
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این راهنما از یادگیری ماشینی برای دستهبندی گلهای زنبق بر اساس گونه استفاده میکند. از TensorFlow برای موارد زیر استفاده می کند:
- یک مدل بسازید،
- این مدل را بر روی داده های مثال آموزش دهید و
- از مدل برای پیش بینی داده های ناشناخته استفاده کنید.
برنامه نویسی TensorFlow
این راهنما از این مفاهیم سطح بالا TensorFlow استفاده می کند:
- از محیط توسعه اجرای مشتاق پیشفرض TensorFlow استفاده کنید،
- وارد کردن داده با Datasets API ،
- مدل ها و لایه ها را با Keras API TensorFlow بسازید .
این آموزش مانند بسیاری از برنامه های TensorFlow ساختار یافته است:
- وارد کردن و تجزیه مجموعه داده.
- نوع مدل را انتخاب کنید.
- مدل را آموزش دهید.
- کارایی مدل را ارزیابی کنید.
- از مدل آموزش دیده برای پیش بینی استفاده کنید.
برنامه راه اندازی
پیکربندی واردات
TensorFlow و سایر ماژول های پایتون مورد نیاز را وارد کنید. به طور پیش فرض، TensorFlow از اجرای مشتاق برای ارزیابی فوری عملیات استفاده می کند، به جای ایجاد یک نمودار محاسباتی که بعداً اجرا می شود، مقادیر مشخص را برمی گرداند. اگر به یک REPL یا کنسول تعاملی python عادت دارید، این به نظر آشنا است.
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.8.0-rc1 Eager execution: True
مشکل طبقه بندی عنبیه
تصور کنید یک گیاه شناس هستید که به دنبال روشی خودکار برای دسته بندی هر گل زنبق که پیدا می کنید هستید. یادگیری ماشین الگوریتم های زیادی را برای طبقه بندی آماری گل ها ارائه می دهد. به عنوان مثال، یک برنامه یادگیری ماشینی پیچیده می تواند گل ها را بر اساس عکس ها طبقه بندی کند. جاه طلبی های ما ساده تر است - ما گل های زنبق را بر اساس اندازه گیری طول و عرض کاسبرگ و گلبرگ آنها طبقه بندی می کنیم.
جنس زنبق شامل حدود 300 گونه است، اما برنامه ما فقط سه گونه زیر را طبقه بندی می کند:
- زنبق ستوزا
- زنبق ویرجینیکا
- زنبق ورسیکالر
 |
| شکل 1. Iris setosa (توسط Radomil ، CC BY-SA 3.0)، Iris versicolor ، (توسط Dlanglois ، CC BY-SA 3.0)، و Iris virginica (توسط Frank Mayfield ، CC BY-SA 2.0). |
خوشبختانه، شخصی قبلاً مجموعه داده ای از 120 گل زنبق را با اندازه های کاسبرگ و گلبرگ ایجاد کرده است. این یک مجموعه داده کلاسیک است که برای مشکلات طبقه بندی یادگیری ماشین مبتدی محبوب است.
مجموعه داده آموزشی را وارد و تجزیه کنید
فایل مجموعه داده را دانلود کنید و آن را به ساختاری تبدیل کنید که توسط این برنامه پایتون قابل استفاده باشد.
مجموعه داده را دانلود کنید
فایل مجموعه داده آموزشی را با استفاده از تابع tf.keras.utils.get_file کنید. این مسیر فایل فایل دانلود شده را برمی گرداند:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
داده ها را بررسی کنید
این مجموعه داده، iris_training.csv ، یک فایل متنی ساده است که داده های جدولی را به صورت مقادیر جدا شده با کاما (CSV) قالب بندی می کند. از دستور head -n5 برای نگاه کردن به پنج ورودی اول استفاده کنید:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
از این نمای مجموعه داده، به موارد زیر توجه کنید:
- خط اول هدر حاوی اطلاعاتی در مورد مجموعه داده است:
- در مجموع 120 نمونه وجود دارد. هر نمونه دارای چهار ویژگی و یکی از سه نام برچسب ممکن است.
- ردیف های بعدی رکوردهای داده هستند، یک مثال در هر خط، که در آن:
بیایید آن را در کد بنویسیم:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
هر برچسب با نام رشته مرتبط است (به عنوان مثال، "setosa")، اما یادگیری ماشین معمولاً بر مقادیر عددی متکی است. اعداد برچسب به یک نمایش نامگذاری شده نگاشت می شوند، مانند:
-
0: زنبق ستوزا -
1: زنبق رنگارنگ -
2: زنبق ویرجینیکا
برای کسب اطلاعات بیشتر در مورد ویژگیها و برچسبها، به بخش اصطلاحات ML در دوره تصادف یادگیری ماشین مراجعه کنید.
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
یک tf.data.Dataset ایجاد کنید
API دادههای TensorFlow بسیاری از موارد رایج را برای بارگذاری دادهها در یک مدل مدیریت میکند. این یک API سطح بالا برای خواندن داده ها و تبدیل آن به فرمی است که برای آموزش استفاده می شود.
از آنجایی که مجموعه داده یک فایل متنی با فرمت CSV است، از تابع tf.data.experimental.make_csv_dataset برای تجزیه داده ها در قالب مناسب استفاده کنید. از آنجایی که این تابع دادهها را برای مدلهای آموزشی تولید میکند، رفتار پیشفرض این است که دادهها را به هم بزند (shufle shuffle=True, shuffle_buffer_size=10000 )، و مجموعه داده را برای همیشه تکرار کنید ( num_epochs=None ). ما همچنین پارامتر batch_size را تنظیم می کنیم:
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
تابع make_csv_dataset یک مجموعه tf.data.Dataset از جفت (features, label) را برمی گرداند، که در آن features ها یک فرهنگ لغت است: {'feature_name': value}
این اشیاء Dataset قابل تکرار هستند. بیایید به مجموعه ای از ویژگی ها نگاه کنیم:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5. , 7.4, 6. , 7.2, 5.9, 5.8, 5. , 5. , 7.7, 5.7, 6.3, 5.8, 5. ,
4.8, 6.6, 6.3, 5.4, 6.9, 4.8, 6.6, 5.8, 7.7, 6.7, 7.6, 5.5, 6.4,
5.6, 6.4, 4.4, 4.5, 6.5, 6.3], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([3.5, 2.8, 2.7, 3.2, 3. , 2.6, 2. , 3.4, 3. , 2.8, 2.3, 2.7, 3.6,
3.1, 2.9, 3.3, 3. , 3.1, 3. , 3. , 4. , 2.6, 3. , 3. , 2.4, 2.7,
2.7, 2.8, 3. , 2.3, 2.8, 2.5], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.6, 6.1, 5.1, 6. , 5.1, 4. , 3.5, 1.6, 6.1, 4.5, 4.4, 5.1, 1.4,
1.6, 4.6, 4.7, 4.5, 5.1, 1.4, 4.4, 1.2, 6.9, 5. , 6.6, 3.7, 5.3,
4.2, 5.6, 1.3, 1.3, 4.6, 5. ], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([0.6, 1.9, 1.6, 1.8, 1.8, 1.2, 1. , 0.4, 2.3, 1.3, 1.3, 1.9, 0.2,
0.2, 1.3, 1.6, 1.5, 2.3, 0.3, 1.4, 0.2, 2.3, 1.7, 2.1, 1. , 1.9,
1.3, 2.1, 0.2, 0.3, 1.5, 1.9], dtype=float32)>)])
توجه داشته باشید که ویژگیهای مشابه با هم گروهبندی یا دستهبندی میشوند. فیلدهای هر ردیف نمونه به آرایه ویژگی مربوطه اضافه می شوند. برای تنظیم تعداد نمونه های ذخیره شده در این آرایه های ویژگی، batch_size را تغییر دهید.
میتوانید با ترسیم چند ویژگی از دسته، شروع به دیدن برخی خوشهها کنید:
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
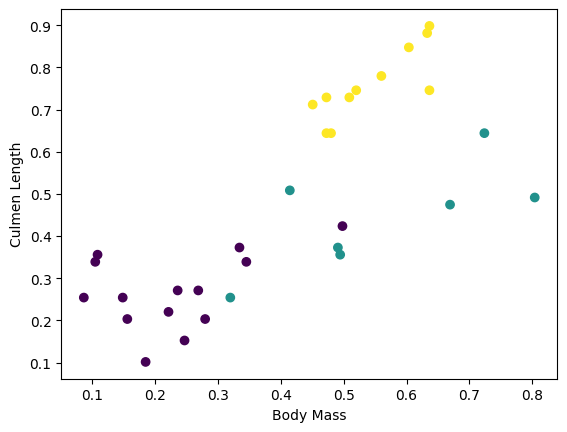
برای سادهسازی مرحله ساخت مدل، تابعی ایجاد کنید تا فرهنگ لغت ویژگیها را در یک آرایه واحد با شکل: (batch_size, num_features) کند.
این تابع از متد tf.stack استفاده می کند که مقادیر را از لیست تانسورها می گیرد و یک تانسور ترکیبی در بعد مشخص شده ایجاد می کند:
def pack_features_vector(features, labels):
"""Pack the features into a single array."""
features = tf.stack(list(features.values()), axis=1)
return features, labels
سپس از روش tf.data.Dataset#map برای بستهبندی features هر جفت (features,label) در مجموعه داده آموزشی استفاده کنید:
train_dataset = train_dataset.map(pack_features_vector)
عنصر ویژگی های Dataset اکنون آرایه هایی با شکل (batch_size, num_features) هستند. بیایید به چند مثال اول نگاه کنیم:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor( [[4.9 3. 1.4 0.2] [6.1 3. 4.9 1.8] [6.1 2.6 5.6 1.4] [6.9 3.2 5.7 2.3] [6.7 3.1 4.4 1.4]], shape=(5, 4), dtype=float32)
نوع مدل را انتخاب کنید
چرا مدل؟
مدل یک رابطه بین ویژگی ها و برچسب است. برای مسئله طبقهبندی زنبق، مدل رابطه بین اندازهگیریهای کاسبرگ و گلبرگ و گونههای عنبیه پیشبینیشده را تعریف میکند. برخی از مدلهای ساده را میتوان با چند خط جبر توصیف کرد، اما مدلهای یادگیری ماشینی پیچیده دارای تعداد زیادی پارامتر هستند که خلاصه کردن آنها دشوار است.
آیا می توانید بدون استفاده از یادگیری ماشینی رابطه بین چهار ویژگی و گونه عنبیه را تعیین کنید؟ یعنی آیا می توانید از تکنیک های برنامه نویسی سنتی (مثلاً بسیاری از دستورات شرطی) برای ایجاد یک مدل استفاده کنید؟ شاید اگر مجموعه داده را به اندازه کافی برای تعیین روابط بین اندازه گیری گلبرگ و کاسبرگ با یک گونه خاص تجزیه و تحلیل کنید. و این در مجموعه دادههای پیچیدهتر دشوار – شاید غیرممکن – میشود. یک رویکرد یادگیری ماشین خوب ، مدل را برای شما تعیین می کند . اگر نمونههای معرف کافی را به نوع مدل یادگیری ماشینی مناسب وارد کنید، برنامه روابط را برای شما مشخص خواهد کرد.
مدل را انتخاب کنید
ما باید نوع مدلی را برای آموزش انتخاب کنیم. انواع مختلفی از مدل ها وجود دارد و انتخاب یک مدل خوب نیاز به تجربه دارد. این آموزش از یک شبکه عصبی برای حل مشکل طبقه بندی عنبیه استفاده می کند. شبکه های عصبی می توانند روابط پیچیده ای بین ویژگی ها و برچسب پیدا کنند. این یک نمودار بسیار ساختار یافته است که در یک یا چند لایه پنهان سازماندهی شده است. هر لایه پنهان از یک یا چند نورون تشکیل شده است. چندین دسته از شبکه های عصبی وجود دارد و این برنامه از یک شبکه عصبی متراکم یا کاملاً متصل استفاده می کند : نورون های یک لایه اتصالات ورودی را از هر نورون در لایه قبلی دریافت می کنند. به عنوان مثال، شکل 2 یک شبکه عصبی متراکم متشکل از یک لایه ورودی، دو لایه پنهان و یک لایه خروجی را نشان می دهد:
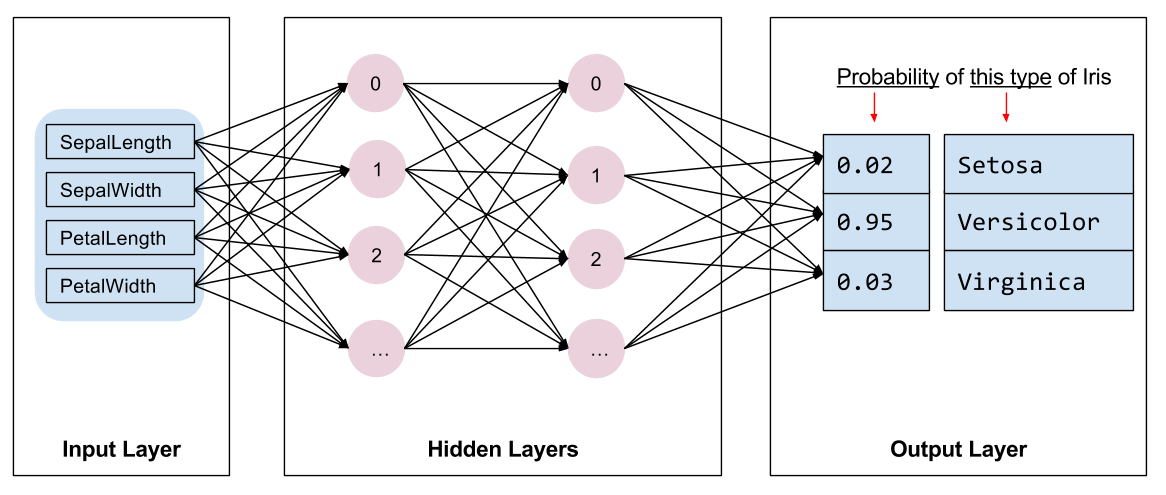 |
| شکل 2. یک شبکه عصبی با ویژگی ها، لایه های پنهان و پیش بینی ها. |
هنگامی که مدل شکل 2 آموزش داده می شود و با یک مثال بدون برچسب تغذیه می شود، سه پیش بینی به دست می دهد: احتمال اینکه این گل گونه عنبیه داده شده باشد. این پیش بینی استنتاج نامیده می شود. برای این مثال، مجموع پیشبینیهای خروجی 1.0 است. در شکل 2، این پیش بینی به صورت زیر تقسیم می شود: 0.02 برای Iris setosa ، 0.95 برای Iris versicolor ، و 0.03 برای Iris virginica . این به این معنی است که مدل پیشبینی میکند - با احتمال 95٪ - که یک گل نمونه بدون برچسب رنگ زنبق است.
با استفاده از Keras یک مدل ایجاد کنید
tf.keras API بهترین راه برای ایجاد مدلها و لایهها است. این کار ساخت مدلها و آزمایشها را آسان میکند در حالی که Keras پیچیدگی اتصال همه چیز را با هم انجام میدهد.
مدل tf.keras.Sequential یک پشته خطی از لایه ها است. سازنده آن فهرستی از نمونه های لایه را می گیرد، در این مورد، دو لایه tf.keras.layers.Dense لایه های متراکم با هر کدام 10 گره، و یک لایه خروجی با 3 گره که نشان دهنده پیش بینی های برچسب ما هستند. پارامتر input_shape لایه اول با تعداد ویژگی های مجموعه داده مطابقت دارد و لازم است:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
تابع فعال سازی شکل خروجی هر گره در لایه را تعیین می کند. این غیر خطی ها مهم هستند - بدون آنها مدل معادل یک لایه خواهد بود. tf.keras.activations زیادی وجود دارد، اما ReLU برای لایه های پنهان رایج است.
تعداد ایده آل لایه ها و نورون های پنهان به مشکل و مجموعه داده بستگی دارد. مانند بسیاری از جنبه های یادگیری ماشینی، انتخاب بهترین شکل شبکه عصبی مستلزم آمیزه ای از دانش و آزمایش است. به عنوان یک قاعده کلی، افزایش تعداد لایههای پنهان و نورونها معمولاً مدل قدرتمندتری ایجاد میکند که برای آموزش مؤثر به دادههای بیشتری نیاز دارد.
با استفاده از مدل
بیایید نگاهی گذرا به عملکرد این مدل با مجموعه ای از ویژگی ها بیندازیم:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0874639e+00, 1.5199981e-03, -9.9991310e-01],
[-5.3246369e+00, -1.8366380e-01, -1.3161827e+00],
[-5.1154275e+00, -2.8129923e-01, -1.3305402e+00],
[-6.0694785e+00, -2.1251860e-01, -1.5091233e+00],
[-5.6730523e+00, -1.4321266e-01, -1.4437559e+00]], dtype=float32)>
در اینجا، هر مثال یک logit برای هر کلاس برمی گرداند.
