
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu öğretici, Open AI Gym CartPole-V0 ortamında bir aracıyı eğitmek için TensorFlow kullanılarak Actor-Critic yönteminin nasıl uygulanacağını gösterir. Okuyucunun, pekiştirmeli öğrenmenin politika gradyan yöntemlerine biraz aşina olduğu varsayılır.
Oyuncu-Eleştirmen yöntemleri
Actor-Critic yöntemleri, değer işlevinden bağımsız politika işlevini temsil eden zamansal fark (TD) öğrenme yöntemleridir.
Bir ilke işlevi (veya ilke), aracının verilen duruma göre gerçekleştirebileceği eylemler üzerinde bir olasılık dağılımı döndürür. Bir değer işlevi, belirli bir durumda başlayan ve sonsuza kadar belirli bir ilkeye göre hareket eden bir aracı için beklenen getiriyi belirler.
Aktör-Eleştiri yönteminde, politika, belirli bir durum verilen bir dizi olası eylem öneren aktör olarak adlandırılır ve tahmini değer işlevi, aktör tarafından verilen politikaya dayalı olarak gerçekleştirilen eylemleri değerlendiren eleştirmen olarak adlandırılır. .
Bu öğreticide, hem Aktör hem de Eleştirmen , iki çıkışlı bir sinir ağı kullanılarak temsil edilecektir.
ArabaKutup-v0
CartPole-v0 ortamında , sürtünmesiz bir yol boyunca hareket eden bir arabaya bir direk bağlanır. Direk dik başlar ve ajanın amacı, arabaya -1 veya +1 kuvvet uygulayarak düşmesini önlemektir. Direğin dik kaldığı her adım için +1 ödül verilir. Bir bölüm, (1) direk dikeyden 15 dereceden fazla olduğunda veya (2) araba merkezden 2,4 birimden fazla hareket ettiğinde sona erer.
Bölüm için ortalama toplam ödül 100 ardışık denemede 195'e ulaştığında sorun "çözülmüş" olarak kabul edilir.
Kurmak
Gerekli paketleri içe aktarın ve genel ayarları yapılandırın.
pip install gympip install pyglet
-yer tutucu37 l10n-yer# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
modeli
Aktör ve Eleştirmen , sırasıyla eylem olasılıklarını ve kritik değerini üreten bir sinir ağı kullanılarak modellenecektir. Bu öğretici, modeli tanımlamak için model alt sınıflamayı kullanır.
İleri geçiş sırasında, model durumu girdi olarak alacak ve hem eylem olasılıklarını hem de duruma bağlı değer fonksiyonunu modelleyen kritik değeri \(V\)çıktısını alacaktır. Amaç, beklenen getiriyi en üst düzeye çıkaran bir \(\pi\) ilkesine dayalı olarak eylemleri seçen bir model eğitmektir.
Cartpole-v0 için durumu temsil eden dört değer vardır: sırasıyla araba konumu, araba hızı, kutup açısı ve kutup hızı. Temsilci, sepeti sırasıyla sola (0) ve sağa (1) itmek için iki işlem yapabilir.
Daha fazla bilgi için OpenAI Gym'in CartPole-v0 wiki sayfasına bakın.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
Eğitim
Temsilciyi eğitmek için şu adımları izleyeceksiniz:
- Bölüm başına eğitim verilerini toplamak için aracıyı ortamda çalıştırın.
- Her zaman adımında beklenen getiriyi hesaplayın.
- Birleştirilmiş aktör-eleştirmen modeli için kaybı hesaplayın.
- Gradyanları hesaplayın ve ağ parametrelerini güncelleyin.
- Başarı kriterine veya maksimum bölümlere ulaşılana kadar 1-4'ü tekrarlayın.
1. Eğitim verilerinin toplanması
Denetimli öğrenmede olduğu gibi, aktör-eleştirmen modelini eğitmek için eğitim verisine sahip olmanız gerekir. Ancak, bu tür verileri toplamak için modelin ortamda "çalıştırılması" gerekir.
Her bölüm için eğitim verileri toplanır. Ardından, her zaman adımında, modelin ağırlıkları tarafından parametrelenen mevcut politikaya dayalı olarak eylem olasılıkları ve kritik değeri oluşturmak için modelin ileri geçişi ortamın durumu üzerinde çalıştırılacaktır.
Bir sonraki eylem, model tarafından oluşturulan eylem olasılıklarından örneklenecek ve daha sonra çevreye uygulanarak bir sonraki durum ve ödülün oluşturulmasına neden olacaktır.
Bu işlem, daha hızlı eğitim için daha sonra bir TensorFlow grafiğinde derlenebilmesi için TensorFlow işlemlerini kullanan run_episode işlevinde uygulanır. Değişken uzunluklu dizilerde Tensor yinelemesini desteklemek için tf.TensorArray s kullanıldığını unutmayın.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. Beklenen getirilerin hesaplanması
Her bir zaman adımı \(t\), \(\{r_{t}\}^{T}_{t=1}\) için bir bölüm sırasında toplanan ödül dizisi, ödüllerin toplamının geçerli zaman adımından \(t\) ila \(T\) ve her birinin alındığı \(\{G_{t}\}^{T}_{t=1}\) beklenen getiriler dizisine dönüştürülür. ödül, katlanarak azalan bir indirim faktörü \(\gamma\)ile çarpılır:
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
\(\gamma\in(0,1)\)'dan beri, mevcut zaman adımından daha uzak olan ödüllere daha az ağırlık verilir.
Sezgisel olarak, beklenen getiri basitçe, şimdiki ödüllerin sonraki ödüllerden daha iyi olduğu anlamına gelir. Matematiksel anlamda, ödüllerin toplamının yakınsamasını sağlamaktır.
Eğitimi stabilize etmek için, sonuçta ortaya çıkan geri dönüş dizisi de standartlaştırılır (yani sıfır ortalama ve birim standart sapmaya sahip olmak).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. Oyuncu-eleştirmen kaybı
Bir hibrit aktör-eleştirmen modeli kullanıldığından, seçilen kayıp fonksiyonu, aşağıda gösterildiği gibi, eğitim için aktör ve kritik kayıplarının bir kombinasyonudur:
\[L = L_{actor} + L_{critic}\]
Aktör kaybı
Aktör kaybı, duruma bağlı bir temel olarak eleştirmen ile politika gradyanlarına dayanır ve tek örnek (bölüm başına) tahminlerle hesaplanır.
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
nerede:
- \(T\): bölüm başına değişebilen, bölüm başına zaman adımı sayısı
- \(s_{t}\): zaman adımındaki durum \(t\)
- \(a_{t}\): zaman adımında seçilen eylem \(t\) verilen durum \(s\)
- \(\pi_{\theta}\): \(\theta\)tarafından parametrelendirilen politikadır (aktör).
- \(V^{\pi}_{\theta}\): \(\theta\)tarafından da parametrelenen değer işlevidir (kritik).
- \(G = G_{t}\): belirli bir durum için beklenen getiri, zaman adımında eylem çifti \(t\)
Fikir, birleşik kaybı en aza indirerek daha yüksek ödüller veren eylemlerin olasılıklarını en üst düzeye çıkarmak olduğundan, toplama negatif bir terim eklenir.
Avantaj
\(G - V\) \(L_{actor}\) terimi, bir eyleme belirli bir duruma o durum için \(\pi\) ilkesine göre seçilen rastgele bir eyleme göre ne kadar daha iyi verildiğini gösteren avantaj olarak adlandırılır.
Bir temel çizgiyi hariç tutmak mümkün olsa da, bu, eğitim sırasında yüksek varyansa neden olabilir. Ve temel olarak kritik \(V\) seçmenin güzel yanı, l10n- \(G\)mümkün olduğunca yakın olacak şekilde eğitilmiş olması ve bu da daha düşük bir varyansa yol açmasıdır.
Ek olarak, eleştirmen olmadan, algoritma beklenen getiriye dayalı olarak belirli bir durumda gerçekleştirilen eylemler için olasılıkları artırmaya çalışacaktır; bu, eylemler arasındaki göreceli olasılıklar aynı kalırsa pek bir fark yaratmayabilir.
Örneğin, belirli bir durum için iki eylemin aynı beklenen getiriyi sağlayacağını varsayalım. Eleştirmen olmadan, algoritma bu eylemlerin olasılığını \(J\)hedefine dayalı olarak yükseltmeye çalışacaktır. Eleştirmenle, hiçbir avantajın olmadığı (\(G - V = 0\)) ortaya çıkabilir ve bu nedenle eylemlerin olasılıklarını arttırmada hiçbir fayda elde edilemez ve algoritma gradyanları sıfıra ayarlar.
kritik kayıp
\(V\) mümkün olduğunca yakın olacak şekilde \(G\) , aşağıdaki kayıp işleviyle bir regresyon problemi olarak kurulabilir:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
burada \(L_{\delta}\) , verilerdeki aykırı değerlere kare-hata kaybından daha az duyarlı olan Huber kaybıdır.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. Parametreleri güncellemek için eğitim adımını tanımlama
Yukarıdaki adımların tümü, her bölümde çalıştırılan bir eğitim adımında birleştirilir. Kayıp işlevine giden tüm adımlar, otomatik farklılaşmayı sağlamak için tf.GradientTape bağlamıyla yürütülür.
Bu öğretici, degradeleri model parametrelerine uygulamak için Adam optimizer'ı kullanır.
İndirilmeyen ödüllerin toplamı, episode_reward da bu adımda hesaplanır. Bu değer daha sonra başarı kriterinin karşılanıp karşılanmadığını değerlendirmek için kullanılacaktır.
tf.function bağlamı, train_step işlevine uygulanır, böylece eğitimde 10 kat hızlanmaya yol açabilecek çağrılabilir bir TensorFlow grafiğine derlenebilir.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. Eğitim döngüsünü çalıştırın
Eğitim, başarı kriterine veya maksimum bölüm sayısına ulaşılana kadar eğitim adımı çalıştırılarak gerçekleştirilir.
Bölüm ödüllerinin devam eden bir kaydı bir kuyrukta tutulur. 100 denemeye ulaşıldığında, sıranın sol (kuyruk) ucundaki en eski ödül kaldırılır ve en yenisi başa (sağ) eklenir. Hesaplama verimliliği için ödüllerin devam eden bir toplamı da korunur.
Çalışma zamanınıza bağlı olarak, eğitim bir dakikadan daha kısa sürede tamamlanabilir.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
görselleştirme
Eğitimden sonra, modelin ortamda nasıl performans gösterdiğini görselleştirmek iyi olacaktır. Modelin bir bölümünün çalıştırıldığı GIF animasyonunu oluşturmak için aşağıdaki hücreleri çalıştırabilirsiniz. OpenAI Gym için ortamın görüntülerini Colab'da doğru bir şekilde işlemesi için ek paketlerin yüklenmesi gerektiğini unutmayın.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
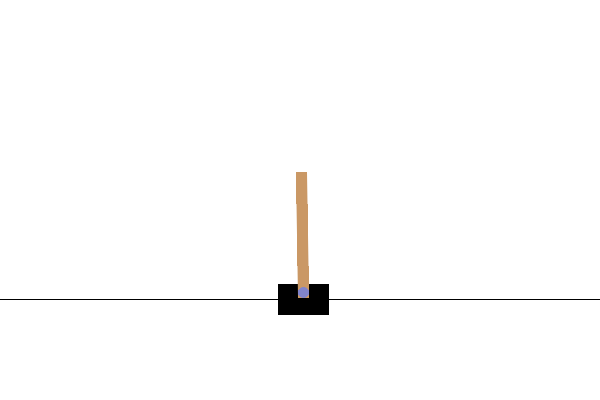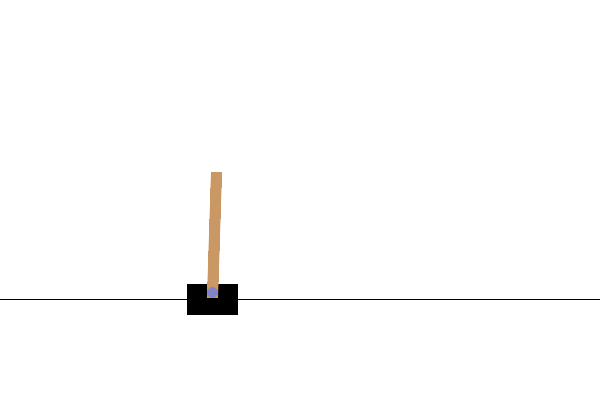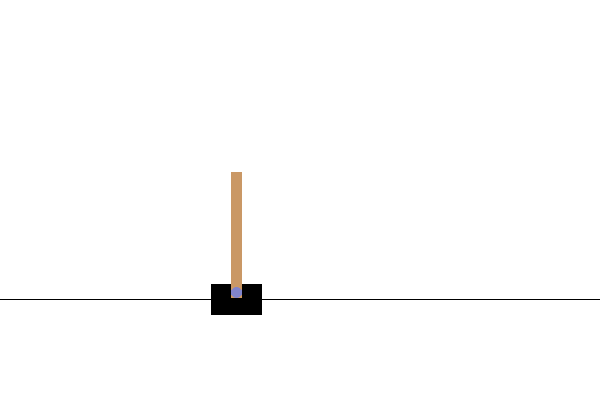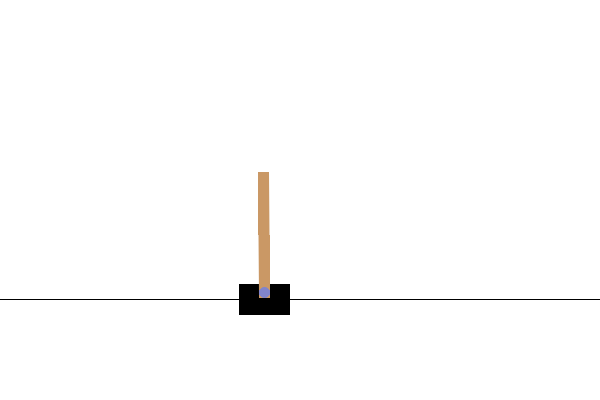
Sonraki adımlar
Bu öğretici, Tensorflow kullanarak aktör-eleştirmen yönteminin nasıl uygulanacağını gösterdi.
Bir sonraki adım olarak, OpenAI Gym'de bir modeli farklı bir ortamda eğitmeyi deneyebilirsiniz.
Oyuncu-eleştirmen yöntemleri ve Cartpole-v0 sorunu hakkında ek bilgi için aşağıdaki kaynaklara başvurabilirsiniz:
- Oyuncu Eleştirmen Yöntemi
- Aktör Eleştirmen Dersi (CAL)
- Kartpole öğrenme kontrol problemi [Barto, et al. 1983]
TensorFlow'da daha fazla pekiştirmeli öğrenme örneği için aşağıdaki kaynakları kontrol edebilirsiniz: