
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
คู่มือนี้จะฝึกโมเดลโครงข่ายประสาทเทียมเพื่อจำแนกรูปภาพเสื้อผ้า เช่น รองเท้าผ้าใบและเสื้อเชิ้ต ไม่เป็นไรหากคุณไม่เข้าใจรายละเอียดทั้งหมด นี่คือภาพรวมอย่างรวดเร็วของโปรแกรม TensorFlow ที่สมบูรณ์พร้อมรายละเอียดที่อธิบายตามที่คุณดำเนินการ
คู่มือนี้ใช้ tf.keras ซึ่งเป็น API ระดับสูงเพื่อสร้างและฝึกโมเดลใน TensorFlow
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0-rc1
นำเข้าชุดข้อมูล Fashion MNIST
คู่มือนี้ใช้ชุดข้อมูล Fashion MNIST ซึ่งมีรูปภาพระดับสีเทา 70,000 ภาพใน 10 หมวดหมู่ รูปภาพแสดงบทความเกี่ยวกับเสื้อผ้าแต่ละชิ้นที่มีความละเอียดต่ำ (28 x 28 พิกเซล) ดังที่แสดงไว้ที่นี่:
| รูปที่ 1 ตัวอย่าง Fashion-MNIST (โดย Zalando, MIT License) |
Fashion MNIST มีจุดมุ่งหมายเพื่อแทนที่ชุดข้อมูล MNIST แบบคลาสสิก ซึ่งมักใช้เป็น "สวัสดี โลก" ของโปรแกรมการเรียนรู้ของเครื่องสำหรับคอมพิวเตอร์วิทัศน์ ชุดข้อมูล MNIST มีรูปภาพของตัวเลขที่เขียนด้วยลายมือ (0, 1, 2 ฯลฯ) ในรูปแบบที่เหมือนกับของบทความเกี่ยวกับเสื้อผ้าที่คุณจะใช้ที่นี่
คู่มือนี้ใช้ Fashion MNIST สำหรับความหลากหลาย และเนื่องจากเป็นปัญหาที่ท้าทายมากกว่า MNIST ปกติเล็กน้อย ชุดข้อมูลทั้งสองมีขนาดค่อนข้างเล็กและใช้เพื่อตรวจสอบว่าอัลกอริธึมทำงานตามที่คาดไว้ เป็นจุดเริ่มต้นที่ดีในการทดสอบและแก้ไขข้อบกพร่องของโค้ด
ที่นี่ 60,000 ภาพถูกใช้เพื่อฝึกเครือข่ายและ 10,000 ภาพเพื่อประเมินว่าเครือข่ายเรียนรู้การจำแนกภาพได้อย่างแม่นยำเพียงใด คุณสามารถเข้าถึง Fashion MNIST ได้โดยตรงจาก TensorFlow นำเข้าและ โหลดข้อมูล Fashion MNIST โดยตรงจาก TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
การโหลดชุดข้อมูลจะส่งคืนอาร์เรย์ NumPy สี่ชุด:
- อาร์เรย์
train_imagesและtrain_labelsเป็น ชุดการฝึก ซึ่งเป็นข้อมูลที่โมเดลใช้ในการเรียนรู้ - โมเดลได้รับการทดสอบกับ ชุดการทดสอบ ,
test_imagesและอาร์เรย์test_labels
รูปภาพเป็นอาร์เรย์ NumPy ขนาด 28x28 โดยมีค่าพิกเซลตั้งแต่ 0 ถึง 255 ป้ายกำกับ คืออาร์เรย์ของจำนวนเต็มตั้งแต่ 0 ถึง 9 สิ่งเหล่านี้สอดคล้องกับ คลาส ของเสื้อผ้าที่รูปภาพแสดง:
| ฉลาก | ระดับ |
|---|---|
| 0 | เสื้อยืด/ท็อป |
| 1 | กางเกง |
| 2 | เสื้อสวมหัว |
| 3 | ชุด |
| 4 | เสื้อโค้ท |
| 5 | รองเท้าแตะ |
| 6 | เสื้อ |
| 7 | รองเท้าผ้าใบ |
| 8 | กระเป๋า |
| 9 | รองเท้าบูทหุ้มข้อ |
แต่ละภาพจะจับคู่กับป้ายกำกับเดียว เนื่องจาก ชื่อคลาส ไม่รวมอยู่ในชุดข้อมูล ให้เก็บไว้ที่นี่เพื่อใช้ในภายหลังเมื่อลงจุดภาพ:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
สำรวจข้อมูล
มาสำรวจรูปแบบของชุดข้อมูลก่อนฝึกโมเดลกัน ต่อไปนี้แสดงให้เห็นว่ามี 60,000 ภาพในชุดการฝึก โดยแต่ละภาพจะแสดงเป็น 28 x 28 พิกเซล:
train_images.shape
(60000, 28, 28)
ในทำนองเดียวกัน มีป้ายกำกับ 60,000 รายการในชุดการฝึก:
len(train_labels)
60000
แต่ละเลเบลเป็นจำนวนเต็มระหว่าง 0 ถึง 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
มี 10,000 ภาพในชุดทดสอบ อีกครั้ง แต่ละภาพจะแสดงเป็น 28 x 28 พิกเซล:
test_images.shape
(10000, 28, 28)
และชุดทดสอบประกอบด้วยป้ายกำกับรูปภาพ 10,000 รายการ:
len(test_labels)
10000
ประมวลผลข้อมูลล่วงหน้า
ข้อมูลต้องได้รับการประมวลผลล่วงหน้าก่อนการฝึกเครือข่าย หากคุณตรวจสอบภาพแรกในชุดการฝึก คุณจะเห็นว่าค่าพิกเซลอยู่ในช่วง 0 ถึง 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
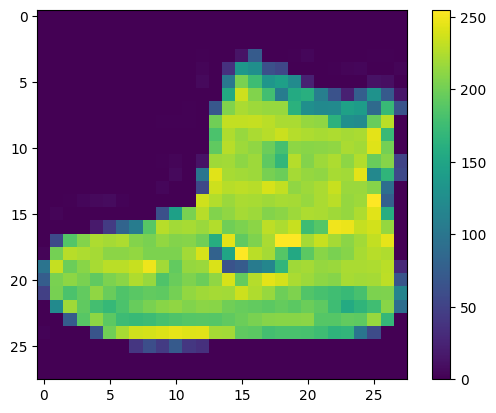
ปรับขนาดค่าเหล่านี้เป็นช่วง 0 ถึง 1 ก่อนป้อนไปยังโมเดลโครงข่ายประสาทเทียม ในการทำเช่นนั้น ให้หารค่าด้วย 255 สิ่งสำคัญคือ ชุดการฝึกและชุด การ ทดสอบ ต้องได้รับการประมวลผลล่วงหน้าในลักษณะเดียวกัน:
train_images = train_images / 255.0
test_images = test_images / 255.0
เพื่อตรวจสอบว่าข้อมูลอยู่ในรูปแบบที่ถูกต้อง และคุณพร้อมที่จะสร้างและฝึกอบรมเครือข่าย ให้แสดงรูปภาพ 25 ภาพแรกจาก ชุดการฝึก และแสดงชื่อคลาสด้านล่างแต่ละภาพ
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

สร้างแบบจำลอง
การสร้างโครงข่ายประสาทเทียมจำเป็นต้องมีการกำหนดค่าเลเยอร์ของแบบจำลอง จากนั้นจึงรวบรวมแบบจำลอง
ตั้งค่าเลเยอร์
โครงสร้างพื้นฐานของโครงข่ายประสาทเทียมคือ เลเยอร์ เลเยอร์ดึงข้อมูลที่แสดงออกมาจากข้อมูลที่ป้อนเข้าไป หวังว่าการแสดงแทนเหล่านี้จะมีความหมายสำหรับปัญหาที่อยู่ในมือ
การเรียนรู้เชิงลึกส่วนใหญ่ประกอบด้วยการโยงเลเยอร์ง่าย ๆ เข้าด้วยกัน เลเยอร์ส่วนใหญ่ เช่น tf.keras.layers.Dense มีพารามิเตอร์ที่เรียนรู้ระหว่างการฝึก
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
เลเยอร์แรกในเครือข่ายนี้ tf.keras.layers.Flatten จะเปลี่ยนรูปแบบของรูปภาพจากอาร์เรย์สองมิติ (ขนาด 28 x 28 พิกเซล) เป็นอาร์เรย์แบบหนึ่งมิติ (ขนาด 28 * 28 = 784 พิกเซล) คิดว่าเลเยอร์นี้เป็นแถวของพิกเซลที่แยกจากกันในรูปภาพและเรียงแถวกัน เลเยอร์นี้ไม่มีพารามิเตอร์ให้เรียนรู้ มันเพียงฟอร์แมตข้อมูลเท่านั้น
หลังจากที่พิกเซลถูกทำให้แบน เครือข่ายจะประกอบด้วยลำดับชั้น tf.keras.layers.Dense สองชั้น สิ่งเหล่านี้เชื่อมต่อกันอย่างหนาแน่นหรือเชื่อมต่อกันอย่างสมบูรณ์ชั้นประสาท เลเยอร์ Dense แรกมี 128 โหนด (หรือเซลล์ประสาท) เลเยอร์ที่สอง (และสุดท้าย) ส่งคืนอาร์เรย์ logits ที่มีความยาว 10 แต่ละโหนดมีคะแนนที่ระบุว่ารูปภาพปัจจุบันเป็นของหนึ่งใน 10 คลาส
รวบรวมโมเดล
ก่อนที่โมเดลจะพร้อมสำหรับการฝึก จำเป็นต้องมีการตั้งค่าเพิ่มเติมอีกเล็กน้อย สิ่งเหล่านี้ถูกเพิ่มเข้ามาในระหว่างขั้นตอนการ คอมไพล์ ของโมเดล:
- ฟังก์ชันการสูญเสีย — วัดความเที่ยงตรงของแบบจำลองระหว่างการฝึก คุณต้องการย่อฟังก์ชันนี้ให้เล็กสุดเพื่อ "บังคับ" โมเดลไปในทิศทางที่ถูกต้อง
- เครื่องมือเพิ่มประสิทธิภาพ — นี่คือวิธีการอัปเดตโมเดลตามข้อมูลที่เห็นและฟังก์ชันการสูญเสีย
- เมตริก —ใช้ตรวจสอบขั้นตอนการฝึกอบรมและการทดสอบ ตัวอย่างต่อไปนี้ใช้ ความแม่นยำ ซึ่งเป็นส่วนของภาพที่จัดประเภทอย่างถูกต้อง
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
ฝึกโมเดล
การฝึกโมเดลโครงข่ายประสาทเทียมต้องมีขั้นตอนต่อไปนี้:
- ป้อนข้อมูลการฝึกอบรมไปยังแบบจำลอง ในตัวอย่างนี้ ข้อมูลการฝึกอยู่ในอาร์เรย์
train_imagesและtrain_labels - โมเดลเรียนรู้ที่จะเชื่อมโยงรูปภาพและป้ายกำกับ
- คุณขอให้โมเดลคาดการณ์เกี่ยวกับชุดทดสอบ ในตัวอย่างนี้ อาร์เรย์
test_images - ตรวจสอบว่าการคาดคะเนตรงกับป้ายกำกับจากอาร์เรย์
test_labels
ป้อนโมเดล
หากต้องการเริ่มการฝึก ให้เรียกใช้เมธอด model.fit ซึ่งเรียกว่า "พอดี" โมเดลกับข้อมูลการฝึก:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5014 - accuracy: 0.8232 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3770 - accuracy: 0.8636 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3376 - accuracy: 0.8770 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3148 - accuracy: 0.8841 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2973 - accuracy: 0.8899 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2807 - accuracy: 0.8955 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2707 - accuracy: 0.9002 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2592 - accuracy: 0.9042 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2506 - accuracy: 0.9070 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2419 - accuracy: 0.9090 <keras.callbacks.History at 0x7f730da81c50>
ขณะที่รถไฟจำลอง ระบบจะแสดงเมตริกการสูญเสียและความแม่นยำ โมเดลนี้มีความแม่นยำประมาณ 0.91 (หรือ 91%) ในข้อมูลการฝึก
ประเมินความถูกต้อง
ถัดไป เปรียบเทียบประสิทธิภาพของโมเดลในชุดข้อมูลทดสอบ:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3347 - accuracy: 0.8837 - 593ms/epoch - 2ms/step Test accuracy: 0.8837000131607056ตัวยึดตำแหน่ง23
ปรากฎว่าความแม่นยำในชุดข้อมูลทดสอบน้อยกว่าความแม่นยำในชุดข้อมูลการฝึกเล็กน้อย ช่องว่างระหว่างความแม่นยำในการฝึกและความแม่นยำในการทดสอบนี้แสดงถึงความ เหมาะสม Overfitting เกิดขึ้นเมื่อโมเดลแมชชีนเลิร์นนิงทำงานได้ดีกับอินพุตใหม่ที่มองไม่เห็นก่อนหน้านี้มากกว่าที่ทำในข้อมูลการฝึก โมเดลที่ใส่มากเกินไปจะ "จดจำ" เสียงและรายละเอียดในชุดข้อมูลการฝึกจนถึงจุดที่ส่งผลกระทบในทางลบต่อประสิทธิภาพของแบบจำลองในข้อมูลใหม่ สำหรับข้อมูลเพิ่มเติม ดูสิ่งต่อไปนี้:
ทำนายฝัน
คุณสามารถใช้โมเดลนี้ในการคาดคะเนเกี่ยวกับภาพบางภาพได้ เอาต์พุตเชิงเส้นของ โมเดล บันทึก . แนบเลเยอร์ softmax เพื่อแปลงบันทึกเป็นความน่าจะเป็น ซึ่งง่ายต่อการตีความ
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
ในที่นี้ โมเดลได้คาดการณ์ป้ายกำกับสำหรับแต่ละรูปภาพในชุดทดสอบ มาดูคำทำนายแรกกัน:
predictions[0]
array([6.5094389e-07, 1.5681711e-10, 9.0262159e-10, 8.3779689e-10,
9.4969926e-07, 6.7454423e-03, 3.7524345e-08, 1.6792126e-02,
9.9967767e-09, 9.7646081e-01], dtype=float32)
การทำนายคืออาร์เรย์ของตัวเลข 10 ตัว สิ่งเหล่านี้แสดงถึง "ความมั่นใจ" ของนางแบบว่าภาพที่สอดคล้องกับบทความเกี่ยวกับเสื้อผ้า 10 ชิ้นที่แตกต่างกัน คุณสามารถดูว่าป้ายกำกับใดมีค่าความเชื่อมั่นสูงสุด:
np.argmax(predictions[0])
9
ดังนั้น นางแบบจึงมั่นใจมากที่สุดว่าภาพนี้คือรองเท้าบูทหุ้มข้อ หรือ class_names[9] การตรวจสอบฉลากทดสอบแสดงว่าการจัดหมวดหมู่นี้ถูกต้อง:
test_labels[0]
9
กราฟนี้เพื่อดูการทำนายคลาสทั้ง 10 ชุด
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
ตรวจสอบการคาดการณ์
คุณสามารถใช้โมเดลนี้ในการคาดคะเนเกี่ยวกับภาพบางภาพได้
มาดูภาพที่ 0 การคาดคะเน และอาร์เรย์การทำนายกัน ป้ายคาดคะเนที่ถูกต้องเป็นสีน้ำเงิน และป้ายคาดคะเนที่ไม่ถูกต้องเป็นสีแดง ตัวเลขระบุเปอร์เซ็นต์ (จาก 100) สำหรับป้ายกำกับที่คาดคะเน
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
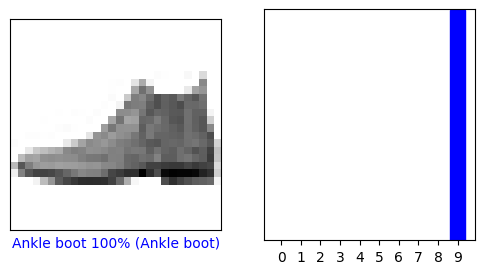
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
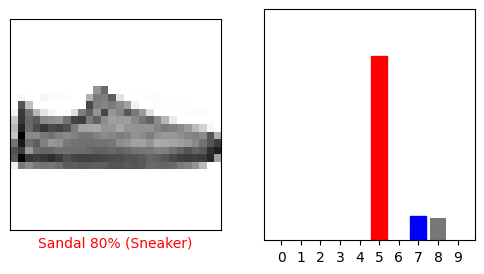
ลองพล็อตภาพหลายภาพด้วยการทำนายของพวกเขา โปรดทราบว่าโมเดลอาจผิดพลาดได้แม้ว่าจะมั่นใจมากก็ตาม
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

ใช้รูปแบบการฝึกอบรม
สุดท้าย ใช้แบบจำลองที่ได้รับการฝึกมาเพื่อทำนายเกี่ยวกับภาพเดียว
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
โมเดล tf.keras ได้รับการปรับให้เหมาะสมเพื่อคาดการณ์ใน ชุด งาน หรือการรวบรวม ตัวอย่างในคราวเดียว ดังนั้น แม้ว่าคุณจะใช้ภาพเดียว คุณต้องเพิ่มลงในรายการ:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)ตัวยึดตำแหน่ง39
ตอนนี้คาดเดาป้ายกำกับที่ถูกต้องสำหรับรูปภาพนี้:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[5.2901622e-05 1.1112720e-14 9.9954790e-01 3.9485815e-10 2.0636957e-04 7.8756333e-12 1.9278938e-04 2.9756516e-16 2.2718803e-08 4.3763088e-15]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
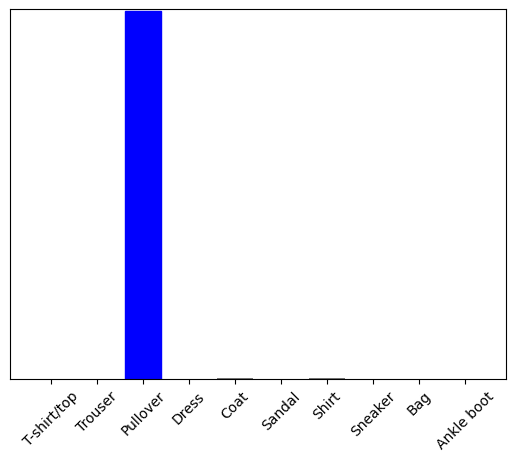
tf.keras.Model.predict ส่งคืนรายการ—หนึ่งรายการสำหรับแต่ละรูปภาพในชุดข้อมูล รับคำทำนายสำหรับภาพ (เท่านั้น) ของเราในชุด:
np.argmax(predictions_single[0])
2
และแบบจำลองคาดการณ์ฉลากตามที่คาดไว้
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.