
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Ringkasan
tf.distribute.Strategy API menyediakan abstraksi untuk mendistribusikan pelatihan Anda ke beberapa unit pemrosesan. Ini memungkinkan Anda untuk melakukan pelatihan terdistribusi menggunakan model dan kode pelatihan yang ada dengan perubahan minimal.
Tutorial ini menunjukkan cara menggunakan tf.distribute.MirroredStrategy untuk melakukan replikasi dalam grafik dengan pelatihan sinkron pada banyak GPU pada satu mesin . Strategi pada dasarnya menyalin semua variabel model ke setiap prosesor. Kemudian, ia menggunakan all-reduce untuk menggabungkan gradien dari semua prosesor, dan menerapkan nilai gabungan ke semua salinan model.
Anda akan menggunakan API tf.keras untuk membangun model dan Model.fit untuk melatihnya. (Untuk mempelajari tentang pelatihan terdistribusi dengan loop pelatihan khusus dan MirroredStrategy , lihat tutorial ini .)
MirroredStrategy melatih model Anda di beberapa GPU di satu mesin. Untuk pelatihan sinkron pada banyak GPU pada banyak pekerja , gunakan tf.distribute.MultiWorkerMirroredStrategy dengan Keras Model.fit atau loop pelatihan khusus . Untuk opsi lainnya, lihat Panduan pelatihan terdistribusi .
Untuk mempelajari berbagai strategi lainnya, ada panduan Distributed training with TensorFlow .
Mempersiapkan
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
2.8.0-rc1
Unduh kumpulan data
Muat set data MNIST dari TensorFlow Datasets . Ini mengembalikan kumpulan data dalam format tf.data .
Menyetel argumen with_info ke True menyertakan metadata untuk seluruh kumpulan data, yang disimpan di sini ke info . Antara lain, objek metadata ini mencakup jumlah kereta dan contoh uji.
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
Tentukan strategi distribusi
Buat objek MirroredStrategy . Ini akan menangani distribusi dan menyediakan manajer konteks ( MirroredStrategy.scope ) untuk membangun model Anda di dalamnya.
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 1
Siapkan pipa input
Saat melatih model dengan beberapa GPU, Anda dapat menggunakan daya komputasi ekstra secara efektif dengan meningkatkan ukuran batch. Secara umum, gunakan ukuran batch terbesar yang sesuai dengan memori GPU dan sesuaikan kecepatan pembelajarannya.
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
Tentukan fungsi yang menormalkan nilai piksel gambar dari rentang [0, 255] hingga rentang [0, 1] ( penskalaan fitur ):
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
Terapkan fungsi scale ini ke data pelatihan dan pengujian, lalu gunakan API tf.data.Dataset untuk mengacak data pelatihan ( Dataset.shuffle ), dan mengelompokkannya ( Dataset.batch ). Perhatikan bahwa Anda juga menyimpan cache dalam memori dari data pelatihan untuk meningkatkan kinerja ( Dataset.cache ).
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
Buat modelnya
Buat dan kompilasi model Keras dalam konteks Strategy.scope :
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
Tentukan panggilan balik
Tentukan tf.keras.callbacks berikut:
-
tf.keras.callbacks.TensorBoard: menulis log untuk TensorBoard, yang memungkinkan Anda memvisualisasikan grafik. -
tf.keras.callbacks.ModelCheckpoint: menyimpan model pada frekuensi tertentu, seperti setelah setiap epoch. -
tf.keras.callbacks.LearningRateScheduler: menjadwalkan kecepatan belajar untuk berubah setelah, misalnya, setiap Epoch/batch.
Untuk tujuan ilustrasi, tambahkan panggilan balik khusus yang disebut PrintLR untuk menampilkan kecepatan belajar di notebook.
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
Latih dan evaluasi
Sekarang, latih model dengan cara biasa dengan memanggil Model.fit pada model dan meneruskan dataset yang dibuat di awal tutorial. Langkah ini sama apakah Anda mendistribusikan pelatihan atau tidak.
