
| | |  Lihat di GitHub Lihat di GitHub | | |
YAMNet adalah jaringan saraf dalam yang telah dilatih sebelumnya yang dapat memprediksi peristiwa audio dari 521 kelas , seperti tawa, gonggongan, atau sirene.
Dalam tutorial ini Anda akan belajar bagaimana:
- Muat dan gunakan model YAMNet untuk inferensi.
- Buat model baru menggunakan penyematan YAMNet untuk mengklasifikasikan suara kucing dan anjing.
- Evaluasi dan ekspor model Anda.
Impor TensorFlow dan perpustakaan lainnya
Mulailah dengan menginstal TensorFlow I/O , yang akan memudahkan Anda memuat file audio dari disk.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
Tentang YAMNet
YAMNet adalah jaringan saraf pra-terlatih yang menggunakan arsitektur konvolusi yang dapat dipisahkan secara mendalam dari MobileNetV1 . Itu dapat menggunakan bentuk gelombang audio sebagai input dan membuat prediksi independen untuk masing-masing dari 521 peristiwa audio dari korpus AudioSet .
Secara internal, model mengekstrak "bingkai" dari sinyal audio dan memproses kumpulan bingkai ini. Versi model ini menggunakan bingkai yang berdurasi 0,96 detik dan mengekstrak satu bingkai setiap 0,48 detik .
Model menerima array Tensor atau NumPy float32 1-D yang berisi bentuk gelombang dengan panjang yang berubah-ubah, direpresentasikan sebagai sampel saluran tunggal (mono) 16 kHz dalam kisaran [-1.0, +1.0] . Tutorial ini berisi kode untuk membantu Anda mengonversi file WAV ke format yang didukung.
Model mengembalikan 3 output, termasuk skor kelas, embeddings (yang akan Anda gunakan untuk transfer pembelajaran), dan spektogram log mel . Anda dapat menemukan detail lebih lanjut di sini .
Salah satu penggunaan khusus YAMNet adalah sebagai ekstraktor fitur tingkat tinggi - keluaran embedding 1.024 dimensi. Anda akan menggunakan fitur masukan model dasar (YAMNet) dan memasukkannya ke dalam model yang lebih dangkal yang terdiri dari satu lapisan tf.keras.layers.Dense tersembunyi. Kemudian, Anda akan melatih jaringan pada sejumlah kecil data untuk klasifikasi audio tanpa memerlukan banyak data berlabel dan pelatihan ujung ke ujung. (Ini mirip dengan pembelajaran transfer untuk klasifikasi gambar dengan TensorFlow Hub untuk informasi selengkapnya.)
Pertama, Anda akan menguji model dan melihat hasil klasifikasi audio. Anda kemudian akan membangun pipa pra-pemrosesan data.
Memuat YAMNet dari TensorFlow Hub
Anda akan menggunakan YAMNet yang telah dilatih sebelumnya dari Tensorflow Hub untuk mengekstrak embeddings dari file suara.
Memuat model dari TensorFlow Hub sangatlah mudah: pilih model, salin URL-nya, dan gunakan fungsi load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Dengan model yang dimuat, Anda dapat mengikuti tutorial penggunaan dasar YAMNet dan mengunduh file WAV sampel untuk menjalankan inferensi.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Anda akan memerlukan fungsi untuk memuat file audio, yang juga akan digunakan nanti saat bekerja dengan data pelatihan. (Pelajari lebih lanjut tentang membaca file audio dan labelnya di Pengenalan audio sederhana .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Muat pemetaan kelas
Sangat penting untuk memuat nama kelas yang dapat dikenali oleh YAMNet. File pemetaan ada di yamnet_model.class_map_path() dalam format CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
Jalankan inferensi
YAMNet menyediakan skor kelas tingkat bingkai (yaitu, 521 skor untuk setiap bingkai). Untuk menentukan prediksi tingkat klip, skor dapat diagregasikan per kelas di seluruh bingkai (misalnya, menggunakan rata-rata atau agregasi maks). Ini dilakukan di bawah ini oleh scores_np.mean(axis=0) . Terakhir, untuk menemukan kelas dengan skor tertinggi di level klip, Anda mengambil maksimum 521 skor gabungan.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
Kumpulan data ESC-50
Dataset ESC-50 ( Piczak, 2015 ) adalah kumpulan berlabel dari 2.000 rekaman audio lingkungan berdurasi lima detik. Dataset terdiri dari 50 kelas, dengan 40 contoh per kelas.
Unduh kumpulan data dan ekstrak.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Jelajahi datanya
Metadata untuk setiap file ditentukan dalam file csv di ./datasets/ESC-50-master/meta/esc50.csv
dan semua file audio ada di ./datasets/ESC-50-master/audio/
Anda akan membuat pandas DataFrame dengan pemetaan dan menggunakannya untuk memiliki tampilan data yang lebih jelas.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Saring datanya
Sekarang setelah data disimpan di DataFrame , terapkan beberapa transformasi:
- Saring baris dan gunakan hanya kelas yang dipilih -
dogdancat. Jika Anda ingin menggunakan kelas lain, di sinilah Anda dapat memilihnya. - Ubah nama file agar memiliki path lengkap. Ini akan membuat loading lebih mudah nantinya.
- Ubah target menjadi dalam kisaran tertentu. Dalam contoh ini,
dogakan tetap pada0, tetapicatakan menjadi1, bukan nilai aslinya5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Muat file audio dan ambil embeddings
Di sini Anda akan menerapkan load_wav_16k_mono dan menyiapkan data WAV untuk model.
Saat mengekstrak embeddings dari data WAV, Anda mendapatkan array bentuk (N, 1024) di mana N adalah jumlah frame yang ditemukan YAMNet (satu untuk setiap 0,48 detik audio).
Model Anda akan menggunakan setiap frame sebagai satu input. Oleh karena itu, Anda perlu membuat kolom baru yang memiliki satu frame per baris. Anda juga perlu memperluas label dan kolom fold untuk mencerminkan baris baru ini dengan benar.
Kolom fold yang diperluas mempertahankan nilai aslinya. Anda tidak dapat mencampur bingkai karena, saat melakukan pemisahan, Anda mungkin memiliki bagian audio yang sama pada pemisahan yang berbeda, yang akan membuat langkah validasi dan pengujian Anda kurang efektif.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
Pisahkan datanya
Anda akan menggunakan kolom fold untuk membagi dataset menjadi train, validasi, dan test set.
ESC-50 diatur ke dalam lima fold validasi silang berukuran seragam, sehingga klip dari sumber asli yang sama selalu berada di fold yang sama - pelajari lebih lanjut di ESC: Dataset untuk kertas Klasifikasi Suara Lingkungan .
Langkah terakhir adalah menghapus kolom fold dari dataset karena Anda tidak akan menggunakannya selama pelatihan.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Buat model Anda
Anda melakukan sebagian besar pekerjaan! Selanjutnya, tentukan model Sequential yang sangat sederhana dengan satu lapisan tersembunyi dan dua keluaran untuk mengenali kucing dan anjing dari suara.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Mari kita jalankan metode evaluate pada data pengujian hanya untuk memastikan tidak ada overfitting.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
Anda melakukannya!
Uji model Anda
Selanjutnya, coba model Anda pada embedding dari pengujian sebelumnya menggunakan YAMNet saja.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Simpan model yang dapat langsung mengambil file WAV sebagai input
Model Anda berfungsi saat Anda memberikannya embeddings sebagai input.
Dalam skenario dunia nyata, Anda akan ingin menggunakan data audio sebagai input langsung.
Untuk melakukan itu, Anda akan menggabungkan YAMNet dengan model Anda menjadi satu model yang dapat Anda ekspor untuk aplikasi lain.
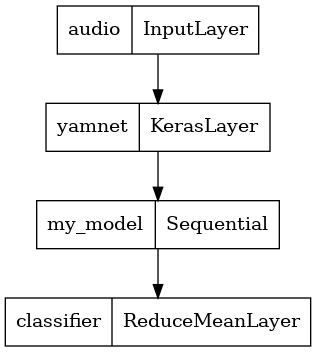
Untuk mempermudah penggunaan hasil model, layer terakhir akan menjadi operasi reduce_mean . Saat menggunakan model ini untuk penyajian (yang akan Anda pelajari nanti di tutorial), Anda memerlukan nama lapisan terakhir. Jika Anda tidak mendefinisikannya, TensorFlow akan otomatis menentukan satu tambahan yang membuatnya sulit untuk diuji, karena akan terus berubah setiap kali Anda melatih model. Saat menggunakan operasi TensorFlow mentah, Anda tidak dapat menetapkan nama untuk operasi tersebut. Untuk mengatasi masalah ini, Anda akan membuat lapisan khusus yang menerapkan reduce_mean dan menyebutnya 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
Muat model yang Anda simpan untuk memverifikasi bahwa itu berfungsi seperti yang diharapkan.
reloaded_model = tf.saved_model.load(saved_model_path)
Dan untuk tes terakhir: diberikan beberapa data suara, apakah model Anda mengembalikan hasil yang benar?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Jika Anda ingin mencoba model baru Anda pada penyiapan penayangan, Anda dapat menggunakan tanda tangan 'serving_default'.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(Opsional) Beberapa pengujian lagi
Modelnya sudah siap.
Mari kita bandingkan dengan YAMNet pada dataset pengujian.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Langkah selanjutnya
Anda telah membuat model yang dapat mengklasifikasikan suara dari anjing atau kucing. Dengan ide yang sama dan kumpulan data yang berbeda, Anda dapat mencoba, misalnya, membuat pengenal akustik burung berdasarkan nyanyiannya.
Bagikan proyek Anda dengan tim TensorFlow di media sosial!