
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questo tutorial mostra come caricare e preelaborare un set di dati di immagine in tre modi:
- Innanzitutto, utilizzerai le utilità di preelaborazione Keras di alto livello (come
tf.keras.utils.image_dataset_from_directory) e i livelli (cometf.keras.layers.Rescaling) per leggere una directory di immagini su disco. - Successivamente, scriverai la tua pipeline di input da zero usando tf.data .
- Infine, scaricherai un set di dati dall'ampio catalogo disponibile in TensorFlow Datasets .
Impostare
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
Scarica il dataset dei fiori
Questo tutorial utilizza un set di dati di diverse migliaia di foto di fiori. Il dataset flowers contiene cinque sottodirectory, una per classe:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
Dopo il download (218 MB), ora dovresti avere una copia delle foto dei fiori disponibile. Ci sono 3.670 immagini in totale:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Ogni directory contiene immagini di quel tipo di fiore. Ecco alcune rose:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Carica i dati utilizzando un'utilità Keras
Carichiamo queste immagini dal disco usando l'utile utility tf.keras.utils.image_dataset_from_directory .
Crea un set di dati
Definire alcuni parametri per il caricatore:
batch_size = 32
img_height = 180
img_width = 180
È buona norma utilizzare una divisione di convalida durante lo sviluppo del modello. Utilizzerai l'80% delle immagini per la formazione e il 20% per la convalida.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Puoi trovare i nomi delle classi nell'attributo class_names su questi set di dati.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Visualizza i dati
Ecco le prime nove immagini del set di dati di addestramento.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
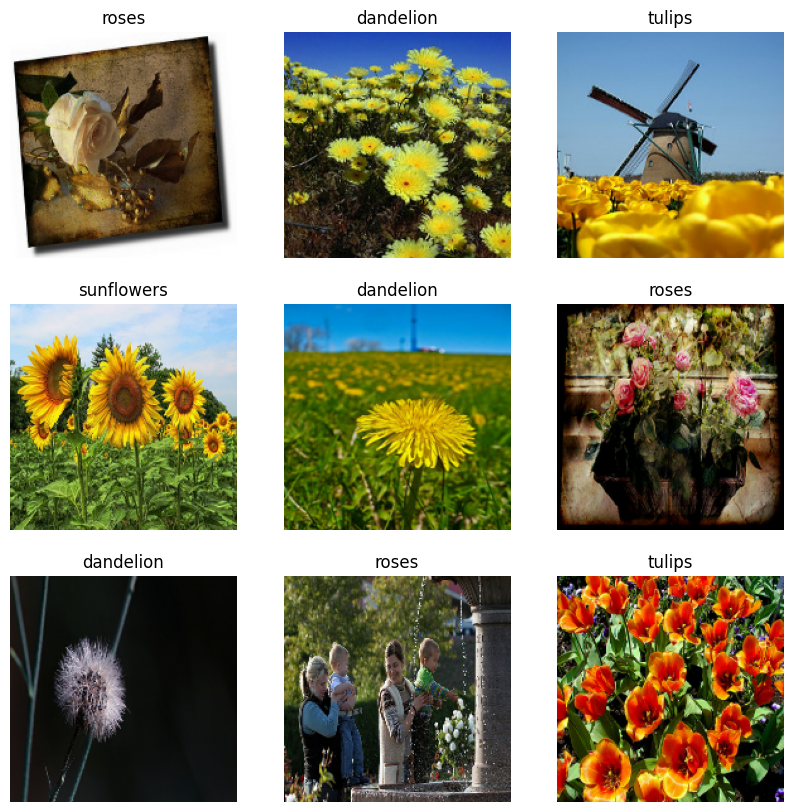
Puoi addestrare un modello utilizzando questi set di dati passandoli a model.fit (mostrato più avanti in questo tutorial). Se lo desideri, puoi anche scorrere manualmente il set di dati e recuperare batch di immagini:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch è un tensore della forma (32, 180, 180, 3) . Si tratta di un batch di 32 immagini di forma 180x180x3 (l'ultima dimensione si riferisce ai canali colore RGB). Il label_batch è un tensore della forma (32,) , queste sono etichette corrispondenti alle 32 immagini.
Puoi chiamare .numpy() su uno di questi tensori per convertirli in numpy.ndarray .
Standardizzare i dati
I valori del canale RGB sono compresi nell'intervallo [0, 255] . Questo non è l'ideale per una rete neurale; in generale dovresti cercare di ridurre i tuoi valori di input.
Qui, standardizzerai i valori in modo che rientrino nell'intervallo [0, 1] usando tf.keras.layers.Rescaling :
normalization_layer = tf.keras.layers.Rescaling(1./255)
Esistono due modi per utilizzare questo livello. Puoi applicarlo al set di dati chiamando Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
In alternativa, puoi includere il livello all'interno della definizione del modello per semplificare la distribuzione. Utilizzerai il secondo approccio qui.
Configura il set di dati per le prestazioni
Assicuriamoci di utilizzare il prelettura bufferizzata in modo da poter produrre dati dal disco senza che l'I/O si blocchi. Questi sono due metodi importanti da utilizzare durante il caricamento dei dati:
-
Dataset.cachemantiene le immagini in memoria dopo che sono state caricate dal disco durante la prima epoca. Ciò garantirà che il set di dati non diventi un collo di bottiglia durante l'addestramento del modello. Se il tuo set di dati è troppo grande per essere contenuto nella memoria, puoi anche utilizzare questo metodo per creare una cache su disco performante. -
Dataset.prefetchsi sovrappone alla preelaborazione dei dati e all'esecuzione del modello durante l'addestramento.
I lettori interessati possono saperne di più su entrambi i metodi e su come memorizzare nella cache i dati su disco nella sezione Prefetching della Guida all'API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Addestra un modello
Per completezza, mostrerai come addestrare un modello semplice utilizzando i set di dati che hai appena preparato.
Il modello sequenziale è costituito da tre blocchi di convoluzione ( tf.keras.layers.Conv2D ) con uno strato di pooling massimo ( tf.keras.layers.MaxPooling2D ) in ciascuno di essi. C'è uno strato completamente connesso ( tf.keras.layers.Dense ) con 128 unità sopra che viene attivato da una funzione di attivazione ReLU ( 'relu' ). Questo modello non è stato ottimizzato in alcun modo: l'obiettivo è mostrarti i meccanismi utilizzando i set di dati che hai appena creato. Per ulteriori informazioni sulla classificazione delle immagini, visita il tutorial sulla classificazione delle immagini .
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
Scegli l'ottimizzatore tf.keras.optimizers.Adam e la funzione di perdita tf.keras.losses.SparseCategoricalCrossentropy . Per visualizzare l'accuratezza dell'addestramento e della convalida per ogni epoca di addestramento, passa l'argomento delle metrics a Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
Potresti notare che l'accuratezza della convalida è bassa rispetto all'accuratezza dell'allenamento, indicando che il tuo modello è overfitting. Puoi saperne di più sull'overfitting e su come ridurlo in questo tutorial .
Utilizzo di tf.data per un controllo più preciso
L'utilità di preelaborazione Keras sopra, tf.keras.utils.image_dataset_from_directory , è un modo conveniente per creare un tf.data.Dataset da una directory di immagini.
Per un controllo della grana più fine, puoi scrivere la tua pipeline di input usando tf.data . Questa sezione mostra come fare proprio questo, iniziando con i percorsi dei file dal file TGZ che hai scaricato in precedenza.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
La struttura ad albero dei file può essere utilizzata per compilare un elenco di class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
Suddividi il set di dati in set di addestramento e convalida:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
È possibile stampare la lunghezza di ciascun set di dati come segue:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
Scrivi una breve funzione che converta un percorso di file in una coppia (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
Usa Dataset.map per creare un set di dati di coppie di image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
Configura il set di dati per le prestazioni
Per addestrare un modello con questo set di dati, vorrai i dati:
- Per essere ben mescolato.
- Da dosare.
- I lotti saranno disponibili il prima possibile.
Queste funzionalità possono essere aggiunte utilizzando l'API tf.data . Per maggiori dettagli, visita la guida alle prestazioni della pipeline di input .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
Visualizza i dati
Puoi visualizzare questo set di dati in modo simile a quello che hai creato in precedenza:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
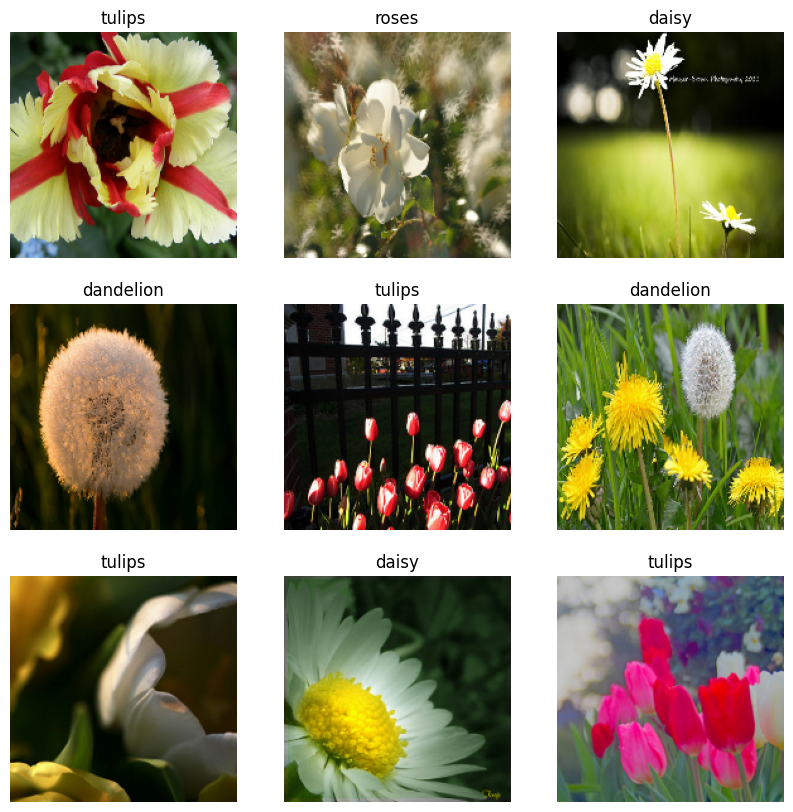
Continua ad addestrare il modello
Ora hai creato manualmente un tf.data.Dataset simile a quello creato da tf.keras.utils.image_dataset_from_directory sopra. Puoi continuare ad addestrare il modello con esso. Come prima, ti allenerai solo per poche epoche per mantenere il tempo di corsa breve.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
Utilizzo dei set di dati TensorFlow
Finora, questo tutorial si è concentrato sul caricamento dei dati su disco. Puoi anche trovare un set di dati da utilizzare esplorando l'ampio catalogo di set di dati facili da scaricare su TensorFlow Datasets .
Poiché in precedenza hai caricato il set di dati Flowers su disco, ora importiamolo con TensorFlow Datasets.
Scarica il set di dati Flowers utilizzando i set di dati TensorFlow:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Il set di dati dei fiori ha cinque classi:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Recupera un'immagine dal set di dati:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Come prima, ricorda di raggruppare, mescolare e configurare i set di addestramento, convalida e test per le prestazioni:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
È possibile trovare un esempio completo di utilizzo del set di dati Flowers e dei set di dati TensorFlow visitando il tutorial sull'aumento dei dati .
Prossimi passi
Questo tutorial ha mostrato due modi per caricare le immagini fuori disco. Innanzitutto, hai imparato come caricare e preelaborare un set di dati di immagini utilizzando i livelli e le utilità di preelaborazione di Keras. Successivamente, hai imparato come scrivere una pipeline di input da zero usando tf.data . Infine, hai imparato come scaricare un set di dati da TensorFlow Datasets.
Per i tuoi prossimi passi:
- Puoi imparare come aggiungere l'aumento dei dati .
- Per ulteriori informazioni su
tf.data, puoi visitare la guida tf.data: Build TensorFlow input pipelines .