
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
tf.distribute.Strategy API انتزاعی برای توزیع آموزش شما در واحدهای پردازشی متعدد ارائه می دهد. این امکان را به شما می دهد تا آموزش های توزیع شده را با استفاده از مدل های موجود و کد آموزشی با حداقل تغییرات انجام دهید.
این آموزش نحوه استفاده از tf.distribute.MirroredStrategy را برای انجام تکثیر گراف با آموزش همزمان بر روی بسیاری از GPUها در یک ماشین نشان می دهد. این استراتژی اساساً تمام متغیرهای مدل را در هر پردازنده کپی می کند. سپس، از all-reduce برای ترکیب گرادیانهای همه پردازندهها استفاده میکند و مقدار ترکیبی را برای همه کپیهای مدل اعمال میکند.
شما از APIهای tf.keras برای ساختن مدل و از Model.fit برای آموزش آن استفاده خواهید کرد. (برای آشنایی با آموزش توزیع شده با یک حلقه آموزشی سفارشی و MirroredStrategy ، این آموزش را بررسی کنید.)
MirroredStrategy مدل شما را روی چندین پردازنده گرافیکی در یک دستگاه آموزش می دهد. برای آموزش همزمان در بسیاری از GPUها روی چندین کارگر ، از tf.distribute.MultiWorkerMirroredStrategy با Keras Model.fit یا یک حلقه آموزشی سفارشی استفاده کنید. برای سایر گزینه ها، به راهنمای آموزشی توزیع شده مراجعه کنید.
برای آشنایی با استراتژی های مختلف دیگر، آموزش توزیع شده با راهنمای تنسورفلو وجود دارد.
برپایی
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
2.8.0-rc1
مجموعه داده را دانلود کنید
مجموعه داده MNIST را از TensorFlow Datasets بارگیری کنید. این یک مجموعه داده را در قالب tf.data برمی گرداند.
تنظیم آرگومان with_info روی True شامل ابرداده کل مجموعه داده است که در اینجا در info ذخیره می شود. از جمله موارد دیگر، این شی فوق داده شامل تعداد نمونه های قطار و آزمایش می شود.
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
استراتژی توزیع را تعریف کنید
یک شی MirroredStrategy ایجاد کنید. این کار توزیع را انجام می دهد و یک مدیر زمینه ( MirroredStrategy.scope ) برای ساخت مدل شما در داخل ارائه می دهد.
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 1
خط لوله ورودی را تنظیم کنید
هنگام آموزش یک مدل با چندین پردازنده گرافیکی، می توانید با افزایش اندازه دسته ای، از قدرت محاسباتی اضافی به طور موثر استفاده کنید. به طور کلی، از بزرگترین اندازه دسته ای که متناسب با حافظه GPU است استفاده کنید و نرخ یادگیری را بر اساس آن تنظیم کنید.
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
تابعی را تعریف کنید که مقادیر پیکسل تصویر را از محدوده [0, 255] به محدوده [0, 1] نرمال میکند ( مقیاسسازی ویژگی ):
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
این تابع scale را روی دادههای آموزشی و آزمایشی اعمال کنید، و سپس از APIهای tf.data.Dataset برای مخلوط کردن دادههای آموزشی ( Dataset.shuffle ) و دستهبندی آنها ( Dataset.batch ) استفاده کنید. توجه داشته باشید که برای بهبود عملکرد، یک کش در حافظه از داده های آموزشی نگهداری می کنید ( Dataset.cache ).
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
مدل را ایجاد کنید
مدل Keras را در چارچوب Strategy.scope ایجاد و کامپایل کنید:
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
تماس های برگشتی را تعریف کنید
tf.keras.callbacks زیر را تعریف کنید:
-
tf.keras.callbacks.TensorBoard: یک گزارش برای TensorBoard می نویسد که به شما امکان می دهد نمودارها را تجسم کنید. -
tf.keras.callbacks.ModelCheckpoint: مدل را در یک فرکانس خاص ذخیره می کند، مانند بعد از هر دوره. -
tf.keras.callbacks.LearningRateScheduler: نرخ یادگیری را برای تغییر، برای مثال، پس از هر دوره/بچ، زمانبندی میکند.
برای اهداف توضیحی، یک تماس سفارشی به نام PrintLR اضافه کنید تا نرخ یادگیری را در نوت بوک نمایش دهد.
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
آموزش دهید و ارزیابی کنید
حال با فراخوانی Model.fit روی مدل و عبور از مجموعه داده ایجاد شده در ابتدای آموزش، مدل را به روش معمول آموزش دهید. این مرحله چه در حال توزیع آموزش باشید چه نباشید یکسان است.
