
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מתמקד במשימה של פילוח תמונה, באמצעות U-Net שונה.
מהו פילוח תמונה?
במשימת סיווג תמונה הרשת מקצה תווית (או מחלקה) לכל תמונת קלט. עם זאת, נניח שאתה רוצה לדעת את הצורה של אותו אובייקט, איזה פיקסל שייך לאיזה אובייקט וכו'. במקרה זה תרצה להקצות מחלקה לכל פיקסל של התמונה. משימה זו ידועה בשם פילוח. מודל פילוח מחזיר מידע הרבה יותר מפורט על התמונה. לפילוח תמונה יש יישומים רבים בהדמיה רפואית, במכוניות בנהיגה עצמית ובהדמיית לוויין, אם להזכיר כמה.
מדריך זה משתמש ב- Oxford-IIIT Pet Dataset ( Parkhi et al, 2012 ). מערך הנתונים מורכב מתמונות של 37 גזעי חיות מחמד, עם 200 תמונות לכל גזע (~100 כל אחת בחלוקה לאילוף ולמבחן). כל תמונה כוללת את התוויות המתאימות, ומסיכות לפי פיקסל. המסכות הן תוויות כיתה עבור כל פיקסל. כל פיקסל מקבל אחת משלוש קטגוריות:
- Class 1: פיקסל השייך לחיית המחמד.
- מחלקה 2: פיקסל על גבול חיית המחמד.
- Class 3: אף אחד מהעיל/פיקסל שמסביב.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
הורד את מערך הנתונים של Oxford-IIIT Pets
מערך הנתונים זמין מ- TensorFlow Datasets . מסכות הפילוח כלולות בגרסה 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
בנוסף, ערכי צבע התמונה מנורמלים לטווח [0,1] . לבסוף, כפי שהוזכר לעיל, הפיקסלים במסכת הפילוח מסומנים או {1, 2, 3}. למען הנוחות, יש להחסיר 1 ממסכת הפילוח, וכתוצאה מכך תוויות שהן: {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
מערך הנתונים כבר מכיל את פיצולי ההדרכה והבדיקות הנדרשים, אז המשך להשתמש באותם פיצולים.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
המחלקה הבאה מבצעת הגדלה פשוטה על ידי היפוך אקראי של תמונה. עבור למדריך הגדלת תמונה כדי ללמוד עוד.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
בנה את צינור הקלט, החלת ה-Augmentation לאחר אצווה של התשומות.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
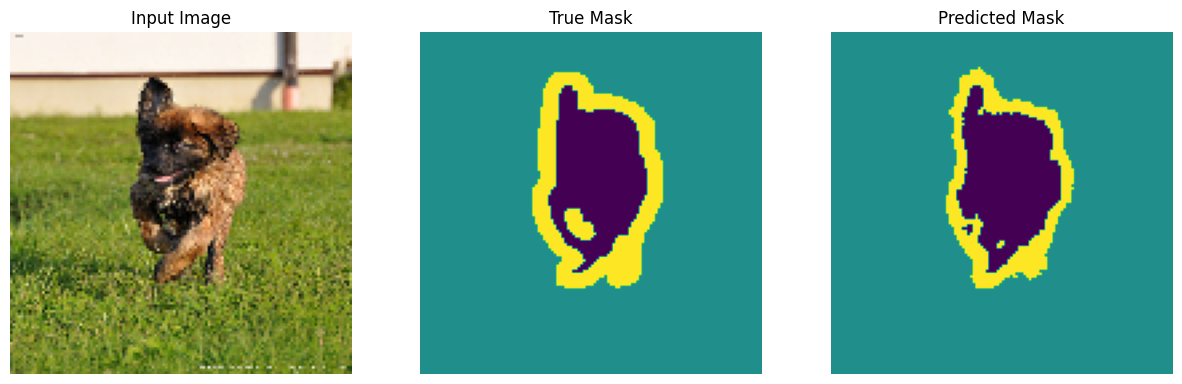
דמיין דוגמה של תמונה ואת המסכה המתאימה לה ממערך הנתונים.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
הגדירו את הדגם
הדגם המשמש כאן הוא U-Net שונה. רשת U-Net מורכבת מקודד (Downsampler) ומפענח (Upsampler). על מנת ללמוד תכונות חזקות ולהפחית את מספר הפרמטרים הניתנים לאימון, תשתמש בדגם מיומן מראש - MobileNetV2 - כמקודד. עבור המפענח, תשתמש בבלוק upsample, שכבר מיושם בדוגמה של pix2pix ב-Repo TensorFlow דוגמאות. (בדוק את pix2pix: תרגום תמונה לתמונה עם מדריך GAN מותנה במחברת.)
כאמור, המקודד יהיה דגם MobileNetV2 מאומן מראש אשר מוכן ומוכן לשימוש ב- tf.keras.applications . המקודד מורכב מתפוקות ספציפיות משכבות ביניים במודל. שימו לב שהמקודד לא יקבל הכשרה במהלך תהליך האימון.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
המפענח/אפסמפלר הוא פשוט סדרה של בלוקים של upsample המיושמים בדוגמאות של TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
שים לב שמספר המסננים בשכבה האחרונה מוגדר למספר output_channels . זה יהיה ערוץ פלט אחד לכל מחלקה.
אימון הדגם
כעת, כל מה שנותר לעשות הוא להרכיב ולהכשיר את המודל.
מכיוון שזו בעיית סיווג מרובה מחלקות, השתמש בפונקציית האובדן tf.keras.losses.CategoricalCrossentropy from_logits מוגדר כ- True , מכיוון שהתוויות הן מספרים שלמים סקלאריים במקום וקטורים של ציונים עבור כל פיקסל של כל מחלקה.
בעת הפעלת הסקה, התווית המוקצית לפיקסל היא הערוץ עם הערך הגבוה ביותר. זה מה שהפונקציה create_mask עושה.
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
עיין במהירות בארכיטקטורת המודל שהתקבלה:
tf.keras.utils.plot_model(model, show_shapes=True)

נסה את המודל כדי לבדוק מה הוא חוזה לפני האימון.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

ההתקשרות חזרה המוגדרת להלן משמשת כדי לראות כיצד המודל משתפר בזמן שהוא מתאמן.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
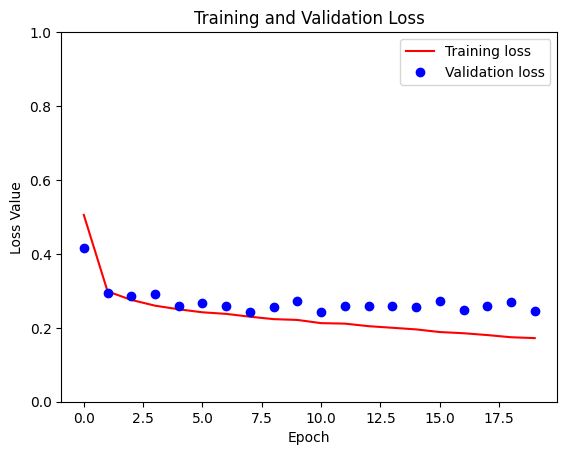
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
לעשות תחזיות
עכשיו, תן כמה תחזיות. למען חיסכון בזמן, מספר העידנים נשמר קטן, אך ניתן להגדיר זאת גבוה יותר כדי להשיג תוצאות מדויקות יותר.
show_predictions(test_batches, 3)


אופציונלי: כיתות לא מאוזנות ומשקולות כיתות
מערכי נתונים של פילוח סמנטי יכולים להיות מאוד לא מאוזנים, כלומר פיקסלים מחלקים מסוימים יכולים להיות נוכחים יותר בתוך תמונות מאשר זו של מחלקות אחרות. מכיוון שניתן להתייחס לבעיות פילוח כבעיות סיווג לפי פיקסל, אתה יכול להתמודד עם בעיית חוסר האיזון על ידי שקלול פונקציית ההפסד כדי לתת את הדעת לכך. זוהי דרך פשוטה ואלגנטית להתמודד עם בעיה זו. עיין במדריך סיווג על נתונים לא מאוזנים למידע נוסף.
כדי למנוע אי בהירות , Model.fit אינו תומך בארגומנט class_weight עבור קלט עם 3+ ממדים.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
אז, במקרה זה אתה צריך ליישם את השקלול בעצמך. תעשה זאת באמצעות משקלים לדוגמה: בנוסף לזוגות (data, label) , Model.fit מקבל גם (data, label, sample_weight) שלשות.
Model.fit מפיץ את sample_weight להפסדים ולמדדים, שמקבלים גם ארגומנט sample_weight . משקל המדגם מוכפל בערך המדגם לפני שלב ההפחתה. לדוגמה:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
אז כדי ליצור משקלים לדוגמה עבור המדריך הזה אתה צריך פונקציה שלוקחת זוג (data, label) נתונים, תווית) ומחזירה טריפל (data, label, sample_weight) . כאשר sample_weight הוא תמונה בעלת ערוץ אחד המכילה את משקל המחלקה עבור כל פיקסל.
היישום הפשוט ביותר האפשרי הוא להשתמש בתווית כאינדקס לרשימת class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
רכיבי הנתונים המתקבלים מכילים 3 תמונות כל אחד:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
עכשיו אתה יכול לאמן מודל על מערך הנתונים המשוקלל הזה:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
הצעדים הבאים
כעת, לאחר שהבנת מהי פילוח תמונה וכיצד זה עובד, אתה יכול לנסות את המדריך הזה עם פלטי שכבת ביניים שונים, או אפילו מודלים שונים שהוכשרו מראש. אתה יכול גם לאתגר את עצמך על ידי ניסיון אתגר מיסוך התמונות של Carvana שמתארח ב-Kaggle.
ייתכן שתרצה גם לראות את ה-API לזיהוי אובייקטים של Tensorflow עבור דגם אחר שתוכל לאמן מחדש על הנתונים שלך. דגמים מאומנים מראש זמינים ב- TensorFlow Hub