
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทช่วยสอนนี้สาธิตวิธีการใช้วิธี Actor-Critic โดยใช้ TensorFlow เพื่อฝึกอบรมตัวแทนในสภาพแวดล้อม Open AI Gym CartPole-V0 ผู้อ่านจะถือว่ามีความคุ้นเคยกับ วิธีการไล่ระดับนโยบาย ของการเรียนรู้การเสริมแรง
วิธีการแสดง-วิจารณ์
วิธีการนักวิจารณ์-วิจารณ์เป็นวิธี การเรียนรู้ความแตกต่างชั่วคราว (TD) ที่แสดงฟังก์ชันนโยบายที่ไม่ขึ้นกับฟังก์ชันค่า
ฟังก์ชันนโยบาย (หรือนโยบาย) ส่งกลับการแจกแจงความน่าจะเป็นเหนือการกระทำที่ตัวแทนสามารถทำได้ตามสถานะที่กำหนด ฟังก์ชันค่ากำหนดผลตอบแทนที่คาดหวังสำหรับตัวแทนที่เริ่มต้นในสถานะที่กำหนดและดำเนินการตามนโยบายเฉพาะตลอดไปหลังจากนั้น
ในวิธีนักวิจารณ์-วิจารณ์ นโยบายจะเรียกว่า นักแสดง ที่เสนอชุดของการกระทำที่เป็นไปได้โดยให้สถานะ และฟังก์ชันค่าโดยประมาณเรียกว่า นักวิจารณ์ ซึ่งประเมินการกระทำของ นักแสดง ตามนโยบายที่กำหนด .
ในบทช่วยสอนนี้ ทั้ง นักแสดง และ นักวิจารณ์ จะแสดงโดยใช้โครงข่ายประสาทเทียมที่มีสองเอาต์พุต
รถเข็นเสา-v0
ใน สภาพแวดล้อม CartPole-v0 จะมีการติดเสาเข้ากับรถเข็นที่เคลื่อนที่ไปตามรางที่ไม่มีการเสียดสี เสาเริ่มต้นตั้งตรงและเป้าหมายของตัวแทนคือการป้องกันไม่ให้ล้มโดยใช้แรง -1 หรือ +1 กับรถเข็น จะมีการให้รางวัล +1 สำหรับทุกๆ ก้าวที่เสายังคงตั้งตรง ตอนจะสิ้นสุดลงเมื่อ (1) เสาอยู่ห่างจากแนวตั้งมากกว่า 15 องศา หรือ (2) รถเข็นเคลื่อนตัวจากศูนย์กลางมากกว่า 2.4 หน่วย
ปัญหาจะถือว่า "แก้ไข" เมื่อรางวัลรวมโดยเฉลี่ยสำหรับตอนถึง 195 ครั้งมากกว่า 100 ครั้งติดต่อกัน
ติดตั้ง
นำเข้าแพ็คเกจที่จำเป็นและกำหนดการตั้งค่าส่วนกลาง
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
แบบอย่าง
นักแสดง และ นักวิจารณ์ จะถูกจำลองโดยใช้โครงข่ายประสาทเทียมหนึ่งโครงข่ายที่สร้างความน่าจะเป็นในการดำเนินการและมูลค่าการวิจารณ์ตามลำดับ บทช่วยสอนนี้ใช้การจัดคลาสย่อยของโมเดลเพื่อกำหนดโมเดล
