
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве основное внимание уделяется задаче сегментации изображения с использованием модифицированного U-Net .
Что такое сегментация изображения?
В задаче классификации изображений сеть присваивает метку (или класс) каждому входному изображению. Однако предположим, что вы хотите знать форму этого объекта, какой пиксель к какому объекту принадлежит и т. д. В этом случае вы захотите присвоить класс каждому пикселю изображения. Эта задача известна как сегментация. Модель сегментации возвращает гораздо более подробную информацию об изображении. Сегментация изображений имеет множество применений в медицинской визуализации, беспилотных автомобилях и спутниковой визуализации, и это лишь некоторые из них.
В этом руководстве используется набор данных домашних животных Oxford-IIIT ( Parkhi et al, 2012 ). Набор данных состоит из изображений 37 пород домашних животных, по 200 изображений каждой породы (примерно по 100 изображений в тренировочном и тестовом сплитах). Каждое изображение включает соответствующие метки и попиксельные маски. Маски являются метками классов для каждого пикселя. Каждому пикселю присваивается одна из трех категорий:
- Класс 1: пиксель, принадлежащий питомцу.
- Класс 2: пиксель, граничащий с питомцем.
- Класс 3: ничего из вышеперечисленного/окружающий пиксель.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
Загрузите набор данных Oxford-IIIT Pets
Набор данных доступен из TensorFlow Datasets . Маски сегментации включены в версию 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
Кроме того, значения цвета изображения нормализованы к диапазону [0,1] . Наконец, как упоминалось выше, пиксели в маске сегментации помечены {1, 2, 3}. Для удобства вычтите 1 из маски сегментации, чтобы получить следующие метки: {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
Набор данных уже содержит необходимые обучающие и тестовые сплиты, поэтому продолжайте использовать те же сплиты.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
Следующий класс выполняет простое увеличение, случайным образом переворачивая изображение. Перейдите к руководству по увеличению изображения, чтобы узнать больше.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
Создайте входной конвейер, применяя расширение после пакетирования входных данных.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
Визуализируйте пример изображения и соответствующую ему маску из набора данных.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Определить модель
Используемая здесь модель представляет собой модифицированную U-Net . U-Net состоит из кодера (понижающего дискретизатора) и декодера (апсемплера). Чтобы изучить надежные функции и уменьшить количество обучаемых параметров, вы будете использовать предварительно обученную модель — MobileNetV2 — в качестве кодировщика. Для декодера вы будете использовать блок upsample, который уже реализован в примере pix2pix в репозитории примеров TensorFlow. (Ознакомьтесь с pix2pix: преобразование изображения в изображение с условным учебным пособием по GAN в записной книжке.)
Как уже упоминалось, кодировщик будет представлять собой предварительно обученную модель MobileNetV2, подготовленную и готовую к использованию в tf.keras.applications . Кодер состоит из конкретных выходных данных промежуточных слоев модели. Обратите внимание, что кодер не будет обучаться в процессе обучения.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Декодер/апсемплер — это просто серия блоков повышающей дискретизации, реализованных в примерах TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Обратите внимание, что количество фильтров на последнем слое равно количеству output_channels . Это будет один выходной канал на класс.
Обучите модель
Теперь осталось только скомпилировать и обучить модель.
Поскольку это проблема мультиклассовой классификации, используйте функцию потерь tf.keras.losses.CategoricalCrossentropy с аргументом from_logits , установленным в True , поскольку метки представляют собой скалярные целые числа, а не векторы оценок для каждого пикселя каждого класса.
При выполнении вывода метка, назначенная пикселю, является каналом с наибольшим значением. Это то, что делает функция create_mask .
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Взгляните на результирующую архитектуру модели:
tf.keras.utils.plot_model(model, show_shapes=True)

Попробуйте модель, чтобы проверить, что она предсказывает перед обучением.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

Обратный вызов, определенный ниже, используется для наблюдения за тем, как модель улучшается во время ее обучения.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

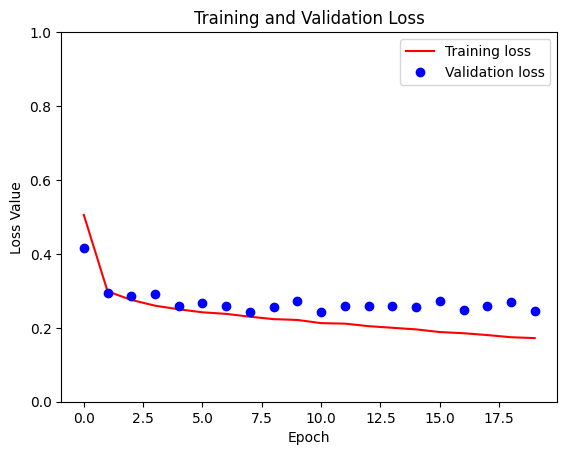
Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
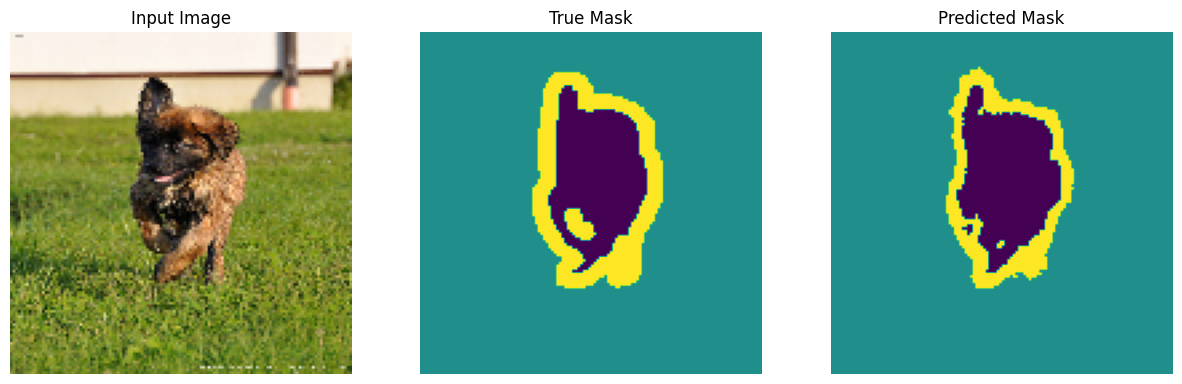
Делать предсказания
А теперь сделайте несколько прогнозов. В интересах экономии времени количество эпох было небольшим, но вы можете установить его выше для получения более точных результатов.
show_predictions(test_batches, 3)


Необязательно: несбалансированные классы и веса классов
Наборы данных семантической сегментации могут быть сильно несбалансированными, что означает, что пиксели определенного класса могут присутствовать внутри изображений больше, чем пиксели других классов. Поскольку проблемы сегментации можно рассматривать как проблемы классификации по пикселям, вы можете решить проблему дисбаланса, взвесив функцию потерь, чтобы учесть это. Это простой и элегантный способ справиться с этой проблемой. Дополнительные сведения см. в руководстве по классификации несбалансированных данных .
Чтобы избежать двусмысленности , Model.fit не поддерживает аргумент class_weight для входных данных с 3+ измерениями.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
Итак, в этом случае вам нужно реализовать взвешивание самостоятельно. Вы сделаете это, используя выборочные веса: в дополнение к парам (data, label) Model.fit также принимает тройки (data, label, sample_weight) .
Model.fit распространяет sample_weight на потери и метрики, которые также принимают аргумент sample_weight . Вес образца умножается на значение образца до шага уменьшения. Например:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
Таким образом, чтобы сделать образцы весов для этого руководства, вам нужна функция, которая принимает пару (data, label) и возвращает тройку (data, label, sample_weight) . Где sample_weight — это одноканальное изображение, содержащее вес класса для каждого пикселя.
Простейшая возможная реализация — использовать метку в качестве индекса в списке class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
Результирующие элементы набора данных содержат по 3 изображения каждый:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
Теперь вы можете обучить модель на этом взвешенном наборе данных:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Следующие шаги
Теперь, когда вы понимаете, что такое сегментация изображений и как она работает, вы можете попробовать это руководство с различными выходными данными промежуточного слоя или даже с разными предварительно обученными моделями. Вы также можете испытать себя, приняв участие в конкурсе Carvana по маскированию изображений, размещенном на Kaggle.
Вы также можете увидеть API обнаружения объектов Tensorflow для другой модели, которую вы можете переобучить на своих собственных данных. Предварительно обученные модели доступны на TensorFlow Hub .