
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Dalam masalah regresi , tujuannya adalah untuk memprediksi output dari nilai kontinu, seperti harga atau probabilitas. Bandingkan ini dengan masalah klasifikasi , di mana tujuannya adalah untuk memilih kelas dari daftar kelas (misalnya, di mana gambar berisi apel atau jeruk, mengenali buah mana dalam gambar).
Tutorial ini menggunakan dataset Auto MPG klasik dan mendemonstrasikan cara membuat model untuk memprediksi efisiensi bahan bakar mobil akhir 1970-an dan awal 1980-an. Untuk melakukan ini, Anda akan memberikan model dengan deskripsi banyak mobil dari periode waktu itu. Deskripsi ini mencakup atribut seperti silinder, perpindahan, tenaga kuda, dan berat.
Contoh ini menggunakan Keras API. (Kunjungi tutorial dan panduan Keras untuk mempelajari lebih lanjut.)
# Use seaborn for pairplot.pip install -q seaborn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# Make NumPy printouts easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2.8.0-rc1
Kumpulan data MPG Otomatis
Dataset tersedia dari UCI Machine Learning Repository .
Dapatkan datanya
Pertama-tama unduh dan impor dataset menggunakan pandas:
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
Bersihkan data
Dataset berisi beberapa nilai yang tidak diketahui:
dataset.isna().sum()
MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
Jatuhkan baris-baris itu agar tutorial awal ini tetap sederhana:
dataset = dataset.dropna()
Kolom "Origin" bersifat kategoris, bukan numerik. Jadi langkah selanjutnya adalah melakukan one-hot encode nilai di kolom dengan pd.get_dummies .
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
dataset.tail()
Pisahkan data menjadi set pelatihan dan pengujian
Sekarang, bagi dataset menjadi training set dan test set. Anda akan menggunakan set tes dalam evaluasi akhir model Anda.
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
Periksa datanya
Tinjau distribusi bersama dari beberapa pasang kolom dari set pelatihan.
Baris atas menunjukkan bahwa efisiensi bahan bakar (MPG) adalah fungsi dari semua parameter lainnya. Baris lainnya menunjukkan bahwa mereka adalah fungsi satu sama lain.
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x7f6bfdae9850>
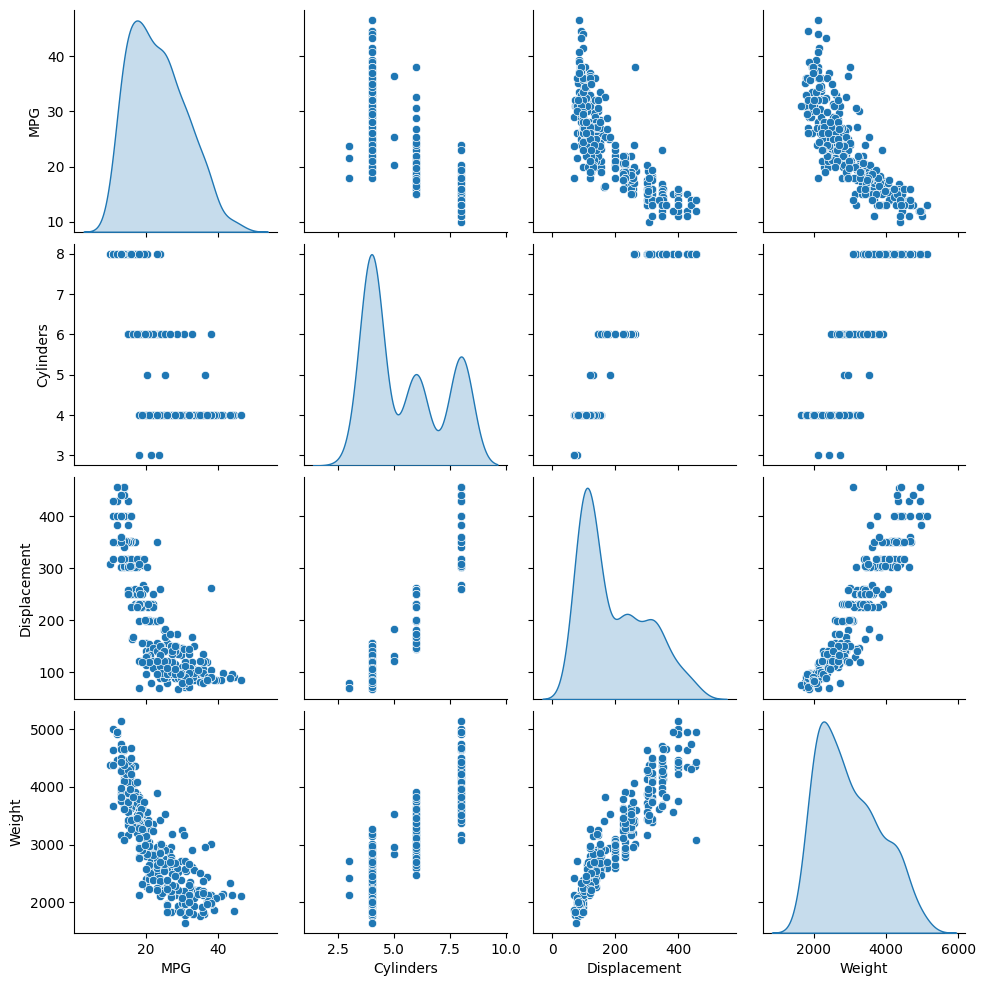
Mari kita juga memeriksa statistik keseluruhan. Perhatikan bagaimana setiap fitur mencakup rentang yang sangat berbeda:
train_dataset.describe().transpose()
Pisahkan fitur dari label
Pisahkan nilai target—"label"—dari fitur. Label ini adalah nilai yang akan Anda latih untuk diprediksi oleh model.
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
Normalisasi
Dalam tabel statistik, mudah untuk melihat betapa berbedanya rentang setiap fitur:
train_dataset.describe().transpose()[['mean', 'std']]
Ini adalah praktik yang baik untuk menormalkan fitur yang menggunakan skala dan rentang yang berbeda.
Salah satu alasan mengapa ini penting adalah karena fitur dikalikan dengan bobot model. Jadi, skala output dan skala gradien dipengaruhi oleh skala input.
Meskipun model mungkin menyatu tanpa normalisasi fitur, normalisasi membuat pelatihan jauh lebih stabil.
Lapisan Normalisasi
tf.keras.layers.Normalization adalah cara yang bersih dan sederhana untuk menambahkan normalisasi fitur ke dalam model Anda.
Langkah pertama adalah membuat lapisan:
normalizer = tf.keras.layers.Normalization(axis=-1)
Kemudian, sesuaikan status lapisan prapemrosesan ke data dengan memanggil Normalization.adapt :
normalizer.adapt(np.array(train_features))
Hitung mean dan varians, dan simpan di layer:
print(normalizer.mean.numpy())
[[ 5.478 195.318 104.869 2990.252 15.559 75.898 0.178 0.197
0.624]]
Saat lapisan dipanggil, ia mengembalikan data input, dengan masing-masing fitur dinormalisasi secara independen:
first = np.array(train_features[:1])
with np.printoptions(precision=2, suppress=True):
print('First example:', first)
print()
print('Normalized:', normalizer(first).numpy())
First example: [[ 4. 90. 75. 2125. 14.5 74. 0. 0. 1. ]] Normalized: [[-0.87 -1.01 -0.79 -1.03 -0.38 -0.52 -0.47 -0.5 0.78]]
Regresi linier
Sebelum membangun model deep neural network, mulailah dengan regresi linier menggunakan satu dan beberapa variabel.
Regresi linier dengan satu variabel
Mulailah dengan regresi linier variabel tunggal untuk memprediksi 'MPG' dari 'Horsepower' .
Melatih model dengan tf.keras biasanya dimulai dengan mendefinisikan arsitektur model. Gunakan model tf.keras.Sequential , yang mewakili urutan langkah .
Ada dua langkah dalam model regresi linier variabel tunggal Anda:
- Normalisasikan fitur input
'Horsepower'menggunakan lapisan prapemrosesantf.keras.layers.Normalization. - Terapkan transformasi linier (\(y = mx+b\)) untuk menghasilkan 1 output menggunakan lapisan linier (
tf.keras.layers.Dense).
Jumlah input dapat diatur oleh argumen input_shape , atau secara otomatis ketika model dijalankan untuk pertama kalinya.
Pertama, buat array NumPy yang terbuat dari fitur 'Horsepower' . Kemudian, tf.keras.layers.Normalization dan sesuaikan statusnya dengan data horsepower :
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = layers.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
Bangun model Keras Sequential:
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense (Dense) (None, 1) 2
=================================================================
Total params: 5
Trainable params: 2
Non-trainable params: 3
_________________________________________________________________
Model ini akan memprediksi 'MPG' dari 'Horsepower' .
Jalankan model yang tidak terlatih pada 10 nilai 'Horsepower' pertama. Outputnya tidak akan bagus, tetapi perhatikan bahwa ia memiliki bentuk yang diharapkan (10, 1) :
horsepower_model.predict(horsepower[:10])
array([[-1.186],
[-0.67 ],
[ 2.189],
[-1.662],
[-1.504],
[-0.59 ],
[-1.782],
[-1.504],
[-0.392],
[-0.67 ]], dtype=float32)
Setelah model dibangun, konfigurasikan prosedur pelatihan menggunakan metode Keras Model.compile . Argumen terpenting untuk dikompilasi adalah loss dan optimizer , karena ini menentukan apa yang akan dioptimalkan ( mean_absolute_error ) dan bagaimana (menggunakan tf.keras.optimizers.Adam ).
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
Gunakan Keras Model.fit untuk menjalankan pelatihan selama 100 epoch:
%%time
history = horsepower_model.fit(
train_features['Horsepower'],
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.79 s, sys: 797 ms, total: 5.59 s Wall time: 3.8 s
Visualisasikan kemajuan pelatihan model menggunakan statistik yang disimpan dalam objek history :
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plot_loss(history)
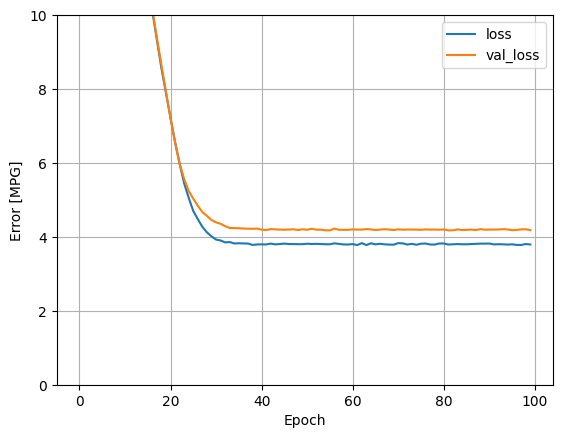
Kumpulkan hasil pada set tes untuk nanti:
test_results = {}
test_results['horsepower_model'] = horsepower_model.evaluate(
test_features['Horsepower'],
test_labels, verbose=0)
Karena ini adalah regresi variabel tunggal, mudah untuk melihat prediksi model sebagai fungsi dari input:
x = tf.linspace(0.0, 250, 251)
y = horsepower_model.predict(x)
def plot_horsepower(x, y):
plt.scatter(train_features['Horsepower'], train_labels, label='Data')
plt.plot(x, y, color='k', label='Predictions')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.legend()
plot_horsepower(x, y)
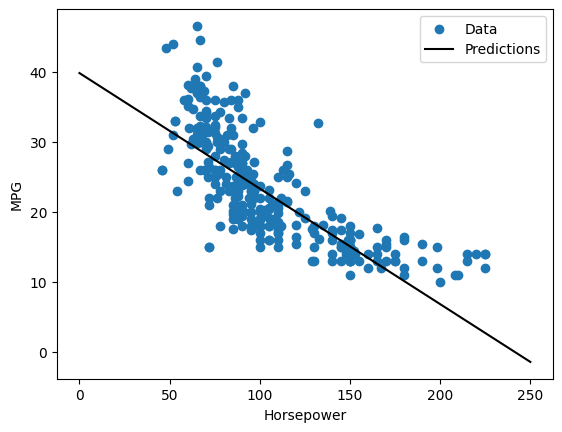
Regresi linier dengan banyak input
Anda dapat menggunakan pengaturan yang hampir sama untuk membuat prediksi berdasarkan beberapa masukan. Model ini masih melakukan \(y = mx+b\) yang sama kecuali bahwa \(m\) adalah matriks dan \(b\) adalah vektor.
Buat model Keras Sequential dua langkah lagi dengan lapisan pertama menjadi normalizer ( tf.keras.layers.Normalization(axis=-1) ) yang Anda tetapkan sebelumnya dan disesuaikan dengan seluruh dataset:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
Saat Anda memanggil Model.predict pada sekumpulan input, itu menghasilkan units=1 output untuk setiap contoh:
linear_model.predict(train_features[:10])
array([[ 0.441],
[ 1.522],
[ 0.188],
[ 1.169],
[ 0.058],
[ 0.965],
[ 0.034],
[-0.674],
[ 0.437],
[-0.37 ]], dtype=float32)
Saat Anda memanggil model, matriks bobotnya akan dibuat—periksa apakah bobot kernel ( \(m\) di \(y=mx+b\)) memiliki bentuk (9, 1) :
linear_model.layers[1].kernel
<tf.Variable 'dense_1/kernel:0' shape=(9, 1) dtype=float32, numpy=
array([[-0.702],
[ 0.307],
[ 0.114],
[ 0.233],
[ 0.244],
[ 0.322],
[-0.725],
[-0.151],
[ 0.407]], dtype=float32)>
Konfigurasikan model dengan Keras Model.compile dan latih dengan Model.fit selama 100 epoch:
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
%%time
history = linear_model.fit(
train_features,
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.89 s, sys: 740 ms, total: 5.63 s Wall time: 3.75 s
Menggunakan semua input dalam model regresi ini menghasilkan kesalahan pelatihan dan validasi yang jauh lebih rendah daripada horsepower_model , yang memiliki satu input:
plot_loss(history)
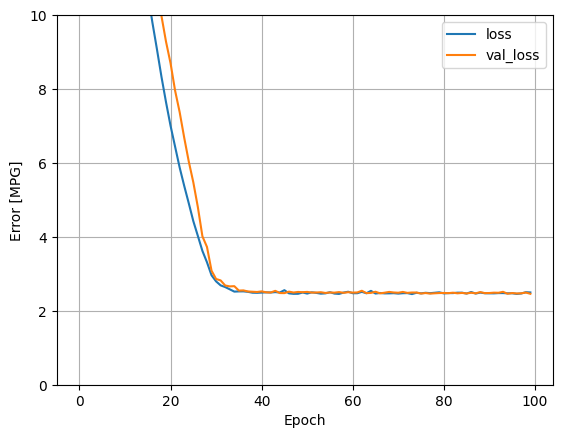
Kumpulkan hasil pada set tes untuk nanti:
test_results['linear_model'] = linear_model.evaluate(
test_features, test_labels, verbose=0)
Regresi dengan jaringan saraf dalam (DNN)
Di bagian sebelumnya, Anda menerapkan dua model linier untuk input tunggal dan banyak.
Di sini, Anda akan menerapkan model DNN dengan input tunggal dan banyak input.
Kode pada dasarnya sama kecuali modelnya diperluas untuk menyertakan beberapa lapisan non-linear "tersembunyi". Nama "tersembunyi" di sini hanya berarti tidak terhubung langsung ke input atau output.
Model-model ini akan berisi beberapa lapisan lebih banyak daripada model linier:
- Lapisan normalisasi, seperti sebelumnya (dengan
horsepower_normalizeruntuk model input tunggal dannormalizeruntuk model input ganda). - Dua lapisan tersembunyi, non-linear,
Densedengan fungsi aktivasi ReLU (relu) nonlinier. - Lapisan keluaran tunggal
Denselinier.
Kedua model akan menggunakan prosedur pelatihan yang sama sehingga metode compile disertakan dalam fungsi build_and_compile_model di bawah ini.
def build_and_compile_model(norm):
model = keras.Sequential([
norm,
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(loss='mean_absolute_error',
optimizer=tf.keras.optimizers.Adam(0.001))
return model
Regresi menggunakan DNN dan satu input
Buat model DNN dengan hanya 'Horsepower' sebagai input dan horsepower_normalizer (didefinisikan sebelumnya) sebagai lapisan normalisasi:
dnn_horsepower_model = build_and_compile_model(horsepower_normalizer)
Model ini memiliki beberapa parameter yang lebih dapat dilatih daripada model linier:
dnn_horsepower_model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense_2 (Dense) (None, 64) 128
dense_3 (Dense) (None, 64) 4160
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 4,356
Trainable params: 4,353
Non-trainable params: 3
_________________________________________________________________
Melatih model dengan Keras Model.fit :
%%time
history = dnn_horsepower_model.fit(
train_features['Horsepower'],
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.07 s, sys: 691 ms, total: 5.76 s Wall time: 3.92 s
Model ini sedikit lebih baik daripada horsepower_model input tunggal linier :
plot_loss(history)
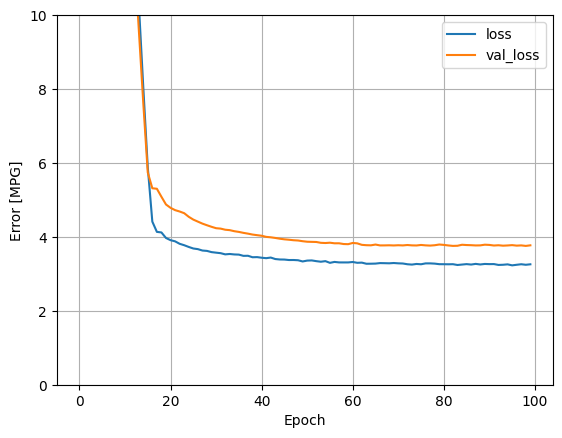
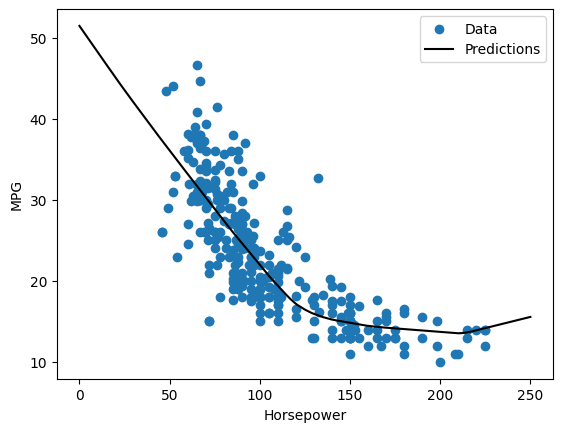
Jika Anda memplot prediksi sebagai fungsi 'Horsepower' , Anda harus memperhatikan bagaimana model ini memanfaatkan nonlinier yang disediakan oleh lapisan tersembunyi:
x = tf.linspace(0.0, 250, 251)
y = dnn_horsepower_model.predict(x)
plot_horsepower(x, y)
Kumpulkan hasil pada set tes untuk nanti:
test_results['dnn_horsepower_model'] = dnn_horsepower_model.evaluate(
test_features['Horsepower'], test_labels,
verbose=0)
Regresi menggunakan DNN dan beberapa input
Ulangi proses sebelumnya menggunakan semua input. Performa model sedikit meningkat pada dataset validasi.
dnn_model = build_and_compile_model(normalizer)
dnn_model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization (Normalizatio (None, 9) 19
n)
dense_5 (Dense) (None, 64) 640
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 4,884
Trainable params: 4,865
Non-trainable params: 19
_________________________________________________________________
%%time
history = dnn_model.fit(
train_features,
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.08 s, sys: 725 ms, total: 5.8 s Wall time: 3.94 s
plot_loss(history)
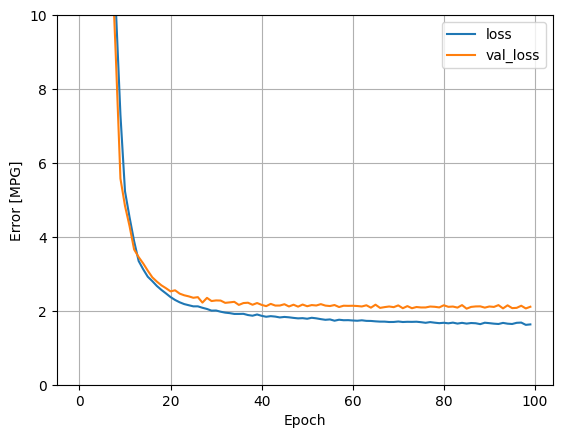
Kumpulkan hasil pada set tes:
test_results['dnn_model'] = dnn_model.evaluate(test_features, test_labels, verbose=0)
Pertunjukan
Karena semua model telah dilatih, Anda dapat meninjau kinerja set pengujiannya:
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
Hasil ini cocok dengan kesalahan validasi yang diamati selama pelatihan.
Membuat prediksi
Anda sekarang dapat membuat prediksi dengan dnn_model pada set pengujian menggunakan Keras Model.predict dan meninjau kerugiannya:
test_predictions = dnn_model.predict(test_features).flatten()
a = plt.axes(aspect='equal')
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
lims = [0, 50]
plt.xlim(lims)
plt.ylim(lims)
_ = plt.plot(lims, lims)

Tampaknya model memprediksi dengan cukup baik.
Sekarang, periksa distribusi kesalahan:
error = test_predictions - test_labels
plt.hist(error, bins=25)
plt.xlabel('Prediction Error [MPG]')
_ = plt.ylabel('Count')
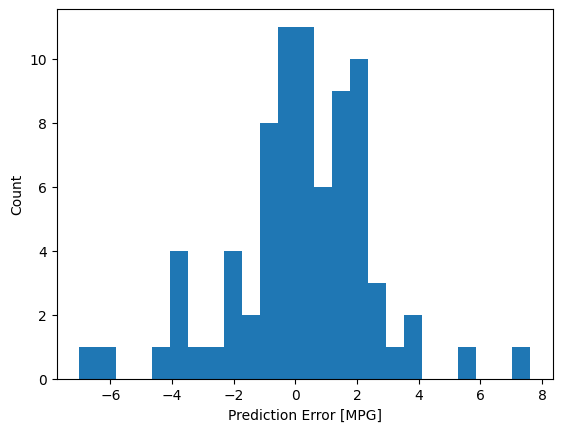
Jika Anda senang dengan modelnya, simpan untuk digunakan nanti dengan Model.save :
dnn_model.save('dnn_model')
2022-01-26 07:26:13.372245: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: dnn_model/assets
Jika Anda memuat ulang model, itu memberikan output yang identik:
reloaded = tf.keras.models.load_model('dnn_model')
test_results['reloaded'] = reloaded.evaluate(
test_features, test_labels, verbose=0)
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
Kesimpulan
Notebook ini memperkenalkan beberapa teknik untuk menangani masalah regresi. Berikut adalah beberapa tips lagi yang dapat membantu:
- Mean squared error (MSE) (
tf.losses.MeanSquaredError) dan mean absolute error (MAE) (tf.losses.MeanAbsoluteError) adalah fungsi kerugian yang umum digunakan untuk masalah regresi. MAE kurang sensitif terhadap outlier. Fungsi kerugian yang berbeda digunakan untuk masalah klasifikasi. - Demikian pula, metrik evaluasi yang digunakan untuk regresi berbeda dari klasifikasi.
- Ketika fitur data input numerik memiliki nilai dengan rentang yang berbeda, setiap fitur harus diskalakan secara independen ke rentang yang sama.
- Overfitting adalah masalah umum untuk model DNN, meskipun itu bukan masalah untuk tutorial ini. Kunjungi tutorial Overfit dan underfit untuk bantuan lebih lanjut dengan ini.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.