ในระหว่างการส่งต่อ แบบจำลองจะรับสถานะเป็นอินพุต และจะส่งออกทั้งความน่าจะเป็นของการดำเนินการและค่าวิจารณ์ \(V\)ซึ่งจำลอง ฟังก์ชันค่า ที่ขึ้นกับสถานะ เป้าหมายคือการฝึกโมเดลที่เลือกการดำเนินการตามนโยบาย \(\pi\) ที่เพิ่ม ผลตอบแทน ที่คาดหวังได้สูงสุด
สำหรับ Cartpole-v0 มีสี่ค่าที่แสดงถึงสถานะ: ตำแหน่งรถเข็น ความเร็วของรถเข็น มุมของเสา และความเร็วของเสาตามลำดับ ตัวแทนสามารถดำเนินการสองอย่างเพื่อผลักรถเข็นไปทางซ้าย (0) และทางขวา (1) ตามลำดับ
อ้างถึง หน้าวิกิ CartPole-v0 ของ OpenAI Gym สำหรับข้อมูลเพิ่มเติม
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
การฝึกอบรม
ในการฝึกอบรมตัวแทน คุณจะต้องทำตามขั้นตอนเหล่านี้:
- รันเอเจนต์บนสภาพแวดล้อมเพื่อรวบรวมข้อมูลการฝึกต่อตอน
- คำนวณผลตอบแทนที่คาดหวังในแต่ละขั้นตอน
- คำนวณการสูญเสียสำหรับแบบจำลองนักวิจารณ์ที่รวมกัน
- คำนวณการไล่ระดับสีและอัปเดตพารามิเตอร์เครือข่าย
- ทำซ้ำ 1-4 จนกว่าจะถึงเกณฑ์ความสำเร็จหรือจำนวนตอนสูงสุด
1. รวบรวมข้อมูลการฝึก
ในการเรียนรู้ภายใต้การดูแล คุณต้องมีข้อมูลการฝึกอบรมเพื่อฝึกรูปแบบการวิจารณ์นักแสดง อย่างไรก็ตาม ในการรวบรวมข้อมูลดังกล่าว โมเดลจะต้อง "รัน" ในสภาพแวดล้อม
ข้อมูลการฝึกอบรมจะถูกเก็บรวบรวมสำหรับแต่ละตอน จากนั้นในแต่ละขั้นตอน เวลา forward pass ของโมเดลจะทำงานบนสถานะของสภาพแวดล้อมเพื่อสร้างความน่าจะเป็นของการดำเนินการและค่าวิจารณ์ตามนโยบายปัจจุบันที่กำหนดพารามิเตอร์โดยน้ำหนักของโมเดล
การดำเนินการถัดไปจะถูกสุ่มตัวอย่างจากความน่าจะเป็นของการดำเนินการที่สร้างโดยแบบจำลอง ซึ่งจะนำไปใช้กับสภาพแวดล้อม ทำให้เกิดสถานะถัดไปและรางวัลที่สร้างขึ้น
กระบวนการนี้ถูกนำมาใช้ในฟังก์ชัน run_episode ซึ่งใช้การดำเนินการ TensorFlow เพื่อให้สามารถคอมไพล์เป็นกราฟ TensorFlow ได้ในภายหลังเพื่อการฝึกที่รวดเร็วขึ้น โปรดทราบว่า tf.TensorArray ถูกใช้เพื่อรองรับการวนซ้ำของ Tensor บนอาร์เรย์ความยาวผันแปรได้
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. การคำนวณผลตอบแทนที่คาดหวัง
