
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Trong một bài toán hồi quy , mục đích là để dự đoán đầu ra của một giá trị liên tục, như giá cả hoặc xác suất. Đối chiếu điều này với một bài toán phân loại , trong đó mục đích là chọn một lớp từ danh sách các lớp (ví dụ, trong đó một bức tranh có một quả táo hoặc một quả cam, nhận biết loại quả nào trong ảnh).
Hướng dẫn này sử dụng tập dữ liệu Auto MPG cổ điển và trình bày cách xây dựng mô hình để dự đoán hiệu suất nhiên liệu của ô tô cuối những năm 1970 và đầu những năm 1980. Để làm điều này, bạn sẽ cung cấp cho các mô hình mô tả về nhiều loại ô tô trong khoảng thời gian đó. Mô tả này bao gồm các thuộc tính như xi lanh, dịch chuyển, mã lực và trọng lượng.
Ví dụ này sử dụng API Keras. (Truy cập các hướng dẫn và hướng dẫn của Keras để tìm hiểu thêm.)
# Use seaborn for pairplot.pip install -q seaborn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# Make NumPy printouts easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2.8.0-rc1
Tập dữ liệu MPG tự động
Tập dữ liệu có sẵn từ Kho lưu trữ Học máy UCI .
Lấy dữ liệu
Trước tiên, hãy tải xuống và nhập tập dữ liệu bằng cách sử dụng gấu trúc:
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
Làm sạch dữ liệu
Tập dữ liệu chứa một vài giá trị không xác định:
dataset.isna().sum()
MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
Bỏ các hàng đó để giữ cho hướng dẫn ban đầu này đơn giản:
dataset = dataset.dropna()
Cột "Origin" là cột phân loại, không phải số. Vì vậy, bước tiếp theo là mã hóa một lần các giá trị trong cột bằng pd.get_dummies .
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
dataset.tail()
Chia dữ liệu thành các tập huấn luyện và kiểm tra
Bây giờ, hãy tách tập dữ liệu thành tập huấn luyện và tập thử nghiệm. Bạn sẽ sử dụng bộ thử nghiệm để đánh giá cuối cùng các mô hình của mình.
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
Kiểm tra dữ liệu
Xem lại cách phân phối chung của một vài cặp cột từ tập huấn luyện.
Hàng trên cùng gợi ý rằng hiệu suất nhiên liệu (MPG) là một hàm của tất cả các thông số khác. Các hàng khác cho biết chúng là chức năng của nhau.
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x7f6bfdae9850>
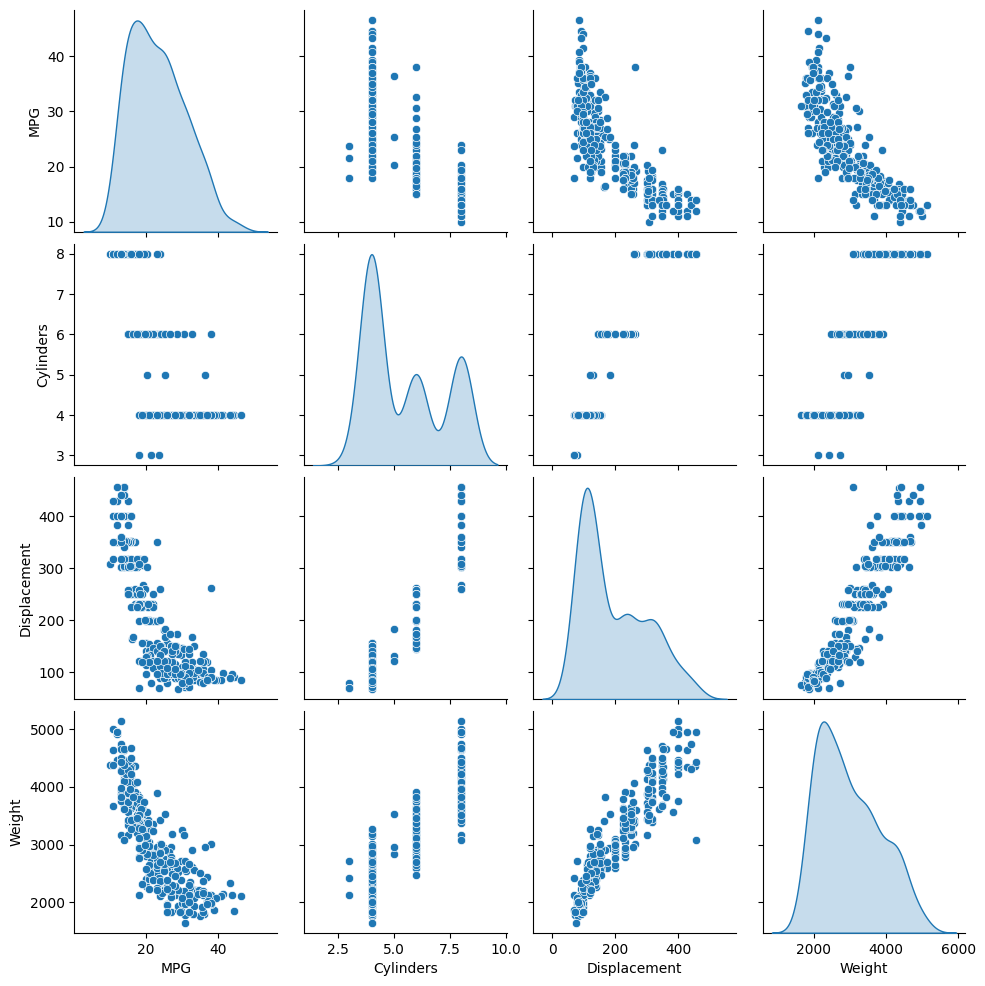
Hãy cũng kiểm tra các số liệu thống kê tổng thể. Lưu ý cách mỗi tính năng bao gồm một phạm vi rất khác nhau:
train_dataset.describe().transpose()
Tách các tính năng khỏi nhãn
Tách giá trị mục tiêu — "nhãn" —từ các tính năng. Nhãn này là giá trị mà bạn sẽ đào tạo mô hình để dự đoán.
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
Bình thường hóa
Trong bảng thống kê, dễ dàng thấy được mức độ khác nhau của từng đối tượng địa lý:
train_dataset.describe().transpose()[['mean', 'std']]
Thông lệ tốt là chuẩn hóa các đối tượng địa lý sử dụng các quy mô và phạm vi khác nhau.
Một lý do khiến điều này quan trọng là vì các tính năng được nhân với trọng lượng của mô hình. Vì vậy, quy mô của các đầu ra và quy mô của các bậc thang bị ảnh hưởng bởi quy mô của các đầu vào.
Mặc dù một mô hình có thể hội tụ mà không có tính năng chuẩn hóa, nhưng việc chuẩn hóa sẽ giúp quá trình đào tạo ổn định hơn nhiều.
Lớp chuẩn hóa
tf.keras.layers.Normalization là một cách đơn giản và dễ hiểu để thêm tính năng chuẩn hóa vào mô hình của bạn.
Bước đầu tiên là tạo lớp:
normalizer = tf.keras.layers.Normalization(axis=-1)
Sau đó, điều chỉnh trạng thái của lớp tiền xử lý với dữ liệu bằng cách gọi Normalization.adapt :
normalizer.adapt(np.array(train_features))
Tính giá trị trung bình và phương sai và lưu trữ chúng trong lớp:
print(normalizer.mean.numpy())
[[ 5.478 195.318 104.869 2990.252 15.559 75.898 0.178 0.197
0.624]]
Khi lớp được gọi, nó trả về dữ liệu đầu vào, với mỗi tính năng được chuẩn hóa độc lập:
first = np.array(train_features[:1])
with np.printoptions(precision=2, suppress=True):
print('First example:', first)
print()
print('Normalized:', normalizer(first).numpy())
First example: [[ 4. 90. 75. 2125. 14.5 74. 0. 0. 1. ]] Normalized: [[-0.87 -1.01 -0.79 -1.03 -0.38 -0.52 -0.47 -0.5 0.78]]
Hồi quy tuyến tính
Trước khi xây dựng mô hình mạng nơron sâu, hãy bắt đầu với hồi quy tuyến tính sử dụng một và một số biến.
Hồi quy tuyến tính với một biến
Bắt đầu với hồi quy tuyến tính một biến để dự đoán 'MPG' từ 'Horsepower' .
Đào tạo một mô hình với tf.keras thường bắt đầu bằng cách xác định kiến trúc mô hình. Sử dụng mô hình tf.keras.Sequential , đại diện cho một chuỗi các bước .
Có hai bước trong mô hình hồi quy tuyến tính một biến của bạn:
- Chuẩn hóa các tính năng đầu vào
'Horsepower'bằng cách sử dụng lớp tiền xử lýtf.keras.layers.Normalization. - Áp dụng phép biến đổi tuyến tính (\(y = mx+b\)) để tạo ra 1 đầu ra bằng cách sử dụng lớp tuyến tính (
tf.keras.layers.Dense).
Số lượng đầu vào có thể được đặt bằng đối số input_shape hoặc tự động khi mô hình được chạy lần đầu tiên.
Đầu tiên, tạo một mảng NumPy làm bằng các tính năng 'Horsepower' . Sau đó, khởi tạo tf.keras.layers.Normalization và điều chỉnh trạng thái của nó với dữ liệu horsepower :
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = layers.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
Xây dựng mô hình tuần tự Keras:
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense (Dense) (None, 1) 2
=================================================================
Total params: 5
Trainable params: 2
Non-trainable params: 3
_________________________________________________________________
Mô hình này sẽ dự đoán 'MPG' từ 'Horsepower' .
Chạy mô hình chưa được đào tạo trên 10 giá trị 'Mã lực' đầu tiên. Kết quả đầu ra sẽ không tốt, nhưng lưu ý rằng nó có hình dạng mong đợi là (10, 1) :
horsepower_model.predict(horsepower[:10])
array([[-1.186],
[-0.67 ],
[ 2.189],
[-1.662],
[-1.504],
[-0.59 ],
[-1.782],
[-1.504],
[-0.392],
[-0.67 ]], dtype=float32)
Sau khi xây dựng mô hình, hãy cấu hình quy trình đào tạo bằng phương thức Model.compile . Các đối số quan trọng nhất để biên dịch là loss và trình optimizer , vì chúng xác định những gì sẽ được tối ưu hóa ( mean_absolute_error ) và cách thức (sử dụng tf.keras.optimizers.Adam ).
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
Sử dụng Keras Model.fit để thực hiện đào tạo trong 100 kỷ nguyên:
%%time
history = horsepower_model.fit(
train_features['Horsepower'],
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.79 s, sys: 797 ms, total: 5.59 s Wall time: 3.8 s
Hình dung tiến trình đào tạo của mô hình bằng cách sử dụng số liệu thống kê được lưu trữ trong đối tượng history :
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plot_loss(history)
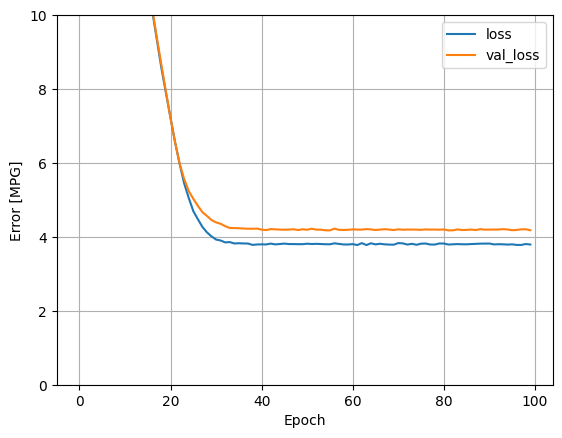
Thu thập kết quả trên bộ thử nghiệm để sử dụng sau:
test_results = {}
test_results['horsepower_model'] = horsepower_model.evaluate(
test_features['Horsepower'],
test_labels, verbose=0)
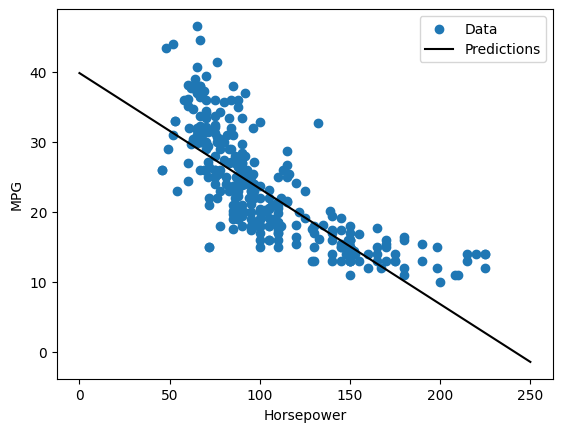
Vì đây là một hồi quy một biến, nên dễ dàng xem các dự đoán của mô hình như một hàm của đầu vào:
x = tf.linspace(0.0, 250, 251)
y = horsepower_model.predict(x)
def plot_horsepower(x, y):
plt.scatter(train_features['Horsepower'], train_labels, label='Data')
plt.plot(x, y, color='k', label='Predictions')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.legend()
plot_horsepower(x, y)
Hồi quy tuyến tính với nhiều đầu vào
Bạn có thể sử dụng một thiết lập gần như giống hệt nhau để đưa ra dự đoán dựa trên nhiều đầu vào. Mô hình này vẫn thực hiện cùng một \(y = mx+b\) ngoại trừ \(m\) là một ma trận và \(b\) là một vectơ.
Tạo lại mô hình tuần tự Keras hai bước với lớp đầu tiên là bộ normalizer ( tf.keras.layers.Normalization(axis=-1) ) mà bạn đã xác định trước đó và điều chỉnh cho phù hợp với toàn bộ tập dữ liệu:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
Khi bạn gọi Model.predict trên một loạt đầu vào, nó tạo ra units=1 đầu ra cho mỗi ví dụ:
linear_model.predict(train_features[:10])
array([[ 0.441],
[ 1.522],
[ 0.188],
[ 1.169],
[ 0.058],
[ 0.965],
[ 0.034],
[-0.674],
[ 0.437],
[-0.37 ]], dtype=float32)
Khi bạn gọi mô hình, các ma trận trọng số của nó sẽ được xây dựng — hãy kiểm tra xem các trọng số của kernel ( \(m\) trong \(y=mx+b\)) có hình dạng là (9, 1) :
linear_model.layers[1].kernel
<tf.Variable 'dense_1/kernel:0' shape=(9, 1) dtype=float32, numpy=
array([[-0.702],
[ 0.307],
[ 0.114],
[ 0.233],
[ 0.244],
[ 0.322],
[-0.725],
[-0.151],
[ 0.407]], dtype=float32)>
Định cấu hình mô hình với Keras Model.compile và đào tạo với Model.fit trong 100 kỷ nguyên:
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
%%time
history = linear_model.fit(
train_features,
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.89 s, sys: 740 ms, total: 5.63 s Wall time: 3.75 s
Sử dụng tất cả các đầu vào trong mô hình hồi quy này sẽ đạt được lỗi đào tạo và xác nhận thấp hơn nhiều so với mô hình horsepower_model , có một đầu vào:
plot_loss(history)
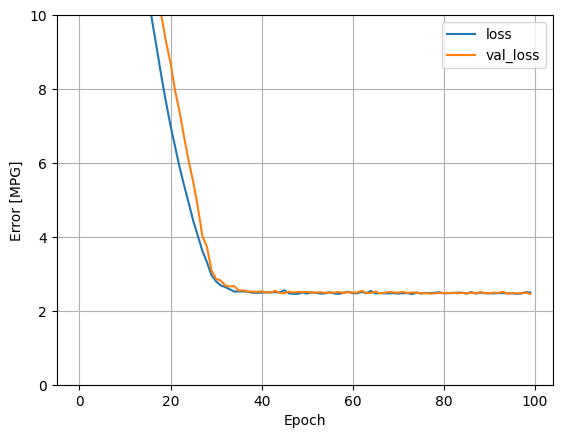
Thu thập kết quả trên bộ thử nghiệm để sử dụng sau:
test_results['linear_model'] = linear_model.evaluate(
test_features, test_labels, verbose=0)
Hồi quy với mạng nơ-ron sâu (DNN)
Trong phần trước, bạn đã triển khai hai mô hình tuyến tính cho đầu vào đơn và nhiều đầu vào.
Tại đây, bạn sẽ triển khai các mô hình DNN một đầu vào và nhiều đầu vào.
Mã về cơ bản giống nhau ngoại trừ mô hình được mở rộng để bao gồm một số lớp phi tuyến tính "ẩn". Tên "hidden" ở đây chỉ có nghĩa là không được kết nối trực tiếp với các đầu vào hoặc đầu ra.
Các mô hình này sẽ chứa nhiều lớp hơn so với mô hình tuyến tính:
- Lớp chuẩn hóa, như trước đây (với
horsepower_normalizercho mô hình một đầu vào và bộnormalizercho mô hình nhiều đầu vào). - Hai lớp ẩn, phi tuyến tính,
Densevới chức năng kích hoạt ReLU (relu) phi tuyến tính. - Một lớp đầu ra đơn
Densetuyến tính.
Cả hai mô hình sẽ sử dụng cùng một quy trình đào tạo nên phương thức compile được bao gồm trong hàm build_and_compile_model bên dưới.
def build_and_compile_model(norm):
model = keras.Sequential([
norm,
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(loss='mean_absolute_error',
optimizer=tf.keras.optimizers.Adam(0.001))
return model
Hồi quy sử dụng DNN và một đầu vào duy nhất
Tạo mô hình DNN chỉ có 'Horsepower' làm đầu vào và horsepower_normalizer (được định nghĩa trước đó) làm lớp chuẩn hóa:
dnn_horsepower_model = build_and_compile_model(horsepower_normalizer)
Mô hình này có nhiều tham số có thể đào tạo hơn so với mô hình tuyến tính:
dnn_horsepower_model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense_2 (Dense) (None, 64) 128
dense_3 (Dense) (None, 64) 4160
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 4,356
Trainable params: 4,353
Non-trainable params: 3
_________________________________________________________________
Đào tạo người mẫu với Keras Model.fit :
%%time
history = dnn_horsepower_model.fit(
train_features['Horsepower'],
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.07 s, sys: 691 ms, total: 5.76 s Wall time: 3.92 s
Mô hình này hoạt động tốt hơn một chút so với mô hình horsepower_model đầu vào đơn tuyến tính:
plot_loss(history)
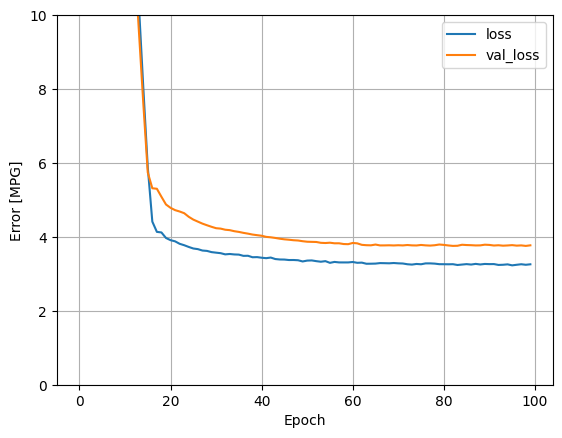
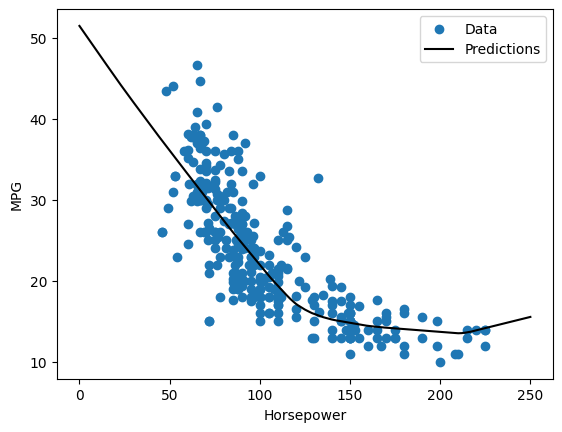
Nếu bạn vẽ các dự đoán dưới dạng một hàm của 'Horsepower' , bạn nên chú ý cách mô hình này tận dụng tính phi tuyến tính được cung cấp bởi các lớp ẩn:
x = tf.linspace(0.0, 250, 251)
y = dnn_horsepower_model.predict(x)
plot_horsepower(x, y)
Thu thập kết quả trên bộ thử nghiệm để sử dụng sau:
test_results['dnn_horsepower_model'] = dnn_horsepower_model.evaluate(
test_features['Horsepower'], test_labels,
verbose=0)
Hồi quy sử dụng một DNN và nhiều đầu vào
Lặp lại quy trình trước đó bằng cách sử dụng tất cả các đầu vào. Hiệu suất của mô hình cải thiện một chút trên tập dữ liệu xác thực.
dnn_model = build_and_compile_model(normalizer)
dnn_model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization (Normalizatio (None, 9) 19
n)
dense_5 (Dense) (None, 64) 640
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 4,884
Trainable params: 4,865
Non-trainable params: 19
_________________________________________________________________
%%time
history = dnn_model.fit(
train_features,
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.08 s, sys: 725 ms, total: 5.8 s Wall time: 3.94 s
plot_loss(history)
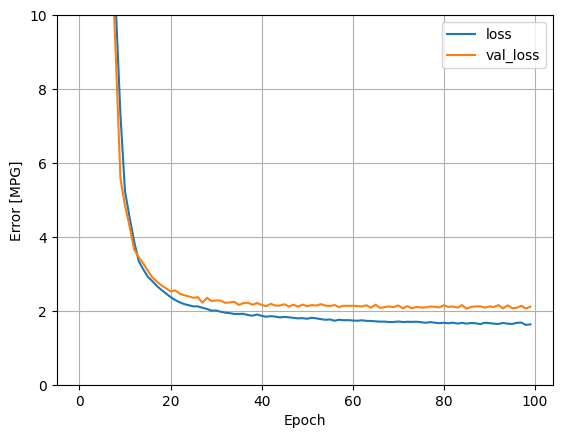
Thu thập kết quả trên bộ thử nghiệm:
test_results['dnn_model'] = dnn_model.evaluate(test_features, test_labels, verbose=0)
Màn biểu diễn
Vì tất cả các mô hình đã được đào tạo, bạn có thể xem lại hiệu suất bộ thử nghiệm của chúng:
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
Các kết quả này phù hợp với lỗi xác nhận được quan sát trong quá trình đào tạo.
Dự đoán
Bây giờ bạn có thể đưa ra dự đoán với dnn_model trên bộ thử nghiệm bằng cách sử dụng Keras Model Model.predict và xem xét sự mất mát:
test_predictions = dnn_model.predict(test_features).flatten()
a = plt.axes(aspect='equal')
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
lims = [0, 50]
plt.xlim(lims)
plt.ylim(lims)
_ = plt.plot(lims, lims)

Có vẻ như mô hình dự đoán khá tốt.
Bây giờ, hãy kiểm tra phân phối lỗi:
error = test_predictions - test_labels
plt.hist(error, bins=25)
plt.xlabel('Prediction Error [MPG]')
_ = plt.ylabel('Count')
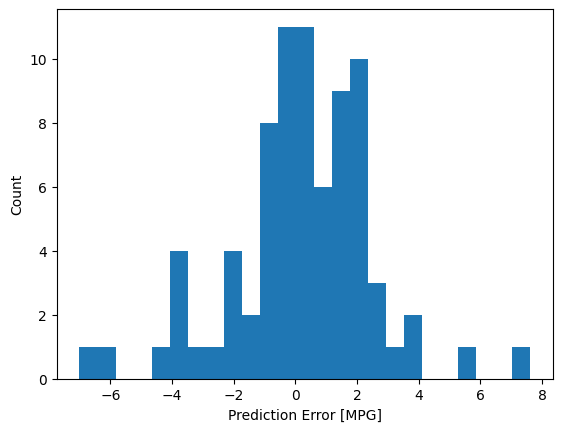
Nếu bạn hài lòng với mô hình, hãy lưu nó để sử dụng sau này với Model.save :
dnn_model.save('dnn_model')
2022-01-26 07:26:13.372245: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: dnn_model/assets
Nếu bạn tải lại mô hình, nó cho kết quả giống hệt nhau:
reloaded = tf.keras.models.load_model('dnn_model')
test_results['reloaded'] = reloaded.evaluate(
test_features, test_labels, verbose=0)
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
Sự kết luận
Sổ tay này giới thiệu một số kỹ thuật để xử lý vấn đề hồi quy. Dưới đây là một số mẹo khác có thể hữu ích:
- Lỗi bình phương trung bình (MSE) (
tf.losses.MeanSquaredError) và sai số tuyệt đối trung bình (MAE) (tf.losses.MeanAbsoluteError) là các hàm mất mát phổ biến được sử dụng cho các bài toán hồi quy. MAE ít nhạy cảm hơn với các yếu tố ngoại lai. Các hàm tổn thất khác nhau được sử dụng cho các bài toán phân loại. - Tương tự, các số liệu đánh giá được sử dụng cho hồi quy khác với phân loại.
- Khi các đối tượng địa lý dữ liệu đầu vào dạng số có các giá trị với các phạm vi khác nhau, thì mỗi đối tượng địa lý phải được chia tỷ lệ độc lập thành cùng một phạm vi.
- Trang bị quá mức là một vấn đề phổ biến đối với các mô hình DNN, mặc dù nó không phải là vấn đề đối với hướng dẫn này. Truy cập hướng dẫn Overfit và underfit để được trợ giúp thêm về vấn đề này.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.