
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini menunjukkan cara memproses file audio dalam format WAV dan membangun serta melatih model pengenalan suara otomatis (ASR) dasar untuk mengenali sepuluh kata yang berbeda. Anda akan menggunakan sebagian dari kumpulan data Perintah Ucapan ( Warden, 2018 ), yang berisi klip audio singkat (satu detik atau kurang) dari perintah, seperti "turun", "pergi", "kiri", "tidak", " kanan", "berhenti", "naik" dan "ya".
Sistem pengenalan suara dan ucapan di dunia nyata sangatlah kompleks. Namun, seperti klasifikasi gambar dengan dataset MNIST , tutorial ini akan memberi Anda pemahaman dasar tentang teknik yang terlibat.
Mempersiapkan
Impor modul dan dependensi yang diperlukan. Perhatikan bahwa Anda akan menggunakan seaborn untuk visualisasi dalam tutorial ini.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
Impor kumpulan data Perintah Pidato mini
Untuk menghemat waktu dengan pemuatan data, Anda akan bekerja dengan versi yang lebih kecil dari kumpulan data Perintah Ucapan. Dataset asli terdiri dari lebih dari 105.000 file audio dalam format file audio WAV (Waveform) dari orang-orang yang mengucapkan 35 kata berbeda. Data ini dikumpulkan oleh Google dan dirilis di bawah lisensi CC BY.
Unduh dan ekstrak file mini_speech_commands.zip yang berisi kumpulan data Perintah Ucapan yang lebih kecil dengan tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
Klip audio set data disimpan dalam delapan folder yang sesuai dengan setiap perintah ucapan: no , yes , down , go , left , up , right , dan stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
Ekstrak klip audio ke dalam daftar bernama filenames , dan acak:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
Pisahkan filenames menjadi set pelatihan, validasi, dan pengujian menggunakan rasio 80:10:10, masing-masing:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
Baca file audio dan labelnya
Di bagian ini Anda akan melakukan praproses dataset, membuat tensor yang didekodekan untuk bentuk gelombang dan label yang sesuai. Perhatikan bahwa:
- Setiap file WAV berisi data deret waktu dengan jumlah sampel yang ditetapkan per detik.
- Setiap sampel mewakili amplitudo sinyal audio pada waktu tertentu.
- Dalam sistem 16-bit , seperti file WAV dalam kumpulan data Perintah Ucapan mini, nilai amplitudo berkisar dari -32,768 hingga 32,767.
- Sample rate untuk dataset ini adalah 16kHz.
Bentuk tensor yang dikembalikan oleh tf.audio.decode_wav adalah [samples, channels] , di mana channels adalah 1 untuk mono atau 2 untuk stereo. Set data Perintah Ucapan mini hanya berisi rekaman mono.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
Sekarang, mari kita definisikan fungsi yang mempraproses file audio WAV mentah dataset menjadi tensor audio:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
Tentukan fungsi yang membuat label menggunakan direktori induk untuk setiap file:
- Pisahkan jalur file menjadi
tf.RaggedTensors (tensor dengan dimensi kasar—dengan irisan yang mungkin memiliki panjang berbeda).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
Tentukan fungsi pembantu get_waveform_and_label —yang menyatukan semuanya:
- Inputnya adalah nama file audio WAV.
- Outputnya adalah tuple yang berisi tensor audio dan label yang siap untuk pembelajaran terawasi.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
Bangun set pelatihan untuk mengekstrak pasangan label audio:
- Buat
tf.data.DatasetdenganDataset.from_tensor_slicesdanDataset.map, menggunakanget_waveform_and_labelditentukan sebelumnya.
Anda akan membuat set validasi dan pengujian menggunakan prosedur serupa nanti.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
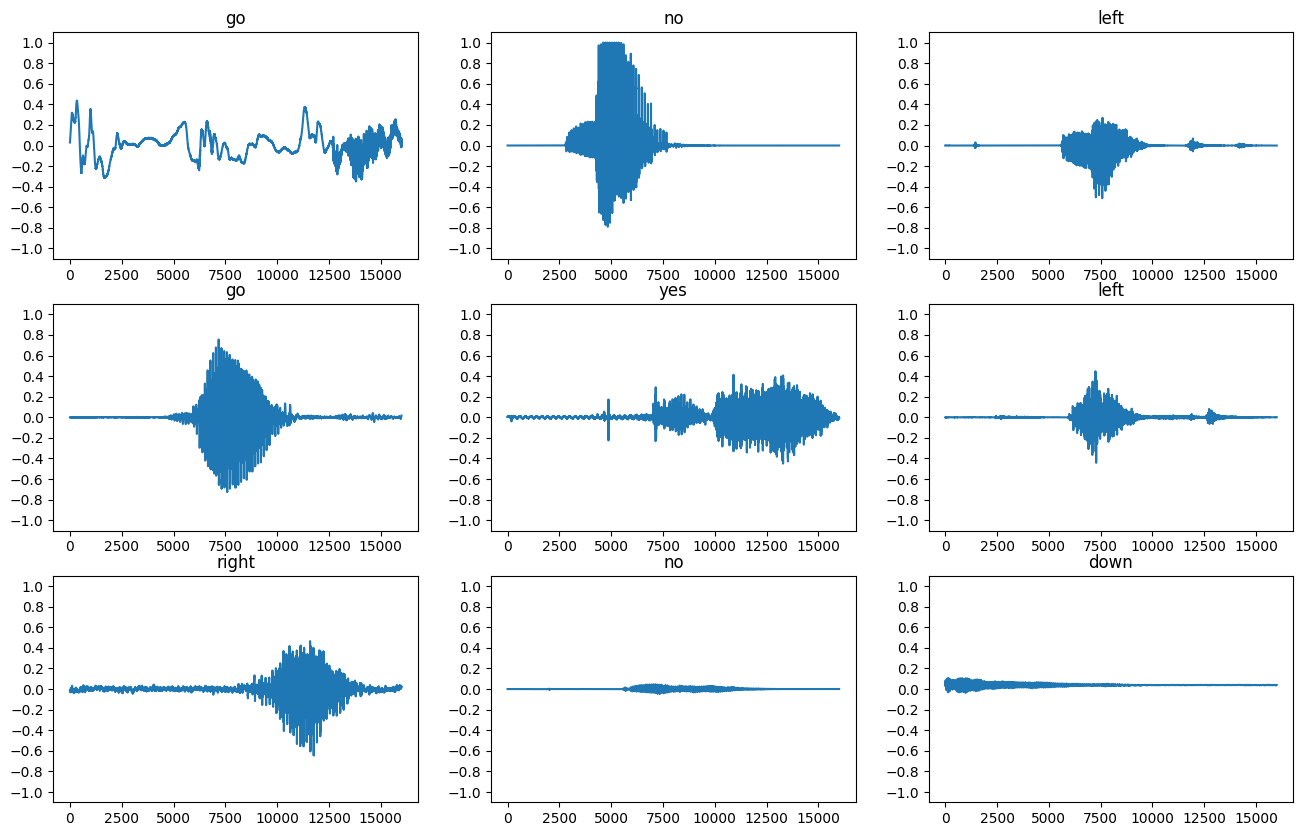
Mari kita plot beberapa bentuk gelombang audio:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
Konversi bentuk gelombang ke spektogram
Bentuk gelombang dalam dataset direpresentasikan dalam domain waktu. Selanjutnya, Anda akan mengubah bentuk gelombang dari sinyal domain waktu menjadi sinyal domain frekuensi waktu dengan menghitung transformasi Fourier waktu singkat (STFT) untuk mengubah bentuk gelombang menjadi sebagai spektogram , yang menunjukkan perubahan frekuensi dari waktu ke waktu dan dapat berupa direpresentasikan sebagai gambar 2D. Anda akan memasukkan gambar spektogram ke jaringan saraf Anda untuk melatih model.
Transformasi Fourier ( tf.signal.fft ) mengubah sinyal ke frekuensi komponennya, tetapi kehilangan semua informasi waktu. Sebagai perbandingan, STFT ( tf.signal.stft ) membagi sinyal menjadi beberapa jendela waktu dan menjalankan transformasi Fourier pada setiap jendela, mempertahankan beberapa informasi waktu, dan mengembalikan tensor 2D tempat Anda dapat menjalankan konvolusi standar.
Buat fungsi utilitas untuk mengubah bentuk gelombang menjadi spektogram:
- Bentuk gelombang harus memiliki panjang yang sama, sehingga ketika Anda mengubahnya menjadi spektogram, hasilnya memiliki dimensi yang serupa. Ini dapat dilakukan hanya dengan membubuhkan nol pada klip audio yang lebih pendek dari satu detik (menggunakan
tf.zeros). - Saat memanggil
tf.signal.stft, pilih parameterframe_lengthdanframe_stepsehingga "gambar" spektogram yang dihasilkan hampir persegi. Untuk informasi lebih lanjut tentang pilihan parameter STFT, lihat video Coursera ini tentang pemrosesan sinyal audio dan STFT. - STFT menghasilkan array bilangan kompleks yang mewakili besaran dan fase. Namun, dalam tutorial ini Anda hanya akan menggunakan besaran, yang dapat Anda peroleh dengan menerapkan
tf.abspada keluarantf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
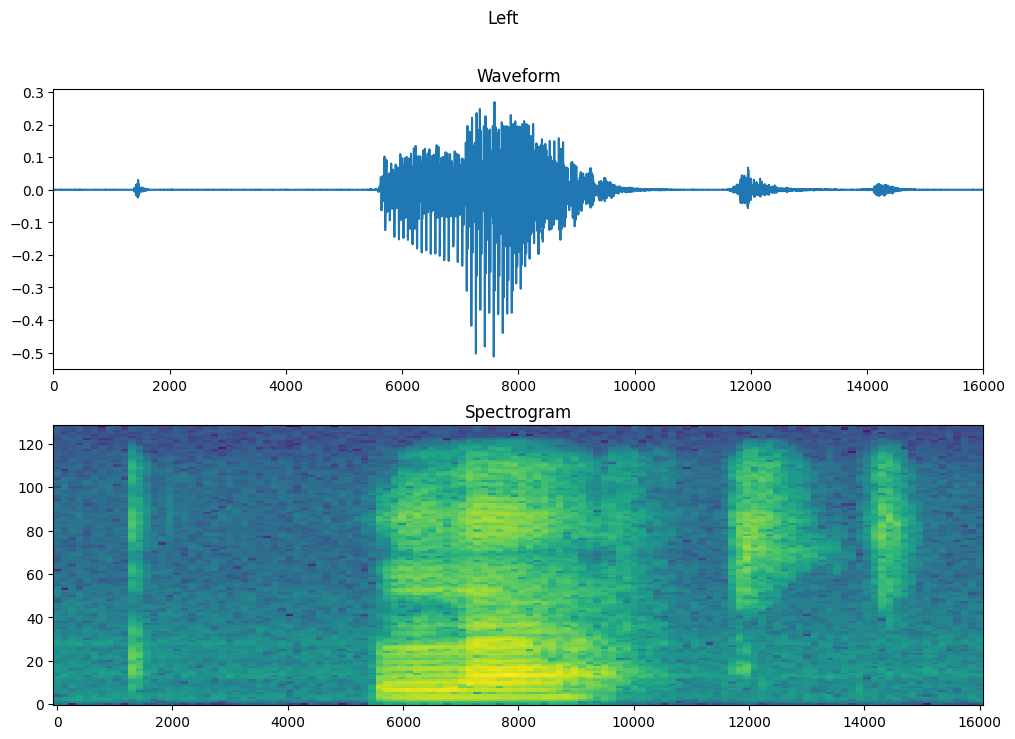
Selanjutnya, mulailah menjelajahi data. Cetak bentuk gelombang tensorisasi satu contoh dan spektogram yang sesuai, dan putar audio aslinya:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
Sekarang, tentukan fungsi untuk menampilkan spektogram:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
Plot contoh bentuk gelombang dari waktu ke waktu dan spektogram yang sesuai (frekuensi dari waktu ke waktu):
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
Sekarang, tentukan fungsi yang mengubah kumpulan data bentuk gelombang menjadi spektogram dan label yang sesuai sebagai ID bilangan bulat:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
Petakan get_spectrogram_and_label_id di seluruh elemen dataset dengan Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
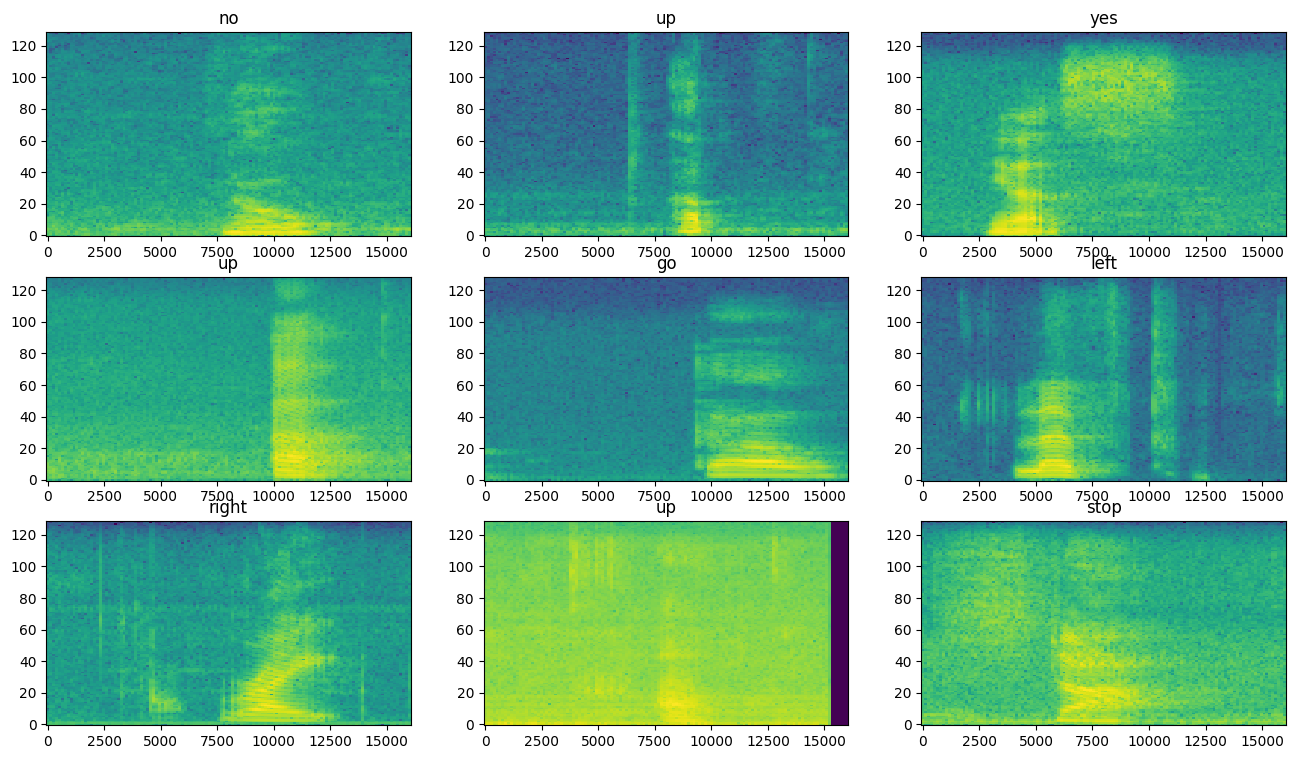
Periksa spektogram untuk contoh yang berbeda dari kumpulan data:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
Bangun dan latih modelnya
Ulangi prapemrosesan set pelatihan pada set validasi dan pengujian:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
Batch set pelatihan dan validasi untuk pelatihan model:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Tambahkan operasi Dataset.cache dan Dataset.prefetch untuk mengurangi latensi baca saat melatih model:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
Untuk modelnya, Anda akan menggunakan jaringan saraf convolutional sederhana (CNN), karena Anda telah mengubah file audio menjadi gambar spektogram.
Model tf.keras.Sequential Anda akan menggunakan lapisan prapemrosesan Keras berikut:
-
tf.keras.layers.Resizing: untuk menurunkan sampel input agar model dapat dilatih lebih cepat. -
tf.keras.layers.Normalization: untuk menormalkan setiap piksel pada gambar berdasarkan mean dan standar deviasinya.
Untuk lapisan Normalization , metode adapt pertama-tama perlu dipanggil pada data pelatihan untuk menghitung statistik agregat (yaitu, rata-rata dan simpangan baku).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Konfigurasikan model Keras dengan pengoptimal Adam dan kehilangan lintas-entropi:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
Latih model lebih dari 10 zaman untuk tujuan demonstrasi:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
Mari kita plot kurva kehilangan pelatihan dan validasi untuk memeriksa bagaimana model Anda telah meningkat selama pelatihan:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

Evaluasi kinerja model
Jalankan model pada set pengujian dan periksa kinerja model:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
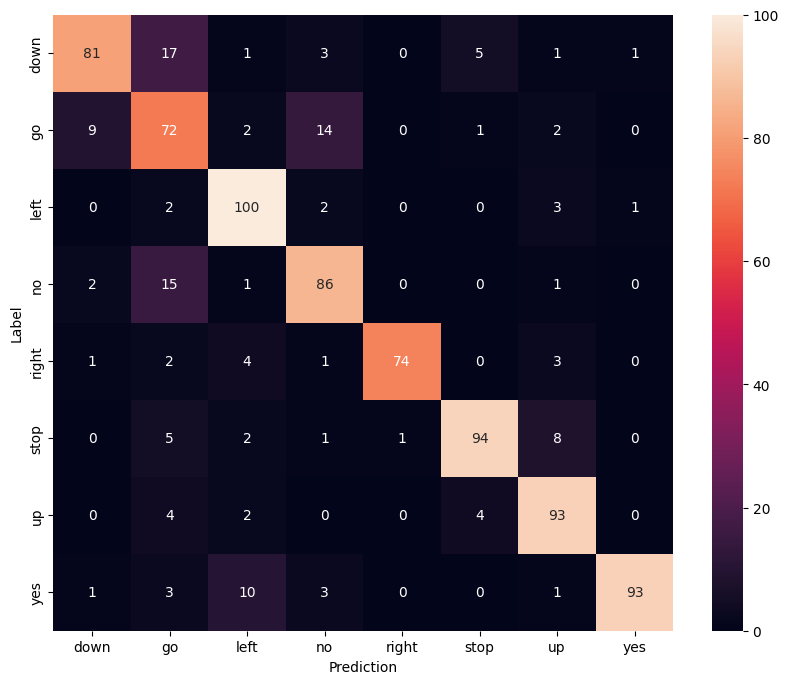
Tampilkan matriks kebingungan
Gunakan matriks konfusi untuk memeriksa seberapa baik model mengklasifikasikan setiap perintah dalam set pengujian:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
Jalankan inferensi pada file audio
Terakhir, verifikasi output prediksi model menggunakan file audio input dari seseorang yang mengatakan "tidak". Seberapa baik performa model Anda?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
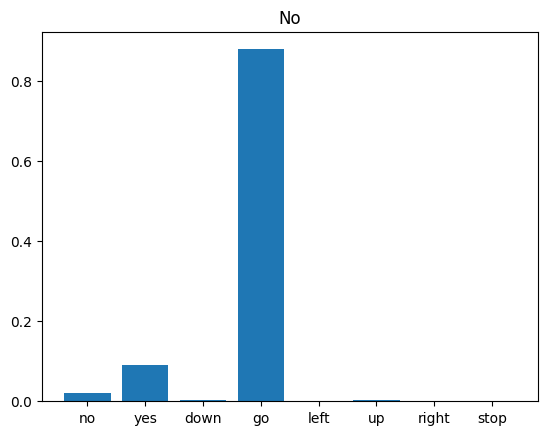
Seperti yang disarankan oleh output, model Anda seharusnya mengenali perintah audio sebagai "tidak".
Langkah selanjutnya
Tutorial ini menunjukkan cara melakukan klasifikasi audio sederhana/pengenalan suara otomatis menggunakan jaringan saraf convolutional dengan TensorFlow dan Python. Untuk mempelajari lebih lanjut, pertimbangkan sumber daya berikut:
- Klasifikasi Suara dengan tutorial YAMNet menunjukkan cara menggunakan pembelajaran transfer untuk klasifikasi audio.
- Buku catatan dari tantangan pengenalan suara TensorFlow Kaggle .
- TensorFlow.js - Pengenalan audio menggunakan codelab pembelajaran transfer mengajarkan cara membuat aplikasi web interaktif Anda sendiri untuk klasifikasi audio.
- Tutorial pembelajaran mendalam untuk pengambilan informasi musik (Choi et al., 2017) di arXiv.
- TensorFlow juga memiliki dukungan tambahan untuk persiapan dan augmentasi data audio untuk membantu proyek berbasis audio Anda sendiri.
- Pertimbangkan untuk menggunakan perpustakaan librosa —paket Python untuk analisis musik dan audio.