoreseedunivoco. - Definire una funzione wrapper che: 1) chiami la funzione
make_seeds; e 2) passa il valoreseedappena generato nella funzione diaugmentper trasformazioni casuali.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
Mappare la funzione wrapper f al set di dati di addestramento e la funzione resize_and_rescale ai set di convalida e test:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Questi set di dati possono ora essere utilizzati per addestrare un modello come mostrato in precedenza.
Prossimi passi
Questo tutorial ha dimostrato l'aumento dei dati utilizzando i livelli di preelaborazione Keras e tf.image .
- Per informazioni su come includere i livelli di preelaborazione all'interno del modello, fare riferimento all'esercitazione sulla classificazione delle immagini .
- Potresti anche essere interessato a scoprire come la preelaborazione dei livelli può aiutarti a classificare il testo, come mostrato nell'esercitazione di base sulla classificazione del testo .
- Puoi saperne di più su
tf.datain questa guida e puoi imparare come configurare le tue pipeline di input per le prestazioni qui .