
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทช่วยสอนนี้สาธิตวิธีสร้างรูปภาพของตัวเลขที่เขียนด้วยลายมือโดยใช้ Deep Convolutional Generative Adversarial Network (DCGAN) โค้ดนี้เขียนโดยใช้ Keras Sequential API พร้อมลูปการฝึก tf.GradientTape
GAN คืออะไร?
Generative Adversarial Networks (GAN) เป็นหนึ่งในแนวคิดที่น่าสนใจที่สุดในวิทยาการคอมพิวเตอร์ในปัจจุบัน สองโมเดลได้รับการฝึกฝนพร้อมกันโดยกระบวนการที่เป็นปฏิปักษ์ ผู้ สร้าง ("ศิลปิน") เรียนรู้ที่จะสร้างภาพที่ดูเหมือนจริง ในขณะที่ผู้ แยกแยะ ("นักวิจารณ์ศิลปะ") เรียนรู้ที่จะแยกแยะภาพจริงออกจากของปลอม
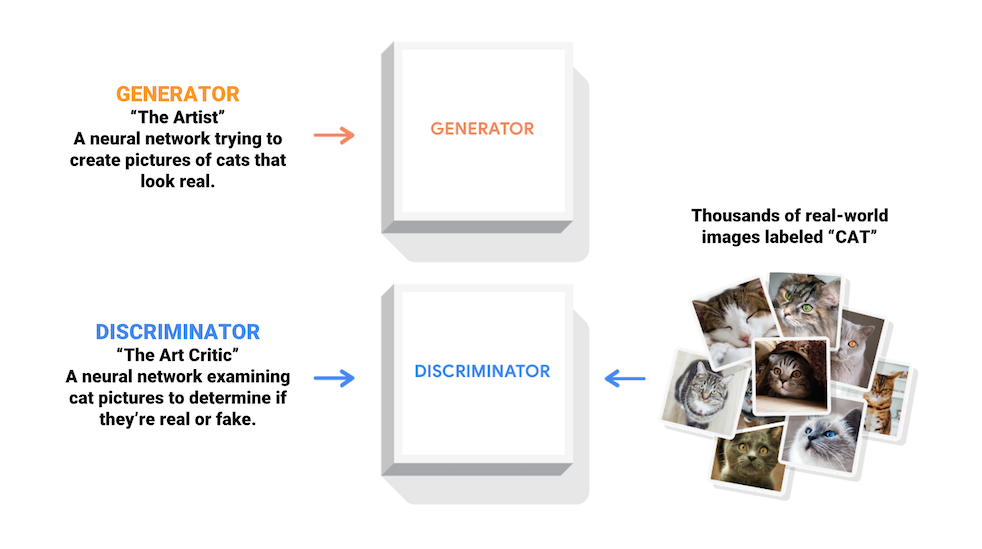
ในระหว่างการฝึก ตัว สร้าง จะค่อยๆ สร้างภาพที่ดูเหมือนจริงได้ดีขึ้น ในขณะที่ผู้ แยกแยะ จะแยกแยะได้ดีขึ้น กระบวนการมาถึงสมดุลเมื่อผู้ เลือกปฏิบัติ ไม่สามารถแยกแยะภาพจริงออกจากของปลอมได้อีกต่อไป
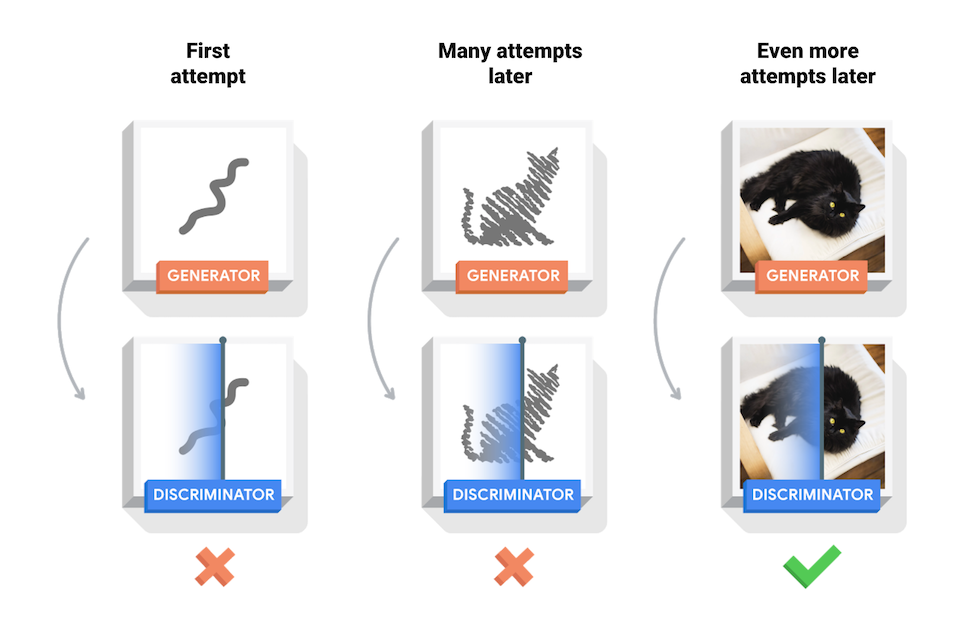
สมุดบันทึกนี้สาธิตกระบวนการนี้ในชุดข้อมูล MNIST แอนิเมชั่นต่อไปนี้แสดงชุดของภาพที่ผลิตโดย เครื่องกำเนิดไฟฟ้า ในขณะที่ได้รับการฝึกฝนมาเป็นเวลา 50 ยุค ภาพเริ่มด้วยสัญญาณรบกวนแบบสุ่ม และมีลักษณะคล้ายกับตัวเลขที่เขียนด้วยลายมือมากขึ้นเรื่อยๆ เมื่อเวลาผ่านไป

หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ GAN โปรดดูหลักสูตร Intro to Deep Learning ของ MIT
ติดตั้ง
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
โหลดและเตรียมชุดข้อมูล
คุณจะใช้ชุดข้อมูล MNIST เพื่อฝึกตัวสร้างและตัวแบ่งแยก เครื่องกำเนิดจะสร้างตัวเลขที่เขียนด้วยลายมือคล้ายกับข้อมูล MNIST
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
สร้างแบบจำลอง
ทั้งตัวสร้างและตัวแบ่งแยกถูกกำหนดโดยใช้ Keras Sequential API
เครื่องกำเนิด
เครื่องกำเนิดไฟฟ้าใช้ tf.keras.layers.Conv2DTranspose (อัพแซมปลิง) เพื่อสร้างภาพจากเมล็ด (สัญญาณรบกวนแบบสุ่ม) เริ่มต้นด้วยเลเยอร์ Dense ที่ใช้เมล็ดพันธุ์นี้เป็นอินพุต จากนั้นสุ่มตัวอย่างหลาย ๆ ครั้งจนกว่าคุณจะได้ขนาดภาพที่ต้องการ 28x28x1 สังเกตการเปิดใช้งาน tf.keras.layers.LeakyReLU สำหรับแต่ละเลเยอร์ ยกเว้นเลเยอร์เอาต์พุตที่ใช้ tanh
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
ใช้ตัวสร้าง (ที่ยังไม่ได้รับการฝึกฝน) เพื่อสร้างภาพ
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>

ผู้เลือกปฏิบัติ
discriminator เป็นตัวแยกประเภทรูปภาพที่ใช้ CNN
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
ใช้ตัวแบ่งแยก (ที่ยังไม่ได้รับการฝึกฝน) เพื่อจำแนกรูปภาพที่สร้างขึ้นว่าจริงหรือของปลอม โมเดลจะได้รับการฝึกให้แสดงค่าบวกสำหรับรูปภาพจริง และค่าลบสำหรับรูปภาพปลอม
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
กำหนดการสูญเสียและเครื่องมือเพิ่มประสิทธิภาพ
กำหนดฟังก์ชันการสูญเสียและตัวเพิ่มประสิทธิภาพสำหรับทั้งสองรุ่น
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
การสูญเสียผู้เลือกปฏิบัติ
วิธีนี้จะวัดว่าผู้เลือกปฏิบัติสามารถแยกแยะภาพจริงออกจากของปลอมได้ดีเพียงใด มันเปรียบเทียบการคาดคะเนของ discriminator กับภาพจริงกับอาร์เรย์ของ 1s และการคาดคะเนของ discriminator เกี่ยวกับภาพปลอม (ที่สร้างขึ้น) กับอาร์เรย์ของ 0s
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
การสูญเสียเครื่องกำเนิดไฟฟ้า
การสูญเสียของเครื่องกำเนิดไฟฟ้าเป็นตัววัดว่าสามารถหลอกลวงผู้เลือกปฏิบัติได้ดีเพียงใด ตามสัญชาตญาณแล้ว หากเครื่องกำเนิดไฟฟ้าทำงานได้ดี ผู้เลือกปฏิบัติจะจัดประเภทภาพปลอมเป็นภาพจริง (หรือ 1) ที่นี่ เปรียบเทียบการตัดสินใจเลือกปฏิบัติของรูปภาพที่สร้างขึ้นกับอาร์เรย์ 1 วินาที
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
เครื่องมือเลือกปฏิบัติและเครื่องมือเพิ่มประสิทธิภาพเครื่องกำเนิดไฟฟ้านั้นแตกต่างกัน เนื่องจากคุณจะฝึกสองเครือข่ายแยกกัน
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
บันทึกจุดตรวจ
โน้ตบุ๊กนี้ยังสาธิตวิธีการบันทึกและกู้คืนโมเดล ซึ่งอาจเป็นประโยชน์ในกรณีที่งานการฝึกที่ใช้เวลานานถูกขัดจังหวะ
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
กำหนดวงจรการฝึก
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
วงการฝึกเริ่มต้นด้วยตัวสร้างที่ได้รับเมล็ดสุ่มเป็นอินพุต เมล็ดนั้นใช้สร้างภาพ จากนั้นจึงใช้ discriminator เพื่อจำแนกภาพจริง (ดึงมาจากชุดฝึก) และภาพปลอม (ผลิตโดยเครื่องกำเนิดไฟฟ้า) การสูญเสียจะถูกคำนวณสำหรับแต่ละรุ่นเหล่านี้ และการไล่ระดับสีจะใช้ในการอัปเดตตัวสร้างและตัวจำแนกประเภท
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
สร้างและบันทึกภาพ
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
ฝึกโมเดล
เรียกเมธอด train() ที่กำหนดไว้ด้านบนเพื่อฝึกเครื่องกำเนิดไฟฟ้าและตัวจำแนกประเภทพร้อมกัน หมายเหตุ การฝึก GAN อาจเป็นเรื่องยาก สิ่งสำคัญคือตัวสร้างและตัวแบ่งแยกต้องไม่เอาชนะซึ่งกันและกัน (เช่น ฝึกในอัตราที่ใกล้เคียงกัน)
ในช่วงเริ่มต้นของการฝึก ภาพที่สร้างขึ้นจะดูเหมือนสัญญาณรบกวนแบบสุ่ม ขณะที่การฝึกอบรมดำเนินไป ตัวเลขที่สร้างขึ้นจะดูสมจริงมากขึ้น หลังจากผ่านไปประมาณ 50 ยุค จะคล้ายกับตัวเลข MNIST การดำเนินการนี้อาจใช้เวลาประมาณ 1 นาที/ยุค โดยใช้การตั้งค่าเริ่มต้นใน Colab
train(train_dataset, EPOCHS)

คืนค่าด่านล่าสุด
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
สร้าง GIF
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

ใช้ imageio เพื่อสร้าง gif แบบเคลื่อนไหวโดยใช้ภาพที่บันทึกไว้ระหว่างการฝึก
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

ขั้นตอนถัดไป
บทช่วยสอนนี้แสดงโค้ดทั้งหมดที่จำเป็นในการเขียนและฝึก GAN ในขั้นตอนต่อไป คุณอาจต้องการทดลองกับชุดข้อมูลอื่น เช่น ชุดข้อมูล Large-scale Celeb Faces Attributes (CelebA) ที่มีอยู่ใน Kaggle หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ GAN โปรดดูบทช่วย สอน NIPS 2016: Generative Adversarial Networks