
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल दर्शाता है कि सीएसवी फ़ाइल में संग्रहीत कागल प्रतियोगिता से पेटफाइंडर डेटासेट के सरलीकृत संस्करण का उपयोग करके संरचित डेटा, जैसे सारणीबद्ध डेटा को कैसे वर्गीकृत किया जाए।
आप मॉडल को परिभाषित करने के लिए केरस का उपयोग करेंगे, और मॉडल को प्रशिक्षित करने के लिए उपयोग की जाने वाली सुविधाओं के लिए CSV फ़ाइल में कॉलम से मैप करने के लिए केरस प्रीप्रोसेसिंग परतों को एक पुल के रूप में उपयोग करेंगे। लक्ष्य यह भविष्यवाणी करना है कि क्या एक पालतू जानवर को अपनाया जाएगा।
इस ट्यूटोरियल में इसके लिए पूरा कोड है:
- पांडा का उपयोग करके एक CSV फ़ाइल को DataFrame में लोड करना।
- बैच के लिए इनपुट पाइपलाइन बनाना और
tf.dataका उपयोग करके पंक्तियों को शफ़ल करना। ( tf.data पर जाएं: अधिक विवरण के लिए TensorFlow इनपुट पाइपलाइन बनाएं ।) - केरस प्रीप्रोसेसिंग परतों के साथ मॉडल को प्रशिक्षित करने के लिए उपयोग की जाने वाली सुविधाओं के लिए सीएसवी फ़ाइल में कॉलम से मैपिंग।
- केरस बिल्ट-इन विधियों का उपयोग करके एक मॉडल का निर्माण, प्रशिक्षण और मूल्यांकन।
PetFinder.my मिनी डेटासेट
PetFinder.my मिनी की CSV डेटासेट फ़ाइल में कई हज़ार पंक्तियाँ हैं, जहाँ प्रत्येक पंक्ति एक पालतू जानवर (कुत्ते या बिल्ली) का वर्णन करती है और प्रत्येक स्तंभ एक विशेषता का वर्णन करता है, जैसे कि उम्र, नस्ल, रंग, और इसी तरह।
नीचे दिए गए डेटासेट के सारांश में, ध्यान दें कि अधिकतर संख्यात्मक और श्रेणीबद्ध कॉलम हैं। इस ट्यूटोरियल में, आप डेटा प्रीप्रोसेसिंग के दौरान केवल उन दो फ़ीचर प्रकारों के साथ काम करेंगे, जो Description (एक निःशुल्क टेक्स्ट फ़ीचर) और AdoptionSpeed (एक वर्गीकरण सुविधा) को छोड़ देंगे।
| स्तंभ | पालतू विवरण | फ़ीचर प्रकार | डाटा प्रकार |
|---|---|---|---|
Type | जानवर का प्रकार ( Dog , Cat ) | स्पष्ट | डोरी |
Age | उम्र | न्यूमेरिकल | पूर्णांक |
Breed1 | प्राथमिक नस्ल | स्पष्ट | डोरी |
Color1 | रंग 1 | स्पष्ट | डोरी |
Color2 | रंग 2 | स्पष्ट | डोरी |
MaturitySize | परिपक्वता पर आकार | स्पष्ट | डोरी |
FurLength | फर की लंबाई | स्पष्ट | डोरी |
Vaccinated | पालतू को टीका लगाया गया है | स्पष्ट | डोरी |
Sterilized | पालतू जानवर की नसबंदी कर दी गई है | स्पष्ट | डोरी |
Health | स्वास्थ्य की स्थिति | स्पष्ट | डोरी |
Fee | गोद लेने का शुल्क | न्यूमेरिकल | पूर्णांक |
Description | प्रोफाइल राइट-अप | मूलपाठ | डोरी |
PhotoAmt | कुल अपलोड की गई तस्वीरें | न्यूमेरिकल | पूर्णांक |
AdoptionSpeed | गोद लेने की स्पष्ट गति | वर्गीकरण | पूर्णांक |
TensorFlow और अन्य पुस्तकालयों को आयात करें
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
tf.__version__
'2.8.0-rc1'
डेटासेट लोड करें और इसे पांडा में पढ़ें DataFrame
पांडा एक पायथन पुस्तकालय है जिसमें संरचित डेटा को लोड करने और काम करने के लिए कई उपयोगी उपयोगिताएँ हैं। PetFinder.my मिनी डेटासेट के साथ CSV फ़ाइल डाउनलोड करने और निकालने के लिए tf.keras.utils.get_file का उपयोग करें, और इसे pandas.read_csv के साथ pandas.read_csv में लोड करें:
dataset_url = 'http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip'
csv_file = 'datasets/petfinder-mini/petfinder-mini.csv'
tf.keras.utils.get_file('petfinder_mini.zip', dataset_url,
extract=True, cache_dir='.')