برای تبدیل این logit ها به یک احتمال برای هر کلاس، از تابع softmax استفاده کنید:
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.01210616, 0.7224865 , 0.26540732],
[0.00440638, 0.75297093, 0.24262273],
[0.00585618, 0.7362918 , 0.25785193],
[0.00224076, 0.7835035 , 0.21425581],
[0.00310779, 0.7834839 , 0.21340834]], dtype=float32)>
در نظر گرفتن tf.argmax در بین کلاس ها، شاخص کلاس پیش بینی شده را به ما می دهد. اما، این مدل هنوز آموزش ندیده است، بنابراین این ها پیش بینی های خوبی نیستند:
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [0 2 2 2 1 1 0 1 1 2 2 1 0 2 2 2 1 0 2 2 1 0 2 1 2 0 1 1 2 2 1 2]
مدل را آموزش دهید
آموزش مرحله ای از یادگیری ماشینی است که مدل به تدریج بهینه می شود یا مدل مجموعه داده را یاد می گیرد . هدف این است که به اندازه کافی در مورد ساختار مجموعه داده آموزشی یاد بگیریم تا بتوان در مورد داده های دیده نشده پیش بینی کرد. اگر در مورد مجموعه داده آموزشی بیش از حد یاد بگیرید، پیشبینیها فقط برای دادههایی که دیدهاند کار میکنند و قابل تعمیم نخواهند بود. این مشکل بیش از حد برازش نامیده می شود - مانند این است که به جای درک چگونگی حل یک مشکل، پاسخ ها را به خاطر بسپارید.
مسئله طبقهبندی عنبیه نمونهای از یادگیری ماشینی نظارت شده است : این مدل از نمونههایی که حاوی برچسب هستند آموزش داده میشود. در یادگیری ماشینی بدون نظارت ، نمونه ها دارای برچسب نیستند. در عوض، مدل معمولاً الگوهایی را در میان ویژگیها پیدا میکند.
تابع افت و گرادیان را تعریف کنید
هر دو مرحله آموزش و ارزیابی نیاز به محاسبه ضرر مدل دارند. این نشان میدهد که پیشبینیهای یک مدل چقدر از برچسب مورد نظر دور هستند، به عبارت دیگر، عملکرد مدل چقدر بد است. ما می خواهیم این مقدار را به حداقل برسانیم یا بهینه کنیم.
مدل ما تلفات خود را با استفاده از تابع tf.keras.losses.SparseCategoricalCrossentropy محاسبه میکند که پیشبینیهای احتمال کلاس مدل و برچسب مورد نظر را میگیرد و میانگین تلفات را در بین مثالها برمیگرداند.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.6059828996658325
از زمینه tf.GradientTape برای محاسبه گرادیان های مورد استفاده برای بهینه سازی مدل خود استفاده کنید:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
یک بهینه ساز ایجاد کنید
یک بهینه ساز ، گرادیان های محاسبه شده را بر روی متغیرهای مدل اعمال می کند تا تابع loss را به حداقل برساند. میتوانید تابع تلفات را به عنوان یک سطح منحنی در نظر بگیرید (شکل 3 را ببینید) و ما میخواهیم با قدم زدن در اطراف، پایینترین نقطه آن را پیدا کنیم. شیب ها در جهت شیب دارترین صعود قرار دارند—بنابراین مسیر مخالف را طی می کنیم و به سمت پایین تپه حرکت می کنیم. با محاسبه مکرر تلفات و گرادیان برای هر دسته، مدل را در طول آموزش تنظیم می کنیم. به تدریج، مدل بهترین ترکیب وزن و سوگیری را برای به حداقل رساندن کاهش پیدا می کند. و هرچه ضرر کمتر باشد، پیشبینی مدل بهتر است.
 |
| شکل 3. الگوریتم های بهینه سازی که در طول زمان در فضای سه بعدی تجسم شده اند. (منبع: Stanford class CS231n ، مجوز MIT، اعتبار تصویر: Alec Radford ) |
TensorFlow الگوریتم های بهینه سازی زیادی برای آموزش در دسترس دارد. این مدل از tf.keras.optimizers.SGD استفاده می کند که الگوریتم گرادیان تصادفی (SGD) را پیاده سازی می کند. learning_rate اندازه گام را برای هر تکرار در پایین تپه تعیین می کند. این یک فراپارامتر است که معمولاً برای دستیابی به نتایج بهتر آن را تنظیم می کنید.
بیایید بهینه ساز را راه اندازی کنیم:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
ما از این برای محاسبه یک مرحله بهینه سازی استفاده می کنیم:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.6059828996658325 Step: 1, Loss: 1.3759253025054932
حلقه آموزشی
با تمام قطعات در جای خود، مدل آماده آموزش است! یک حلقه آموزشی، نمونه های مجموعه داده را به مدل تغذیه می کند تا به پیش بینی های بهتر کمک کند. بلوک کد زیر این مراحل آموزشی را تنظیم می کند:
- هر دوره را تکرار کنید. یک دوره یک گذر از مجموعه داده است.
- در یک دوره، روی هر مثال در
Datasetآموزشی تکرار کنید و ویژگیهای (x) و برچسب (y) آن را در نظر بگیرید. - با استفاده از ویژگی های مثال، یک پیش بینی انجام دهید و آن را با برچسب مقایسه کنید. عدم دقت پیشبینی را اندازهگیری کنید و از آن برای محاسبه تلفات و گرادیانهای مدل استفاده کنید.
- از یک
optimizerبرای به روز رسانی متغیرهای مدل استفاده کنید. - برخی از آمارها را برای تجسم پیگیری کنید.
- برای هر دوره تکرار کنید.
متغیر num_epochs تعداد دفعاتی است که روی مجموعه داده ها حلقه زده می شود. برخلاف شهود، آموزش طولانیتر یک مدل، مدل بهتر را تضمین نمیکند. num_epochs یک هایپرپارامتر است که می توانید آن را تنظیم کنید. انتخاب عدد مناسب معمولاً به تجربه و آزمایش نیاز دارد:
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.766, Accuracy: 43.333% Epoch 050: Loss: 0.579, Accuracy: 71.667% Epoch 100: Loss: 0.398, Accuracy: 82.500% Epoch 150: Loss: 0.307, Accuracy: 92.500% Epoch 200: Loss: 0.224, Accuracy: 95.833%
عملکرد ضرر را در طول زمان تجسم کنید
در حالی که چاپ کردن پیشرفت آموزشی مدل مفید است، مشاهده این پیشرفت اغلب مفیدتر است. TensorBoard یک ابزار تجسم سازی خوب است که با TensorFlow بسته بندی شده است، اما ما می توانیم نمودارهای اولیه را با استفاده از ماژول matplotlib ایجاد کنیم.
تفسیر این نمودارها به تجربه کمی نیاز دارد، اما شما واقعاً می خواهید شاهد کاهش ضرر و افزایش دقت باشید:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
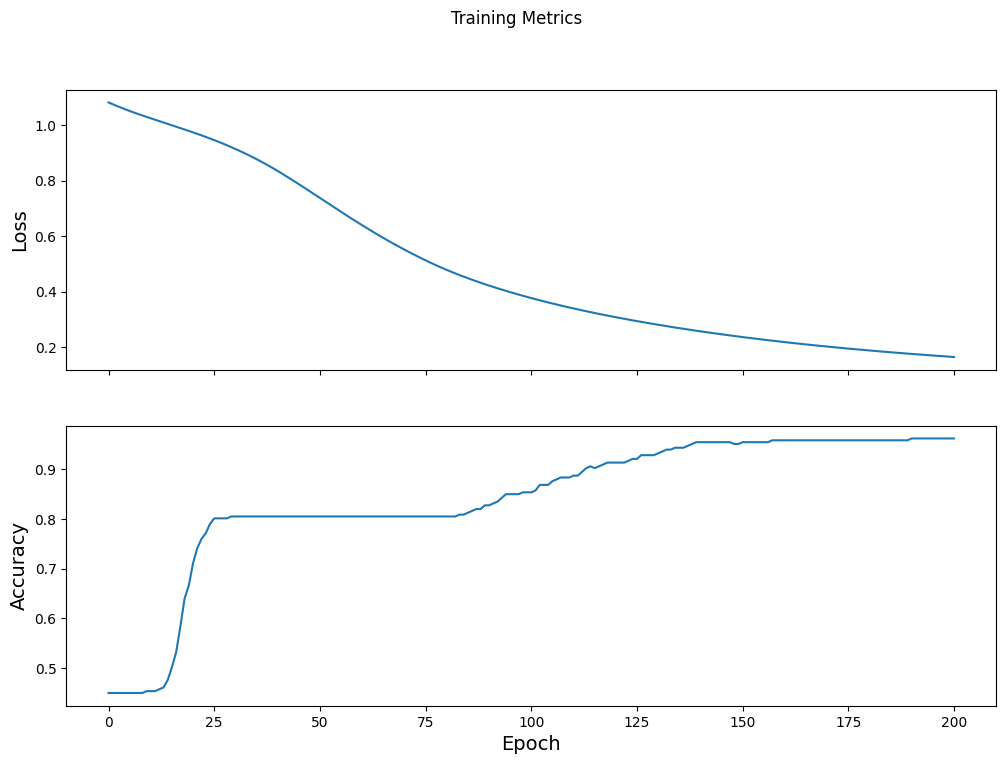
کارایی مدل را ارزیابی کنید
اکنون که مدل آموزش دیده است، می توانیم آماری از عملکرد آن به دست آوریم.
ارزیابی به معنای تعیین میزان مؤثر پیش بینی های مدل است. برای تعیین اثربخشی مدل در طبقهبندی عنبیه، اندازهگیریهای کاسبرگ و گلبرگ را به مدل منتقل کنید و از مدل بخواهید تا پیشبینی کند که چه گونههای زنبق را نشان میدهند. سپس پیش بینی های مدل را با برچسب واقعی مقایسه کنید. به عنوان مثال، مدلی که گونه های صحیح را روی نیمی از نمونه های ورودی انتخاب کرده است، دقت 0.5 دارد. شکل 4 یک مدل کمی موثرتر را نشان می دهد که 4 مورد از 5 پیش بینی را با دقت 80 درصد درست می کند:
| ویژگی های نمونه | برچسب | پیش بینی مدل | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| شکل 4. طبقه بندی کننده عنبیه که 80 درصد دقت دارد. | |||||
مجموعه داده آزمایشی را تنظیم کنید
ارزیابی مدل مشابه آموزش مدل است. بزرگترین تفاوت این است که نمونه ها از یک مجموعه تست جداگانه به جای مجموعه آموزشی آمده اند. برای ارزیابی منصفانه اثربخشی یک مدل، مثالهایی که برای ارزیابی یک مدل استفاده میشوند باید متفاوت از نمونههای مورد استفاده برای آموزش مدل باشند.
راهاندازی Dataset آزمایشی مشابه راهاندازی Dataset آموزشی است. فایل متنی CSV را دانلود کنید و مقادیر آن را تجزیه کنید، سپس کمی آن را به هم بزنید:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
مدل را روی مجموعه داده آزمایشی ارزیابی کنید
برخلاف مرحله آموزش، مدل فقط یک دوره واحد از داده های آزمون را ارزیابی می کند. در سلول کد زیر، روی هر مثال در مجموعه آزمایشی تکرار میکنیم و پیشبینی مدل را با برچسب واقعی مقایسه میکنیم. این برای اندازه گیری دقت مدل در کل مجموعه تست استفاده می شود:
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
برای مثال میتوانیم در آخرین دسته ببینیم که مدل معمولاً درست است:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 1],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
از مدل آموزش دیده برای پیش بینی استفاده کنید
ما مدلی را آموزش دادهایم و "اثبات" کردهایم که در طبقهبندی گونههای زنبق خوب - اما نه کامل است. حال بیایید از مدل آموزشدیده برای پیشبینی نمونههای بدون برچسب استفاده کنیم. یعنی روی نمونه هایی که دارای ویژگی هستند اما برچسب ندارند.
در زندگی واقعی، نمونههای بدون برچسب میتوانند از بسیاری از منابع مختلف از جمله برنامهها، فایلهای CSV و فیدهای داده آمده باشند. در حال حاضر، ما به صورت دستی سه نمونه بدون برچسب را برای پیشبینی برچسبهای آنها ارائه میکنیم. به یاد بیاورید، اعداد برچسب به یک نمایش نامگذاری شده به صورت زیر نگاشت می شوند:
-
0: زنبق ستوزا -
1: زنبق رنگارنگ -
2: زنبق ویرجینیکا
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (97.6%) Example 1 prediction: Iris versicolor (82.0%) Example 2 prediction: Iris virginica (56.4%)