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-01-26 05:38:28.865380: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
933/938 [============================>.] - ETA: 0s - loss: 0.2029 - accuracy: 0.9399
Learning rate for epoch 1 is 0.0010000000474974513
938/938 [==============================] - 10s 4ms/step - loss: 0.2022 - accuracy: 0.9401 - lr: 0.0010
Epoch 2/12
930/938 [============================>.] - ETA: 0s - loss: 0.0654 - accuracy: 0.9813
Learning rate for epoch 2 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0652 - accuracy: 0.9813 - lr: 0.0010
Epoch 3/12
931/938 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9864
Learning rate for epoch 3 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0453 - accuracy: 0.9864 - lr: 0.0010
Epoch 4/12
923/938 [============================>.] - ETA: 0s - loss: 0.0246 - accuracy: 0.9933
Learning rate for epoch 4 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0244 - accuracy: 0.9934 - lr: 1.0000e-04
Epoch 5/12
929/938 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9944
Learning rate for epoch 5 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0212 - accuracy: 0.9944 - lr: 1.0000e-04
Epoch 6/12
930/938 [============================>.] - ETA: 0s - loss: 0.0192 - accuracy: 0.9950
Learning rate for epoch 6 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0194 - accuracy: 0.9950 - lr: 1.0000e-04
Epoch 7/12
927/938 [============================>.] - ETA: 0s - loss: 0.0179 - accuracy: 0.9953
Learning rate for epoch 7 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0179 - accuracy: 0.9953 - lr: 1.0000e-04
Epoch 8/12
938/938 [==============================] - ETA: 0s - loss: 0.0153 - accuracy: 0.9966
Learning rate for epoch 8 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0153 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 9/12
927/938 [============================>.] - ETA: 0s - loss: 0.0151 - accuracy: 0.9966
Learning rate for epoch 9 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0150 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 10/12
935/938 [============================>.] - ETA: 0s - loss: 0.0148 - accuracy: 0.9966
Learning rate for epoch 10 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0148 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 11/12
937/938 [============================>.] - ETA: 0s - loss: 0.0146 - accuracy: 0.9967
Learning rate for epoch 11 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0146 - accuracy: 0.9967 - lr: 1.0000e-05
Epoch 12/12
926/938 [============================>.] - ETA: 0s - loss: 0.0145 - accuracy: 0.9967
Learning rate for epoch 12 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0144 - accuracy: 0.9967 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fad70067c10>
بررسی پست های بازرسی ذخیره شده:
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
برای بررسی عملکرد مدل، آخرین چک پوینت را بارگیری کنید و Model.evaluate را روی داده های آزمایشی فراخوانی کنید:
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:15.260539: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 2s 4ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval accuracy: 0.9879000186920166
برای تجسم خروجی، TensorBoard را اجرا کنید و گزارشها را مشاهده کنید:
%tensorboard --logdir=logs
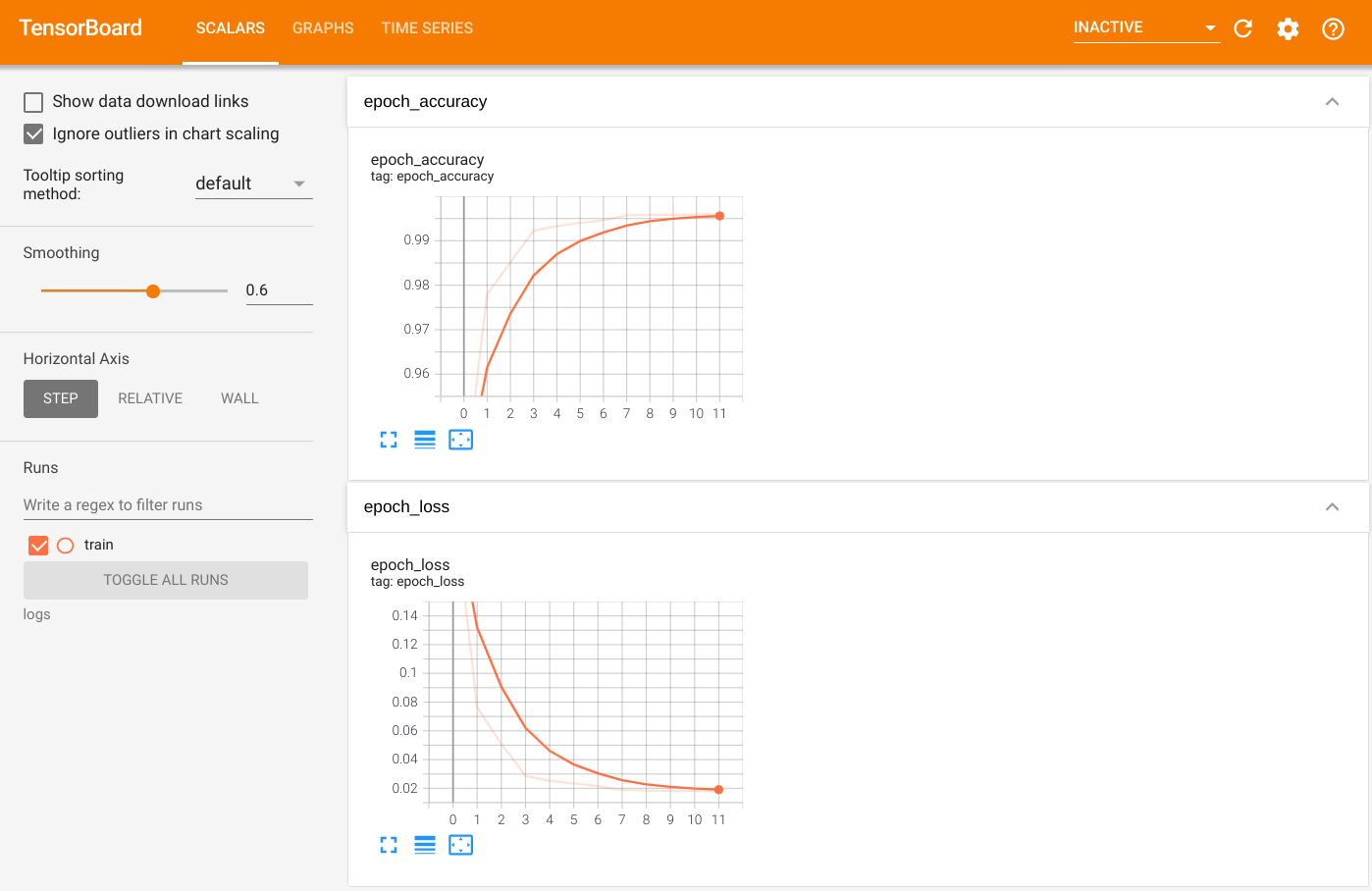
ls -sh ./logs
total 4.0K 4.0K train
صادرات به SavedModel
نمودار و متغیرها را با استفاده از Model.save به قالب پلتفرم-agnostic Model.save کنید. بعد از اینکه مدل شما ذخیره شد، می توانید آن را با یا بدون Strategy.scope بارگیری کنید.
path = 'saved_model/'
model.save(path, save_format='tf')
2022-01-26 05:39:18.012847: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
اکنون مدل را بدون Strategy.scope بارگیری کنید:
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
157/157 [==============================] - 1s 2ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
مدل را با Strategy.scope بارگیری کنید:
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:19.489971: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 3s 3ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
منابع اضافی
مثالهای بیشتری که از استراتژیهای توزیع مختلف با Keras Model.fit API استفاده میکنند:
- در آموزش حل وظایف GLUE با استفاده از BERT در TPU از
tf.distribute.MirroredStrategyبرای آموزش GPU وtf.distribute.TPUStrategyTPU استفاده می شود. - ذخیره و بارگذاری یک مدل با استفاده از آموزش استراتژی توزیع، نحوه استفاده از API های SavedModel را با
tf.distribute.Strategyنشان می دهد. - مدلهای رسمی TensorFlow را میتوان برای اجرای چندین استراتژی توزیع پیکربندی کرد.
برای کسب اطلاعات بیشتر در مورد استراتژی های توزیع TensorFlow:
- آموزش سفارشی با tf.distribute.Strategy نحوه استفاده از
tf.distribute.MirroredStrategyرا برای آموزش تک کارگری با یک حلقه آموزشی سفارشی نشان می دهد. - آموزش Multi-worker با Keras نحوه استفاده از
MultiWorkerMirroredStrategyباModel.fitرا نشان می دهد. - حلقه آموزشی Custom with Keras و MultiWorkerMirroredStrategy آموزش نحوه استفاده از
MultiWorkerMirroredStrategyبا Keras و یک حلقه آموزشی سفارشی را نشان می دهد. - راهنمای آموزشی Distributed in TensorFlow یک نمای کلی از استراتژی های توزیع موجود را ارائه می دهد.
- راهنمای عملکرد بهتر با tf.function اطلاعاتی درباره استراتژیها و ابزارهای دیگر، مانند TensorFlow Profiler که میتوانید برای بهینهسازی عملکرد مدلهای TensorFlow خود استفاده کنید، ارائه میدهد.