dataframe = pd.read_csv(csv_file)
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip 1671168/1668792 [==============================] - 0s 0us/step 1679360/1668792 [==============================] - 0s 0us/step
डेटाफ़्रेम की पहली पाँच पंक्तियों की जाँच करके डेटासेट का निरीक्षण करें:
dataframe.head()
एक लक्ष्य चर बनाएँ
कागल की पेटफाइंडर.माई एडॉप्शन प्रेडिक्शन प्रतियोगिता में मूल कार्य उस गति की भविष्यवाणी करना था जिस पर एक पालतू जानवर को अपनाया जाएगा (जैसे पहले सप्ताह में, पहले महीने में, पहले तीन महीने, और इसी तरह)।
इस ट्यूटोरियल में, आप इसे बाइनरी वर्गीकरण समस्या में बदलकर कार्य को सरल बना देंगे, जहां आपको केवल यह अनुमान लगाना होगा कि पालतू जानवर को अपनाया गया था या नहीं।
AdoptionSpeed कॉलम को संशोधित करने के बाद, 0 इंगित करेगा कि पालतू जानवर को नहीं अपनाया गया था, और 1 इंगित करेगा कि यह था।
# In the original dataset, `'AdoptionSpeed'` of `4` indicates
# a pet was not adopted.
dataframe['target'] = np.where(dataframe['AdoptionSpeed']==4, 0, 1)
# Drop unused features.
dataframe = dataframe.drop(columns=['AdoptionSpeed', 'Description'])
डेटाफ़्रेम को प्रशिक्षण, सत्यापन और परीक्षण सेट में विभाजित करें
डेटासेट एकल पांडा डेटाफ़्रेम में है। उदाहरण के लिए, क्रमशः 80:10:10 अनुपात का उपयोग करके इसे प्रशिक्षण, सत्यापन और परीक्षण सेट में विभाजित करें:
train, val, test = np.split(dataframe.sample(frac=1), [int(0.8*len(dataframe)), int(0.9*len(dataframe))])
print(len(train), 'training examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
9229 training examples 1154 validation examples 1154 test examples
tf.data का उपयोग करके एक इनपुट पाइपलाइन बनाएं
इसके बाद, एक उपयोगिता फ़ंक्शन बनाएं जो प्रत्येक प्रशिक्षण, सत्यापन और परीक्षण सेट DataFrame को tf.data.Dataset में परिवर्तित करता है, फिर डेटा को फेरबदल और बैच करता है।
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
df = dataframe.copy()
labels = df.pop('target')
df = {key: value[:,tf.newaxis] for key, value in dataframe.items()}
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
अब, नए बनाए गए फ़ंक्शन का उपयोग करें ( df_to_dataset ) डेटा के प्रारूप की जांच करने के लिए इनपुट पाइपलाइन हेल्पर फ़ंक्शन इसे प्रशिक्षण डेटा पर कॉल करके लौटाता है, और आउटपुट को पढ़ने योग्य रखने के लिए एक छोटे बैच आकार का उपयोग करें:
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
[(train_features, label_batch)] = train_ds.take(1)
print('Every feature:', list(train_features.keys()))
print('A batch of ages:', train_features['Age'])
print('A batch of targets:', label_batch )
Every feature: ['Type', 'Age', 'Breed1', 'Gender', 'Color1', 'Color2', 'MaturitySize', 'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Fee', 'PhotoAmt', 'target'] A batch of ages: tf.Tensor( [[84] [ 1] [ 5] [ 1] [12]], shape=(5, 1), dtype=int64) A batch of targets: tf.Tensor([1 1 0 1 0], shape=(5,), dtype=int64)
जैसा कि आउटपुट प्रदर्शित करता है, प्रशिक्षण सेट कॉलम नामों (डेटाफ़्रेम से) का एक शब्दकोश देता है जो पंक्तियों से कॉलम मानों को मैप करता है।
केरस प्रीप्रोसेसिंग लेयर्स लागू करें
केरस प्रीप्रोसेसिंग परतें आपको केरस-देशी इनपुट प्रोसेसिंग पाइपलाइन बनाने की अनुमति देती हैं, जिसका उपयोग गैर-केरस वर्कफ़्लोज़ में स्वतंत्र प्रीप्रोसेसिंग कोड के रूप में किया जा सकता है, जो सीधे केरस मॉडल के साथ संयुक्त होता है, और केरस सेव्डमॉडल के हिस्से के रूप में निर्यात किया जाता है।
इस ट्यूटोरियल में, आप प्रीप्रोसेसिंग, स्ट्रक्चर्ड डेटा एन्कोडिंग, और फ़ीचर इंजीनियरिंग को प्रदर्शित करने के लिए निम्नलिखित चार प्रीप्रोसेसिंग परतों का उपयोग करेंगे:
-
tf.keras.layers.Normalization: इनपुट सुविधाओं का फीचर-वार सामान्यीकरण करता है। -
tf.keras.layers.CategoryEncoding: पूर्णांक श्रेणीबद्ध विशेषताओं को एक-गर्म, बहु-गर्म, या tf-idf सघन अभ्यावेदन में बदल देता है। -
tf.keras.layers.StringLookup: स्ट्रिंग श्रेणीबद्ध मानों को पूर्णांक सूचकांकों में बदल देता है। -
tf.keras.layers.IntegerLookup: पूर्णांक श्रेणीबद्ध मानों को पूर्णांक सूचकांकों में बदल देता है।
आप प्रीप्रोसेसिंग परतों के साथ कार्य करना मार्गदर्शिका में उपलब्ध परतों के बारे में अधिक जान सकते हैं।
- PetFinder.my मिनी डेटासेट की संख्यात्मक विशेषताओं के लिए, आप डेटा के वितरण को मानकीकृत करने के लिए
tf.keras.layers.Normalizationलेयर का उपयोग करेंगे। - पालतू
Types (DogऔरCatके तार) जैसी श्रेणीबद्ध विशेषताओं के लिए, आप उन्हेंtf.keras.layers.CategoryEncodingके साथ बहु-हॉट एन्कोडेड टेंसर में बदल देंगे।
संख्यात्मक कॉलम
PetFinder.my मिनी डेटासेट में प्रत्येक संख्यात्मक सुविधा के लिए, आप डेटा के वितरण को मानकीकृत करने के लिए tf.keras.layers.Normalization लेयर का उपयोग करेंगे।
एक नई उपयोगिता फ़ंक्शन को परिभाषित करें जो एक परत लौटाती है जो कि केरस प्रीप्रोसेसिंग परत का उपयोग करके संख्यात्मक सुविधाओं के लिए सुविधा-वार सामान्यीकरण लागू करती है:
def get_normalization_layer(name, dataset):
# Create a Normalization layer for the feature.
normalizer = layers.Normalization(axis=None)
# Prepare a Dataset that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
इसके बाद, 'PhotoAmt' को सामान्य करने के लिए कुल अपलोड की गई पालतू फ़ोटो सुविधाओं पर कॉल करके नए फ़ंक्शन का परीक्षण करें:
photo_count_col = train_features['PhotoAmt']
layer = get_normalization_layer('PhotoAmt', train_ds)
layer(photo_count_col)
<tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[-0.8272058 ],
[-0.19125296],
[ 1.3986291 ],
[-0.19125296],
[-0.50922936]], dtype=float32)>
श्रेणीबद्ध कॉलम
डेटासेट में पेट Type s को स्ट्रिंग्स के रूप में दर्शाया जाता है- Dog s और Cat s- जिन्हें मॉडल में फीड किए जाने से पहले मल्टी-हॉट एन्कोडेड होने की आवश्यकता होती है। Age विशेषता
एक अन्य नए उपयोगिता फ़ंक्शन को परिभाषित करें जो एक परत लौटाता है जो एक शब्दावली से पूर्णांक सूचकांकों के मूल्यों को मैप करता है और tf.keras.layers.StringLookup , tf.keras.layers.IntegerLookup , और tf.keras.CategoryEncoding प्रीप्रोसेसिंग का उपयोग करके सुविधाओं को एन्कोड करता है। परतें:
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
# Create a layer that turns strings into integer indices.
if dtype == 'string':
index = layers.StringLookup(max_tokens=max_tokens)
# Otherwise, create a layer that turns integer values into integer indices.
else:
index = layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a `tf.data.Dataset` that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Encode the integer indices.
encoder = layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply multi-hot encoding to the indices. The lambda function captures the
# layer, so you can use them, or include them in the Keras Functional model later.
return lambda feature: encoder(index(feature))
get_category_encoding_layer फ़ंक्शन को पालतू 'Type' सुविधाओं पर कॉल करके उन्हें मल्टी-हॉट एन्कोडेड टेंसर में बदलने के लिए परीक्षण करें:
test_type_col = train_features['Type']
test_type_layer = get_category_encoding_layer(name='Type',
dataset=train_ds,
dtype='string')
test_type_layer(test_type_col)
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.]], dtype=float32)>
पालतू 'Age' सुविधाओं पर प्रक्रिया को दोहराएं:
test_age_col = train_features['Age']
test_age_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
test_age_layer(test_age_col)
<tf.Tensor: shape=(5, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.]], dtype=float32)>
मॉडल को प्रशिक्षित करने के लिए चयनित सुविधाओं को प्रीप्रोसेस करें
आपने सीखा कि कई प्रकार के केरस प्रीप्रोसेसिंग लेयर्स का उपयोग कैसे किया जाता है। अगला, आप करेंगे:
- PetFinder.my मिनी डेटासेट से 13 संख्यात्मक और श्रेणीबद्ध विशेषताओं पर पहले परिभाषित प्रीप्रोसेसिंग उपयोगिता कार्यों को लागू करें।
- एक सूची में सभी फीचर इनपुट जोड़ें।
जैसा कि शुरुआत में उल्लेख किया गया है, मॉडल को प्रशिक्षित करने के लिए, आप PetFinder.my मिनी डेटासेट के संख्यात्मक ( 'PhotoAmt' , 'Fee' ) और श्रेणीबद्ध ( 'Age' , 'Type' , 'Color1' Color1' , 'Color2 'Color2' , 'Gender' का उपयोग करेंगे। 'Gender' , 'MaturitySize' आकार', 'FurLength' , 'Vaccinated' , 'Sterilized' , 'Health' , 'Breed1' ) विशेषताएं।
इससे पहले, आपने इनपुट पाइपलाइन को प्रदर्शित करने के लिए एक छोटे बैच आकार का उपयोग किया था। आइए अब 256 के बड़े बैच आकार के साथ एक नई इनपुट पाइपलाइन बनाएं:
batch_size = 256
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:4: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead. after removing the cwd from sys.path.
संख्यात्मक विशेषताओं (पालतू जानवरों की तस्वीरों की संख्या और गोद लेने के शुल्क) को सामान्य करें, और उन्हें encoded_features नामक इनपुट की एक सूची में जोड़ें:
all_inputs = []
encoded_features = []
# Numerical features.
for header in ['PhotoAmt', 'Fee']:
numeric_col = tf.keras.Input(shape=(1,), name=header)
normalization_layer = get_normalization_layer(header, train_ds)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
डेटासेट (पेट आयु) से पूर्णांक श्रेणीबद्ध मानों को पूर्णांक सूचकांकों में बदलें, बहु-गर्म एन्कोडिंग करें, और परिणामी सुविधा इनपुट को encoded_features में जोड़ें:
age_col = tf.keras.Input(shape=(1,), name='Age', dtype='int64')
encoding_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
encoded_age_col = encoding_layer(age_col)
all_inputs.append(age_col)
encoded_features.append(encoded_age_col)
स्ट्रिंग श्रेणीबद्ध मानों के लिए समान चरण दोहराएं:
categorical_cols = ['Type', 'Color1', 'Color2', 'Gender', 'MaturitySize',
'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Breed1']
for header in categorical_cols:
categorical_col = tf.keras.Input(shape=(1,), name=header, dtype='string')
encoding_layer = get_category_encoding_layer(name=header,
dataset=train_ds,
dtype='string',
max_tokens=5)
encoded_categorical_col = encoding_layer(categorical_col)
all_inputs.append(categorical_col)
encoded_features.append(encoded_categorical_col)
मॉडल बनाएं, संकलित करें और प्रशिक्षित करें
अगला कदम केरस फंक्शनल एपीआई का उपयोग करके एक मॉडल बनाना है। अपने मॉडल में पहली परत के लिए, encoded_features के साथ संयोजन के माध्यम से फीचर इनपुट- एन्कोडेड_फीचर्स की सूची को एक वेक्टर में tf.keras.layers.concatenate करें।
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(32, activation="relu")(all_features)
x = tf.keras.layers.Dropout(0.5)(x)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
मॉडल को Model.compile के साथ कॉन्फ़िगर करें:
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"])
आइए कनेक्टिविटी ग्राफ की कल्पना करें:
# Use `rankdir='LR'` to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")
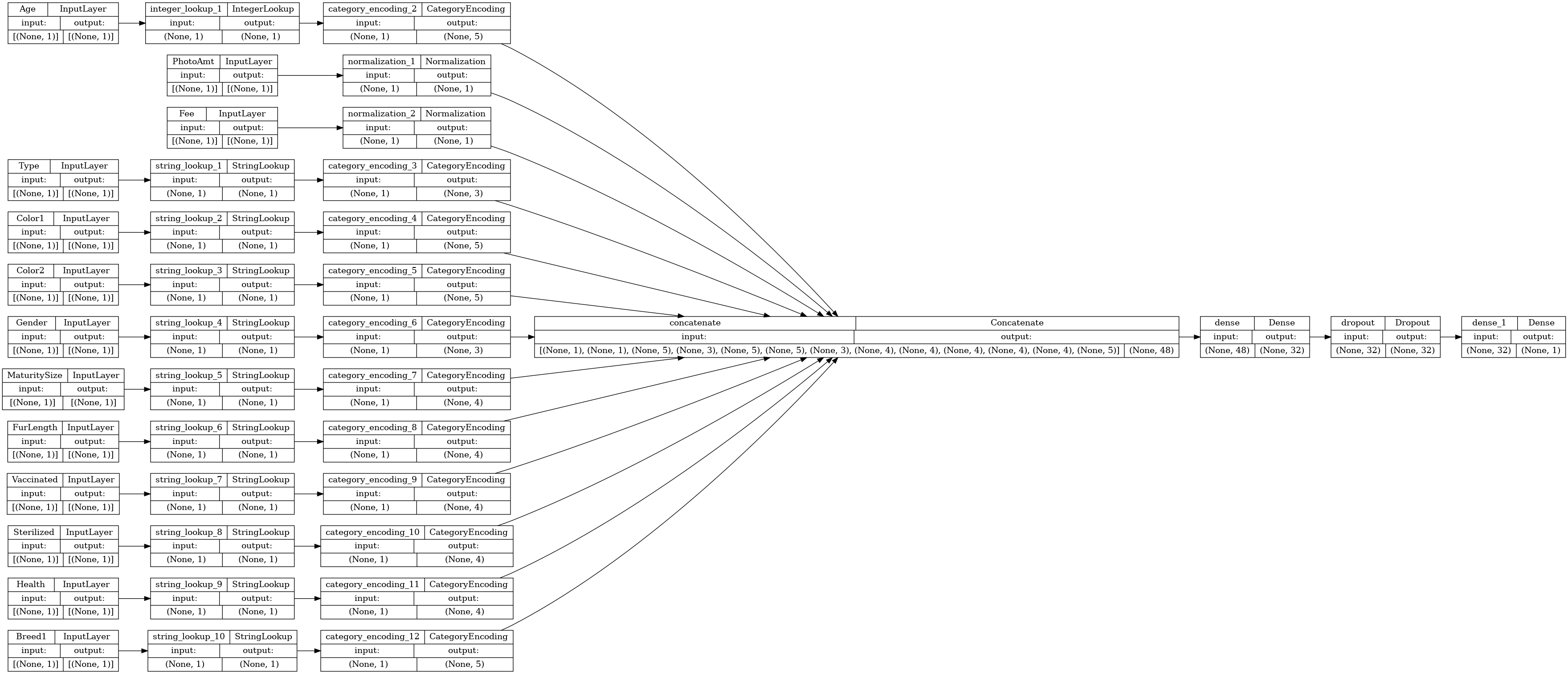
अगला, मॉडल को प्रशिक्षित और परीक्षण करें:
model.fit(train_ds, epochs=10, validation_data=val_ds)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['target'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 37/37 [==============================] - 2s 19ms/step - loss: 0.6524 - accuracy: 0.5034 - val_loss: 0.5887 - val_accuracy: 0.6941 Epoch 2/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5906 - accuracy: 0.6648 - val_loss: 0.5627 - val_accuracy: 0.7218 Epoch 3/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5697 - accuracy: 0.6924 - val_loss: 0.5463 - val_accuracy: 0.7504 Epoch 4/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5558 - accuracy: 0.6978 - val_loss: 0.5346 - val_accuracy: 0.7504 Epoch 5/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5502 - accuracy: 0.7105 - val_loss: 0.5272 - val_accuracy: 0.7487 Epoch 6/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5415 - accuracy: 0.7123 - val_loss: 0.5210 - val_accuracy: 0.7608 Epoch 7/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5354 - accuracy: 0.7171 - val_loss: 0.5152 - val_accuracy: 0.7435 Epoch 8/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5301 - accuracy: 0.7214 - val_loss: 0.5113 - val_accuracy: 0.7513 Epoch 9/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5286 - accuracy: 0.7189 - val_loss: 0.5087 - val_accuracy: 0.7574 Epoch 10/10 37/37 [==============================] - 0s 8ms/step - loss: 0.5252 - accuracy: 0.7260 - val_loss: 0.5058 - val_accuracy: 0.7539 <keras.callbacks.History at 0x7f5f9fa91c50>
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
5/5 [==============================] - 0s 6ms/step - loss: 0.5012 - accuracy: 0.7626 Accuracy 0.762565016746521
अनुमान करें
आपके द्वारा मॉडल के अंदर प्रीप्रोसेसिंग परतों को शामिल करने के बाद आपके द्वारा विकसित किया गया मॉडल अब सीधे CSV फ़ाइल से एक पंक्ति को वर्गीकृत कर सकता है।
अब आप नए डेटा पर अनुमान लगाने से पहले केरस मॉडल को Model.save और Model.load_model के साथ सेव और रीलोड कर सकते हैं:
model.save('my_pet_classifier')
reloaded_model = tf.keras.models.load_model('my_pet_classifier')
2022-01-26 06:20:08.013613: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Function `_wrapped_model` contains input name(s) PhotoAmt, Fee, Age, Type, Color1, Color2, Gender, MaturitySize, FurLength, Vaccinated, Sterilized, Health, Breed1 with unsupported characters which will be renamed to photoamt, fee, age, type, color1, color2, gender, maturitysize, furlength, vaccinated, sterilized, health, breed1 in the SavedModel. INFO:tensorflow:Assets written to: my_pet_classifier/assets INFO:tensorflow:Assets written to: my_pet_classifier/assets
एक नए नमूने के लिए एक भविष्यवाणी प्राप्त करने के लिए, आप बस Model.predict विधि को कॉल कर सकते हैं। आपको केवल दो चीजें करने की ज़रूरत है:
- स्केलर्स को एक सूची में लपेटें ताकि बैच आयाम हो (
Modelकेवल डेटा के बैच को संसाधित करता है, एकल नमूने नहीं)। - प्रत्येक सुविधा पर
tf.convert_to_tensorपर कॉल करें।
sample = {
'Type': 'Cat',
'Age': 3,
'Breed1': 'Tabby',
'Gender': 'Male',
'Color1': 'Black',
'Color2': 'White',
'MaturitySize': 'Small',
'FurLength': 'Short',
'Vaccinated': 'No',
'Sterilized': 'No',
'Health': 'Healthy',
'Fee': 100,
'PhotoAmt': 2,
}
input_dict = {name: tf.convert_to_tensor([value]) for name, value in sample.items()}
predictions = reloaded_model.predict(input_dict)
prob = tf.nn.sigmoid(predictions[0])
print(
"This particular pet had a %.1f percent probability "
"of getting adopted." % (100 * prob)
)
This particular pet had a 77.7 percent probability of getting adopted.
अगले कदम
संरचित डेटा को वर्गीकृत करने के बारे में अधिक जानने के लिए, अन्य डेटासेट के साथ काम करने का प्रयास करें। अपने मॉडलों के प्रशिक्षण और परीक्षण के दौरान सटीकता में सुधार करने के लिए, ध्यान से सोचें कि आपके मॉडल में किन विशेषताओं को शामिल किया जाए और उनका प्रतिनिधित्व कैसे किया जाए।
नीचे डेटासेट के लिए कुछ सुझाव दिए गए हैं:
- TensorFlow डेटासेट: MovieLens : मूवी अनुशंसा सेवा से मूवी रेटिंग का एक सेट।
- TensorFlow डेटासेट: वाइन गुणवत्ता : पुर्तगाली "विन्हो वर्डे" वाइन के लाल और सफेद वेरिएंट से संबंधित दो डेटासेट। आप कागल पर रेड वाइन गुणवत्ता डेटासेट भी पा सकते हैं।
- कागल: arXiv डेटासेट : arXiv से 1.7 मिलियन विद्वानों के लेखों का एक संग्रह, जिसमें भौतिकी, कंप्यूटर विज्ञान, गणित, सांख्यिकी, इलेक्ट्रिकल इंजीनियरिंग, मात्रात्मक जीव विज्ञान और अर्थशास्त्र शामिल हैं।