ลำดับของรางวัลสำหรับแต่ละช่วงเวลา \(t\), \(\{r_{t}\}^{T}_{t=1}\) ที่รวบรวมในตอนหนึ่งจะถูกแปลงเป็นลำดับของผลตอบแทนที่คาดหวัง \(\{G_{t}\}^{T}_{t=1}\) ซึ่งผลรวมของรางวัลจะถูกนำมาจากขั้นตอนเวลาปัจจุบัน \(t\) ถึง \(T\) และแต่ละรายการ รางวัลคูณด้วยปัจจัยส่วนลดที่ลดลงแบบทวีคูณ \(\gamma\):
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
ตั้งแต่ \(\gamma\in(0,1)\)รางวัลที่ไกลจากขั้นตอนปัจจุบันจะมีน้ำหนักน้อยลง
ตามสัญชาตญาณแล้ว ผลตอบแทนที่คาดหวังก็หมายความว่ารางวัลในตอนนี้ดีกว่ารางวัลในภายหลัง ในความหมายทางคณิตศาสตร์ ก็คือการทำให้แน่ใจว่าผลรวมของรางวัลจะมาบรรจบกัน
เพื่อทำให้การฝึกมีเสถียรภาพ ลำดับผลลัพธ์ของผลตอบแทนยังเป็นมาตรฐานอีกด้วย (กล่าวคือต้องมีค่าเฉลี่ยเป็นศูนย์และส่วนเบี่ยงเบนมาตรฐานของหน่วย)
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. การสูญเสียนักแสดง - นักวิจารณ์
เนื่องจากมีการใช้แบบจำลองนักวิจารณ์และนักวิจารณ์แบบลูกผสม ฟังก์ชันการสูญเสียที่เลือกจึงเป็นการผสมผสานระหว่างความสูญเสียของนักแสดงและนักวิจารณ์สำหรับการฝึกอบรม ดังที่แสดงด้านล่าง:
\[L = L_{actor} + L_{critic}\]
การสูญเสียนักแสดง
การสูญเสียนักแสดงขึ้นอยู่กับ นโยบายไล่ระดับโดยนักวิจารณ์เป็นพื้นฐานขึ้นอยู่กับสถานะ และคำนวณด้วยการประมาณการตัวอย่างเดียว (ต่อตอน)
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
ที่ไหน:
- \(T\): จำนวนครั้งต่อตอน ซึ่งสามารถเปลี่ยนแปลงได้ในแต่ละตอน
- \(s_{t}\): สถานะ ณ ช่วงเวลา \(t\)
- \(a_{t}\): เลือกการกระทำที่ timestep \(t\) กำหนดสถานะ \(s\)
- \(\pi_{\theta}\): เป็นนโยบาย (นักแสดง) ที่กำหนดพารามิเตอร์โดย \(\theta\)
- \(V^{\pi}_{\theta}\): เป็นฟังก์ชันค่า (วิจารณ์) ที่กำหนดพารามิเตอร์ด้วย \(\theta\)
- \(G = G_{t}\): ผลตอบแทนที่คาดหวังสำหรับสถานะที่กำหนด คู่การกระทำที่ timestep \(t\)
คำที่เป็นลบจะถูกเพิ่มเข้าไปในผลรวมเนื่องจากแนวคิดคือการเพิ่มความน่าจะเป็นของการกระทำที่ให้ผลตอบแทนที่สูงขึ้นโดยการลดการขาดทุนรวมกันให้น้อยที่สุด
ข้อได้เปรียบ