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-01-26 05:38:28.865380: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
933/938 [============================>.] - ETA: 0s - loss: 0.2029 - accuracy: 0.9399
Learning rate for epoch 1 is 0.0010000000474974513
938/938 [==============================] - 10s 4ms/step - loss: 0.2022 - accuracy: 0.9401 - lr: 0.0010
Epoch 2/12
930/938 [============================>.] - ETA: 0s - loss: 0.0654 - accuracy: 0.9813
Learning rate for epoch 2 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0652 - accuracy: 0.9813 - lr: 0.0010
Epoch 3/12
931/938 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9864
Learning rate for epoch 3 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0453 - accuracy: 0.9864 - lr: 0.0010
Epoch 4/12
923/938 [============================>.] - ETA: 0s - loss: 0.0246 - accuracy: 0.9933
Learning rate for epoch 4 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0244 - accuracy: 0.9934 - lr: 1.0000e-04
Epoch 5/12
929/938 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9944
Learning rate for epoch 5 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0212 - accuracy: 0.9944 - lr: 1.0000e-04
Epoch 6/12
930/938 [============================>.] - ETA: 0s - loss: 0.0192 - accuracy: 0.9950
Learning rate for epoch 6 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0194 - accuracy: 0.9950 - lr: 1.0000e-04
Epoch 7/12
927/938 [============================>.] - ETA: 0s - loss: 0.0179 - accuracy: 0.9953
Learning rate for epoch 7 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0179 - accuracy: 0.9953 - lr: 1.0000e-04
Epoch 8/12
938/938 [==============================] - ETA: 0s - loss: 0.0153 - accuracy: 0.9966
Learning rate for epoch 8 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0153 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 9/12
927/938 [============================>.] - ETA: 0s - loss: 0.0151 - accuracy: 0.9966
Learning rate for epoch 9 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0150 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 10/12
935/938 [============================>.] - ETA: 0s - loss: 0.0148 - accuracy: 0.9966
Learning rate for epoch 10 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0148 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 11/12
937/938 [============================>.] - ETA: 0s - loss: 0.0146 - accuracy: 0.9967
Learning rate for epoch 11 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0146 - accuracy: 0.9967 - lr: 1.0000e-05
Epoch 12/12
926/938 [============================>.] - ETA: 0s - loss: 0.0145 - accuracy: 0.9967
Learning rate for epoch 12 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0144 - accuracy: 0.9967 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fad70067c10>
Periksa pos pemeriksaan yang disimpan:
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
Untuk memeriksa seberapa baik kinerja model, muat pos pemeriksaan terbaru dan panggil Model.evaluate pada data pengujian:
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:15.260539: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 2s 4ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval accuracy: 0.9879000186920166
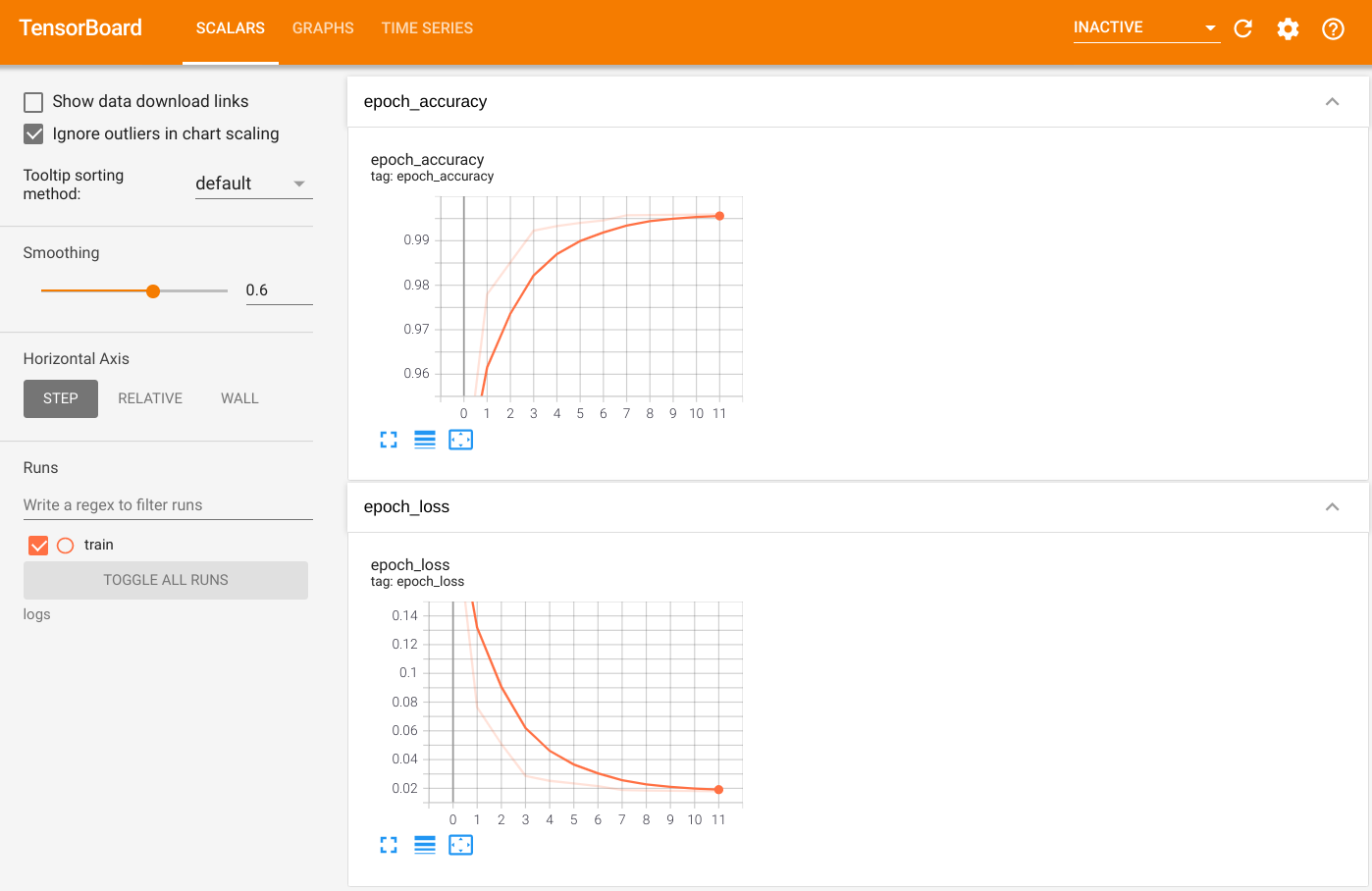
Untuk memvisualisasikan output, luncurkan TensorBoard dan lihat log:
%tensorboard --logdir=logs
ls -sh ./logs
total 4.0K 4.0K train
Ekspor ke Model Tersimpan
Ekspor grafik dan variabel ke format SavedModel platform-agnostik menggunakan Model.save . Setelah model Anda disimpan, Anda dapat memuatnya dengan atau tanpa Strategy.scope .
path = 'saved_model/'
model.save(path, save_format='tf')
2022-01-26 05:39:18.012847: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
Sekarang, muat model tanpa Strategy.scope :
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
157/157 [==============================] - 1s 2ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
Muat model dengan Strategy.scope :
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:19.489971: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 3s 3ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
Sumber daya tambahan
Contoh lainnya yang menggunakan strategi distribusi berbeda dengan Keras Model.fit API:
- Tutorial Memecahkan GLUE menggunakan BERT pada tutorial TPU menggunakan
tf.distribute.MirroredStrategyuntuk pelatihan pada GPU dantf.distribute.TPUStrategy—pada TPU. - Tutorial Simpan dan muat model menggunakan strategi distribusi menunjukkan cara menggunakan API SavedModel dengan
tf.distribute.Strategy. - Model TensorFlow resmi dapat dikonfigurasi untuk menjalankan beberapa strategi distribusi.
Untuk mempelajari lebih lanjut tentang strategi distribusi TensorFlow:
- Pelatihan Kustom dengan tf.distribute.Strategy tutorial menunjukkan cara menggunakan
tf.distribute.MirroredStrategyuntuk pelatihan pekerja tunggal dengan loop pelatihan kustom. - Pelatihan Multi-pekerja dengan tutorial Keras menunjukkan cara menggunakan
MultiWorkerMirroredStrategydenganModel.fit. - Loop pelatihan Kustom dengan Keras dan tutorial MultiWorkerMirroredStrategy menunjukkan cara menggunakan
MultiWorkerMirroredStrategydengan Keras dan loop pelatihan kustom. - Pelatihan Terdistribusi dalam panduan TensorFlow memberikan gambaran umum tentang strategi distribusi yang tersedia.
- Panduan kinerja yang lebih baik dengan tf.function memberikan informasi tentang strategi dan alat lain, seperti TensorFlow Profiler yang dapat Anda gunakan untuk mengoptimalkan kinerja model TensorFlow Anda.