
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Panduan ini melatih model jaringan saraf untuk mengklasifikasikan gambar pakaian, seperti sepatu kets dan kemeja. Tidak apa-apa jika Anda tidak memahami semua detailnya; ini adalah ikhtisar cepat dari program TensorFlow lengkap dengan detail yang dijelaskan saat Anda melanjutkan.
Panduan ini menggunakan tf.keras , API tingkat tinggi untuk membuat dan melatih model di TensorFlow.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0-rc1
Impor kumpulan data Fashion MNIST
Panduan ini menggunakan dataset Fashion MNIST yang berisi 70.000 gambar skala abu-abu dalam 10 kategori. Gambar-gambar tersebut menunjukkan pakaian satu per satu dengan resolusi rendah (28 x 28 piksel), seperti yang terlihat di sini:
| Gambar 1. Sampel Fashion-MNIST (oleh Zalando, Lisensi MIT). |
Fashion MNIST dimaksudkan sebagai pengganti drop-in untuk dataset MNIST klasik—sering digunakan sebagai program pembelajaran mesin "Halo, Dunia" untuk visi komputer. Dataset MNIST berisi gambar angka tulisan tangan (0, 1, 2, dll.) dalam format yang identik dengan artikel pakaian yang akan Anda gunakan di sini.
Panduan ini menggunakan Fashion MNIST untuk variasi, dan karena ini merupakan masalah yang sedikit lebih menantang daripada MNIST biasa. Kedua kumpulan data tersebut relatif kecil dan digunakan untuk memverifikasi bahwa suatu algoritme berfungsi seperti yang diharapkan. Mereka adalah titik awal yang baik untuk menguji dan men-debug kode.
Di sini, 60.000 gambar digunakan untuk melatih jaringan dan 10.000 gambar untuk mengevaluasi seberapa akurat jaringan belajar mengklasifikasikan gambar. Anda dapat mengakses Fashion MNIST langsung dari TensorFlow. Impor dan muat data Fashion MNIST langsung dari TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Memuat dataset mengembalikan empat array NumPy:
-
train_imagesdantrain_labelsadalah set pelatihan —data yang digunakan model untuk belajar. - Model diuji terhadap set tes ,
test_images, dan arraytest_labels.
Gambar adalah array NumPy 28x28, dengan nilai piksel berkisar dari 0 hingga 255. Label adalah array bilangan bulat, mulai dari 0 hingga 9. Ini sesuai dengan kelas pakaian yang diwakili oleh gambar:
| Label | Kelas |
|---|---|
| 0 | T-shirt/atas |
| 1 | Celana panjang |
| 2 | Menarik |
| 3 | Gaun |
| 4 | Mantel |
| 5 | sandal |
| 6 | Kemeja |
| 7 | sepatu kets |
| 8 | Tas |
| 9 | Pergelangan sepatu |
Setiap gambar dipetakan ke satu label. Karena nama kelas tidak disertakan dengan dataset, simpan di sini untuk digunakan nanti saat memplot gambar:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Jelajahi datanya
Mari kita jelajahi format kumpulan data sebelum melatih model. Berikut ini menunjukkan ada 60.000 gambar dalam set pelatihan, dengan masing-masing gambar direpresentasikan sebagai 28 x 28 piksel:
train_images.shape
(60000, 28, 28)
Demikian juga, ada 60.000 label di set pelatihan:
len(train_labels)
60000
Setiap label adalah bilangan bulat antara 0 dan 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
Ada 10.000 gambar dalam set pengujian. Sekali lagi, setiap gambar direpresentasikan sebagai 28 x 28 piksel:
test_images.shape
(10000, 28, 28)
Dan set pengujian berisi 10.000 label gambar:
len(test_labels)
10000
Pra-proses data
Data harus diproses terlebih dahulu sebelum melatih jaringan. Jika Anda memeriksa gambar pertama di set pelatihan, Anda akan melihat bahwa nilai piksel berada dalam kisaran 0 hingga 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
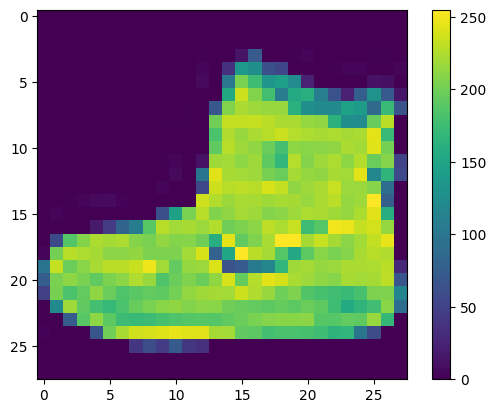
Skalakan nilai-nilai ini ke kisaran 0 hingga 1 sebelum memasukkannya ke model jaringan saraf. Untuk melakukannya, bagi nilai dengan 255. Penting agar set pelatihan dan set pengujian diproses sebelumnya dengan cara yang sama:
train_images = train_images / 255.0
test_images = test_images / 255.0
Untuk memverifikasi bahwa data dalam format yang benar dan bahwa Anda siap untuk membangun dan melatih jaringan, mari tampilkan 25 gambar pertama dari set pelatihan dan tampilkan nama kelas di bawah setiap gambar.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Bangun modelnya
Membangun jaringan saraf memerlukan konfigurasi lapisan model, kemudian kompilasi model.
Siapkan lapisan
Blok bangunan dasar dari jaringan saraf adalah lapisan . Lapisan mengekstrak representasi dari data yang dimasukkan ke dalamnya. Mudah-mudahan, representasi ini bermakna untuk masalah yang dihadapi.
Sebagian besar pembelajaran mendalam terdiri dari rantai bersama lapisan sederhana. Sebagian besar lapisan, seperti tf.keras.layers.Dense , memiliki parameter yang dipelajari selama pelatihan.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
Lapisan pertama dalam jaringan ini, tf.keras.layers.Flatten , mengubah format gambar dari larik dua dimensi (28 x 28 piksel) menjadi larik satu dimensi (28 * 28 = 784 piksel). Pikirkan lapisan ini sebagai deretan piksel yang tidak bertumpuk dalam gambar dan melapisinya. Lapisan ini tidak memiliki parameter untuk dipelajari; itu hanya memformat ulang data.
Setelah piksel diratakan, jaringan terdiri dari urutan dua lapisan tf.keras.layers.Dense . Ini terhubung secara padat, atau sepenuhnya terhubung, lapisan saraf. Lapisan Dense pertama memiliki 128 node (atau neuron). Lapisan kedua (dan terakhir) mengembalikan array logits dengan panjang 10. Setiap node berisi skor yang menunjukkan gambar saat ini milik salah satu dari 10 kelas.
Kompilasi modelnya
Sebelum model siap untuk pelatihan, perlu beberapa pengaturan lagi. Ini ditambahkan selama langkah kompilasi model:
- Loss function —Ini mengukur seberapa akurat model selama pelatihan. Anda ingin meminimalkan fungsi ini untuk "mengarahkan" model ke arah yang benar.
- Pengoptimal —Inilah cara model diperbarui berdasarkan data yang dilihatnya dan fungsi kerugiannya.
- Metrik —Digunakan untuk memantau langkah-langkah pelatihan dan pengujian. Contoh berikut menggunakan akurasi , pecahan dari gambar yang diklasifikasikan dengan benar.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Latih modelnya
Pelatihan model jaringan saraf memerlukan langkah-langkah berikut:
- Masukkan data pelatihan ke model. Dalam contoh ini, data pelatihan ada dalam
train_imagesdantrain_labels. - Model belajar mengasosiasikan gambar dan label.
- Anda meminta model untuk membuat prediksi tentang set pengujian—dalam contoh ini, larik
test_images. - Verifikasi bahwa prediksi cocok dengan label dari larik
test_labels.
Beri makan model
Untuk memulai pelatihan, panggil metode model.fit —disebut demikian karena "menyesuaikan" model dengan data pelatihan:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5014 - accuracy: 0.8232 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3770 - accuracy: 0.8636 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3376 - accuracy: 0.8770 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3148 - accuracy: 0.8841 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2973 - accuracy: 0.8899 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2807 - accuracy: 0.8955 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2707 - accuracy: 0.9002 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2592 - accuracy: 0.9042 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2506 - accuracy: 0.9070 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2419 - accuracy: 0.9090 <keras.callbacks.History at 0x7f730da81c50>
Saat model berlatih, metrik kehilangan dan akurasi ditampilkan. Model ini mencapai akurasi sekitar 0,91 (atau 91%) pada data pelatihan.
Evaluasi akurasi
Selanjutnya, bandingkan performa model pada kumpulan data pengujian:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3347 - accuracy: 0.8837 - 593ms/epoch - 2ms/step Test accuracy: 0.8837000131607056
Ternyata akurasi pada dataset uji sedikit kurang dari akurasi pada dataset pelatihan. Kesenjangan antara akurasi pelatihan dan akurasi tes ini menunjukkan overfitting . Overfitting terjadi ketika model pembelajaran mesin berperforma lebih buruk pada input baru yang sebelumnya tidak terlihat daripada pada data pelatihan. Model overfitted "mengingat" kebisingan dan detail dalam set data pelatihan ke titik di mana hal itu berdampak negatif pada kinerja model pada data baru. Untuk informasi lebih lanjut, lihat berikut ini:
Membuat prediksi
Dengan model yang terlatih, Anda dapat menggunakannya untuk membuat prediksi tentang beberapa gambar. Keluaran linier model, logits . Lampirkan lapisan softmax untuk mengonversi log menjadi probabilitas, yang lebih mudah diinterpretasikan.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
Di sini, model telah memprediksi label untuk setiap gambar dalam set pengujian. Mari kita lihat prediksi pertama:
predictions[0]
array([6.5094389e-07, 1.5681711e-10, 9.0262159e-10, 8.3779689e-10,
9.4969926e-07, 6.7454423e-03, 3.7524345e-08, 1.6792126e-02,
9.9967767e-09, 9.7646081e-01], dtype=float32)
Prediksi adalah larik 10 angka. Mereka mewakili "keyakinan" model bahwa gambar tersebut sesuai dengan masing-masing dari 10 item pakaian yang berbeda. Anda dapat melihat label mana yang memiliki nilai kepercayaan tertinggi:
np.argmax(predictions[0])
9
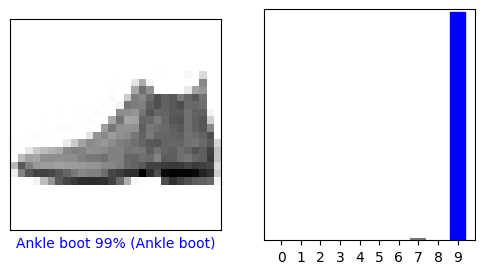
Jadi, model paling yakin bahwa gambar ini adalah ankle boot, atau class_names[9] . Memeriksa label uji menunjukkan bahwa klasifikasi ini benar:
test_labels[0]
9
Grafik ini untuk melihat set lengkap 10 prediksi kelas.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Verifikasi prediksi
Dengan model yang terlatih, Anda dapat menggunakannya untuk membuat prediksi tentang beberapa gambar.
Mari kita lihat gambar ke-0, prediksi, dan larik prediksi. Label prediksi yang benar berwarna biru dan label prediksi yang salah berwarna merah. Angka tersebut memberikan persentase (dari 100) untuk label yang diprediksi.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
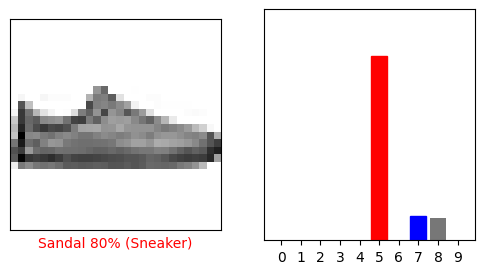
Mari kita plot beberapa gambar dengan prediksi mereka. Perhatikan bahwa modelnya bisa salah bahkan ketika sangat percaya diri.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

Gunakan model yang terlatih
Terakhir, gunakan model terlatih untuk membuat prediksi tentang satu gambar.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
model tf.keras dioptimalkan untuk membuat prediksi pada kumpulan , atau kumpulan, contoh sekaligus. Oleh karena itu, meskipun Anda menggunakan satu gambar, Anda perlu menambahkannya ke daftar:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
Sekarang prediksi label yang benar untuk gambar ini:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[5.2901622e-05 1.1112720e-14 9.9954790e-01 3.9485815e-10 2.0636957e-04 7.8756333e-12 1.9278938e-04 2.9756516e-16 2.2718803e-08 4.3763088e-15]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
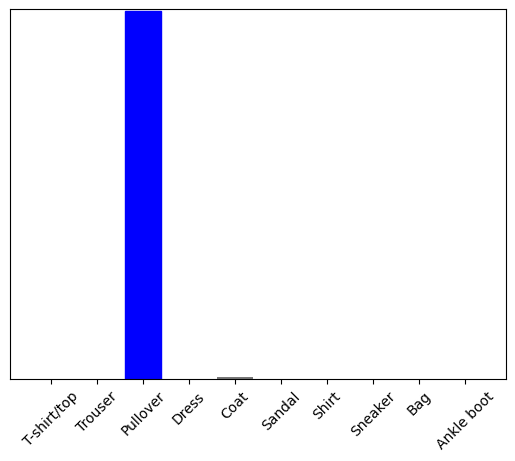
tf.keras.Model.predict mengembalikan daftar daftar—satu daftar untuk setiap gambar dalam kumpulan data. Dapatkan prediksi untuk (hanya) gambar kami dalam kumpulan:
np.argmax(predictions_single[0])
2
Dan model memprediksi label seperti yang diharapkan.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.