คำศัพท์ \(L_{actor}\) ในสูตร l10n- \(G - V\) ของเราเรียกว่า ข้อได้เปรียบ ซึ่งบ่งชี้ว่าการดำเนินการได้รับสถานะเฉพาะมากกว่าการกระทำแบบสุ่มที่เลือกตามนโยบาย \(\pi\) สำหรับสถานะนั้นดีกว่ามากเพียงใด
แม้ว่าการยกเว้นพื้นฐานอาจเป็นไปได้ แต่อาจส่งผลให้มีความแปรปรวนสูงระหว่างการฝึก และสิ่งที่ดีในการเลือกนักวิจารณ์ \(V\) เป็นพื้นฐานก็คือ มันถูกฝึกฝนให้อยู่ใกล้ \(G\)มากที่สุด ทำให้เกิดความแปรปรวนที่ต่ำกว่า
นอกจากนี้ หากไม่มีนักวิจารณ์ อัลกอริธึมจะพยายามเพิ่มความน่าจะเป็นสำหรับการดำเนินการในสถานะใดสถานะหนึ่งโดยพิจารณาจากผลตอบแทนที่คาดหวัง ซึ่งอาจไม่ได้สร้างความแตกต่างมากนักหากความน่าจะเป็นที่สัมพันธ์กันระหว่างการกระทำยังคงเหมือนเดิม
ตัวอย่างเช่น สมมติว่าสองการกระทำสำหรับสถานะที่กำหนดจะให้ผลตอบแทนที่คาดหวังเหมือนกัน หากไม่มีนักวิจารณ์ อัลกอริทึมจะพยายามเพิ่มความน่าจะเป็นของการกระทำเหล่านี้ตามวัตถุประสงค์ \(J\)สำหรับนักวิจารณ์ อาจกลายเป็นว่าไม่มีข้อได้เปรียบ (\(G - V = 0\)) ดังนั้นจึงไม่มีประโยชน์ใดในการเพิ่มความน่าจะเป็นของการกระทำ และอัลกอริทึมจะตั้งค่าการไล่ระดับสีเป็นศูนย์
นักวิจารณ์สูญเสีย
การฝึกอบรม \(V\) ให้ใกล้เคียงกับ \(G\) มากที่สุด สามารถตั้งค่าให้เป็นปัญหาการถดถอยด้วยฟังก์ชันการสูญเสียต่อไปนี้:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
โดยที่ \(L_{\delta}\) คือการ สูญเสียของ Huber ซึ่งมีความไวต่อค่าผิดปกติในข้อมูลน้อยกว่าการสูญเสียข้อผิดพลาดกำลังสอง
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. กำหนดขั้นตอนการฝึกอบรมเพื่ออัปเดตพารามิเตอร์
ขั้นตอนทั้งหมดข้างต้นรวมกันเป็นขั้นตอนการฝึกที่ดำเนินการทุกตอน ขั้นตอนทั้งหมดที่นำไปสู่ฟังก์ชันการสูญเสียจะดำเนินการด้วยบริบท tf.GradientTape เพื่อเปิดใช้งานการสร้างความแตกต่างโดยอัตโนมัติ
บทช่วยสอนนี้ใช้เครื่องมือเพิ่มประสิทธิภาพ Adam เพื่อใช้การไล่ระดับสีกับพารามิเตอร์โมเดล
ผลรวมของรางวัลที่ยังไม่ได้ลดราคาคือ episode_reward จะถูกคำนวณในขั้นตอนนี้เช่นกัน ค่านี้จะใช้ในภายหลังเพื่อประเมินว่าตรงตามเกณฑ์ความสำเร็จหรือไม่
บริบท tf.function ถูกนำไปใช้กับฟังก์ชัน train_step เพื่อให้สามารถคอมไพล์เป็นกราฟ TensorFlow ที่เรียกได้ ซึ่งสามารถนำไปสู่การเร่งความเร็ว 10 เท่าในการฝึก
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. เรียกใช้วงการฝึก
การฝึกจะดำเนินการโดยใช้ขั้นตอนการฝึกจนกว่าจะถึงเกณฑ์ความสำเร็จหรือถึงจำนวนตอนสูงสุด
บันทึกการทำงานของรางวัลตอนจะถูกเก็บไว้ในคิว เมื่อถึงการทดสอบ 100 ครั้ง รางวัลที่เก่าที่สุดจะถูกลบออกที่ปลายด้านซ้าย (ส่วนท้าย) ของคิว และรางวัลใหม่ล่าสุดจะเพิ่มที่ส่วนหัว (ขวา) ผลรวมของรางวัลจะยังคงอยู่เพื่อประสิทธิภาพในการคำนวณ
การฝึกจะเสร็จสิ้นภายในเวลาไม่ถึงนาทีทั้งนี้ขึ้นอยู่กับรันไทม์ของคุณ
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
การสร้างภาพ
หลังการฝึก จะเป็นการดีที่จะนึกภาพว่าแบบจำลองทำงานอย่างไรในสภาพแวดล้อม คุณสามารถเรียกใช้เซลล์ด้านล่างเพื่อสร้างภาพเคลื่อนไหว GIF ของการเรียกใช้โมเดลหนึ่งตอน โปรดทราบว่า OpenAI Gym จำเป็นต้องติดตั้งแพ็คเกจเพิ่มเติมเพื่อแสดงภาพของสภาพแวดล้อมใน Colab อย่างถูกต้อง
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
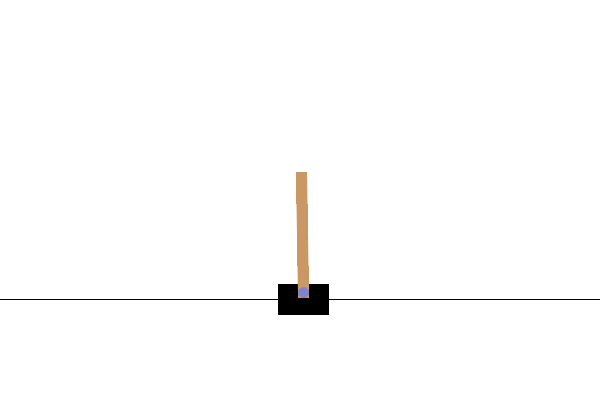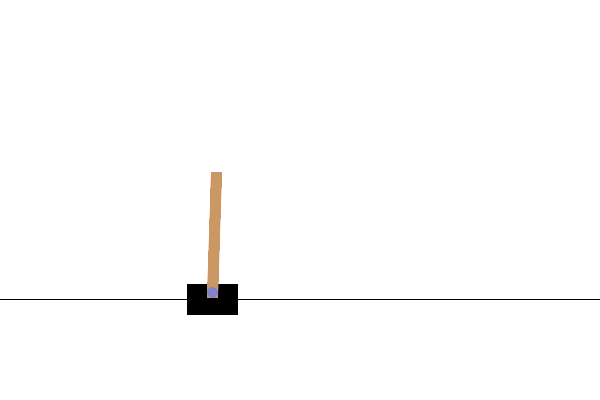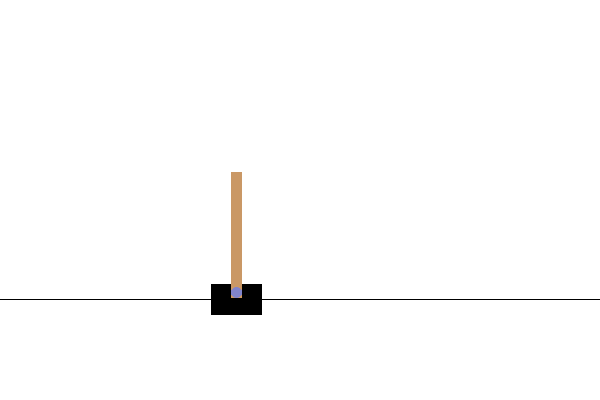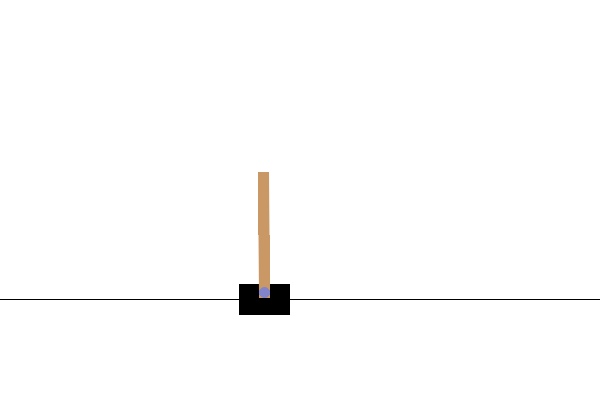
ขั้นตอนถัดไป
กวดวิชานี้สาธิตวิธีการใช้วิธีการวิจารณ์นักแสดงโดยใช้ Tensorflow
ในขั้นตอนต่อไป คุณสามารถลองฝึกโมเดลในสภาพแวดล้อมที่แตกต่างกันใน OpenAI Gym
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีการวิจารณ์ของนักแสดงและปัญหา Cartpole-v0 คุณสามารถอ้างอิงถึงแหล่งข้อมูลต่อไปนี้:
- วิธีการวิจารณ์นักแสดง
- การบรรยายนักวิจารณ์นักแสดง (CAL)
- ปัญหาการควบคุมการเรียนรู้ของ Cartpole [Barto, et al. พ.ศ. 2523
สำหรับตัวอย่างการเรียนรู้การเสริมแรงเพิ่มเติมใน TensorFlow คุณสามารถตรวจสอบแหล่งข้อมูลต่อไปนี้: