
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này trình bày cách triển khai phương pháp Actor-Critic bằng cách sử dụng TensorFlow để đào tạo một nhân viên trên môi trường Open AI Gym CartPole-V0. Người đọc được cho là đã quen thuộc với các phương pháp học tăng cường chính sách theo gradient .
Phương pháp phê bình diễn viên
Các phương pháp Actor-Critic là các phương pháp học tập về sự khác biệt theo thời gian (TD) thể hiện chức năng chính sách độc lập với chức năng giá trị.
Một hàm chính sách (hoặc chính sách) trả về phân phối xác suất cho các hành động mà tác nhân có thể thực hiện dựa trên trạng thái đã cho. Một hàm giá trị xác định lợi nhuận kỳ vọng cho một tác nhân bắt đầu từ một trạng thái nhất định và hoạt động theo một chính sách cụ thể mãi mãi sau đó.
Trong phương pháp Tác nhân-Phê bình, chính sách được gọi là tác nhân đề xuất một tập hợp các hành động có thể xảy ra với một trạng thái và hàm giá trị ước tính được gọi là tác nhân phê bình , đánh giá các hành động được thực hiện bởi tác nhân dựa trên chính sách đã cho. .
Trong hướng dẫn này, cả Actor và Critic sẽ được trình bày bằng cách sử dụng một mạng nơ-ron với hai đầu ra.
CartPole-v0
Trong môi trường CartPole-v0 , một cực được gắn vào một xe đẩy di chuyển dọc theo một đường ray không ma sát. Trụ bắt đầu thẳng đứng và mục tiêu của tác nhân là ngăn nó đổ bằng cách tác dụng một lực -1 hoặc +1 lên xe đẩy. Phần thưởng +1 được trao cho mỗi lần bước cột vẫn thẳng đứng. Một tập kết thúc khi (1) cái sào lệch 15 độ so với phương thẳng đứng hoặc (2) chiếc xe đẩy lệch tâm hơn 2,4 đơn vị.
Vấn đề coi như "giải được" khi tổng phần thưởng trung bình của tập phim đạt 195 trên 100 lần thử nghiệm liên tiếp.
Thành lập
Nhập các gói cần thiết và định cấu hình cài đặt chung.
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
Mô hình
Tác nhân và Người chỉ trích sẽ được lập mô hình bằng cách sử dụng một mạng nơ- ron tạo ra xác suất hành động và giá trị phê bình tương ứng. Hướng dẫn này sử dụng phân lớp mô hình để xác định mô hình.
Trong quá trình chuyển tiếp, mô hình sẽ lấy trạng thái làm đầu vào và sẽ xuất ra cả xác suất hành động và giá trị \(V\), mô hình này mô hình hóa hàm giá trị phụ thuộc vào trạng thái. Mục tiêu là đào tạo một mô hình chọn các hành động dựa trên chính sách \(\pi\) nhằm tối đa hóa lợi tức mong đợi .
Đối với Cartpole-v0, có bốn giá trị đại diện cho trạng thái lần lượt là: vị trí cart, vận tốc cart, góc cực và vận tốc cực. Nhân viên có thể thực hiện hai hành động để đẩy giỏ hàng lần lượt sang trái (0) và sang phải (1).
Tham khảo trang wiki CartPole-v0 của OpenAI Gym để biết thêm thông tin.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
Tập huấn
Để đào tạo đại lý, bạn sẽ làm theo các bước sau:
- Chạy tác nhân trên môi trường để thu thập dữ liệu đào tạo mỗi tập.
- Tính toán lợi nhuận kỳ vọng ở mỗi bước thời gian.
- Tính toán tổn thất cho mô hình kết hợp giữa diễn viên và nhà phê bình.
- Tính toán độ dốc và cập nhật các thông số mạng.
- Lặp lại 1-4 cho đến khi đạt được tiêu chí thành công hoặc số tập tối đa.
1. Thu thập dữ liệu đào tạo
Giống như trong học tập có giám sát, để đào tạo mô hình diễn viên-nhà phê bình, bạn cần phải có dữ liệu đào tạo. Tuy nhiên, để thu thập dữ liệu như vậy, mô hình sẽ cần được "chạy" trong môi trường.
Dữ liệu đào tạo được thu thập cho mỗi tập. Sau đó, tại mỗi bước thời gian, chuyển tiếp của mô hình sẽ được chạy trên trạng thái của môi trường để tạo ra xác suất hành động và giá trị tới hạn dựa trên chính sách hiện tại được tham số hóa bởi trọng số của mô hình.
Hành động tiếp theo sẽ được lấy mẫu từ các xác suất hành động do mô hình tạo ra, sau đó sẽ được áp dụng cho môi trường, gây ra trạng thái và phần thưởng tiếp theo được tạo ra.
Quá trình này được thực hiện trong hàm run_episode , sử dụng các hoạt động TensorFlow để sau đó nó có thể được biên dịch thành đồ thị TensorFlow để đào tạo nhanh hơn. Lưu ý rằng tf.TensorArray được sử dụng để hỗ trợ lặp lại Tensor trên các mảng có độ dài thay đổi.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. Tính toán lợi nhuận kỳ vọng
Chuỗi phần thưởng cho mỗi bước \(t\), \(\{r_{t}\}^{T}_{t=1}\) được thu thập trong một tập được chuyển đổi thành chuỗi trả về dự kiến \(\{G_{t}\}^{T}_{t=1}\) , trong đó tổng phần thưởng được lấy từ timestep hiện tại \(t\) đến \(T\) và mỗi phần thưởng được nhân với hệ số chiết khấu giảm dần theo cấp số nhân \(\gamma\):
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
Kể từ \(\gamma\in(0,1)\), phần thưởng xa hơn so với bước thời gian hiện tại sẽ có ít trọng lượng hơn.
Về mặt trực quan, lợi nhuận mong đợi chỉ đơn giản ngụ ý rằng phần thưởng bây giờ tốt hơn phần thưởng sau này. Theo nghĩa toán học, nó là để đảm bảo rằng tổng các phần thưởng hội tụ.
Để ổn định đào tạo, chuỗi kết quả trả về cũng được tiêu chuẩn hóa (nghĩa là không có giá trị trung bình và độ lệch chuẩn đơn vị).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. Sự mất mát của diễn viên-nhà phê bình
Vì mô hình diễn viên-nhà phê bình kết hợp được sử dụng, hàm mất mát được chọn là sự kết hợp của tổn thất tác nhân và nhà phê bình cho quá trình đào tạo, như được hiển thị bên dưới:
\[L = L_{actor} + L_{critic}\]
Diễn viên mất
Tổn thất của tác nhân dựa trên độ phân cấp chính sách với nhà phê bình là đường cơ sở phụ thuộc vào tiểu bang và được tính toán với ước tính đơn mẫu (mỗi tập).
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
ở đâu:
- \(T\): số bước thời gian trên mỗi tập, có thể thay đổi trên mỗi tập
- \(s_{t}\): trạng thái tại timestep \(t\)
- \(a_{t}\): hành động đã chọn tại bước timestep \(t\) đã cho trạng thái \(s\)
- \(\pi_{\theta}\): là chính sách (tác nhân) được tham số hóa bởi \(\theta\)
- \(V^{\pi}_{\theta}\): là hàm giá trị (phê bình) cũng được tham số hóa bởi \(\theta\)
- \(G = G_{t}\): lợi nhuận dự kiến cho một trạng thái nhất định, cặp hành động ở bước timestep \(t\)
Một thuật ngữ âm được thêm vào tổng vì ý tưởng là tối đa hóa xác suất của các hành động mang lại phần thưởng cao hơn bằng cách giảm thiểu tổn thất tổng hợp.
Thuận lợi
Thuật ngữ \(L_{actor}\) \(G - V\) chúng tôi được gọi là lợi thế , cho biết mức độ tốt hơn một hành động được cung cấp cho một trạng thái cụ thể so với một hành động ngẫu nhiên được chọn theo chính sách \(\pi\) cho trạng thái đó.
Mặc dù có thể loại trừ đường cơ sở, nhưng điều này có thể dẫn đến phương sai cao trong quá trình đào tạo. Và điều thú vị khi chọn phê bình \(V\) làm đường cơ sở là nó được đào tạo để càng gần với \(G\)càng tốt, dẫn đến phương sai thấp hơn.
Ngoài ra, không có người chỉ trích, thuật toán sẽ cố gắng tăng xác suất cho các hành động được thực hiện trên một trạng thái cụ thể dựa trên lợi nhuận kỳ vọng, điều này có thể không tạo ra nhiều khác biệt nếu xác suất tương đối giữa các hành động vẫn như nhau.
Ví dụ: giả sử rằng hai hành động cho một trạng thái nhất định sẽ mang lại cùng một lợi tức mong đợi. Nếu không có người chỉ trích, thuật toán sẽ cố gắng tăng xác suất của những hành động này dựa trên mục tiêu \(J\). Với người chỉ trích, có thể không có lợi thế nào (\(G - V = 0\)) và do đó, không có lợi ích nào thu được khi tăng xác suất của các hành động và thuật toán sẽ đặt độ dốc bằng 0.
Mất mát nghiêm trọng
Việc đào tạo \(V\) để gần nhất có thể với \(G\) có thể được thiết lập như một vấn đề hồi quy với hàm mất sau:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
trong đó \(L_{\delta}\) là tổn thất Huber , ít nhạy cảm với các giá trị ngoại lệ trong dữ liệu hơn là tổn thất lỗi bình phương.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. Xác định bước huấn luyện để cập nhật các tham số
Tất cả các bước trên được kết hợp thành một bước đào tạo được chạy mỗi tập. Tất cả các bước dẫn đến hàm mất mát được thực thi với ngữ cảnh tf.GradientTape để cho phép phân biệt tự động.
Hướng dẫn này sử dụng trình tối ưu hóa Adam để áp dụng các gradient cho các tham số mô hình.
Tổng số phần thưởng chưa chiết khấu, episode_reward , cũng được tính trong bước này. Giá trị này sau này sẽ được sử dụng để đánh giá xem tiêu chí thành công có được đáp ứng hay không.
Ngữ cảnh tf.function . function được áp dụng cho hàm train_step để nó có thể được biên dịch thành một đồ thị TensorFlow có thể gọi, có thể dẫn đến tốc độ đào tạo tăng gấp 10 lần.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. Chạy vòng lặp đào tạo
Huấn luyện được thực hiện bằng cách chạy bước huấn luyện cho đến khi đạt được tiêu chí thành công hoặc số tập tối đa.
Bản ghi đang chạy của phần thưởng tập được lưu trong hàng đợi. Sau khi đạt được 100 lượt thử, phần thưởng cũ nhất sẽ bị xóa ở cuối (đuôi) bên trái của hàng đợi và phần thưởng mới nhất được thêm vào ở đầu (phải). Tổng số phần thưởng đang chạy cũng được duy trì để mang lại hiệu quả tính toán.
Tùy thuộc vào thời gian chạy của bạn, quá trình đào tạo có thể kết thúc trong vòng chưa đầy một phút.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
Hình dung
Sau khi đào tạo, sẽ rất tốt nếu bạn hình dung được mô hình hoạt động như thế nào trong môi trường. Bạn có thể chạy các ô bên dưới để tạo ảnh động GIF của một tập chạy mô hình. Lưu ý rằng các gói bổ sung cần được cài đặt cho OpenAI Gym để hiển thị hình ảnh của môi trường một cách chính xác trong Colab.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
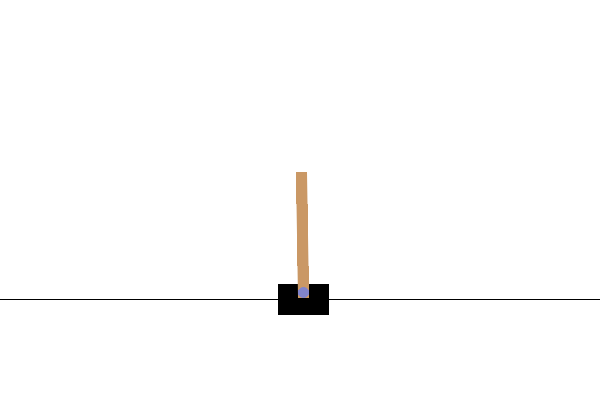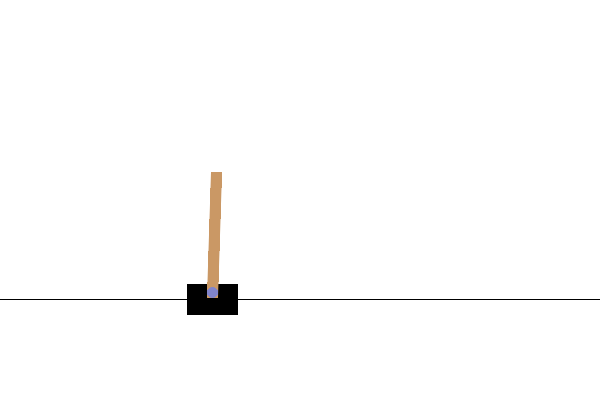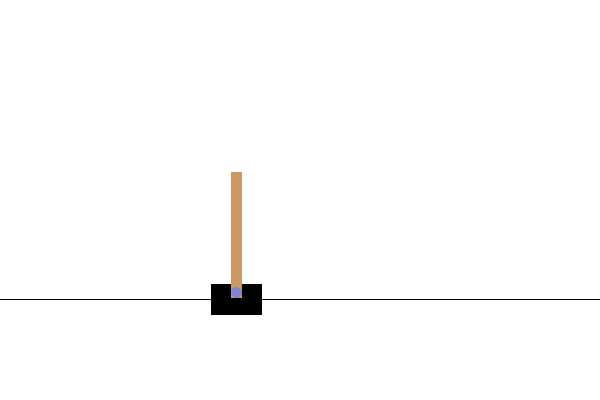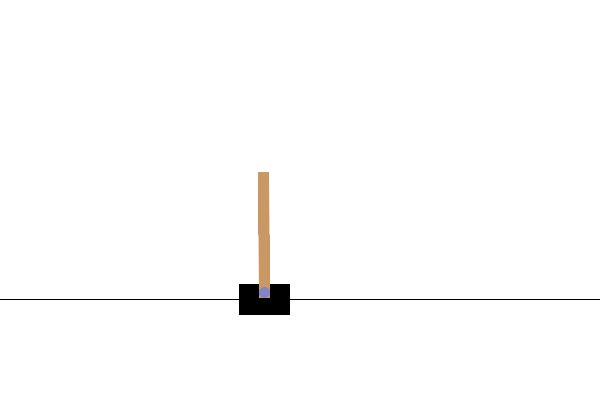
Bước tiếp theo
Hướng dẫn này đã trình bày cách triển khai phương pháp diễn viên-phê bình bằng Tensorflow.
Bước tiếp theo, bạn có thể thử đào tạo người mẫu trên một môi trường khác trong Phòng tập thể dục OpenAI.
Để biết thêm thông tin về phương pháp tác nhân-phê bình và vấn đề Cartpole-v0, bạn có thể tham khảo các tài nguyên sau:
- Phương pháp phê bình diễn viên
- Bài giảng về nhà phê bình diễn viên (CAL)
- Vấn đề điều khiển học Cartpole [Barto, et al. 1983]
Để biết thêm các ví dụ học tập củng cố trong TensorFlow, bạn có thể kiểm tra các tài nguyên sau: