
| | |  در GitHub مشاهده کنید در GitHub مشاهده کنید | | |
YAMNet یک شبکه عصبی عمیق از پیش آموزش دیده است که می تواند رویدادهای صوتی را از 521 کلاس ، مانند خنده، پارس کردن، یا آژیر پیش بینی کند.
در این آموزش شما یاد خواهید گرفت که چگونه:
- مدل YAMNet را برای استنتاج بارگذاری و استفاده کنید.
- یک مدل جدید با استفاده از تعبیههای YAMNet برای طبقهبندی صداهای سگ و گربه بسازید.
- مدل خود را ارزیابی و صادر کنید.
TensorFlow و کتابخانه های دیگر را وارد کنید
با نصب TensorFlow I/O شروع کنید، که بارگذاری فایل های صوتی را از روی دیسک برای شما آسان تر می کند.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
درباره YAMNet
YAMNet یک شبکه عصبی از پیش آموزش دیده است که از معماری کانولوشن قابل جداسازی در عمق MobileNetV1 استفاده می کند. می تواند از شکل موج صوتی به عنوان ورودی استفاده کند و برای هر یک از 521 رویداد صوتی از مجموعه AudioSet پیش بینی های مستقل انجام دهد.
در داخل، مدل «فریمها» را از سیگنال صوتی استخراج میکند و دستههایی از این فریمها را پردازش میکند. این نسخه از مدل از فریم هایی با طول 0.96 ثانیه استفاده می کند و هر 0.48 ثانیه یک فریم را استخراج می کند.
مدل یک آرایه 1-D float32 Tensor یا NumPy را می پذیرد که حاوی شکل موجی با طول دلخواه است که به صورت نمونه های تک کانالی (مونو) 16 کیلوهرتز در محدوده [-1.0, +1.0] نمایش داده می شود. این آموزش حاوی کدهایی است که به شما کمک می کند فایل های WAV را به فرمت پشتیبانی شده تبدیل کنید.
این مدل 3 خروجی شامل امتیازات کلاس، جاسازیها (که برای یادگیری انتقال استفاده خواهید کرد) و طیفنگار log mel را برمیگرداند. شما می توانید جزئیات بیشتر را در اینجا بیابید.
یکی از کاربردهای خاص YAMNet به عنوان یک استخراج کننده ویژگی های سطح بالا است - خروجی تعبیه 1024 بعدی. شما از ویژگی های ورودی مدل پایه (YAMNet) استفاده کرده و آنها را به مدل کم عمق تر خود متشکل از یک لایه پنهان tf.keras.layers.Dense می کنید. سپس، شبکه را بر روی مقدار کمی داده برای طبقه بندی صدا بدون نیاز به داده های برچسب دار زیاد و آموزش سرتاسر آموزش می دهید. (این شبیه به انتقال یادگیری برای طبقه بندی تصاویر با TensorFlow Hub برای اطلاعات بیشتر است.)
ابتدا مدل را تست کرده و نتایج طبقه بندی صدا را مشاهده خواهید کرد. سپس خط لوله پیش پردازش داده را می سازید.
در حال بارگیری YAMNet از TensorFlow Hub
شما می خواهید از یک YAMNet از پیش آموزش دیده از Tensorflow Hub برای استخراج جاسازی ها از فایل های صوتی استفاده کنید.
بارگیری یک مدل از TensorFlow Hub ساده است: مدل را انتخاب کنید، URL آن را کپی کنید و از تابع load استفاده کنید.
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
با بارگذاری مدل، میتوانید آموزش استفاده اولیه YAMNet را دنبال کنید و یک نمونه فایل WAV را برای اجرای استنتاج دانلود کنید.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
برای بارگذاری فایل های صوتی به یک تابع نیاز دارید که بعداً هنگام کار با داده های آموزشی نیز از آن استفاده می شود. (درباره خواندن فایلهای صوتی و برچسبهای آنها در تشخیص ساده صوتی بیشتر بیاموزید.
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

نقشه کلاس را بارگیری کنید
بارگیری نام کلاس هایی که YAMNet قادر به تشخیص آن است، مهم است. فایل نگاشت در yamnet_model.class_map_path() با فرمت CSV موجود است.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
استنتاج را اجرا کنید
YAMNet امتیازهای کلاس در سطح فریم را ارائه می دهد (یعنی 521 امتیاز برای هر فریم). به منظور تعیین پیشبینیهای سطح کلیپ، نمرات را میتوان در هر کلاس در فریمها جمع کرد (مثلاً با استفاده از میانگین یا حداکثر تجمع). این کار در زیر توسط scores_np.mean(axis=0) انجام می شود. در نهایت، برای پیدا کردن کلاس با امتیاز بالا در سطح کلیپ، حداکثر 521 امتیاز جمعآوری شده را میگیرید.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
مجموعه داده ESC-50
مجموعه داده ESC-50 ( Piczak، 2015 ) مجموعه ای برچسب دار از 2000 ضبط صوتی محیطی پنج ثانیه ای است. مجموعه داده شامل 50 کلاس با 40 نمونه در هر کلاس است.
مجموعه داده را دانلود و استخراج کنید.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
داده ها را کاوش کنید
ابرداده برای هر فایل در فایل csv در ./datasets/ESC-50-master/meta/esc50.csv مشخص شده است.
و تمامی فایل های صوتی در ./datasets/ESC-50-master/audio/
شما با نقشه برداری یک DataFrame پاندا ایجاد می کنید و از آن برای داشتن دید واضح تری از داده ها استفاده می کنید.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
داده ها را فیلتر کنید
اکنون که داده ها در DataFrame ذخیره می شوند، برخی از تبدیل ها را اعمال کنید:
- ردیف ها را فیلتر کنید و فقط از کلاس های انتخاب شده استفاده کنید -
dogوcat. اگر می خواهید از هر کلاس دیگری استفاده کنید، اینجاست که می توانید آنها را انتخاب کنید. - نام فایل را اصلاح کنید تا مسیر کامل داشته باشد. این کار بارگذاری را بعدا آسان تر می کند.
- اهداف را تغییر دهید تا در محدوده خاصی قرار گیرند. در این مثال،
dogدر0باقی می ماند، اماcatبه جای مقدار اصلی خود5،1می شود.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
فایل های صوتی را بارگیری کنید و موارد تعبیه شده را بازیابی کنید
در اینجا شما load_wav_16k_mono را اعمال میکنید و دادههای WAV را برای مدل آماده میکنید.
هنگام استخراج جاسازیها از دادههای WAV، آرایهای از شکل (N, 1024) دریافت میکنید که N تعداد فریمهایی است که YAMNet پیدا کرده است (یک فریم برای هر 0.48 ثانیه صدا).
مدل شما از هر فریم به عنوان یک ورودی استفاده می کند. بنابراین، باید یک ستون جدید ایجاد کنید که دارای یک فریم در هر سطر باشد. همچنین باید برچسب ها و ستون fold را گسترش دهید تا به درستی این ردیف های جدید را منعکس کنند.
ستون fold گسترش یافته مقادیر اصلی را حفظ می کند. نمیتوانید فریمها را با هم ترکیب کنید، زیرا هنگام انجام تقسیمها، ممکن است در نهایت بخشهایی از یک صدا را در تقسیمهای مختلف داشته باشید، که باعث میشود اعتبارسنجی و مراحل تست شما مؤثرتر نباشد.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
داده ها را تقسیم کنید
شما از ستون fold برای تقسیم مجموعه داده ها به مجموعه های قطار، اعتبار سنجی و آزمایش استفاده خواهید کرد.
ESC-50 در پنج تای اعتبار fold با اندازه یکنواخت مرتب شده است، به طوری که کلیپ های یک منبع اصلی همیشه در یک تا هستند - در مقاله ESC: fold for Environmental Sound Classification بیشتر بدانید.
آخرین مرحله حذف ستون fold از مجموعه داده است زیرا قرار نیست در طول آموزش از آن استفاده کنید.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
مدل خود را ایجاد کنید
شما بیشتر کار را انجام دادید! بعد، یک مدل Sequential بسیار ساده با یک لایه پنهان و دو خروجی برای تشخیص گربه ها و سگ ها از صداها تعریف کنید.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
بیایید روش evaluate را روی داده های آزمایش اجرا کنیم تا مطمئن شویم که بیش از حد برازش وجود ندارد.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
توانجامش دادی!
مدل خود را تست کنید
در مرحله بعد، مدل خود را روی جاسازی آزمایش قبلی فقط با استفاده از YAMNet امتحان کنید.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
مدلی را ذخیره کنید که بتواند مستقیماً یک فایل WAV را به عنوان ورودی بگیرد
مدل شما زمانی کار می کند که به آن جاسازی ها را به عنوان ورودی بدهید.
در یک سناریوی واقعی، شما می خواهید از داده های صوتی به عنوان ورودی مستقیم استفاده کنید.
برای انجام این کار، YAMNet را با مدل خود در یک مدل ترکیب میکنید که میتوانید برای برنامههای کاربردی دیگر صادر کنید.
برای سهولت استفاده از نتیجه مدل، لایه نهایی یک عملیات reduce_mean خواهد بود. هنگام استفاده از این مدل برای سرو (که در ادامه آموزش با آن آشنا خواهید شد) به نام لایه نهایی نیاز خواهید داشت. اگر یکی را تعریف نکنید، TensorFlow به صورت خودکار یک افزایشی را تعریف میکند که آزمایش آن را سخت میکند، زیرا هر بار که مدل را آموزش میدهید تغییر میکند. هنگام استفاده از یک عملیات خام TensorFlow، نمی توانید نامی به آن اختصاص دهید. برای رسیدگی به این مشکل، یک لایه سفارشی ایجاد میکنید که reduce_mean را اعمال میکند و آن را 'classifier' طبقهبند» مینامید.
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
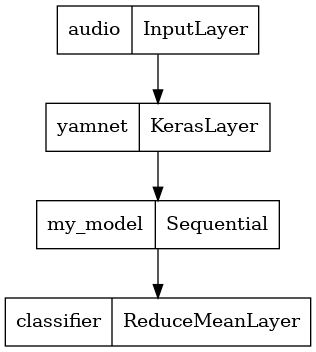
مدل ذخیره شده خود را بارگیری کنید تا بررسی کنید که مطابق انتظار کار می کند.
reloaded_model = tf.saved_model.load(saved_model_path)
و برای تست نهایی: با توجه به برخی داده های صوتی، آیا مدل شما نتیجه صحیح را برمی گرداند؟
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
اگر میخواهید مدل جدید خود را در تنظیمات سرویس امتحان کنید، میتوانید از امضای «serving_default» استفاده کنید.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(اختیاری) چند آزمایش دیگر
مدل آماده است.
بیایید آن را با YAMNet در مجموعه داده آزمایشی مقایسه کنیم.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
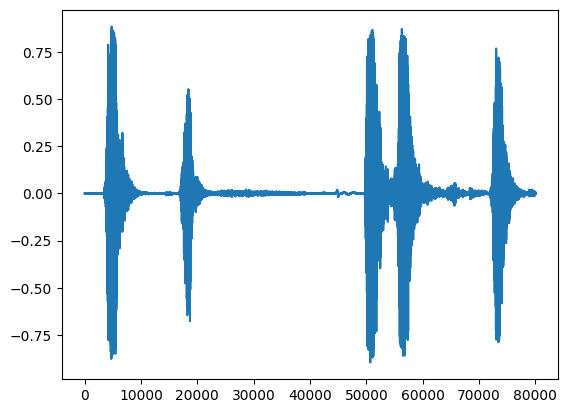
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
مراحل بعدی
شما مدلی ایجاد کرده اید که می تواند صداهای سگ یا گربه را طبقه بندی کند. با همین ایده و مجموعه داده های متفاوت می توانید سعی کنید، برای مثال، یک شناسه صوتی پرندگان را بر اساس آواز آنها بسازید.
پروژه خود را با تیم TensorFlow در رسانه های اجتماعی به اشتراک بگذارید!