
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش نحوه پیادهسازی روش Actor-Critic را با استفاده از TensorFlow برای آموزش یک عامل در محیط Open AI Gym CartPole-V0 نشان میدهد. فرض بر این است که خواننده با روشهای گرادیان خط مشی یادگیری تقویتی آشنایی دارد.
روش های بازیگر-نقد
روشهای بازیگر-نقد، روشهای یادگیری تفاوت زمانی (TD) هستند که تابع خطمشی مستقل از تابع ارزش را نشان میدهند.
یک تابع خط مشی (یا خط مشی) توزیع احتمال را بر روی اقداماتی که عامل می تواند بر اساس وضعیت داده شده انجام دهد، برمی گرداند. یک تابع مقدار بازده مورد انتظار را برای یک عامل تعیین میکند که از یک وضعیت معین شروع میشود و برای همیشه بر اساس یک سیاست خاص عمل میکند.
در روش Actor-Critic، خط مشی به عنوان بازیگری گفته میشود که مجموعهای از اقدامات ممکن را با توجه به یک حالت پیشنهاد میکند و تابع ارزش تخمین زده شده به عنوان منتقد نامیده میشود که اقدامات انجام شده توسط بازیگر را بر اساس خط مشی داده شده ارزیابی میکند. .
در این آموزش، Actor و Critic هر دو با استفاده از یک شبکه عصبی با دو خروجی نمایش داده می شوند.
CartPole-v0
در محیط CartPole-v0 ، یک قطب به گاری که در امتداد یک مسیر بدون اصطکاک حرکت می کند متصل است. قطب به صورت عمودی شروع می شود و هدف عامل جلوگیری از سقوط آن با اعمال نیروی 1- یا 1+ به گاری است. برای هر گامی که قطب قائم بماند، یک جایزه +1 داده می شود. یک قسمت زمانی به پایان می رسد که (1) قطب بیش از 15 درجه از عمودی باشد یا (2) گاری بیش از 2.4 واحد از مرکز حرکت کند.
وقتی میانگین کل پاداش برای قسمت به 195 در 100 آزمایش متوالی برسد، مشکل "حل شده" در نظر گرفته می شود.
برپایی
بسته های لازم را وارد کنید و تنظیمات جهانی را پیکربندی کنید.
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
مدل
Actor و Critic با استفاده از یک شبکه عصبی که به ترتیب احتمالات عمل و ارزش انتقادی را تولید میکند، مدلسازی میشوند. این آموزش از زیر کلاسه مدل برای تعریف مدل استفاده می کند.
در طول گذر رو به جلو، مدل حالت را به عنوان ورودی می گیرد و هم احتمالات عمل و هم مقدار بحرانی \(V\)را که تابع مقدار وابسته به حالت را مدل می کند، خروجی می دهد. هدف آموزش مدلی است که اقداماتی را بر اساس خط مشی \(\pi\) انتخاب می کند که بازده مورد انتظار را به حداکثر می رساند.
برای Cartpole-v0، چهار مقدار وجود دارد که وضعیت را نشان می دهد: موقعیت گاری، سرعت چرخ دستی، زاویه قطب و سرعت قطب. نماینده می تواند دو عمل را انجام دهد تا سبد را به ترتیب به چپ (0) و راست (1) فشار دهد.
برای اطلاعات بیشتر به صفحه ویکی CartPole-v0 ورزشگاه OpenAI مراجعه کنید.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
آموزش
برای آموزش نماینده مراحل زیر را طی کنید:
- عامل را روی محیط اجرا کنید تا داده های آموزشی در هر قسمت جمع آوری شود.
- بازده مورد انتظار را در هر مرحله زمانی محاسبه کنید.
- ضرر را برای مدل ترکیبی بازیگر و منتقد محاسبه کنید.
- شیب ها را محاسبه کنید و پارامترهای شبکه را به روز کنید.
- 1-4 را تکرار کنید تا به معیار موفقیت یا حداکثر قسمت ها رسیده باشید.
1. جمع آوری داده های آموزشی
همانطور که در یادگیری نظارت شده، برای آموزش مدل بازیگر-منتقد، باید داده های آموزشی داشته باشید. با این حال، برای جمع آوری چنین داده هایی، مدل باید در محیط "اجرا" شود.
داده های آموزشی برای هر قسمت جمع آوری می شود. سپس در هر مرحله زمانی، گذر رو به جلو مدل بر روی وضعیت محیط اجرا میشود تا احتمالات عمل و مقدار بحرانی بر اساس پارامتر خط مشی فعلی که توسط وزنهای مدل تعیین شده است، تولید شود.
اقدام بعدی از احتمالات عمل تولید شده توسط مدل نمونه برداری می شود، که سپس در محیط اعمال می شود و باعث ایجاد حالت و پاداش بعدی می شود.
این فرآیند در تابع run_episode میشود که از عملیات TensorFlow استفاده میکند تا بعداً برای آموزش سریعتر در نمودار TensorFlow کامپایل شود. توجه داشته باشید که tf.TensorArray s برای پشتیبانی از تکرار Tensor در آرایه های با طول متغیر استفاده شد.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. محاسبه بازده مورد انتظار
دنباله پاداش برای هر مرحله \(t\)، \(\{r_{t}\}^{T}_{t=1}\) جمع آوری شده در طول یک قسمت به دنباله ای از بازده های مورد انتظار \(\{G_{t}\}^{T}_{t=1}\) تبدیل می شود که در آن مجموع پاداش ها از مرحله زمانی فعلی \(t\) تا \(T\) هر مکان گرفته می شود. پاداش با یک ضریب تخفیف به طور نمایی در حال زوال \(\gamma\)ضرب می شود:
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
از آنجایی که \(\gamma\in(0,1)\)، به پاداشهای دورتر از مرحله زمانی فعلی وزن کمتری داده میشود.
به طور شهودی، بازده مورد انتظار به سادگی نشان می دهد که پاداش در حال حاضر بهتر از پاداش های بعدی است. در یک مفهوم ریاضی، برای اطمینان از همگرایی مجموع پاداش ها است.
برای تثبیت آموزش، توالی حاصل از بازده نیز استاندارد شده است (یعنی صفر میانگین و انحراف استاندارد واحد).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. از دست دادن بازیگر- منتقد
از آنجایی که یک مدل ترکیبی بازیگر- منتقد استفاده می شود، تابع ضرر انتخابی ترکیبی از ضرر بازیگر و منتقد برای آموزش است، همانطور که در زیر نشان داده شده است:
\[L = L_{actor} + L_{critic}\]
از دست دادن بازیگر
از دست دادن بازیگر بر اساس گرادیان های خط مشی با منتقد به عنوان خط پایه وابسته به حالت است و با تخمین های تک نمونه ای (در هر قسمت) محاسبه می شود.
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
جایی که:
- \(T\): تعداد گامهای زمانی در هر قسمت، که میتواند در هر قسمت متفاوت باشد
- \(s_{t}\): وضعیت در گام زمانی \(t\)
- \(a_{t}\): اقدام انتخاب شده در گام زمانی \(t\) حالت داده شده \(s\)
- \(\pi_{\theta}\): خط مشی (actor) است که توسط \(\theta\)پارامتر شده است.
- \(V^{\pi}_{\theta}\): تابع مقدار (نقدی) است که با \(\theta\)نیز پارامتر شده است.
- \(G = G_{t}\): بازده مورد انتظار برای یک وضعیت معین، جفت اقدام در گام زمانی \(t\)
یک عبارت منفی به مجموع اضافه میشود، زیرا ایده این است که با به حداقل رساندن زیان ترکیبی، احتمال اقداماتی که پاداشهای بالاتری را به همراه دارند، به حداکثر برسانیم.
مزیت - فایده - سود - منفعت
عبارت \(G - V\) در فرمول \(L_{actor}\) ما مزیت نامیده میشود، که نشان میدهد چقدر بهتر به یک عمل یک حالت خاص نسبت به یک اقدام تصادفی انتخاب شده بر اساس خطمشی \(\pi\) برای آن حالت داده میشود.
در حالی که امکان حذف یک خط پایه وجود دارد، این ممکن است منجر به واریانس بالا در طول تمرین شود. و نکته خوب در مورد انتخاب \(V\) به عنوان خط پایه این است که آموزش داده می شود تا حد ممکن به \(G\)نزدیک شود که منجر به واریانس کمتری می شود.
علاوه بر این، بدون منتقد، الگوریتم تلاش میکند تا احتمالات اقدامات انجام شده در یک حالت خاص را بر اساس بازده مورد انتظار افزایش دهد، که اگر احتمالات نسبی بین اقدامات ثابت باقی بماند، ممکن است تفاوت زیادی ایجاد نکند.
به عنوان مثال، فرض کنید که دو اقدام برای یک وضعیت معین، بازده مورد انتظار یکسانی را به همراه داشته باشند. بدون منتقد، الگوریتم تلاش میکند تا احتمال این اقدامات را بر اساس هدف \(J\)افزایش دهد. با منتقد، ممکن است معلوم شود که هیچ مزیتی وجود ندارد (\(G - V = 0\)) و بنابراین هیچ سودی در افزایش احتمالات اقدامات به دست نمیآید و الگوریتم گرادیانها را صفر میکند.
ضرر انتقادی
آموزش \(V\) برای نزدیک شدن به \(G\) می تواند به عنوان یک مشکل رگرسیونی با تابع ضرر زیر تنظیم شود:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
که در آن \(L_{\delta}\) ضرر هوبر است که نسبت به خطاهای مربعی حساسیت کمتری نسبت به داده های پرت دارد.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. تعریف مرحله آموزش برای به روز رسانی پارامترها
تمام مراحل بالا در یک مرحله آموزشی ترکیب می شوند که هر قسمت اجرا می شود. تمام مراحل منتهی به تابع ضرر با زمینه tf.GradientTape اجرا می شوند تا تمایز خودکار را فعال کنند.
این آموزش از بهینه ساز Adam برای اعمال گرادیان ها به پارامترهای مدل استفاده می کند.
مجموع پاداشهای بدون تخفیف، episode_reward نیز در این مرحله محاسبه میشود. این مقدار بعداً برای ارزیابی اینکه آیا معیار موفقیت برآورده شده است استفاده می شود.
زمینه tf.function بر روی تابع train_step اعمال می شود تا بتوان آن را در یک نمودار TensorFlow قابل فراخوانی کامپایل کرد که می تواند منجر به افزایش سرعت 10 برابری در آموزش شود.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. حلقه آموزش را اجرا کنید
آموزش با اجرای مرحله آموزش تا رسیدن به معیار موفقیت یا حداکثر تعداد قسمت ها اجرا می شود.
یک رکورد در حال اجرا از جوایز قسمت در یک صف نگهداری می شود. پس از رسیدن به 100 آزمایش، قدیمیترین پاداش در سمت چپ (دم) انتهای صف حذف میشود و جدیدترین پاداش در سر (راست) اضافه میشود. مجموع در حال اجرا از پاداش نیز برای بهره وری محاسباتی حفظ می شود.
بسته به زمان اجرا شما، آموزش می تواند در کمتر از یک دقیقه تمام شود.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
تجسم
پس از آموزش، خوب است که نحوه عملکرد مدل را در محیط تجسم کنید. میتوانید سلولهای زیر را اجرا کنید تا یک انیمیشن GIF از یک قسمت اجرا شده مدل ایجاد کنید. توجه داشته باشید که بسته های اضافی برای OpenAI Gym باید نصب شود تا تصاویر محیط به درستی در Colab ارائه شود.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
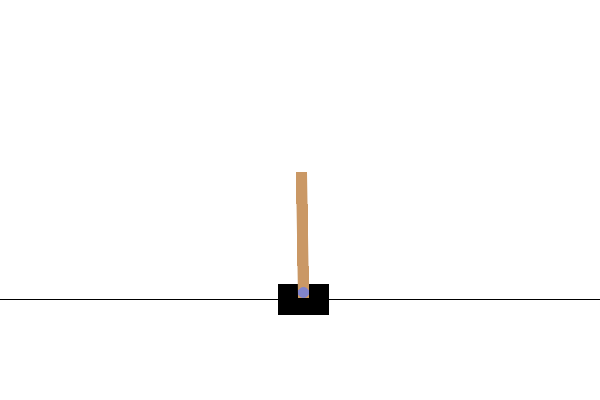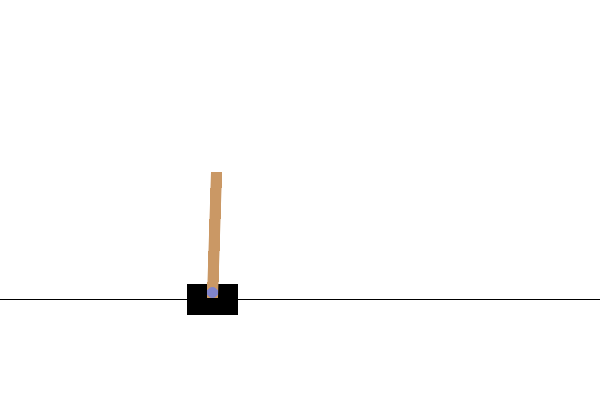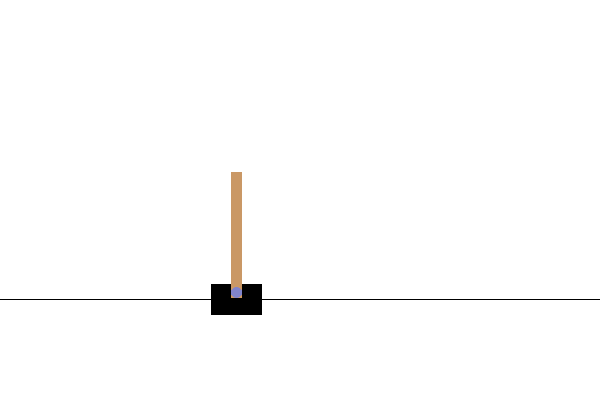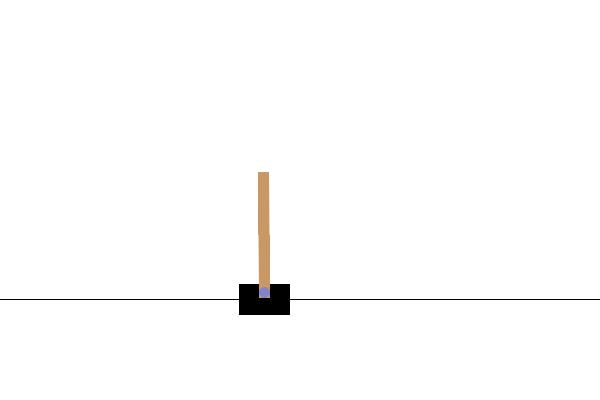
مراحل بعدی
این آموزش نحوه پیاده سازی روش بازیگر-نقد با استفاده از تنسورفلو را نشان می دهد.
به عنوان گام بعدی، می توانید یک مدل را در محیطی متفاوت در OpenAI Gym آموزش دهید.
برای اطلاعات بیشتر در مورد روشهای منتقد بازیگر و مشکل Cartpole-v0، میتوانید به منابع زیر مراجعه کنید:
برای مثالهای یادگیری تقویتی بیشتر در TensorFlow، میتوانید منابع زیر را بررسی کنید: