
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מראה כיצד לטעון ולעבד מראש מערך נתונים של תמונה בשלוש דרכים:
- ראשית, תשתמש בכלי עזר לעיבוד מקדים של Keras (כגון
tf.keras.utils.image_dataset_from_directory) ובשכבות (כגוןtf.keras.layers.Rescaling) כדי לקרוא ספריית תמונות בדיסק. - לאחר מכן, תכתוב צינור קלט משלך מאפס באמצעות tf.data .
- לבסוף, תוריד מערך נתונים מהקטלוג הגדול הזמין ב- TensorFlow Datasets .
להכין
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
הורד את מערך הנתונים של הפרחים
מדריך זה משתמש במערך נתונים של כמה אלפי תמונות של פרחים. מערך הנתונים של הפרחים מכיל חמש ספריות משנה, אחת לכל מחלקה:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
לאחר ההורדה (218MB), אמור להיות לך כעת עותק של תמונות הפרחים זמין. יש 3,670 תמונות בסך הכל:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
כל ספרייה מכילה תמונות של סוג פרח זה. הנה כמה ורדים:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

טען נתונים באמצעות כלי שירות Keras
בוא נטען את התמונות האלה מהדיסק באמצעות כלי השירות המועיל tf.keras.utils.image_dataset_from_directory .
צור מערך נתונים
הגדר כמה פרמטרים עבור המטען:
batch_size = 32
img_height = 180
img_width = 180
מומלץ להשתמש בפיצול אימות בעת פיתוח המודל שלך. אתה תשתמש ב-80% מהתמונות לאימון ו-20% לאימות.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
אתה יכול למצוא את שמות המחלקות בתכונה class_names במערך הנתונים האלה.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
דמיינו את הנתונים
להלן תשע התמונות הראשונות מתוך מערך ההדרכה.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
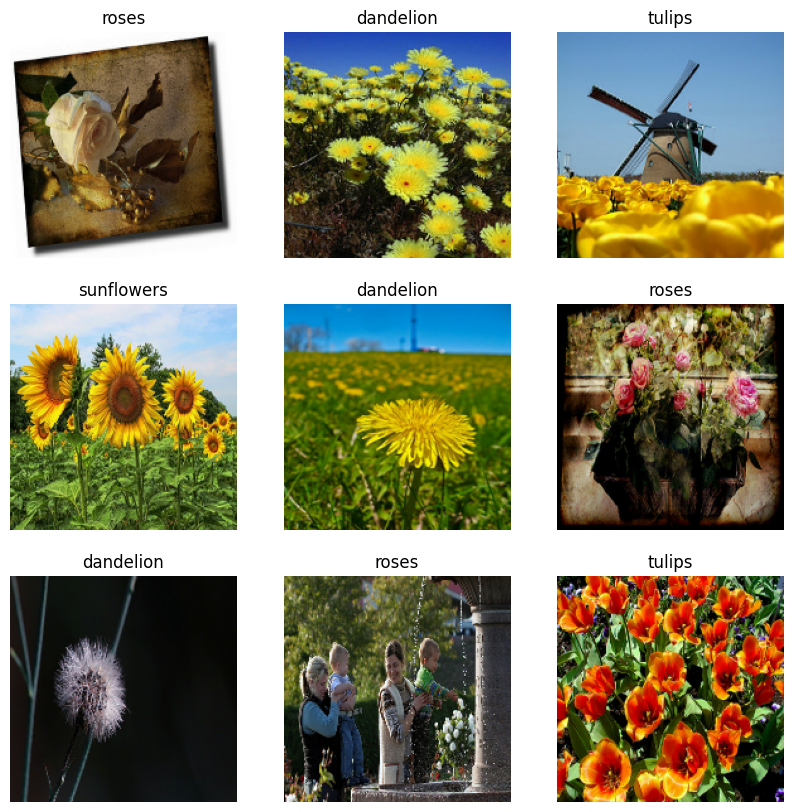
אתה יכול לאמן מודל באמצעות מערכי נתונים אלה על ידי העברתם אל model.fit (מוצג מאוחר יותר במדריך זה). אם תרצה, תוכל גם לחזור על מערך הנתונים באופן ידני ולאחזר קבוצות של תמונות:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
ה- image_batch הוא טנסור של הצורה (32, 180, 180, 3) . זוהי אצווה של 32 תמונות 180x180x3 (הממד האחרון מתייחס לערוצי צבע RGB). ה- label_batch הוא טנסור של הצורה (32,) , אלו תוויות מתאימות ל-32 התמונות.
אתה יכול לקרוא .numpy() בכל אחד מהטנסורים האלה כדי להמיר אותם ל- numpy.ndarray .
תקן את הנתונים
ערכי ערוץ ה-RGB נמצאים בטווח [0, 255] . זה לא אידיאלי עבור רשת עצבית; באופן כללי, עליך לשאוף להקטין את ערכי הקלט שלך.
כאן, תתקן את הערכים כך שיהיו בטווח [0, 1] באמצעות tf.keras.layers.Rescaling :
normalization_layer = tf.keras.layers.Rescaling(1./255)
ישנן שתי דרכים להשתמש בשכבה זו. אתה יכול להחיל אותו על מערך הנתונים על ידי קריאה Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
לחלופין, אתה יכול לכלול את השכבה בתוך הגדרת המודל שלך כדי לפשט את הפריסה. אתה תשתמש בגישה השנייה כאן.
הגדר את מערך הנתונים לביצועים
בוא נוודא להשתמש באחזור מראש מאוחסן כדי שתוכל להפיק נתונים מהדיסק מבלי שהקלט/פלט ייחסם. אלו הן שתי שיטות חשובות שבהן עליך להשתמש בעת טעינת נתונים:
-
Dataset.cacheשומר את התמונות בזיכרון לאחר טעינתן מהדיסק במהלך התקופה הראשונה. זה יבטיח שמערך הנתונים לא יהפוך לצוואר בקבוק בזמן אימון המודל שלך. אם מערך הנתונים שלך גדול מכדי להתאים לזיכרון, אתה יכול גם להשתמש בשיטה זו כדי ליצור מטמון בעל ביצועים בדיסק. -
Dataset.prefetchחופף לעיבוד מקדים של נתונים וביצוע מודלים תוך כדי אימון.
קוראים מעוניינים יכולים ללמוד עוד על שתי השיטות, כמו גם כיצד לשמר נתונים בדיסק בסעיף 'אחזור מראש ' של מדריך ביצועים טובים יותר עם tf.data API .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
לאמן דוגמנית
למען השלמות, תראה כיצד לאמן מודל פשוט באמצעות מערכי הנתונים שהכנת זה עתה.
המודל Sequential מורכב משלושה בלוקים של קונבולציה ( tf.keras.layers.Conv2D ) עם שכבת בריכה מקסימלית ( tf.keras.layers.MaxPooling2D ) בכל אחד מהם. יש שכבה מחוברת לחלוטין ( tf.keras.layers.Dense ) עם 128 יחידות מעליה שמופעלת על ידי פונקציית הפעלה של ReLU ( 'relu' ). המודל הזה לא כוונן בשום צורה - המטרה היא להראות לך את המכניקה באמצעות מערכי הנתונים שיצרת זה עתה. למידע נוסף על סיווג תמונות, בקר במדריך סיווג תמונות .
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
בחר tf.keras.optimizers.Adam Optimizer ו- tf.keras.losses.SparseCategoricalCrossentropy אובדן. כדי להציג את דיוק ההדרכה והאימות עבור כל עידן אימון, העבר את ארגומנט metrics אל Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
ייתכן שתבחין שדיוק האימות נמוך בהשוואה לדיוק האימון, מה שמצביע על כך שהדגם שלך מתאים יותר מדי. תוכל ללמוד עוד על התאמת יתר וכיצד לצמצם אותה במדריך זה.
שימוש ב-tf.data לשליטה עדינה יותר
כלי העיבוד המקדים של Keras לעיל - tf.keras.utils.image_dataset_from_directory - הוא דרך נוחה ליצור tf.data.Dataset תמונות.
לשליטה עדינה יותר של גרגירים, אתה יכול לכתוב צינור קלט משלך באמצעות tf.data . סעיף זה מראה כיצד לעשות זאת, החל בנתיבי הקבצים מקובץ TGZ שהורדת קודם לכן.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
ניתן להשתמש במבנה העץ של הקבצים כדי להרכיב רשימה של class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
פצל את מערך הנתונים לקבוצות הדרכה ואימות:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
ניתן להדפיס את האורך של כל מערך נתונים באופן הבא:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
כתוב פונקציה קצרה הממירה נתיב קובץ לזוג (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
השתמש Dataset.map כדי ליצור מערך נתונים של זוגות image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
הגדר את מערך הנתונים לביצועים
כדי לאמן מודל עם מערך הנתונים הזה, תרצה את הנתונים:
- להיות דשדש היטב.
- להיות באצווה.
- אצוות יהיו זמינות בהקדם האפשרי.
ניתן להוסיף תכונות אלו באמצעות ממשק ה-API של tf.data . לפרטים נוספים, בקר במדריך ביצועי צינור קלט .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
דמיינו את הנתונים
אתה יכול לדמיין את מערך הנתונים הזה באופן דומה לזה שיצרת בעבר:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
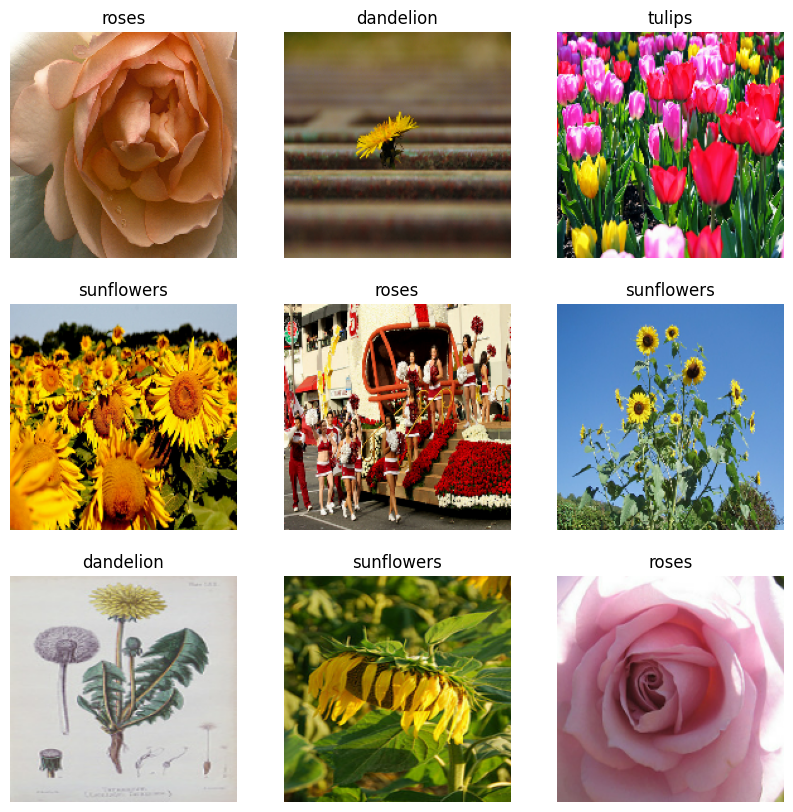
המשך להכשיר את הדגם
כעת בנית באופן ידני מערך tf.data.Dataset דומה לזה שנוצר על ידי tf.keras.utils.image_dataset_from_directory למעלה. אתה יכול להמשיך לאמן את הדגם איתו. כמו קודם, תתאמן רק לכמה תקופות כדי לשמור על זמן הריצה קצר.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
שימוש בערכות נתונים של TensorFlow
עד כה, מדריך זה התמקד בטעינת נתונים מהדיסק. אתה יכול גם למצוא מערך נתונים לשימוש על ידי חקר הקטלוג הגדול של מערכי נתונים קלים להורדה ב- TensorFlow Datasets .
כפי שטען בעבר את מערך הנתונים של Flowers מחוץ לדיסק, בוא נייבא אותו כעת עם ערכות נתונים של TensorFlow.
הורד את מערך הנתונים של Flowers באמצעות ערכות נתונים של TensorFlow:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
למערך הנתונים של הפרחים יש חמש מחלקות:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
אחזר תמונה ממערך הנתונים:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

כמו קודם, זכור לקבץ, לערבב ולהגדיר את מערכי ההדרכה, האימות והבדיקות לביצועים:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
תוכל למצוא דוגמה מלאה לעבודה עם מערך הנתונים של Flowers ו- TensorFlow Datasets על ידי ביקור במדריך להגדלת נתונים .
הצעדים הבאים
מדריך זה הראה שתי דרכים לטעינת תמונות מהדיסק. ראשית, למדת כיצד לטעון ולעבד מראש מערך תמונות באמצעות שכבות וכלי עזר לעיבוד מקדים של Keras. לאחר מכן, למדת כיצד לכתוב צינור קלט מאפס באמצעות tf.data . לבסוף, למדת כיצד להוריד מערך נתונים מ- TensorFlow Datasets.
לצעדים הבאים שלך:
- אתה יכול ללמוד כיצד להוסיף הגדלת נתונים .
- למידע נוסף על
tf.data, אתה יכול לבקר במדריך tf.data: בניית צינורות קלט של TensorFlow .